
【人工智能】机器学习入门之监督学习(一)有监督学习
 监督学习算法是常见算法之一,主要分为有监督学习和无监督学习。本文主要记录了有监督学习中的分类算法和回归算法,其中回归算法是本文最主要内容。
监督学习算法是常见算法之一,主要分为有监督学习和无监督学习。本文主要记录了有监督学习中的分类算法和回归算法,其中回归算法是本文最主要内容。
机器学习入门之监督学习(一)有监督学习
简介
监督学习算法是常见算法之一,主要分为有监督学习和无监督学习。本文主要记录了有监督学习中的分类算法和回归算法,其中回归算法是本文最主要内容。
本笔记对应视频:阿里云开发者社区学习中心-人工智能学习路线-阶段1:机器学习概览及常见算法
对应视频地址:https://developer.aliyun.com/learning/course/529
监督学习
定义:利用已知类别的样本,训练学习得到一个最优模型,使其达到所要求性能,再利用这个训练所得模型,将所有的输入映射为相应的输出,对输出进行简单的判断,从而实现分类的目的,即可以对未知数据进行分类。
监督学习分为:有监督学习,无监督学习,半监督学习
本文内容主要介绍有监督学习和无监督学习相关算法
有监督学习
有监督学习( Supervised learning ) :利用一组已知类别的样本来训练模型,使其达到性能要求。
特点:为输入数据(训练数据)均有一个明确的标识或结果(标签)
萌狼说1:就是给他问题和答案,让他自己做题,然后自己对答案。
萌狼说2:就是给它一道有答案的例题让它学习
分类算法
分类(Classification):就是通过已有数据集(训练集)的学习,得到一个目标函数f (模型),把每个属性集x映射到目标属性y (类) ,且y必须是离散的(若y为连续的,则属于回归算法)。通过对已知类别训练集的分
析,从中发现分类规则,以此预测新数据的类别。
萌狼说人话:比如我手上有一堆图片,同时每张图片标记了图中人物是否戴口罩。我给它看:AI你看啊,这张图是戴了口罩了,这张图是没戴口罩的……(AI学习中),根据我教它的,它进行建模,然后你给它一张没见过的图片,它在这个时候就能根据模型预测这张图是否戴了口罩了。
【相关阅读】计算机视觉技术与应用:识别人物是否带口罩
文章地址(包含代码):https://mp.weixin.qq.com/s/mEvL4qUpB0gxYhMm6WVqng
分类算法有很多种
按原理分类:
- 基于统计的:例如贝叶斯分类
- 基于规则的:例如决策树算法
- 基于神经网络的:神经网络算法
- 基于距离的:KNN(K最近邻)
常用评估指标
- 精确率:预测结果与实际结果的比例
- 召回率:预测结果中某类结果的正确覆盖率
- F1-Score:统计量,综合评估分类模型,取值0-1之间
回归算法
回归(Regression)
分类算法的带的目标属性y(类)是离散的,而回归算法得到的y是连续的。
既然是连续的,就可以使用函数表示。
所以回归算法的实质:通过已有数据,尽可能的去拟合成一个函数
例如:我有商品在不同售价时对应卖出数量的数据集,对这些数据建模后,模型就可以根据我们输入的价格预测会卖出的数量。实际上它是根据我们给的数据,拟合了一个函数,例如拟合线性方程Y=aX+b
这个a和b可以使用最小二乘法求出来。
比如我给你如下数据
| 价格 | 销售量 |
|---|---|
| 1 | 1000 |
| 2 | 900 |
| 3 | 800 |
| 4 | 700 |
| 5 | 600 |
| 6 | 500 |
| 7 | 400 |
| 8 | 300 |
| 9 | 200 |
| 10 | 100 |
你一看这数据,你就知道价格和销售量之间存在着某种关系,比如y=kx+b
计算出斜率后根据
和已经确定的斜率k,利用待定系数法求出截距b
先用数学的方式算一下,代码如下
import pandas as pd
def getK(data):
avgx = data["x"].values.mean() # 获取x平均值
avgy = data["y"].values.mean() # 获取y平均值
fenzi = 0
fenmu = 0
for i in range(len(data["x"])):
x = data["x"][i]
y = data["y"][i]
fenzi += x * y
fenmu += x * x
fenzi = fenzi -len(data["x"]) * avgx * avgy
fenmu = fenmu - len(data["x"]) * avgx *avgx
k = fenzi / fenmu
b = avgy - k *avgx
return "y="+str(k)+"x+"+str(b)
data = pd.DataFrame(data = [[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],[1000, 900, 800, 700, 600, 500, 400, 300, 200, 100]],index=["x","y"])
data = data.T # 转置
result = getK(data)
print(result)
[输出结果] y=-100.0x+1100.0
这个线性方程走下坡路,y后面就会变为负数。虽然说销售量不可能为负数,但是我们这个只是一个不严谨的例子,数据我随便造的,存在不合理的情况也正常
我们的目的是: tensorflow拟合的线性回归方程,尽可能贴近数学计算出来的线性回归方程
接下来使用Tensoflow来得出这个模型(拟合线性回归方程)
首先准备数据,光是我们上面的数据是远远不够的,因此我们造一点数据出来,造数据的代码如下
import math
import random
import pandas as pd
def getCheck(data):
avgx = data["x"].values.mean() # 获取x平均值
avgy = data["y"].values.mean() # 获取y平均值
fenzi = 0
fenmu = 0
for i in range(len(data["x"])):
x = data["x"][i]
