
结对编程
结对编程
| 这个作业属于哪个课程 | 课程链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 结对编程的学习,并实现一个四则运算题生成器 |
林郁达 3119005330
黄润波 3119005322
一、PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 860 | 1550 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 30 | 50 |
| · Design Review | · 设计复审 | 20 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| · Design | · 具体设计 | 300 | 750 |
| · Coding | · 具体编码 | 200 | 300 |
| · Code Review | · 代码复审 | 50 | 25 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 50 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 20 |
| · 合计 | 860 | 1550 |
二、已完成的主要功能
- 根据传入的参数生成对应个数与值上限的四则运算式与答案文件,生成 10000条 上限为10 运算符个数为3 的文件总共仅需要230ms±
- 根据传入的参数读取对应的问题文件与答案文件,根据顺序关系判断计算式与答案是否匹配,并将正确与错误的个数,题目序号进行输出
三、效能分析
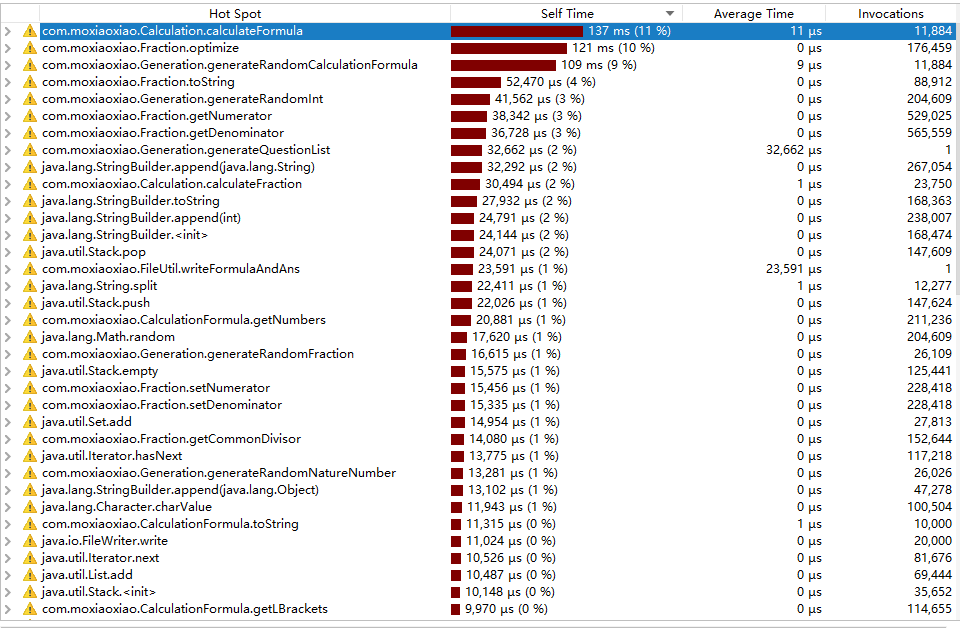
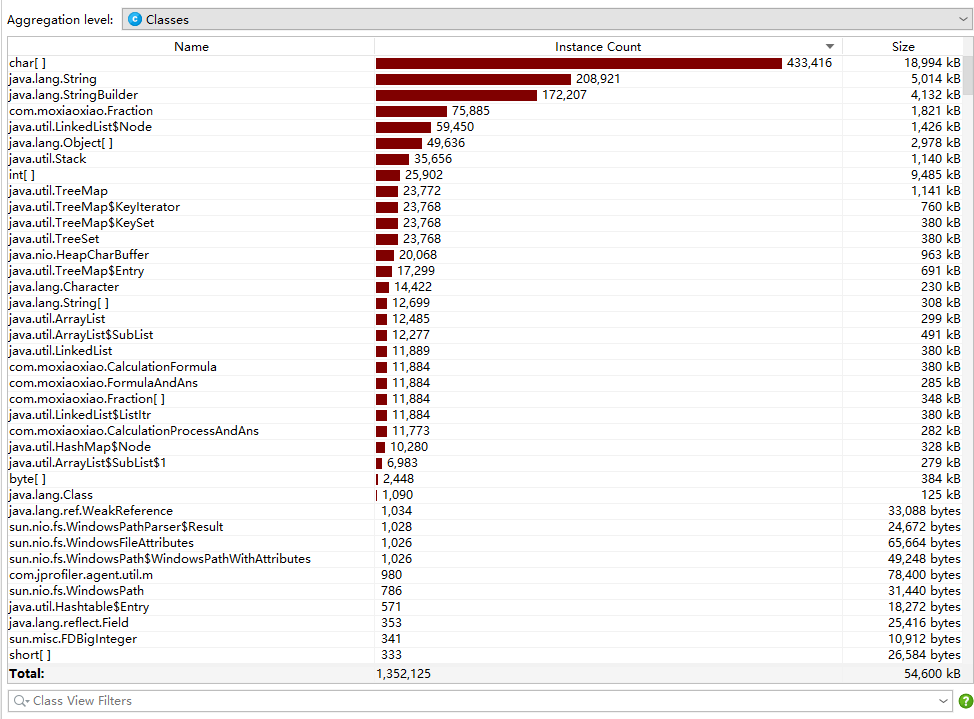
耗时占比图与内存占比图
由于存储的特性,使用字符串处理该项目是较为稳妥的一种选择,自然字符串与字符数组的内存占用上会相对较高,并且涉及较多的字符串拼接,Builder自然占用内存较高。
而在耗时上占比最大的为计算表达式与生成表达式,优化表达式三个方法上,计算表达式和生成表达式因为代码较多,计算较为复杂而占比较高,优化表达式则是因为每次调用表达式对象都会进行一次优化,因为频繁的调用而导致的占比较高。
目前可以考虑优化掉这个优化表达式的方法,生成表达式也可以进行一定的优化,而计算方面因为是采用逆波兰式,所以就需要酌情考虑优化了,为了有更高的查重效率采用逆波兰是最佳的选择。
四、具体的模块设计
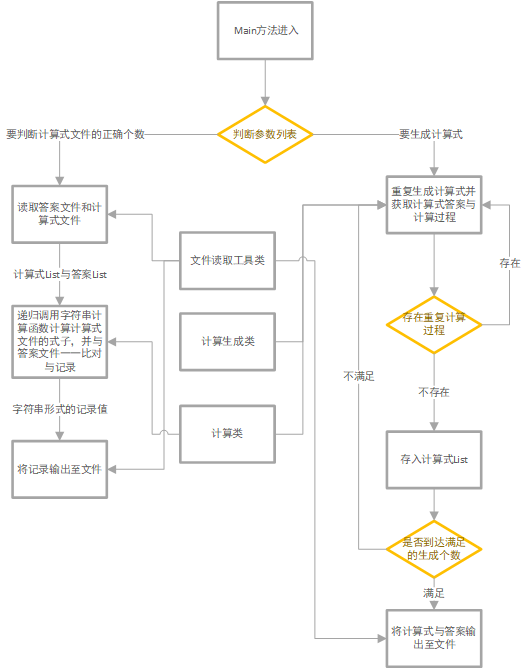
文件读取工具类:主要负责文件的读写功能
计算生成类:负责计算式的生成与判断
计算类:分别负责两种类型(计算式类,字符串类)的计算式计算
在右边的计算生成采用的是自定义的计算式类进行运算,而判断文件计算式的则是采用字符串类进行计算
字符串运算
字符串的运算采用的是递归运算的方式,这种方式操作简单,不需要过多的内存占用。
关键代码:
public static String getResult(String str) throws Exception {
//处理包裹在最外层的括号
if (str.startsWith("(") && str.endsWith(")")) {
str = str.substring(1, str.length() - 1);
}
//处理空格
str = str.replaceAll(" ", "");
//处理一下计算过程中出现的--情况,首位--直接去掉,中间--变为+
