


102302104刘璇-数据采集与融合技术实践作业3
作业1:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
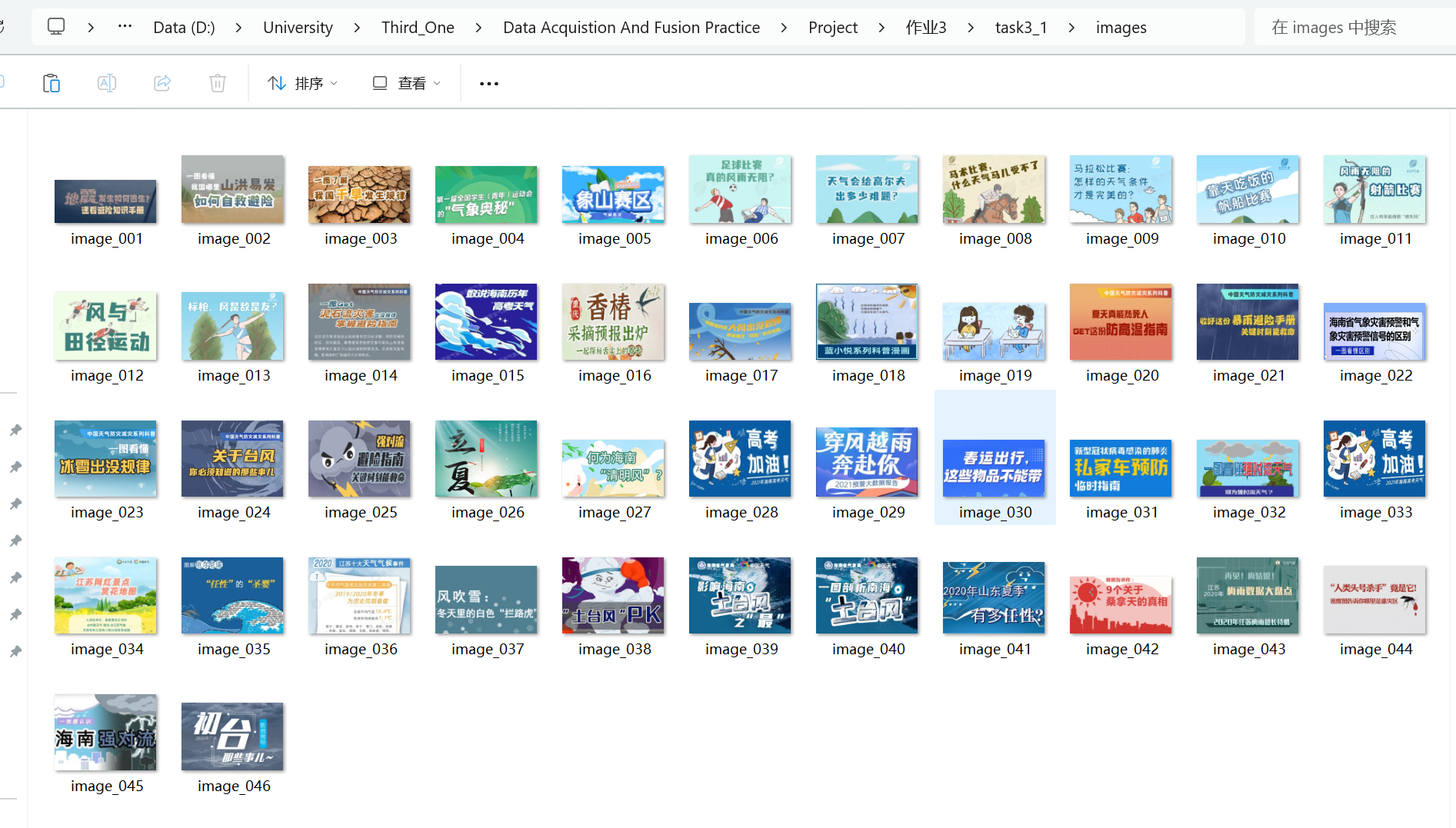
输出信息:将下载的url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图
根据网页获得图片链接:
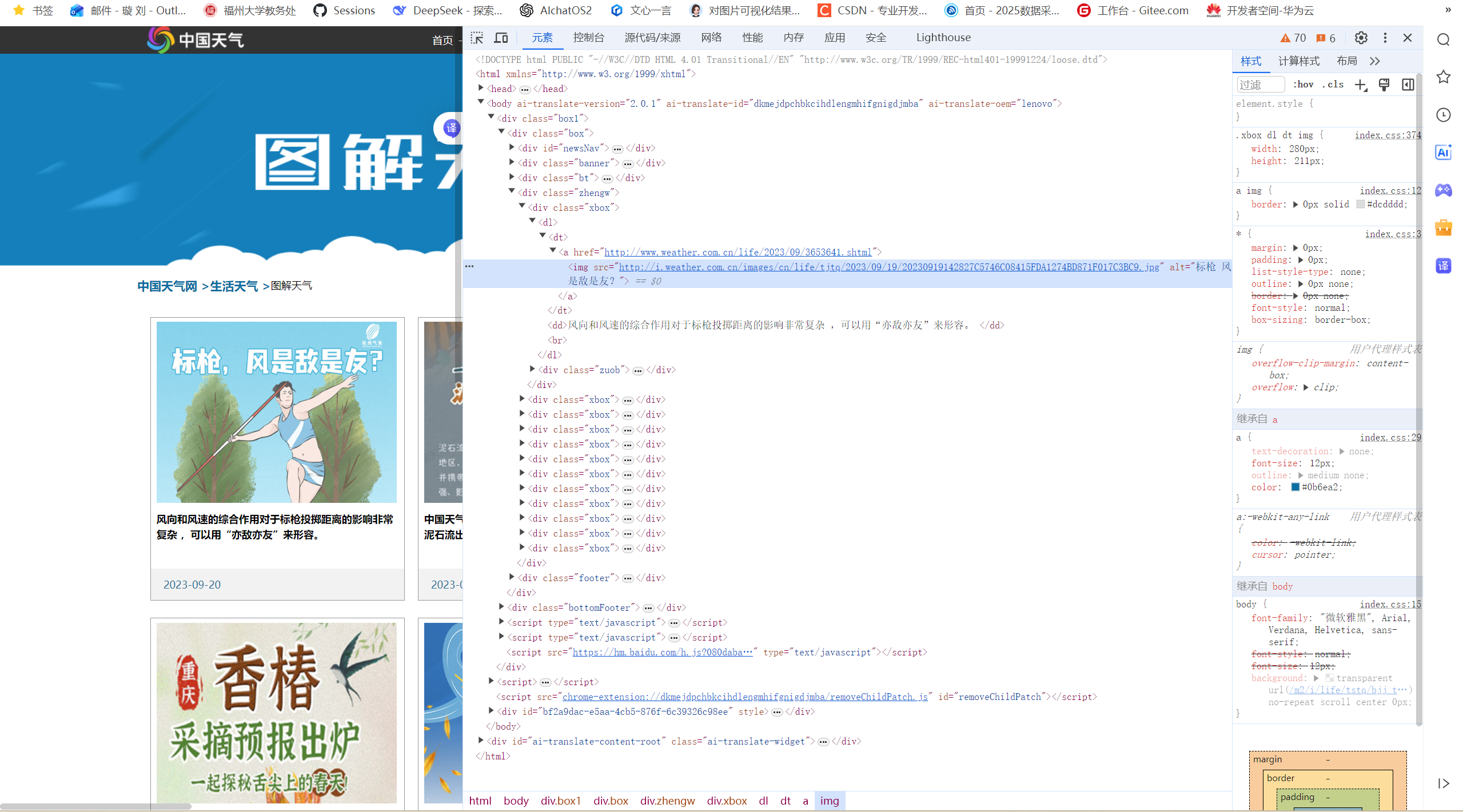
单线程核心代码设计逻辑:
为了获取中国天气网的图片资源,我设计了分层处理的爬虫:在页面解析阶段,通过双路径匹配同时捕获常规和延迟加载的图片链接;数据处理时对图片依次进行格式校验、文件类型判断和去重检测。
单线程核心代码:
点击查看代码
def crawl_images_single_thread(start_url, max_images=140, max_pages=4):
image_count = 0
