

深度学习笔记010WeightDecay权重衰退
权重衰退——最常见的处理过拟合的方法
通过限制参数的选择范围来控制模型容量
对于权重W和偏移b,让||W||² <= θ
小的θ意味着更强的正则项
通常不限制b,限不限制都差不多
因为W越大,往往对噪声的放大就更大,所以我们需要适当限制W大小,达到控制噪音的目的,也就解决了过拟合问题。
但通常不直接用上面的式子,而是:


加入的一项通常叫做罚,penalty
想要模型复杂度降低,直接增加拉马达即可。
正则化:能够减少泛化误差的方法都叫正则。
下图的前导知识如下:
理解正则化很棒的视频:https://www.bilibili.com/video/BV1Z44y147xA?spm_id_from=333.999.0.0
理解梯度:https://blog.csdn.net/keeppractice/article/details/105620966
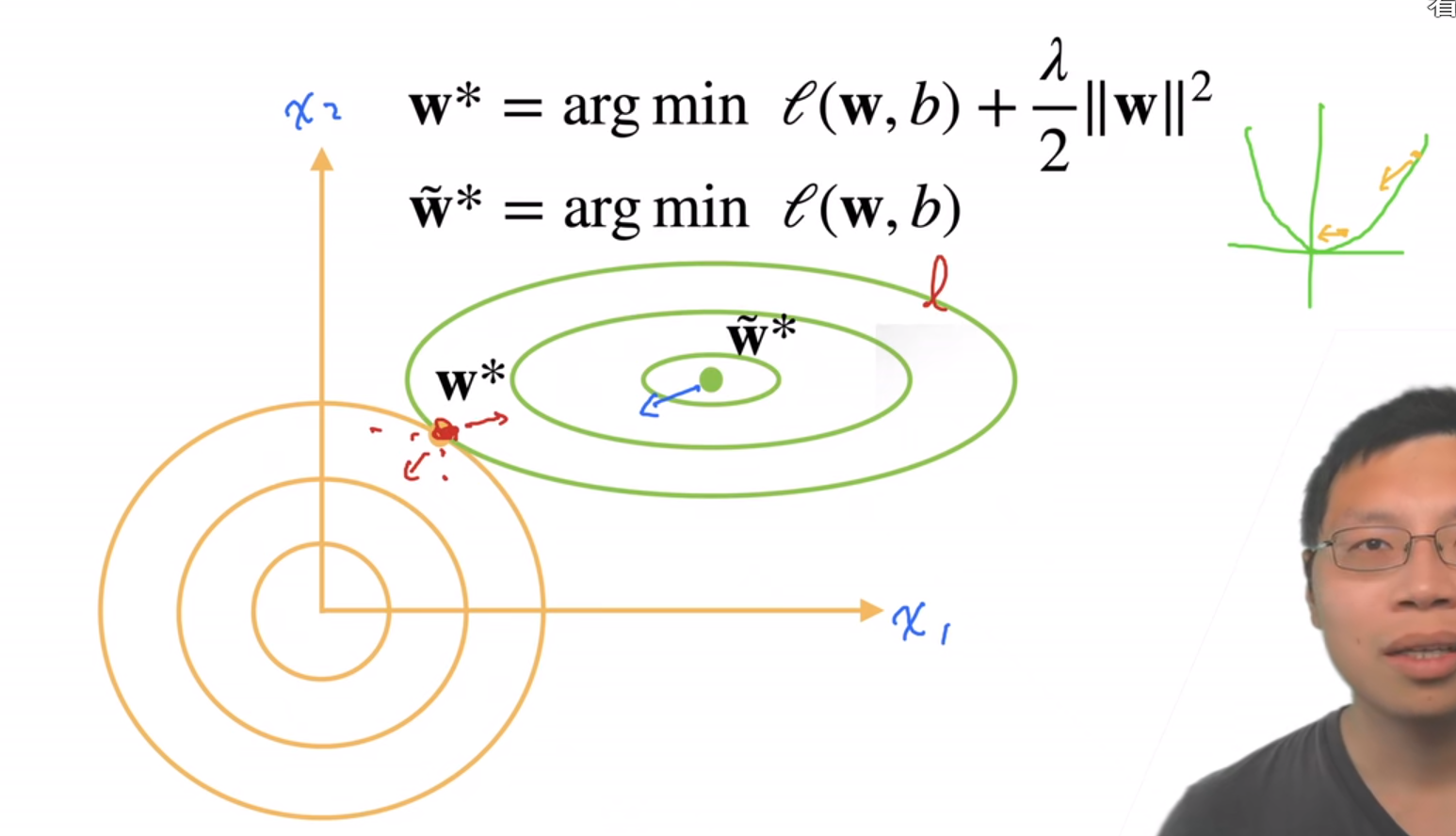
加入这个罚penalty,画出penalty的图像,可以看到我们将W的范围限制到了原点周围的圆里,这样就相当于把W往原点附近拉扯,W就会变小,模型容量就会降低,从而模型的泛化能力就会得到提升,从而模型的过拟合问题会得到缓解。

为什么叫权重衰退?
