

伪分布式Hadoop集群
单机模式(Standalone )
hadoop默认情况是以非分布式单机方式运行的,所有的Hadoop服务都是运行在一个JVM虚拟机上,这种模式下Hadoop采用操作系统本地文件而不是HDFS(Hadoop File System)进行数据的存储。
伪分布式(Pseudo-Distributed )
模式可以模拟真实多节点集群,可以让Hadoop守护进程(DataNode、NameNode和ResourceManager)运行在单一服务器上,意味着这种单节点的Hadoop集群无法保证高可用性与数据的安全性,生产环境不推荐使用。
全分布式(Fully-Distributed)
Hadoop守护进程(DataNode、NameNode和ResourceManager)在不同的机器上运行,这种模式可以保证Hadoop集群的高可用性、数据安全性。常应用在生产环境中。
SSH免密登录设置
Hadoop应用提供了很多脚本用来管理和维护Hadoop守护进程,这其中就用了SSH登录相关命令
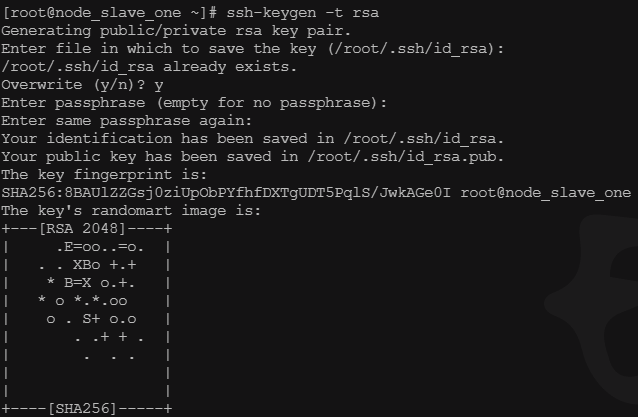
生成SSH密钥
## 生成密钥命令:ssh-keygen -t rsa
拷贝公钥

使用ssh免密登录本地

相关配置文件
Hadoop为启动和停止Hadoop应用提供了以上三个环境变量脚本,其中 hadoop-env.sh用来设置hadoop运行环境相关的配置mapred-env.sh用来指定mapReduce操作环境相关配置、yarn-env.sh是用来指定yarn使用的环境变量的值。
没有在自定义配置文件中配置参数对应的值,则默认以xx.default.xml配置的值为准,否则以自定义xx.site的值为准
core-default.xml:hadoop核心配置文件,可以在core-site.xml中设置变量来覆盖此文件的默认配置值。
hdfs-default.xml :HDFS相关服务的默认配置文件,可以设置hdfs-site.xml覆盖此文件中的默认配置值。
yarn-default.xml:YARN默认配置文件,可以设置yarn-site.xml覆盖此文件中默认配置值。
mapred-default.xml:MapReduce默认配置文件,可以设置mapred-site.xml覆盖此文件中默认配置值。
配置Hadoop核心属性(core-site.xml)
- fs.defaultFS:设置文件系统的名称以及NameNode所在主机和端口信息
<property>
<name>fs.defaultFS</name>
<value>hdfs://node_slave_one:9000</value>
<description>hdfs内部通讯访问地址</description>
</property>
- hadoop.http.staticuser.user 设置操作hdfs为用户为hdfs
<property> <name>hadoop.http.staticuser.user</name> <value>hdfs</value> </property>
- hadoop.tmp.dir 设置hadoop本地数据存储目录
<property> <name>hadoop.tmp.dir</name> <value>/soft/data/hadoop/tmpDir</value> </property>
- fs.trash.interval
设置Hadoop文件存储在垃圾箱中的时间,默认值为0,即永久删除被删除的所有文件库,这里我们默认设置1440分钟(1天)
<property> <name>fs.trash.interval</name> <value>1440</value> </property>
配置Mapreduce(mapred-site.xml)
- mapreduce.framework.name 设置hadoop使用YARN作为执行MapReduce的框架
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
- yarn.app.mapreduce.am.env 指定mapruce APP MASTER 环境变量
<property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property>
- mapreduce.map.env 指定mapreduce Reuce Task 环境变量
<property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property>
- mapreduce.reduce.env 指定mapreduce Reuce Task 环境变量
<property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property>
配置Yarn(yarn-site.xml)
yarn.nodemanager.aux-services:此属性可以让NodeManager指定MapReduce容器从map任务到reduce任务所需要执行的shuffle操作,只有设置了这个值才可以运行MapReduce任务。
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
- yarn.nodemanager.aux-services.mapreduce_shuffle.class
设置YARN使用这个设置值对应的类执行shuffle操作
<property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property>
- yarn.nodemanager.resource.memory-mb 设置YARN在每一个节点消耗的总内存值单位MB
<property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property>
- yarn.scheduler.minimum-allocation-mb 设置每一个启动的容器节点最小内存单位MB
<property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property>
配置HDFS(hdfs-site.xml)
- dfs.namenode.secondary.http-address 设置SecondaryNameNode运行主机和端口
<property> <name>dfs.namenode.secondary.http-address</name> <value>node_slave_one:9868</value> </property>
- dfs.replication 参数配置默认的文件块数量为3,但我们这里搭建伪分布式所以需要设置为1
<property> <name>dfs.replication</name> <value>1</value> </property>
- dfs.datanode.data.dir 设置DataNode数据快本地存储目录
<property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hdfs/data</value> </property>
- dfs.namenode.name.dir 设置NameNode核心文件如fsimage如edit日志文件存储位置,只有NameNode服务可以读取和写入这些文件。
<property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hdfs/name</value> </property>
- dfs.namenode.checkpoint.dir 指定SecondaryNameNode存储元数据文件位置
<property> <name>dfs.namenode.checkpoint.dir</name> <value>file:/soft/data/hadoop/hdfs/snn</value> </property>
-
修改worker
[root@slaveone hadoop-3.3.2]# cat etc/hadoop/workers slaveone
- 对于start-dfs.sh和stop-dfs.sh添加下列参数:
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
- 对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
格式化集群
使用hdfs用户执行NameNode格式化,需要注意的是NameNode的格式化只需要做一次就够。
hdfs namenode -format

 浙公网安备 33010602011771号
浙公网安备 33010602011771号