
python爬虫课程网络设计(中国各省疫情累计确诊人数分析,疫情地图.词云.柱状图)
一.选题背景
选此题的目的:社会背景层面是针对2019年以来新冠肺炎疫情在我国起始出现,希望可以使人们意识到此次疫情的来势汹涌迅速以及严重性,对各省感染人数做出较为详细的地图化展示,引起人们们的重视,增强防疫的意识与措施。
经济层面:对各省疫情的确诊人数的分析,进一步确定对防疫战略的部署与规划,增加资源利用
技术层面:选此题符合自己的学习层面,
数据来源方面:
数据分析的预期目标是使人更加直观的看出疫情的实时动态
二.题式网络爬虫设计方案
1.主题是网络爬虫名称
基于爬虫的百度实时疫情下的中国疫情地图(数据可视化)
2.
3.爬虫方案概述
(1)针对百度实时疫情更新的网站进行数据爬取(2)进行数据的清洗,对要用的数据进行定位和提取(3)传入数据,运用pyecharts的地图绘制模块进行疫情地图的绘制。
三.主题页面的结构特征分析
1.主题页面的结构与特征分析
Request URL:这是我们点击翻译后,真正访问的网址,所以这是我们写爬虫真正要访问的URL。本项爬取网站url= https://voice.baidu.com/act/newpneumonia/newpneumonia
User-Agent:这是我们访问这个网站所用的身份标识,我们在写爬虫时最好在requests的headers参数里带上这个标识
Accept:这是服务器返回内容的简要信息
Form Data:这是我们传递给服务器的内容,可以发现,这就是我们填写的需翻译内容,以及翻译的源语种和目标语种。
2.Htmls页面解析
每一个省的名称与对应的疫情数据都在一个td下
多少个省份就有多少个对应的td
scrapt标签type属性对应的值为'appliction'
3节点(标签)查找方法和遍历方法
运用xpxh方法解析html中的城市名称以及人数
1 html = etree.HTML(text) 2 result = html.xpath('//script[@type="application/json"]/text()')
运用正则表达式匹配数据更新的时间
1 time = re.findall('"mapLastUpdatedTime":"(.*?)"',text)[0]
四.网络爬虫程序设计
1.数据爬取与采集
1 import requests 2 from lxml import etree 3 import re 4 import json 5 class Get_data(): 6 #获取数据 7 def get_data(self): 8 response = requests.get('https://voice.baidu.com/act/newpneumonia/newpneumonia') 9 with open('heml.txt','w') as file: 10 file.write(response.text)
2.对数据进行清洗和处理
1 def get_time(self): 2 #提取更新时间 3 with open('heml.txt','r') as file: 4 text = file.read() 5 time = re.findall('"mapLastUpdatedTime":"(.