current_url = start_url
visited_pages = set()
visited_images = set()
current_page = 1
while (current_page <= max_pages
and image_count < max_images
and current_url not in visited_pages):
visited_pages.add(current_url)
try:
response = requests.get(current_url, headers=HEADERS, timeout=15, verify=False)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
#通过BeautifulSoup查找包含特定路径的图片标签
#同时处理普通src属性和延迟加载的data-src属性
img_tags = soup.find_all("img", src=lambda x: x and "i.weather.com.cn/images/cn/life/" in x)
img_tags += soup.find_all("img", attrs={"data-src": lambda x: x and "i.weather.com.cn/images/cn/life/" in x})
#URL转换,去重验证
for img in img_tags:
if image_count >= max_images:
break
#URL转换:将相对URL转换为绝对URL
img_url = img.get("data-src") or img.get("src")
absolute_url = urljoin(current_url, img_url)
#去重验证:检查URL是否已访问且符合图片格式要求
if (absolute_url not in visited_images
and absolute_url.endswith((".jpg", ".png", ".jpeg"))
and "http" in absolute_url):
visited_images.add(absolute_url)
save_path = os.path.join(SAVE_DIR, f"image_{image_count + 1:03d}.jpg")
if download_image(absolute_url, save_path):
image_count += 1
if current_page < max_pages:
next_link = soup.find("a", text=lambda t: t and "下一页" in t)
if next_link:
next_page_url = next_link.get("href")
current_url = urljoin(start_url, next_page_url)
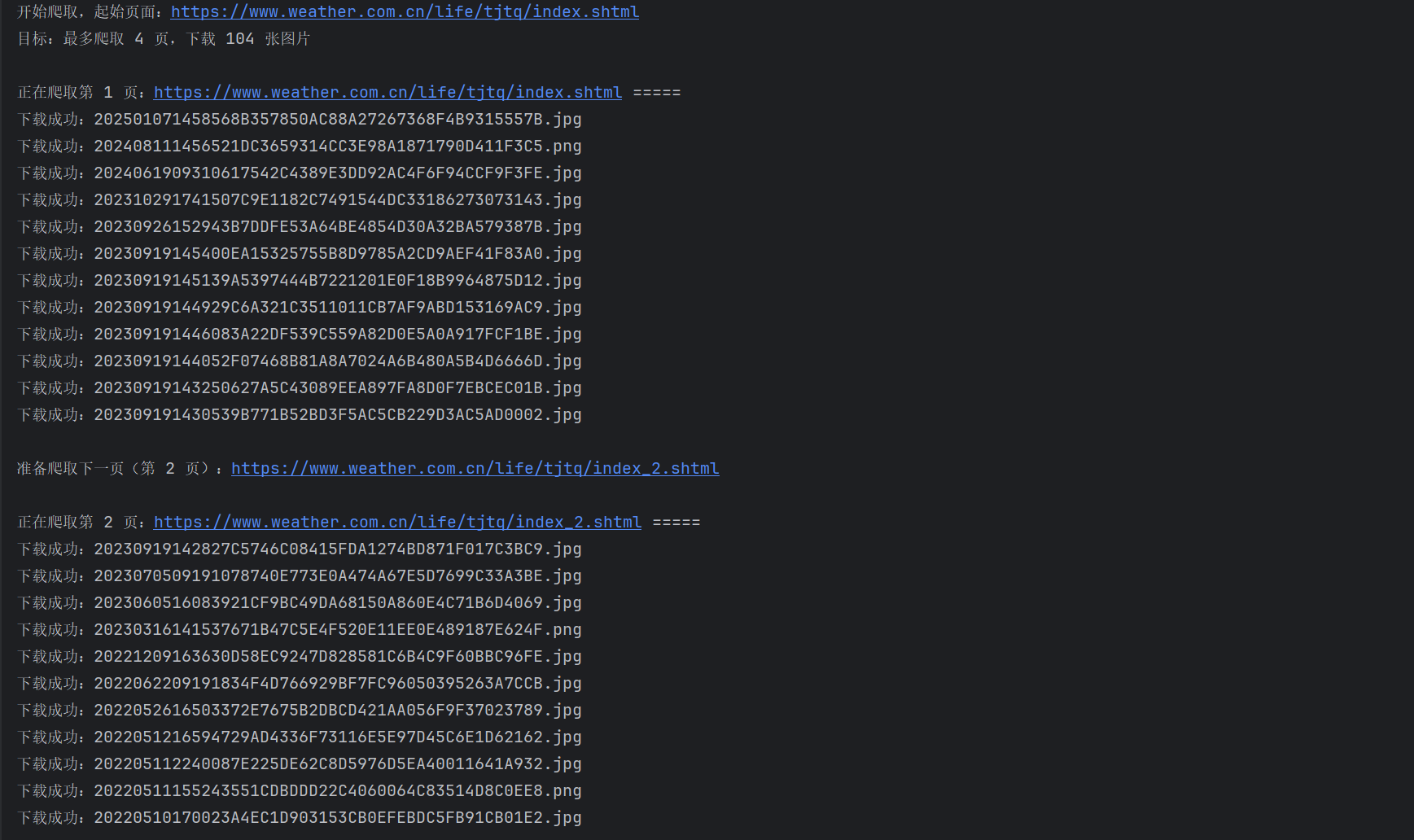
