
第12篇-认识CodeletMark
InterpreterCodelet依赖CodeletMark完成自动创建和初始化。CodeletMark继承自ResourceMark,允许自动析构,执行的主要操作就是,会按照InterpreterCodelet中存储的实际机器指令片段分配内存并提交。这个类的定义如下:
class CodeletMark: ResourceMark {
private:
InterpreterCodelet* _clet; // InterpreterCodelet继承自Stub
InterpreterMacroAssembler** _masm;
CodeBuffer _cb;
public:
// 构造函数
CodeletMark(
InterpreterMacroAssembler*& masm,
const char* description,
Bytecodes::Code bytecode = Bytecodes::_illegal):
// AbstractInterpreter::code()获取的是StubQueue*类型的值,调用request()方法获取的
// 是Stub*类型的值,调用的request()方法实现在vm/code/stubs.cpp文件中
_clet( (InterpreterCodelet*)AbstractInterpreter::code()->request(codelet_size()) ),
_cb(_clet->code_begin(), _clet->code_size())
{
// 初始化InterpreterCodelet中的_description和_bytecode属性
_clet->initialize(description, bytecode);
// InterpreterMacroAssembler->MacroAssembler->Assembler->AbstractAssembler
// 通过传入的cb.insts属性的值来初始化AbstractAssembler的_code_section与_oop_recorder属性的值
// create assembler for code generation
masm = new InterpreterMacroAssembler(&_cb); // 在构造函数中,初始化r13指向bcp、r14指向本地局部变量表
_masm = &masm;
}
// ... 省略析构函数
};
在构造函数中主要完成2个任务:
(1)初始化InterpreterCodelet类型的变量_clet。对InterpreterCodelet实例中的3个属性赋值;
(2)创建一个InterpreterMacroAssembler实例并赋值给masm与_masm,此实例会通过CodeBuffer向InterpreterCodelet实例写入机器指令。
在析构函数中,通常在代码块结束时会自动调用析构函数,在析构函数中完成InterpreterCodelet使用的内存的提交并清理相关变量的值。
1、CodeletMark构造函数
在CodeletMark构造函数会从StubQueue中为InterpreterCodelet分配内存并初始化相关变量
在初始化_clet变量时,调用AbstractInterpreter::code()方法返回AbstractInterpreter类的_code属性的值,这个值在之前TemplateInterpreter::initialize()方法中已经初始化了。继续调用StubQueue类中的request()方法,传递的就是要求分配的用来存储code的大小,通过调用codelet_size()函数来获取,如下:
int codelet_size() {
// Request the whole code buffer (minus a little for alignment).
// The commit call below trims it back for each codelet.
int codelet_size = AbstractInterpreter::code()->available_space() - 2*K;
return codelet_size;
}
需要注意,在创建InterpreterCodelet时,会将StubQueue中剩下的几乎所有可用的内存都分配给此次的InterpreterCodelet实例,这必然会有很大的浪费,不过我们在析构函数中会按照InterpreterCodelet实例的实例大小提交内存的,所以不用担心浪费这个问题。这么做的主要原因就是让各个InterpreterCodelet实例在内存中连续存放,这样有一个非常重要的应用,那就是只要简单通过pc判断就可知道栈帧是否为解释栈帧了,后面将会详细介绍。
通过调用StubQueue::request()函数从StubQueue中分配内存。函数的实现如下:
Stub* StubQueue::request(int requested_code_size) {
Stub* s = current_stub();
int x = stub_code_size_to_size(requested_code_size);
int requested_size = round_to( x , CodeEntryAlignment); // CodeEntryAlignment=32
// 比较需要为新的InterpreterCodelet分配的内存和可用内存的大小情况
if (requested_size <= available_space()) {
if (is_contiguous()) { // 判断_queue_begin小于等于_queue_end时,函数返回true
// Queue: |...|XXXXXXX|.............|
// ^0 ^begin ^end ^size = limit
assert(_buffer_limit == _buffer_size, "buffer must be fully usable");
if (_queue_end + requested_size <= _buffer_size) {
// code fits in(适应) at the end => nothing to do
CodeStrings strings;
stub_initialize(s, requested_size, strings);
return s; // 如果够的话就直接返回
} else {
// stub doesn't fit in at the queue end
// => reduce buffer limit & wrap around
assert(!is_empty(), "just checkin'");
_buffer_limit = _queue_end;
_queue_end = 0;
}
}
}
// ...