*?)"',text)[0] 6 return time 7 8 9 #解析数据(第一次的数据粗提取) 10 def parse_data(self): 11 with open('heml.text','r')as file: 12 text = file.read() 13 html = etree.HTML(text) 14 result = html.xpath('//script[@type="application/json"]/text()') 15 #print(result) 16 result = result[0] 17 result =json.loads(result) 18 result = result['component'][0]['caseList'] 19 #将python的数据类型转换成字符串 20 result = json.dumps(result) 21 with open('data.json','w') as file: 22 file.write(result) 23 print('数据已写入python文件...') 24 25 数据的第二次清洗(转换数据格式,并保证数据与名称对应) 26 import json 27 import map_draw 28 import get_data3 29 with open('data.json','r') as file: 30 data = file.read() 31 #键值对的形式转换成python数据类型 32 data =json.loads(data) 33 map = map_draw.Draw_map() 34 datas = get_data3.Get_data() 35 datas.get_data() 36 update_time = datas.get_time() 37 datas.parse_data() 38 #(省份与数据的一一对应) 39 #中国疫情地图数据 40 def china_map(): 41 area = [] 42 confirmed = [] 43 for each in data: 44 print(each) 45 print('*'*50+'\n') 46 area.append(each['area']) 47 confirmed.append(each['confirmed']) 48 map.tp_map_china(area,confirmed,update_time) 49 #省份疫情数据 50 def province_map(): 51 for each in data: 52 city = [] 53 confirmeds =[] 54 province = ['area'] 55 for each_city in each['subList']: 56 city.append(each_city['city']) 57 confirmeds.append(each_city['confirmed']) 58 59 60 china_map()

3.文本分析
所有省份所对应的疫情数据都在一个表的内容里面, 爬取这个表下的内容数据就好。

每一个tr对应一个省份的疫情数据,爬取正确的div标签并用佛如循环遍历,之后再做更深的数据清洗。
4.数据分析与数据可视化
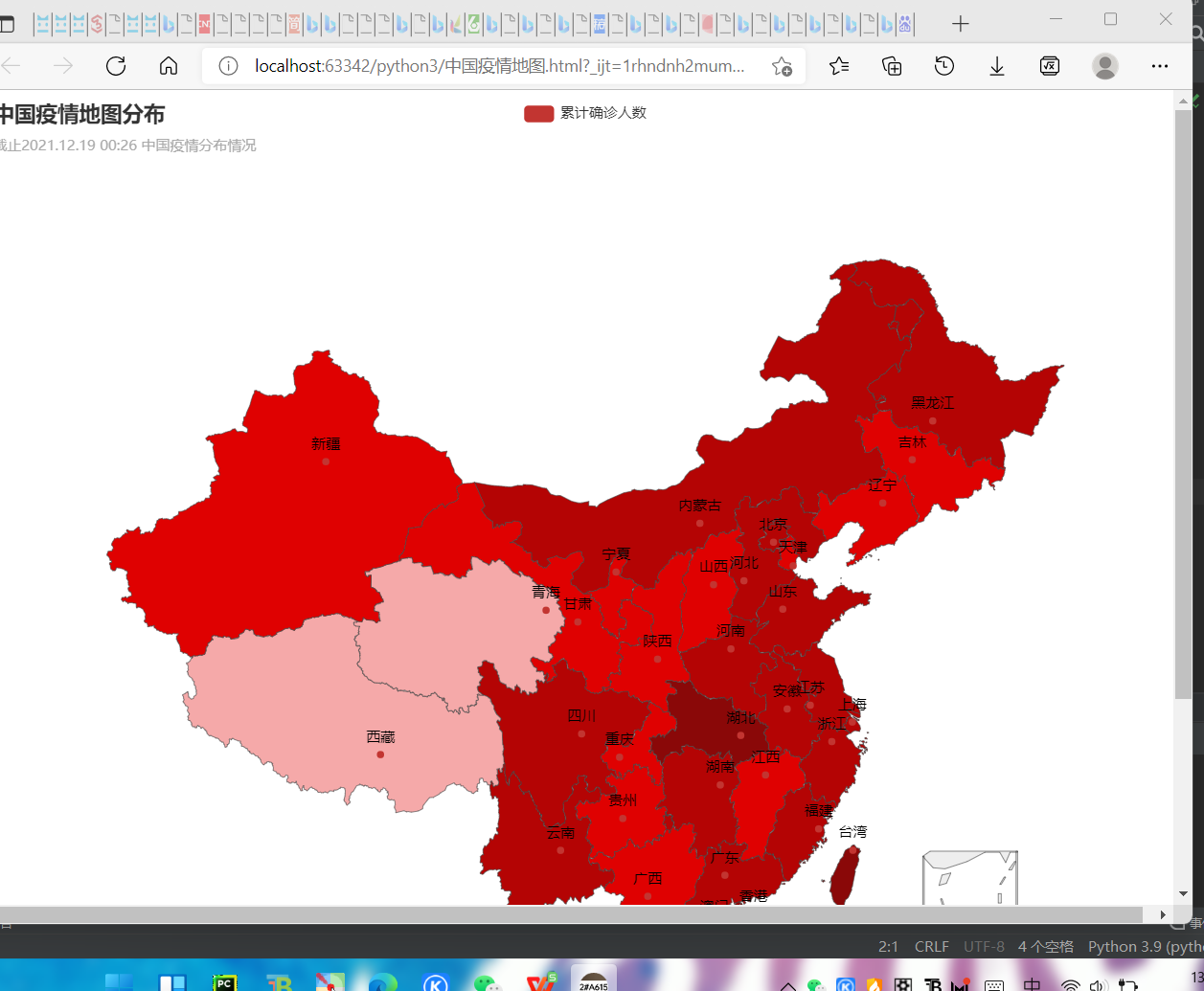
(1)中国疫情地图