str = str.startsWith("--") ? str.substring(2) : str;
str = str.replaceAll("--", "+");
str = str.replaceAll("\\+-", "-");
if (str.matches("-{0,1}[0-9]+([.][0-9]+){0,1}")) {//不存在运算符了,即递归结束,这里的正则为匹配所有的正负整数及小数
return str;
}
//表示每次递归计算完一步后的表达式
String newExpr = null;
// 第一步:从最后的最里面的括号开始去括号至无括号
if (str.contains("(")) {
//最后一个左括号的索引值
int lIndex = str.lastIndexOf("(");
//该左括号对应的右括号的索引
int rIndex = str.indexOf(")", lIndex);
//括号中的字表达式
String subExpr = str.substring(lIndex + 1, rIndex);
newExpr = str.substring(0, lIndex) + getResult(subExpr) //调用本身,计算括号中表达式结果
+ str.substring(rIndex + 1);
return getResult(newExpr);
}
// 第二步:去乘除至无乘除
if (str.contains("*") || str.contains("/") || str.contains("×") || str.contains("÷")) {
//该正则表示匹配一个乘除运算,如1.2*3 1.2/3 1.2*-2 等
Pattern p = Pattern.compile("[0-9]+([.][0-9]+){0,1}[*/×÷]-{0,1}[0-9]+([.][0-9]+){0,1}");
Matcher m = p.matcher(str);
//找到了匹配乘除的计算式
if (m.find()) {
//第一个乘除表达式
String temp = m.group();
String[] a = temp.split("[*/×÷]");
newExpr = str.substring(0, m.start())
+ doubleCal(Double.parseDouble(a[0]), Double.parseDouble(a[1]), temp.charAt(a[0].length()))
+ str.substring(m.end());
}
return getResult(newExpr);
}
// 第三步:去加减至无加减
if (str.contains("+") || str.contains("-")) {
//该正则表示匹配一个乘除运算,如1.2+3 1.2-3 1.2--2 1.2+-2等
Pattern p = Pattern.compile("-{0,1}[0-9]+([.][0-9]+){0,1}[+-][0-9]+([.][0-9]+){0,1}");
Matcher m = p.matcher(str);
if (m.find()) {
//第一个加减表达式
String temp = m.group();
String[] a = temp.split("\\b[+-]", 2);
newExpr = str.substring(0, m.start())
+ doubleCal(Double.parseDouble(a[0]), Double.parseDouble(a[1]), temp.charAt(a[0].length()))
+ str.substring(m.end());