y = data["y"][i]
fenzi += x * y
fenmu += x * x
fenzi = fenzi - len(data["x"]) * avgx * avgy
fenmu = fenmu - len(data["x"]) * avgx * avgx
k = fenzi / fenmu
b = avgy - k * avgx
testX=[]
testY=[]
# return k,b
for i in range(1000):
x = random.uniform(0, 10)
y = k * x + b
testX.append(x)
testY.append(math.floor(y)) # 向下取整
print(testX)
print(testY)
d = pd.DataFrame(data = [testX,testY])
d = d.T
d.to_csv("train_data.csv")
# d.to_csv("test_data.csv")
if __name__ == '__main__':
data = pd.DataFrame(data=[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], [1000, 900, 800, 700, 600, 500, 400, 300, 200, 100]],
index=["x", "y"])
data = data.T # 转置
getCheck(data)
运行上面的代码(注意第33行和第34行,分别是生成训练集和测试集的),生成数据集
【相关阅读】
激活函数:https://www.cnblogs.com/mllt/p/sjwlyh.html#%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0
优化器:https://www.cnblogs.com/mllt/p/sjwlbg.html#2modelcompile
读取数据集
# 读取数据集
train_data = pd.read_csv('./train_data.csv')
test_data = pd.read_csv('./test_data.csv')
构建模型
首先要明确我们要做的事情,我们是在做预测,使用线性回归算法方式预测。
# 构建模型
model = tf.keras.Sequential([
# 全连接层 tf.keras.layers.Dense() 全连接层在整个网络卷积神经网络中起到“特征提取器”的作用
# --- 输出维度
# --- 激活函数activation:relu 关于激活函数。可以查阅https://www.cnblogs.com/mllt/p/sjwlyh.html#%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0
tf.keras.layers.Dense(128, activation='relu', input_shape=(1,)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1)
])
# 设置优化器optimizer 相关链接:https://www.cnblogs.com/mllt/p/sjwlbg.html#2modelcompile
# https://www.cnblogs.com/mllt/p/sjwlyh.html#%E4%BC%98%E5%8C%96%E5%99%A8
optimizer = tf.keras.optimizers.Adam(lr = 0.002)
"""
lr 学习率。lr决定了学习进程的快慢(也可以看作步幅的大小)。
如果学习率过大,很可能会越过最优值;
如果学习率过小,优化的效率可能很低,导致过长的运算时间
优化器keras.optimizers.Adam()是解决这个问题的一个方案。
其大概的思想是开始的学习率设置为一个较大的值,然后根据次数的增多,动态的减小学习率,以实现效率和效果的兼得
"""
训练模型
model.compile(loss="mse", optimizer=optimizer, metrics=['mse']) # 预测评价指标:https://blog.csdn.net/guolindonggld/article/details/87856780
# 均方误差(MSE)是最常用的回归损失函数,计算方法是求预测值与真实值之间距离的平方和
# 相关链接:https://www.cnblogs.com/mllt/p/sjwlbg.html#2modelcompile
# 神经网络模型
print(model)
# 神经网络模型结构
print(model.summary())
# 对神经网络进行训练
模型训练情况可视化
# 训练情况可视化
hist = pd.DataFrame(history.history)
print(hist)
hist['epoch'] = history.epoch
plt.figure()
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.plot(hist['epoch'], hist['loss'],label="训练集损失值")
plt.plot(hist['epoch'], hist['val_loss'],label='测试集损失值')
"""
最佳情况:loss 和 val_loss 都不断下降
过拟合:loss不断下降,val_loss趋近于不变 解决办法:减少学习率或者减少批量数目
数据集异常:loss趋近于不变,val_loss不断下降
学习瓶颈:loss、val_loss都趋近于不变 解决办法:减少学习率或者减少批量数目
神经网络设计的有问题:loss、val_loss都不断上升 解决办法:重置模型结构 重置数据集
"""
plt.legend()
plt.show()
plt.figure()
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.plot(hist['epoch'], hist['mse'],label="训练集准确率")