from pyecharts import options as opts from pyecharts.charts import Map from pyecharts.faker import Faker class Draw_map(): def to_map_city(self): pass #网站中的画图方法 def tp_map_china(self,area,variate,update_time): pieces =[ {"max":99999999,'min':1001,'label':'>10000','color':'#8A0808'}, {"max": 9999, 'min': 1000, 'label': '10000-9999', 'color': '#B40404'}, {"max": 999, 'min': 100, 'label': '100-999', 'color': '#DF0101'}, {"max": 99, 'min': 10, 'label': '1-9', 'color': '#F5A9A9'}, {"max": 9, 'min': 1, 'label': '1-9', 'color': '#F5A9A9'}, {"max": 0, 'min': 0, 'label': '0', 'color': '#FFFFFF'} ] c = ( Map(init_opts=opts.InitOpts(width='1000px',height='880px')) .add("累计确诊人数", [list(z) for z in zip(area, variate)], "china") .set_global_opts( title_opts=opts.TitleOpts(title="中国疫情地图分布", subtitle='截止%s 中国疫情分布情况'%(update_time)), visualmap_opts=opts.VisualMapOpts(max_=200, is_piecewise=True,pieces=pieces), ) .render("中国疫情地图.html") )

在浏览器中运行以上文件得出疫情的图
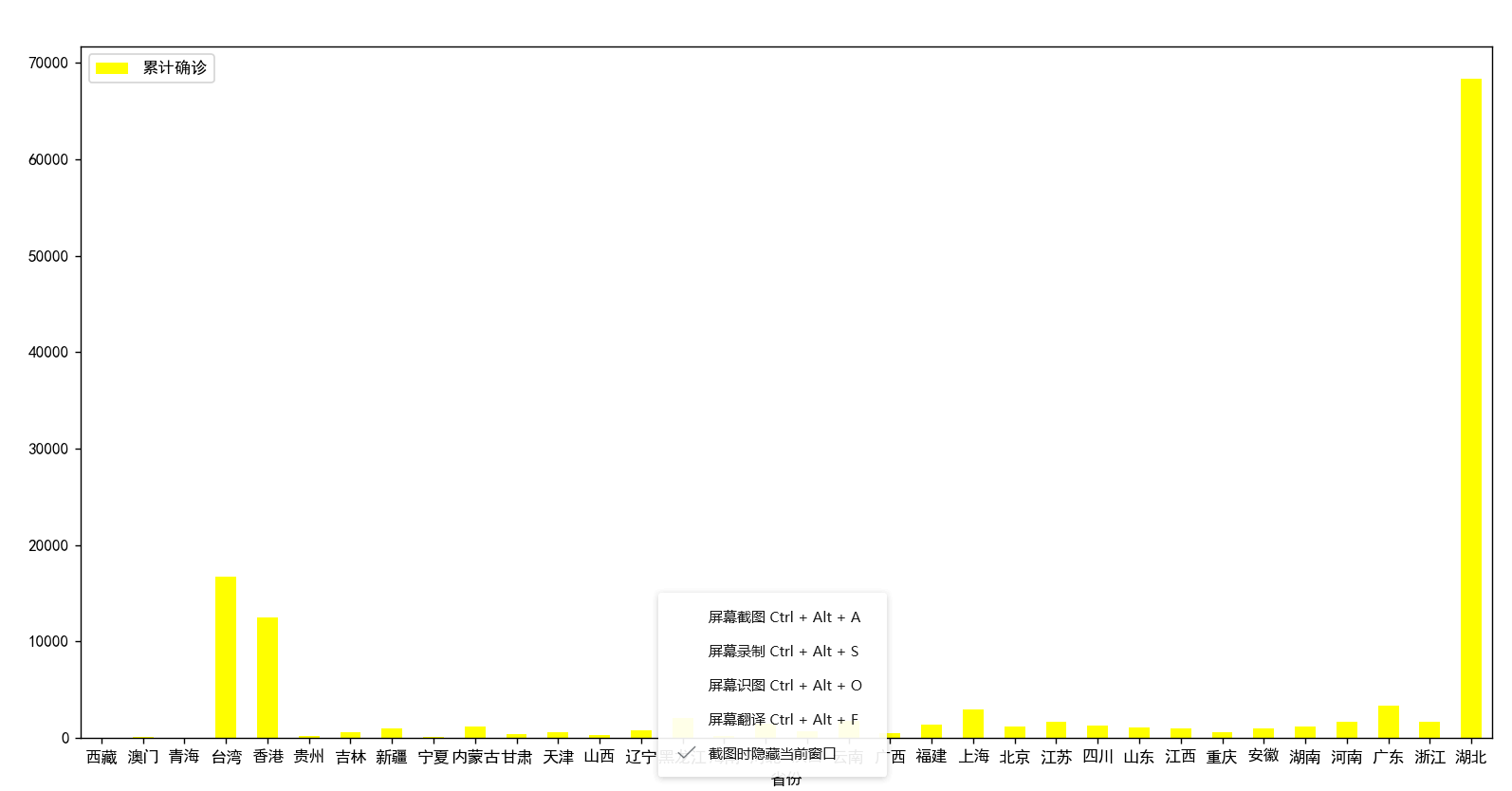
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程
import pandas as pd import matplotlib .pyplot as plt #文字设为中文(解决文字乱码) from matplotlib import rcParams rcParams['font.family'] = 'simhei' people = pd.read_excel('data.xalx') print(people) people.plot.bar(x='省份',y='累计确诊',color='yellow') plt.xticks(rotation=360) plt.show()
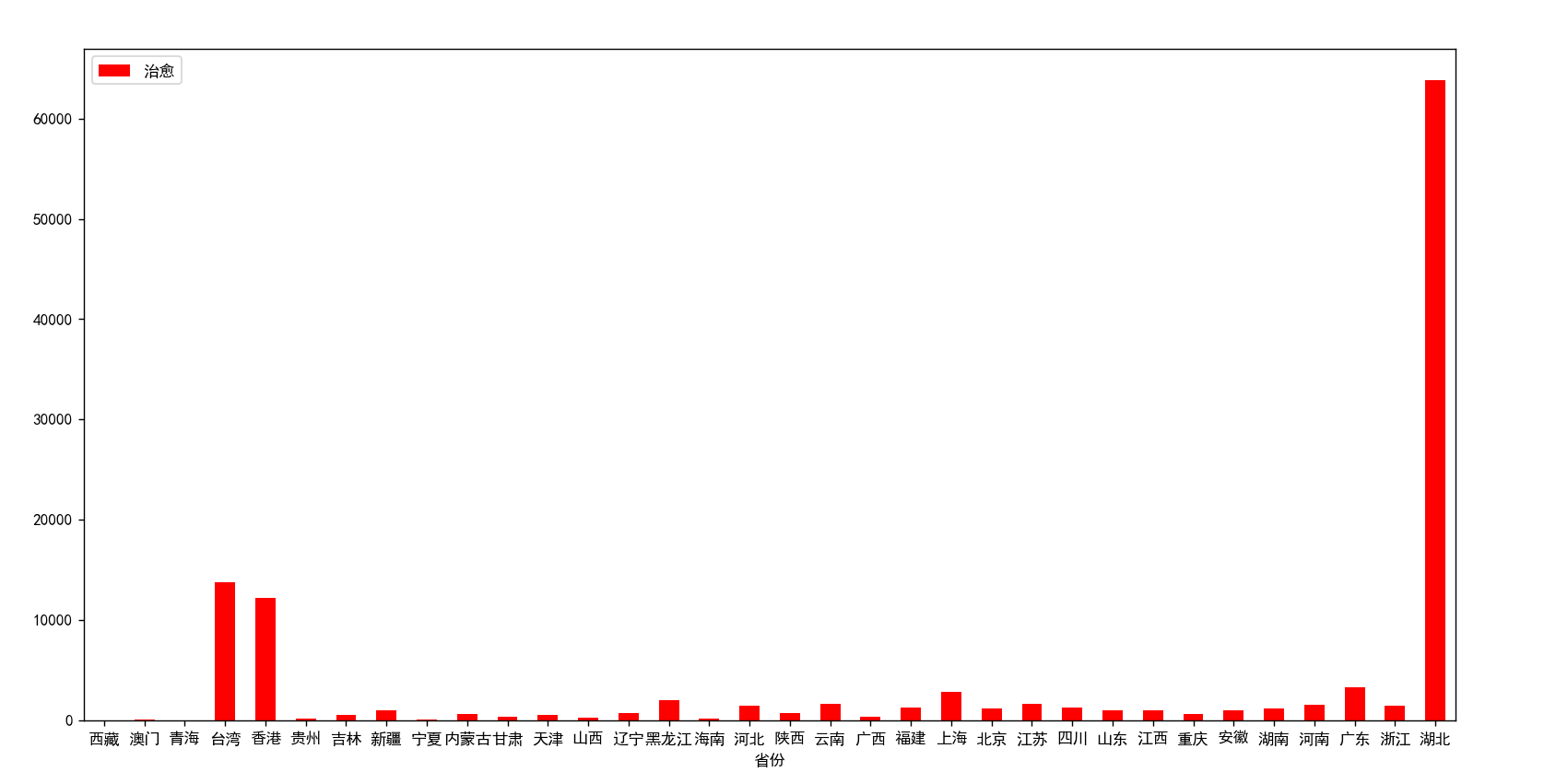
import pandas as pd import matplotlib .pyplot as plt #文字设为中文(解决文字乱码) from matplotlib import rcParams rcParams['font.family'] = 'simhei' people = pd.read_excel('data.xalx') print(people) people.plot.bar(x='省份',y='治愈',color='red') plt.xticks(rotation=360) plt.show()
