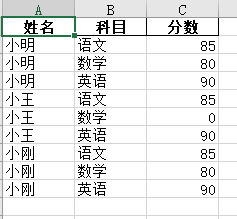
一、数据表格如下:
问题
1、最上方有空行,左边有空列
2、有完全空的行
3、列中存在空值。小王的数据成绩为空
4、姓名列为合并单元格
二、数据清洗的三类函数
1、检测:isnull和notnull:检测是否为空,可用于dataframe和series
2、丢弃:dropna(axis,how,inplace):
axis:删除的是行还是列
how:如果是any,表示任何为空的都删除;如果是all,表示所有值为空才删除
inplace:如果为TRUE,则修改当前df,否则返回新的df
3、fillna:填充空值。fillna(value,method,axis,inplace)
value:用于填充的值,可以是单值或者字典
method:等于使用前一个不为空的值作为填充值用 forWord fill;等于后一个不为空的值用backword fill
axis:按行还是按列填充
inplace:True则修改当前df;否则返回新的df
三、实例
1、略过前边两个空行
import pandas as pd df=pd.read_excel('./student_excel/student_excel.xlsx',engine='openpyxl') #不略过则输出为: ''' Unnamed: 0 Unnamed: 1 Unnamed: 2 Unnamed: 3 #不略过,前边2格空行被读到df 0 NaN NaN NaN NaN 1 NaN 姓名 科目 分数 2 NaN 小明 语文 85 3 NaN NaN 数学 80 4 NaN NaN 英语 90 5 NaN NaN NaN NaN 6 NaN 小王 语文 85 7 NaN NaN 数学 NaN 8 NaN NaN 英语 90 9 NaN NaN NaN NaN 10 NaN 小刚 语文 85 11 NaN NaN 数学 80 12 NaN NaN 英语 90 '''
df=pd.read_excel('./student_excel/student_excel.xlsx',engine='openpyxl',skiprows=2) #增加skiprows参数,略过2个空行 ''' Unnamed: 0 姓名 科目 分数 0 NaN 小明 语文 85.0 1 NaN NaN 数学 80.0 2 NaN NaN 英语 90.0 3 NaN NaN NaN NaN 4 NaN 小王 语文 85.0 5 NaN NaN 数学 NaN 6 NaN NaN 英语 90.0 7 NaN NaN NaN NaN 8 NaN 小刚 语文 85.0 9 NaN NaN 数学 80.0 10 NaN NaN 英语 90.0 '''
2、先检测空值
#在dataframe上检测所有的空值
df.isnull() ''' Unnamed: 0 姓名 科目 分数 0 True False False False 1 True True False False 2 True True False False 3 True True True True 4 True False False False 5 True True False True 6 True True False False 7 True True True True 8 True False False False 9 True True False False 10 True True False False ''' #True的全部是空值
#也可以在series上检测
df['分数'].isnull()
'''
0 False
1 False 2 False 3 True 4 False 5 True 6 False 7 True 8 False 9 False 10 False Name: 分数, dtype: bool
'''
#可以删选没有空值的所有行
df.loc[df['分数'].notnull(),:]
3、删全是空值得列
df.dropna(axis=1,how='all',inplace=True) ''' 姓名 科目 分数 0 小明 语文 85.0 1 NaN 数学 80.0 2 NaN 英语 90.0 3 NaN NaN NaN 4 小王 语文 85.0 5 NaN 数学 NaN 6 NaN 英语 90.0 7 NaN NaN NaN 8 小刚 语文 85.0 9 NaN 数学 80.0 10 NaN 英语 90.0 '''
4、删全是空值的行
df.dropna(axis=0,how='all',inplace=True) ''' 姓名 科目 分数 0 小明 语文 85.0 1 NaN 数学 80.0 2 NaN 英语 90.0 4 小王 语文 85.0 5 NaN 数学 NaN 6 NaN 英语 90.0 8 小刚 语文 85.0 9 NaN 数学 80.0 10 NaN 英语 90.0 '''
5、将分数值为空的填充为0
#两种方法可以实现 #第一种,使用字典 df.fillna({'分数':0}) #分数列作为key,为空的列填充0 #第二种方法,使用筛选 df.loc[:,'分数']=df['分数'].fillna(0) #删选出分数列,为空就填0
'''
| 姓名 | 科目 | 分数 | |
|---|---|---|---|
| 0 | 小明 | 语文 | 85.0 |
| 1 | NaN | 数学 | 80.0 |
| 2 | NaN | 英语 | 90.0 |
| 4 | 小王 | 语文 | 85.0 |
| 5 | NaN | 数学 | 0.0 |
| 6 | NaN | 英语 | 90.0 |
| 8 | 小刚 | 语文 | 85.0 |
| 9 | NaN | 数学 | 80.0 |
| 10 | NaN | 英语 | 90.0 |
'''6、将姓名列为空的填上姓名
#用前边非空的值填充 df.loc[:,'姓名']=df['姓名'].fillna(method='ffill') ''' 姓名 科目 分数 0 小明 语文 85.0 1 小明 数学 80.0 2 小明 英语 90.0 4 小王 语文 85.0 5 小王 数学 0.0 6 小王 英语 90.0 8 小刚 语文 85.0 9 小刚 数学 80.0 10 小刚 英语 90.0 '''
7、将清洗好的数据写到excel
df.to_excel('./student_excel/student_excel_c.xlsx',index=False) #index=False 表示index不写入