return NULL;
}
通过如上的函数,我们能够清楚看到如何从StubQueue中分配InterpreterCodelet内存的逻辑。
首先计算此次需要从StubQueue中分配的内存大小,调用的相关函数如下:
调用的stub_code_size_to_size()函数的实现如下:
// StubQueue类中定义的函数
int stub_code_size_to_size(int code_size) const {
return _stub_interface->code_size_to_size(code_size);
}
// InterpreterCodeletInterface类中定义的函数
virtual int code_size_to_size(int code_size) const {
return InterpreterCodelet::code_size_to_size(code_size);
}
// InterpreterCodelet类中定义的函数
static int code_size_to_size(int code_size) {
// CodeEntryAlignment = 32
// sizeof(InterpreterCodelet) = 32
return round_to(sizeof(InterpreterCodelet), CodeEntryAlignment) + code_size;
}
通过如上的分配内存大小的方式可知内存结构如下:
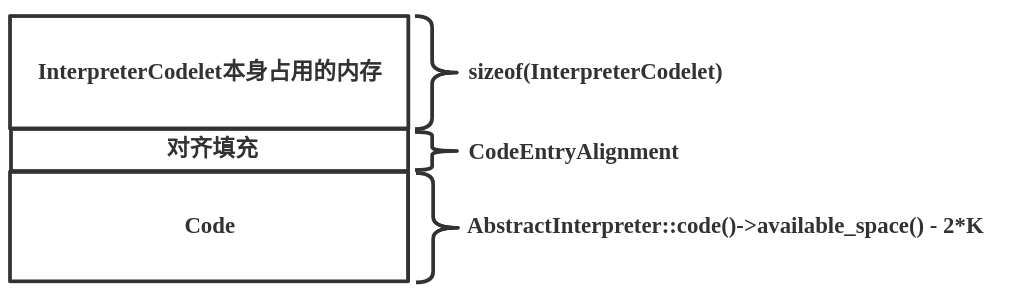
在StubQueue::request()函数中计算出需要从StubQueue中分配的内存大小后,下面进行内存分配。StubQueue::request()函数只给出了最一般的情况,也就是假设所有的InterpreterCodelet实例都是从StubQueue的_stub_buffer地址开始连续分配的。is_contiguous()函数用来判断区域是否连续,实现如下:
bool is_contiguous() const {
return _queue_begin <= _queue_end;
}
调用的available_space()函数得到StubQueue可用区域的大小,实现如下:
// StubQueue类中定义的方法
int available_space() const {
int d = _queue_begin - _queue_end - 1;
return d < 0 ? d + _buffer_size : d;
}
调用如上函数后得到的大小为下图的黄色区域部分。

继续看StubQueue::request()函数,当能满足此次InterpreterCodelet实例要求的内存大小时,会调用stub_initialize()函数,此函数的实现如下:
// 下面都是通过stubInterface来操作Stub的
void stub_initialize(Stub* s, int size,CodeStrings& strings) {
// 通过_stub_interface来操作Stub,会调用s的initialize()函数
_stub_interface->initialize(s, size, strings);
}
// 定义在InterpreterCodeletInterface类中函数
virtual void initialize(Stub* self, int size,CodeStrings& strings){
cast(self)->initialize(size, strings);
}
// 定义在InterpreterCodelet类中的函数
void initialize(int size,CodeStrings& strings) {
_size = size;
}
我们通过StubInterface类中定义的函数来操作Stub,至于为什么要通过StubInterface来操作Stub,就是因为Stub实例很多,所以为了避免在Stub中写虚函数(C++中对含有虚函数的类需要分配一个指针的空间指向虚函数表)浪费内存空间而采取的办法。
如上3个函数最终只完成了一件事儿,就是将此次分配到的内存大小记录在InterpreterCodelet的_size属性中。前面在介绍函数codelet_size()时提到过,这个值在存储了机器指令片段后通常还会空余很多空间,不过不要着急,下面要介绍的析构函数会根据InterpreterCodelet实例中实际生成的机器指令的大小更新这个属性值。
2、CodeletMark析构函数
析构函数的实现如下:
// 析构函数
~CodeletMark() {
// 对齐InterpreterCodelet
(*_masm)->align(wordSize);
// 确保生成的所有机器指令片段都存储到了InterpreterCodelet实例中
(*_masm)->flush();
// 更新InterpreterCodelet实例的相关属性值
AbstractInterpreter::code()->commit((*_masm)->code()->pure_insts_size(), (*_masm)->code()->strings());
// 设置_masm,这样就无法通过这个值继续向此InterpreterCodelet实例中生成机器指令了
*_masm = NULL;
}
调用AbstractInterpreter::code()函数获取StubQueue。调用(*_masm)->code()->pure_insts_size()获取的就是InterpreterCodelet实例的机器指令片段实际需要的内存大小。
StubQueue::commit()函数的实现如下:
void StubQueue::commit(int committed_code_size, CodeStrings& strings) {
int x = stub_code_size_to_size(committed_code_size);
int committed_size = round_to(x, CodeEntryAlignment);
Stub* s = current_stub();
assert(committed_size <= stub_size(s), "committed size must not exceed requested size");
stub_initialize(s, committed_size, strings);
_queue_end += committed_size;
_number_of_stubs++;
}
调用stub_initialize()函数通过InterpreterCodelet实例的_size属性记录此实例中机器指令片段实际内存大小。同时更新StubQueue的_queue_end和_number_of_stubs属性的值,这样就可以为下次InterpreterCodelet实例继续分配内存了。
公众号 深入剖析Java虚拟机HotSpot 已经更新虚拟机源代码剖析相关文章到60+,欢迎关注,如果有任何问题,可加作者微信mazhimazh,拉你入虚拟机群交流