import openpyxl import numpy import pandas as pd from wordcloud import WordCloud wb = openpyxl.load_workbook('data.xlsx') ws = wb['国内疫情'] frequency = {} for row in ws.values: if row[0] == '省份': pass else: frequency[row[0]] = float(row[1]) wordcloud = WordCloud(for_path="C:Windows/Fonts/ITCBLKAD.TTF", background_color="white", width=1929, height=1080) wordcloud.generate_from_frequencies(frequency) wordcloud.to_file('wordcloud.png')

6.数据持久化
调用模块 openpyxl进行数据的储存,导入数据到excel表格并生成excel文件。
7.代码会中,附上完整代码
1 import requests 2 from lxml import etree 3 import re 4 import json 5 class Get_data(): 6 #获取数据 7 def get_data(self): 8 response = requests.get('https://voice.baidu.com/act/newpneumonia/newpneumonia') 9 with open('heml.txt','w') as file: 10 file.write(response.text) 11 12 def get_time(self): 13 #提取更新时间 14 with open('heml.txt','r') as file: 15 text = file.read() 16 time = re.findall('"mapLastUpdatedTime":"(.*?)"',text)[0] 17 return time 18 19 20 #解析数据(第一次的数据粗提取) 21 def parse_data(self): 22 with open('heml.text','r')as file: 23 text = file.read() 24 html = etree.HTML(text) 25 result = html.xpath('//script[@type="application/json"]/text()') 26 #print(result) 27 result = result[0] 28 result =json.loads(result) 29 result = result['component'][0]['caseList'] 30 #将python的数据类型转换成字符串 31 result = json.dumps(result) 32 with open('data.json','w') as file: 33 file.write(result) 34 print('数据已写入python文件...') 35 import json 36 import map_draw 37 import get_data3 38 with open('data.json','r') as file: 39 data = file.read() 40 #键值对的形式转换成python数据类型 41 data =json.loads(data) 42 map = map_draw.Draw_map() 43 datas = get_data3.Get_data() 44 datas.get_data() 45 