
虚拟机执行模式
在HotSpot里面,代码执行有两种模式:
- 直接解释指令:这使用的是HotSpot的解释引擎,它采用模板解释,将每一条指令直接翻译成本地代码,而后由硬件直接执行;
- 编译执行:是指,将代码直接翻译成本地代码执行,这就是耳熟能详的JIT编译器,更加准确的说是HotSpot Compiler;
HotSpot虚拟机可以配置为以下运行模式:
- -Xint:解释模式
- -Xcomp:编译模式
- -Xmixed:混合模式
通过java -version就可以查看虚拟机的运行模式,如下:
OpenJDK 64-Bit Server VM (build 25.0-b70-debug, mixed mode)
JIT的运行模式有两种:client模式和server模式。这两种模式采用的编译器是不一样的,client模式采用的是代号为C1的轻量级编译器,特点是启动快,但是编译不够彻底;而server模式采用的是代号为C2的编译器,特点是启动比较慢,但是编译比较彻底,所以一旦服务起来后,性能更高。
用户可以使用 -client 和 -server 参数强制指定虚拟机运行在 Client 模式或者 Server 模式。这种配合使用的方式称为“混合模式”(Mixed Mode),用户可以使用参数 -Xint 强制虚拟机运行于 “解释模式”(Interpreted Mode),这时候编译器完全不介入工作。另外,使用 -Xcomp 强制虚拟机运行于 “编译模式”(Compiled Mode),这时候将优先采用编译方式执行,但是解释器仍然要在编译无法进行的情况下接入执行过程。
Oracle JDK6u25之后引入了分层编译(对应参数 -XX:+TieredCompilation)的概念,综合了 C1 的启动性能优势和 C2 的峰值性能优势。如果需要关闭分层编译,需要加上启动参数-XX:-TieredCompilation
分层编译将 Java 虚拟机的执行状态分为了五个层次。为了方便阐述,我用“C1 代码”来指代由 C1 生成的机器码,“C2 代码”来指代由 C2 生成的机器码。五个层级分别是:
-
第0层(解释层)启动:这一层主要是提供了一些比较关键性方法的性能,快速进入C1层。
-
第1层(C1编译器):通过上一层提供的一些关键方法的性能信息来优化这些代码。本层不包含性能优化的信息。
-
第2层:基于C1编译器优化的结果来处理的,此时会有少数方法通过C1编译器的编译,在本层会为这些少数方法的调用次数和循环分支执行情况,收集它们的性能分析信息。
-
第3层:得到C1编译器编译的所有方法以及对所有的性能优化信息
-
第4层:只对C2编译器有效。
关于分层编译有关文章:https://book.douban.com/annotation/31392220/
通常情况下,C2 代码的执行效率要比 C1 代码的高出 30% 以上。然而,对于 C1 代码的三种状态,按执行效率从高至低则是 1 层 > 2 层 > 3 层。
其中 1 层的性能比 2 层的稍微高一些,而 2 层的性能又比 3 层高出 30%。这是因为 profiling 越多,其额外的性能开销越大。
在 5 个层次的执行状态中,1 层和 4 层为终止状态。当一个方法被终止状态编译过后,如果编译后的代码并没有失效,那么 Java 虚拟机是不会再次发出该方法的编译请求的。
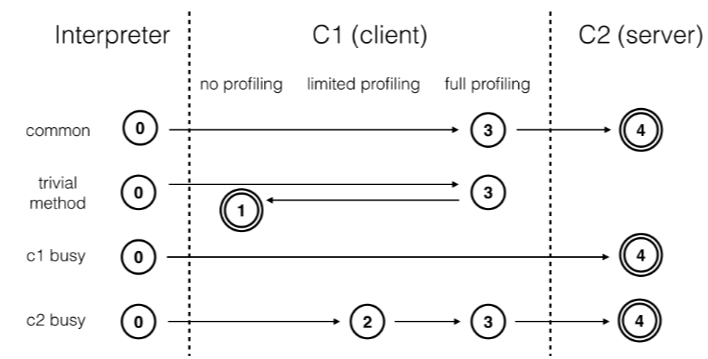
这里我列举了 4 个不同的编译路径(Igor 的演讲列举了更多的编译路径)。通常情况下,热点方法会被 3 层的 C1 编译,然后再被 4 层的 C2 编译。
如果方法的字节码数目比较少(如 getter/setter),而且 3 层的 profiling 没有可收集的数据。
那么,Java 虚拟机断定该方法对于 C1 代码和 C2 代码的执行效率相同。在这种情况下,Java 虚拟机会在 3 层编译之后,直接选择用 1 层的 C1 编译。由于这是一个终止状态,因此 Java 虚拟机不会继续用 4 层的 C2 编译。
在 C1 忙碌的情况下,Java 虚拟机在解释执行过程中对程序进行 profiling,而后直接由 4 层的 C2 编译。在 C2 忙碌的情况下,方法会被 2 层的 C1 编译,然后再被 3 层的 C1 编译,以减少方法在 3 层的执行时间。
Java 8 默认开启了分层编译。不管是开启还是关闭分层编译,原本用来选择即时编译器的参数 -client 和 -server 都是无效的。当关闭分层编译的情况下(指定-XX:-TieredCompilation),Java 虚拟机将直接采用 C2。
如果你希望只是用 C1,那么你可以在打开分层编译的情况下使用参数 -XX:TieredStopAtLevel=1。在这种情况下,Java 虚拟机会在解释执行之后直接由 1 层的 C1 进行编译。
相关文章的链接如下:
1、在Ubuntu 16.04上编译OpenJDK8的源代码
13、类加载器
14、类的双亲委派机制
15、核心类的预装载
16、Java主类的装载
17、触发类的装载
18、类文件介绍
19、文件流
20、解析Class文件
21、常量池解析(1)
22、常量池解析(2)
23、字段解析(1)
24、字段解析之伪共享(2)
25、字段解析(3)
28、方法解析
29、klassVtable与klassItable类的介绍
30、计算vtable的大小
31、计算itable的大小
32、解析Class文件之创建InstanceKlass对象
33、字段解析之字段注入
34、类的连接
35、类的连接之验证
36、类的连接之重写(1)
37、类的连接之重写(2)
38、方法的连接
39、初始化vtable
40、初始化itable
41、类的初始化
42、对象的创建
43、Java引用类型
50、CallStub栈帧
52、generate_fixed_frame()方法生成Java方法栈帧
作者持续维护的个人博客 classloading.com。
关注公众号,有HotSpot源码剖析系列文章!