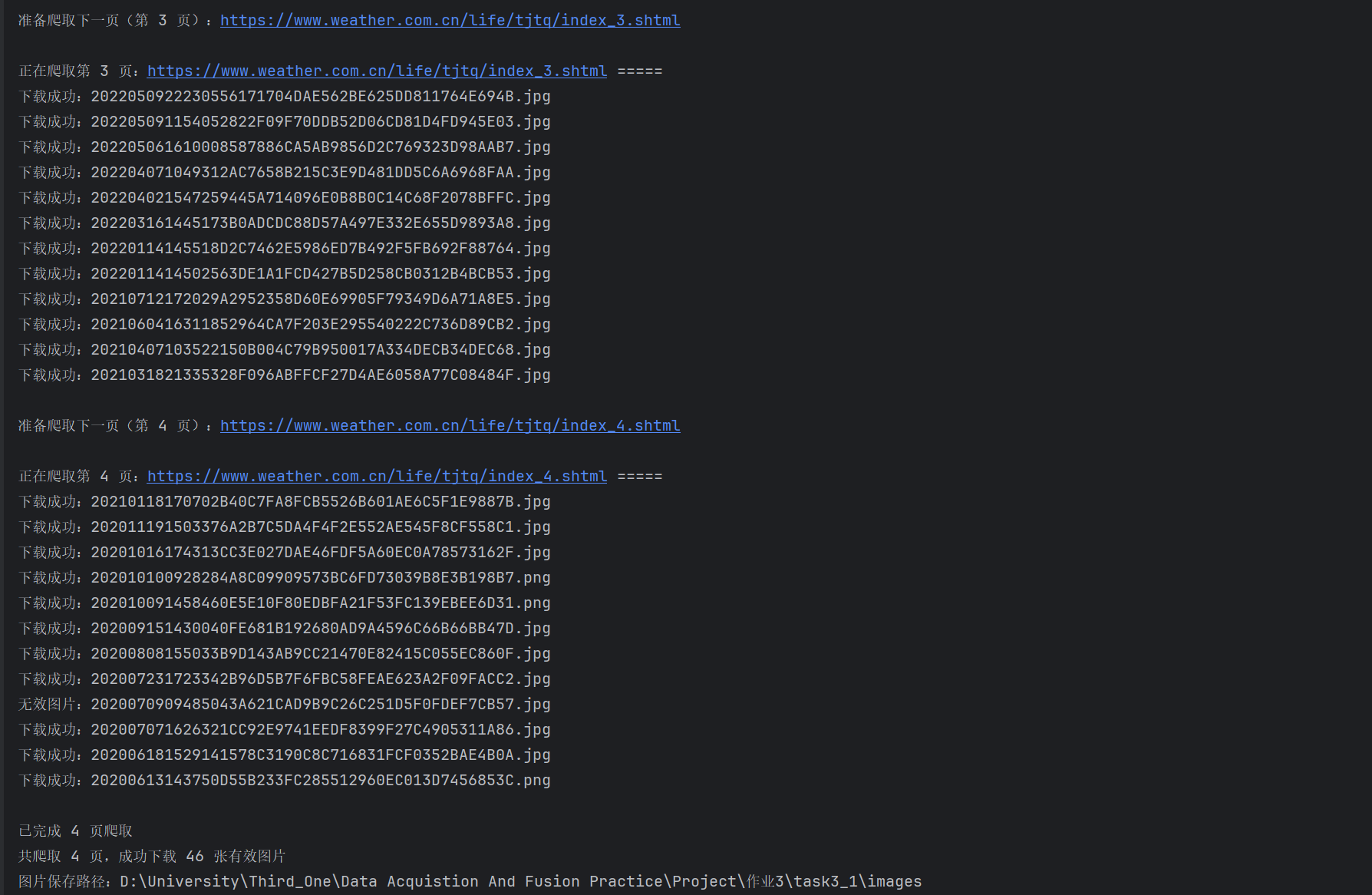
单线程运行结果:
多线程核心代码设计逻辑:
首先通过collect_image_urls函数串行收集所有目标图片URL,然后利用ThreadPoolExecutor线程池并发执行下载任务。
多线程核心代码:
点击查看代码
def crawl_images_multi_thread(start_url, max_images=104, max_pages=4, max_workers=10):
#收集前4页的图片URL
image_urls = collect_image_urls(start_url, max_images, max_pages)
if not image_urls:
print("未收集到任何图片URL,爬取终止")
return
#多线程并发下载
total_downloaded = 0
print(f"\n启动 {max_workers} 个线程,开始并发下载...\n")