update_time = datas.get_time() 46 datas.parse_data() 47 #(省份与数据的一一对应) 48 #中国疫情地图数据 49 def china_map(): 50 area = [] 51 confirmed = [] 52 for each in data: 53 print(each) 54 print('*'*50+'\n') 55 area.append(each['area']) 56 confirmed.append(each['confirmed']) 57 map.tp_map_china(area,confirmed,update_time) 58 #省份疫情数据 59 def province_map(): 60 for each in data: 61 city = [] 62 confirmeds =[] 63 province = ['area'] 64 for each_city in each['subList']: 65 city.append(each_city['city']) 66 confirmeds.append(each_city['confirmed']) 67 68 69 china_map() 70 from pyecharts import options as opts 71 from pyecharts.charts import Map 72 from pyecharts.faker import Faker 73 74 class Draw_map(): 75 def to_map_city(self): 76 pass 77 #网站中的画图方法 78 def tp_map_china(self,area,variate,update_time): 79 pieces =[ 80 {"max":99999999,'min':1001,'label':'>10000','color':'#8A0808'}, 81 {"max": 9999, 'min': 1000, 'label': '10000-9999', 'color': '#B40404'}, 82 {"max": 999, 'min': 100, 'label': '100-999', 'color': '#DF0101'}, 83 {"max": 99, 'min': 10, 'label': '1-9', 'color': '#F5A9A9'}, 84 {"max": 9, 'min': 1, 'label': '1-9', 'color': '#F5A9A9'}, 85 {"max": 0, 'min': 0, 'label': '0', 'color': '#FFFFFF'} 86 87 88 ] 89 c = ( 90 Map(init_opts=opts.InitOpts(width='1000px',height='880px')) 91 .add("累计确诊人数", [list(z) for z in zip(area, variate)], "china") 92 .set_global_opts( 93 title_opts=opts.TitleOpts(title="中国疫情地图分布", subtitle='截止%s 中国疫情分布情况'%(update_time)), 94 visualmap_opts=opts.VisualMapOpts(max_=200, is_piecewise=True,pieces=pieces), 95 ) 96 .render("中国疫情地图.html") 97 ) 98 #画词云图 99 100 import pandas as pd 101 102 103 import matplotlib .pyplot as plt 104 #文字设为中文(解决文字乱码) 105 from matplotlib import rcParams 106 rcParams['font.family'] = 'simhei' 107 people = pd.read_excel('data.xalx') 108 print(people) 109 people.plot.bar(x='省份',y='累计确诊',color='yellow') 110 plt.xticks(rotation=360) 111 plt.show() 112 113 114 import pandas as pd 115 116 117 import matplotlib .pyplot as plt 118 #文字设为中文(解决文字乱码) 119 from matplotlib import rcParams 120 rcParams['font.family'] = 'simhei' 121 people = pd.read_excel('data.xalx') 122 print(people) 123 people.plot.bar(x='省份',y='治愈',color='red') 124 plt.xticks(rotation=360) 125 plt.show() 126 127 128 import openpyxl 129 import numpy 130 import pandas as pd 131 from wordcloud import WordCloud 132 wb = openpyxl.load_workbook('data.xlsx') 133 ws = wb['国内疫情'] 134 frequency = {} 135 for row in ws.values: 136 if row[0] == '省份': 137 pass 138 else: 139 frequency[row[0]] = float(row[1]) 140 wordcloud = WordCloud(for_path="C:Windows/Fonts/ITCBLKAD.TTF", 141 background_color="white", 142 width=1929, height=1080) 143 wordcloud.generate_from_frequencies(frequency) 144 wordcloud.to_file('wordcloud.png') 145 146
147 148 149
五.总结
1.经过对主体数据的分析与可视化,可以得到那些结论?是否达到预期目标?
湖北等地累计确诊人数最多,基本完成了目标即对各省的疫情累计确诊人数做到可视化显示,是人们清楚的看到疫情累计确诊人数多的地方却并不是现在疫情最严重的地方,这得益于我国广大人民和伟大政府的团结一致积极抗议的结果,让人们生活渐渐护肤正常,经济持续发展。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
(1)自己的数据分析这方面不太足,解析标签提取数据还比较生疏,要勤加练习。(2)建议多提取点数据,此次提取的数据只有中国的各省疫情数据
,下次分析时应该多爬取数据,病根基本同需求,不同主线,线索进行数据爬取,从而为后面的数据分析与可视化做充足的准备。