plt.plot(hist['epoch'], hist['val_mse'],label="测试集准确率")
plt.legend()
plt.show()
预测情况可视化
# 预测情况可视化
plt.figure()
y = model.predict(test_data["0"])
plt.plot(test_data["0"],y,label="模型预测值")
plt.plot(test_data['0'],test_data['1'],label="真实值")
plt.legend()
plt.show()
预测
print(model.predict([5.5]))
结果
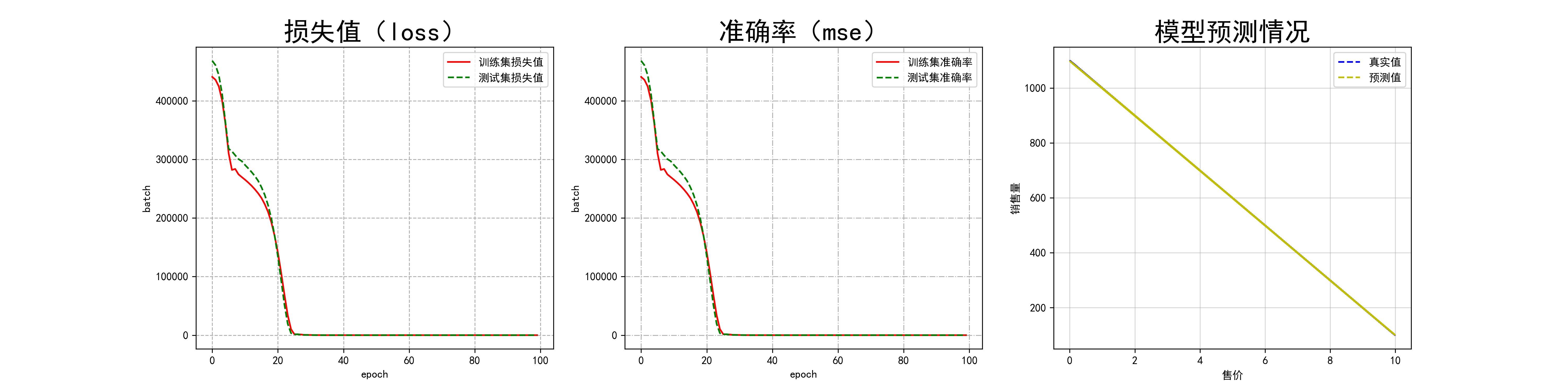
MSE:均方误差(Mean Square Error)
范围[0,+∞],当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大,模型性能越差。
完整代码
这个完整代码,是上面代码删除注释后,图像规范化后的完整代码。
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 正常显示负号
train_data = pd.read_csv('./train_data.csv')
test_data = pd.read_csv('./test_data.csv')
# 构建模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(1,)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1)
])
optimizer = tf.keras.optimizers.Adam(lr = 0.002)
model.compile(loss="mse", optimizer=optimizer, metrics=['mse'])
history = model.fit(train_data["0"], train_data["1"], batch_size=100, epochs=100, validation_split=0.3, verbose=0)
# 训练情况可视化
hist = pd.DataFrame(history.history)
print(hist)
hist['epoch'] = history.epoch
y = model.predict(test_data["0"])
# plt.figure(figsize=(10,5),dpi=300)# 创建画布
fig,axes = plt.subplots(nrows=1,ncols=3,figsize=(20,5),dpi=300)
# 添加描述
axes[0].set_title("损失值(loss)",fontsize=24)
axes[1].set_title("准确率(mse)",fontsize=24)
axes[2].set_title("模型预测情况",fontsize=24)
# 设置标签
axes[0].set_ylabel("batch")
axes[1].set_ylabel("batch")
axes[2].set_ylabel("销售量")
axes[0].set_xlabel("epoch")
axes[1].set_xlabel("epoch")
axes[2].set_xlabel("售价")
axes[0].plot(hist['epoch'], hist['mse'],label="训练集损失值",color="r",linestyle="-")
axes[0].plot(hist['epoch'],hist['val_mse'],label="测试集损失值",color="g",linestyle="--")
axes[1].plot(hist['epoch'], hist['loss'],label="训练集准确率",color="r",linestyle="-")
axes[1].plot(hist['epoch'],hist['val_loss'],label="测试集准确率",color="g",linestyle="--")
axes[2].plot(test_data['0'],test_data['1'],label="真实值",color="b",linestyle="--")
axes[2].plot(test_data['0'],y,label="预测值",color="y",linestyle="--")
axes[0].legend(loc="upper right")# 显示图例必须在绘制时设置好
axes[1].legend(loc="upper right")# 显示图例必须在绘制时设置好
axes[2].legend(loc="upper right")# 显示图例必须在绘制时设置好
# 添加网格
# plt.grid(True,linestyle="--",alpha=0.5) # 添加网格
axes[0].grid(True,linestyle="--",alpha=1)
axes[1].grid(True,linestyle="-.",alpha=1)
axes[2].grid(True,linestyle="-",alpha=0.5)
plt.show()
print(model.predict([5.5]))
其他有监督学习算法
分类算法:
-
KNN ( K最近邻,K-Nearest Neighbour)
-
NB (朴素贝叶斯 ,Naive Bayes )
-
DT (决策树, Decision Tree ) : C45、CART
-
SVM (支持向量机, Support Vector Machine )
回归预测:
-
线性回归( Linear Regression )
-
逻辑回归( Logistic Regression )
-
岭回归( Ridge Regression )
-
拉索回归( LASSO Regression )