}
return getResult(newExpr);
}
throw new Exception("计算错误,请确定表达式: " + str + " 是否存在错误或者括号正常匹配");
}
计算式运算
与字符串不同的是,该计算式类由开发人员自定义而成的,为了是方便生成分式与查重。
计算式类的主要代码:
package com.moxiaoxiao;
import lombok.Getter;
import lombok.Setter;
/**
* @author 墨小小
* <p>
* 计算式类
*/
@Setter
@Getter
public class CalculationFormula{
/**
* 计算符号
*/
private char[] operators;
/**
* 左括号位置
* 下标代表包裹的数字序号,值代表括号个数
*/
private int[] lBrackets;
/**
* 右括号位置
* 下标代表包裹的数字序号,值代表括号个数
*/
private int[] rBrackets;
/**
* 分数
*/
private Fraction[] numbers;
@Override
public String toString() {
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < numbers.length; i++) {
//拼接数字
for (int j = 0; j < lBrackets[i]; j++) {
stringBuilder.append("(");
}
stringBuilder.append(numbers[i].toString());
for (int j = 0; j < rBrackets[i]; j++) {
stringBuilder.append(")");
}
if (i < operators.length) {
stringBuilder.append(operators[i]);
}
}
return stringBuilder.toString();
}
}
采用的是自定义的分数类型(有分子和分母的一个对象),并分别用2个Int数组代表左右括号的个数与位置,和一个数字数组来记录数字。
这种设计结构导致了若采用字符串运算则会没法正常显示分数,或是正常显示出真分数的形式(例如 1’2/3 ,必须先转为 5/3 再进行计算,计算结果也不一定是 5/3 而是 1.667),而且也为了查重的方便,采用的是逆波兰表达式。
参考链接:<a href = “https://blog.csdn.net/qq_26020387/article/details/105455137">【逆波兰表达式】
简单说说:
1.中缀表达式
中缀表达式是一个通用的算术或逻辑公式表示方法。操作符是以中缀形式处于操作数的中间 ,中缀表达式是人们常用的算术表示方法。
[例:1-(2+3) ]计算方法:与我们平常计算相同。
2.前缀表达式
前缀表达式是一种没有括号的算术表达式,与中缀表达式不同的是,其将运算符写在前面,操作数写在后面。为纪念其发明者波兰数学家Jan Lukasiewicz,前缀表达式也称为“波兰式”,
[例:- 1 + 2 3,它等价于1-(2+3)。]计算方法:对前缀表达式求值,要从右至左扫描表达式,首先从右边第一个字符开始判断,若当前字符是数字则一直到数字串的末尾再记录下来,若为运算符,则将右边离得最近的两个“数字串”作相应运算,然后以此作为一个新的“数字串”并记录下来;扫描到表达式最左端时扫描结束,最后运算的值即为表达式的值。
3.后缀表达式
