刘一辰的软件工程随笔
很容易发现,class为areaBox的 tr 标签中保存的是各省的数据,其中的area为省份名称,其余不包含class的 td保存的是疫情的各项人数,而class为 city 的tr中保存的是各个城市的数据,其中,area为城市名称,其余td保存的疫情各项的人数。
在这样的简单分析之后,顿时感觉这实在是太小儿科了,两个嵌套for循环就可以搞定,于是开始编写爬虫,初始测试爬虫代码如下:

import requests from bs4 import BeautifulSoup url = "https://news.qq.com/zt2020/page/feiyan.htm#/" r = requests.get(url) html = r.text soup = BeautifulSoup(html,"lxml") print(soup.prettify())
运行之后,打印数据是这样的
只有一坨 js 代码还有页面头部的几个div,并没有找到我们想要的标签。迟疑了一瞬间,恍然醒悟数据应该是通过js发送请求之后从后台传回来的。直接看这一段HTML代码,果然什么都看不出来。没办法,F12去浏览器控制台看看到底发生了什么数据交换的操作吧。(微软的浏览器用的有点鸡肋,这里切一下Chrome)可以看到服务器返回了这些数据:
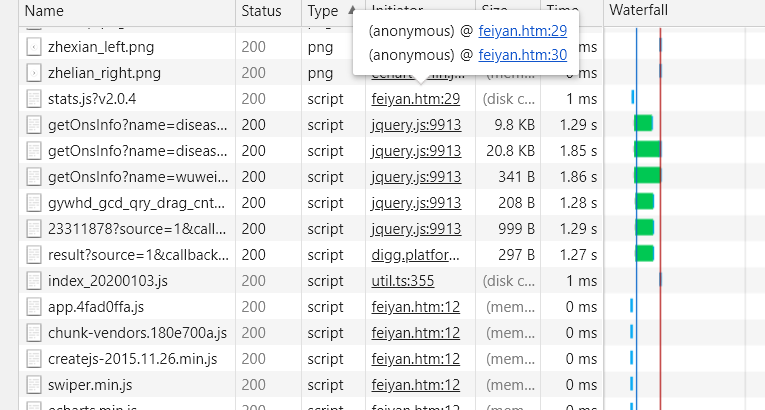
可以看到除了无关紧要的png图片等资源,还返回了这样一堆js文件,一看名字,这些get***Info可能就是我们需要的,检查一下它的地址,然后复制打开


瞬间激动了有木有!!这不就是现成的json数据么,还分析个球的HTML标签,直接爬起来!!!
(激动过头了)先分析一下json的格式和我们需要的“树”,首先可以看到开头有个name 中国的字样,由于该网站支持其他国家的数据,如下:
所以我们解析json的时候就要通过它来筛选本国的数据,那么,在中国下面,又有这样一些数据:
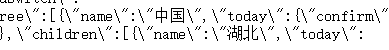

 浙公网安备 33010602011771号
浙公网安备 33010602011771号