因为我们每次更新梯度之前,会在1上减去一个ηλ,来缩小当前权重,也就是认为有一次衰退。
Q&A:
1、权重衰退作用很有限,不要过于依赖。
2、Weight_decay常取1e-2,1e-3,1e-4
3、噪音越大,W越大。所以限制W的大小就会限制噪音的污染。
1 import torch 2 from torch import nn 3 from d2l import torch as d2l 4 5 n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5 6 true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05 7 train_data = d2l.synthetic_data(true_w, true_b, n_train) 8 train_iter = d2l.load_array(train_data, batch_size) 9 test_data = d2l.synthetic_data(true_w, true_b, n_test) 10 test_iter = d2l.load_array(test_data, batch_size, is_train=False) 11 12 def init_params(): 13 w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True) 14 b = torch.zeros(1, requires_grad=True) 15 return [w, b] 16 17 def l2_penalty(w): 18 return torch.sum(w.pow(2))/2 #/2是为了求导之后W系数是1 19 20 #尝试一下这里用L1范数 21 def l1_penalty(w): 22 return torch.sum(torch.abs(w)) 23 24 def train(lambd): 25 #初始化W和b 26 w, b = init_params() 27 # 定义了一个线性回归的net,loss选的是平方损失,lambda X是匿名函数 28 net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss 29 num_epochs, lr = 100, 0.003 30 # 动画化,但是在pycharm里应该没什么价值 31 animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log', 32 xlim=[5, num_epochs], legend=['train', 'test']) 33 for epoch in range(num_epochs): 34 for X, y in train_iter: 35 # 增加了L2范数惩罚项, 36 # 广播机制使l2_penalty(w)成为一个长度为batch_size的向量 37 #l = loss(net(X), y) + lambd * l2_penalty(w) 38 #尝试一下用L1 39 l = loss(net(X), y) + lambd * l2_penalty(w) 40 l.sum().backward() 41 d2l.sgd([w, b], lr, batch_size) 42 if (epoch + 1) % 5 == 0: 43 animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss), 44 d2l.evaluate_loss(net, test_iter, loss))) 45 print('w的L2范数是:', torch.norm(w).item()) 46 d2l.plt.show() 47 48 49 train(lambd=6) 50 51 52 #简洁实现: 53 54 55 56 def train_concise(wd): 57 net = nn.Sequential(nn.Linear(num_inputs, 1)) 58 for param in net.parameters(): 59 param.data.normal_() 60 loss = nn.MSELoss(reduction='none') 61 num_epochs, lr = 100, 0.003 62 # 偏置参数没有衰减 63 trainer = torch.optim.SGD([ 64 {"params":net[0].weight,'weight_decay': wd}, 65 {"params":net[0].bias}], lr=lr) 66 animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log', 67 xlim=[5, num_epochs], legend=['train', 'test']) 68 for epoch in range(num_epochs): 69 for X, y in train_iter: 70 trainer.zero_grad() 71 l = loss(net(X), y) 72 l.mean().backward() 73 trainer.step() 74 if (epoch + 1) % 5 == 0: 75 animator.add(epoch + 1, 76 (d2l.evaluate_loss(net, train_iter, loss), 77 d2l.evaluate_loss(net, test_iter, loss))) 78 print('w的L2范数:', net[0].weight.norm().item()) 79 d2l.plt.show() 80 81 #train_concise(10)
结论:
首先我们将weight decay取为0,3,6,分别如下:
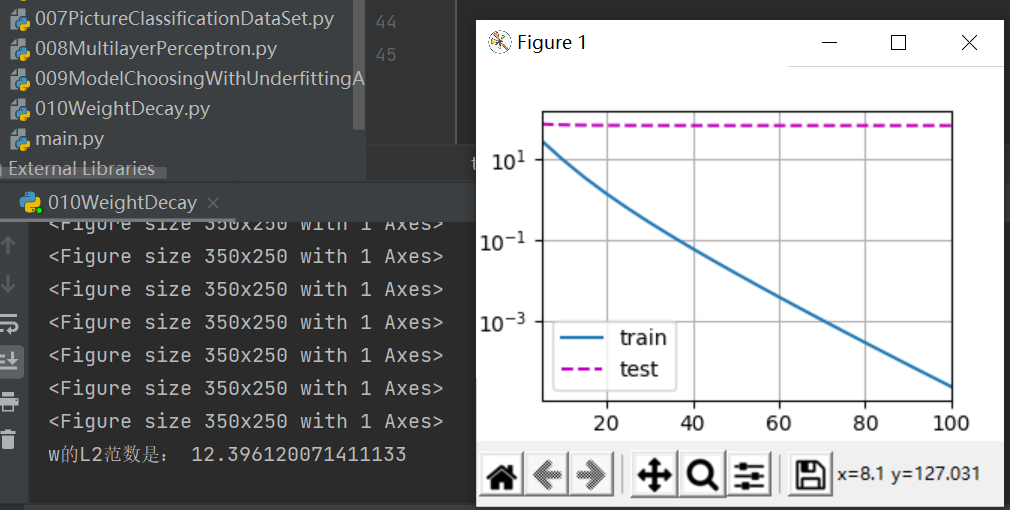
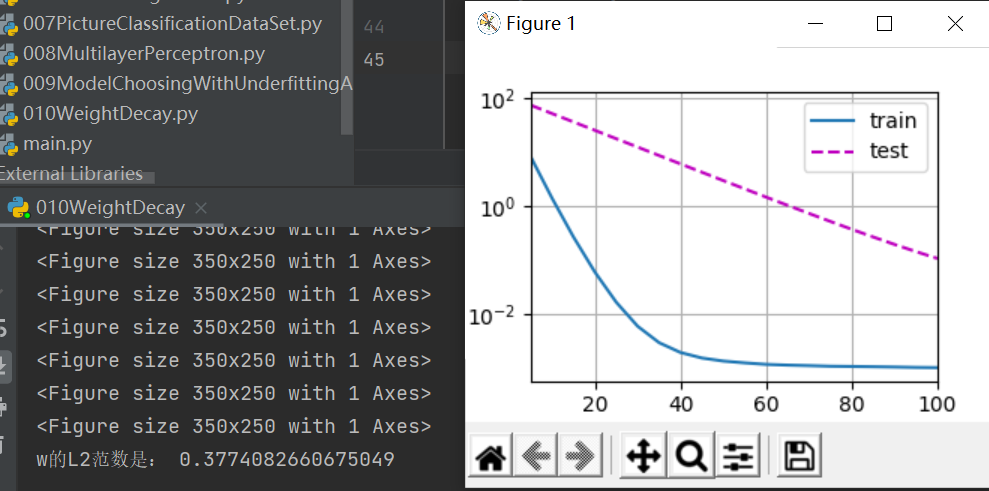
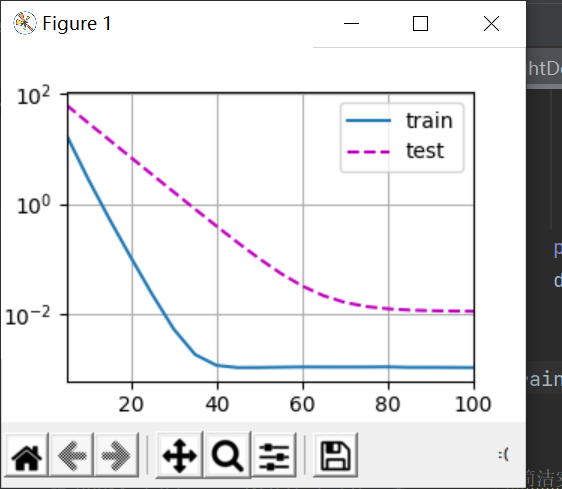
W最优解为0.01,但是可以看到取0的时候,完全拟合了训练数据,而测试数据基本没有动静,这是最极端的过拟合;取3的时候对测试数据有了一些反应;取6的时候可以看到,测试数据收敛到了一个不错的值,所以这个过拟合能很不错地用权重衰退法解决。
好奇L1什么样子,于是将代码中加入了一个L1范式,取λ为6,结果如下:
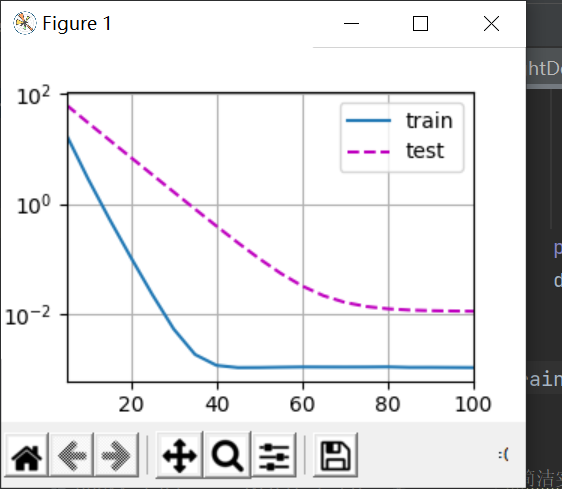
好像差不多hhhh。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号