逆波兰表达式又叫做后缀表达式。逆波兰表示法是波兰逻辑学家J・卢卡西维兹(J・ Lukasewicz)于1929年首先提出的一种表达式的表示方法。后来,人们就把用这种表示法写出的表达式称作“逆波兰表达式”。逆波兰表达式把运算量写在前面,把算符写在后面。
[例:1, 2, 3, +, -,它等价于1-(2+3)。]计算方式:新建一个表达式,如果当前字符为变量或者为数字,则压栈,如果是运算符,则将栈顶两个元素弹出作相应运算,结果再入栈,最后当表达式扫描完后,栈里的就是结果。
查重的思路也是通过按规范存储其计算过程并比较计算过程来判断是否会出现计算式的重复情况。
计算部分主要代码:
/**
* 计算一个分数表达式
*
* @param formula 要被计算的式子
* @return 计算后的分数值和计算过程
*/
public static CalculationProcessAndAns calculateFormula(CalculationFormula formula) throws ByZeroException {
//初始化俩个栈,符号栈和算术栈
Stack<Character> operatorStack = new Stack<>();
Stack<Object> formulaStack = new Stack<>();
//通过共用的下标,轮流insert进入stack
for (int i = 0; i < formula.getNumbers().length; i++) {
//1 + ( ( 2 + 3 ) * 4 ) - 5
//处理左括号
for (int j = 0; j < formula.getLBrackets()[i]; j++) {
operatorStack.push('(');
}
//处理数字
formulaStack.push(formula.getNumbers()[i]);
//处理右括号
for (int j = 0; j < formula.getRBrackets()[i]; j++) {
while (true) {
char temp = operatorStack.pop();
if (temp == '(') {
break;
}
formulaStack.push(temp);
}
}
//处理运算符
if (i < formula.getNumbers().length - 1) {
char operator = formula.getOperators()[i];
while (true) {
if (operatorStack.empty() || operatorStack.peek() == '(') {
operatorStack.push(operator);
break;
} else if ((operator == '×' || operator == '*' || operator == '÷') && (operatorStack.peek() == '+' || operatorStack.peek() == '-')) {
operatorStack.push(operator);
break;
} else {
formulaStack.push(operatorStack.pop());
}
}
}
}
//处理剩下的运算符号
while (!operatorStack.empty()) {
formulaStack.push(operatorStack.pop());
}
//将运算式栈转为一般链表,并存入List以计算
List<Object> formulaList = new LinkedList<>();
while (!formulaStack.empty()) {
formulaList.add(formulaStack.pop());
}
Collections.reverse(formulaList);
//用一个栈零时存数字
Stack<Fraction> fractionStack = new Stack<>();
//用字符串拼接计算过程
StringBuilder calculationProcess = new StringBuilder();
for (Object o : formulaList) {
if (o instanceof Fraction) {
//是个数字
fractionStack.push((Fraction) o);
} else if (o instanceof Character) {
//是个计算符号 查重要在这里处理
Fraction num2 = fractionStack.pop();
Fraction num1 = fractionStack.pop();
Fraction num3 = calculateFraction(num1, num2, (char) o);
fractionStack.push(num3);
switch ((char) o) {
case '+':
case '*':
case '×': {
if (num1.getValue() < num2.getValue()) {
calculationProcess.append(num1).append((char) o).append(num2).append(" ");
} else {
calculationProcess.append(num2).append((char) o).append(num1).append(" ");
}
break;
}
case '-':
case '÷': {
calculationProcess.append(num1).append((char) o).append(num2).append(" ");
break;
}
}
}
}
CalculationProcessAndAns result = new CalculationProcessAndAns();
result.setAns(fractionStack.pop().optimize());
result.setProcess(calculationProcess.toString());
//把计算过程和答案一起返回,方便查重
return result;
}
五、具体代码
六、运行测试
- 测试生成10000条计算式,值的上限为10

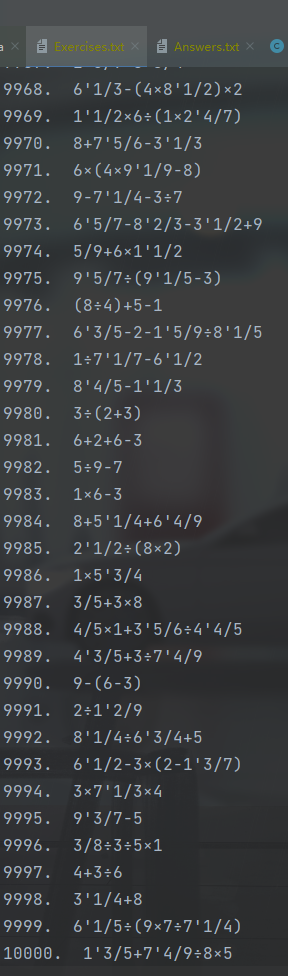
[计算式文件]
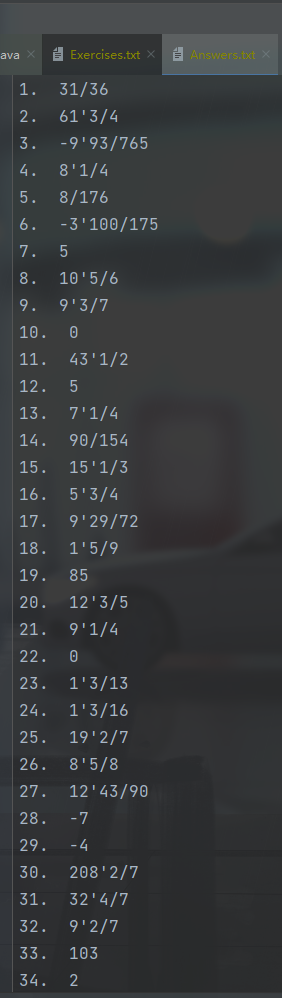

[答案文件]
- 测试读取文件并判断文件计算式正确与错误个数和题目序号

[题目文件]
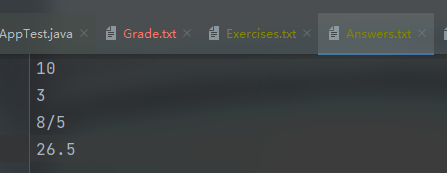
[答案文件]
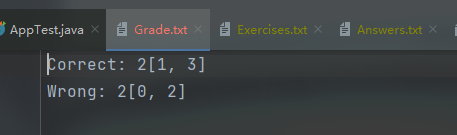
[输出结果]
结果正确
七、项目小结
林郁达:本次结对编程的体验十分神奇吧,两个人从0开始磨合到现在逐渐熟悉,并且开发效率也比原本开始要好上很多。比起平时独立思考的作业,合作开发更多的是需要我和搭档之间的配合与交流,在合作配合中相互磨合久了,开发效率也会比单个人开发来得更好,试一次十分有趣的体验。
黄润波:本次作业最失败的点是我们没有充分地去磨合就开始了编程,以至于想出了许多错误的想法与思路,虽然最终实现了目标,但是对我们能力的提升上并没有太大的帮助。在下一次的项目中我一定要多思考。