with ThreadPoolExecutor(max_workers=max_workers) as executor:
#提交所有下载任务
future_to_url = {}
for i, img_url in enumerate(image_urls):
save_path = os.path.join(SAVE_DIR, f"image_{i+1:03d}.jpg")
future = executor.submit(download_image, img_url, save_path)
future_to_url[future] = img_url
#统计下载结果
for future in as_completed(future_to_url):
if future.result():
total_downloaded += 1
多线程运行结果:
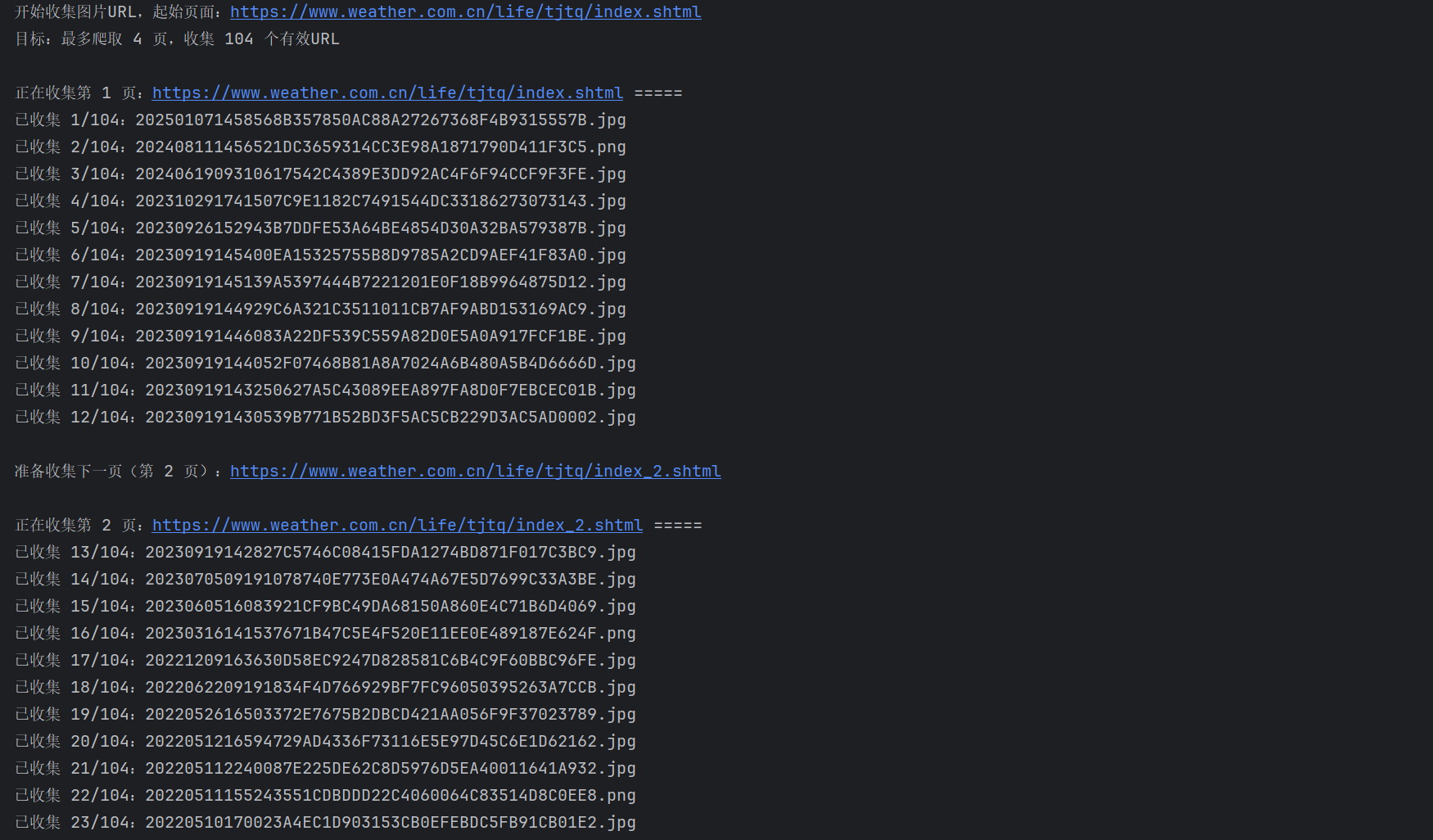
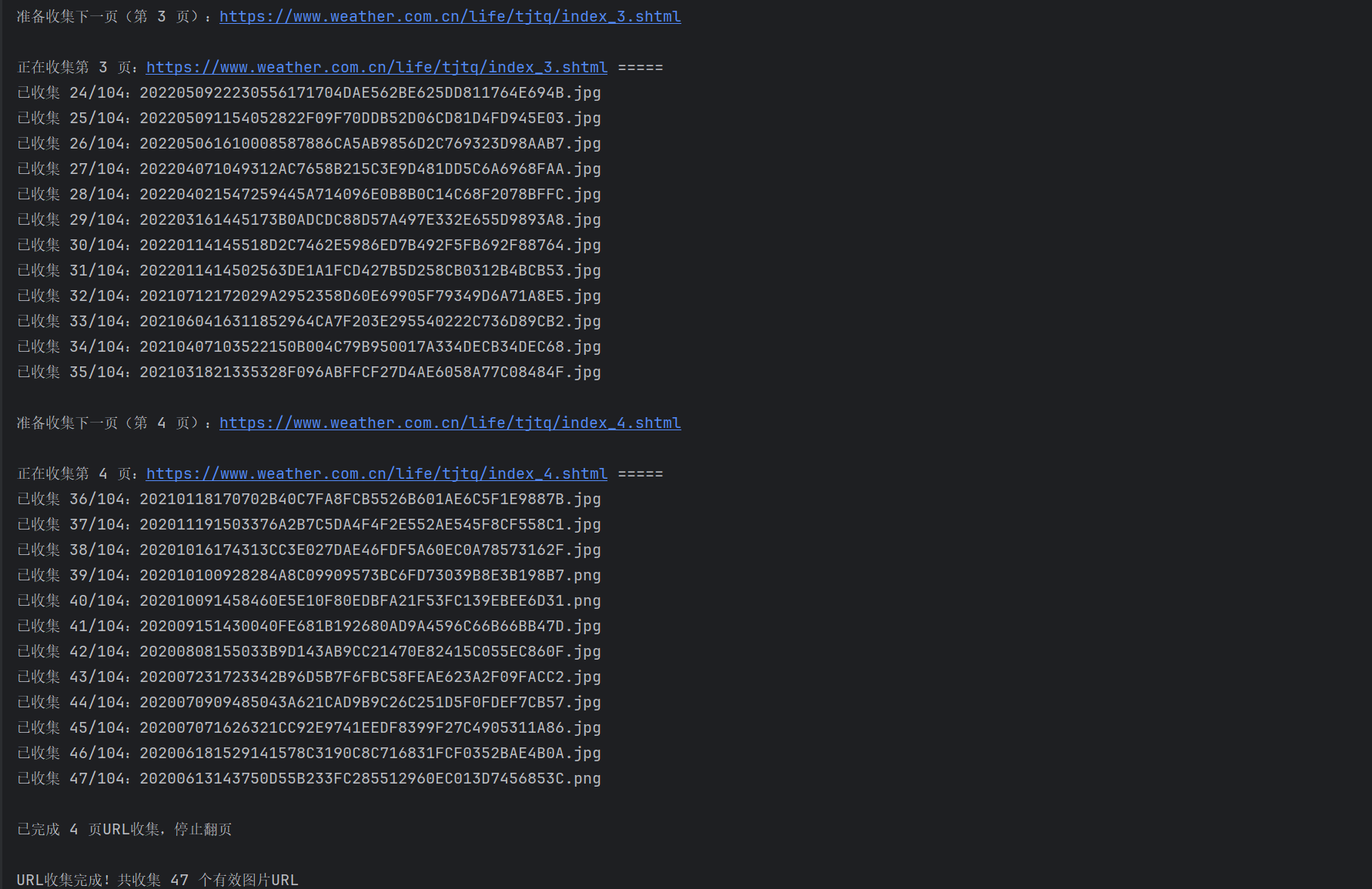
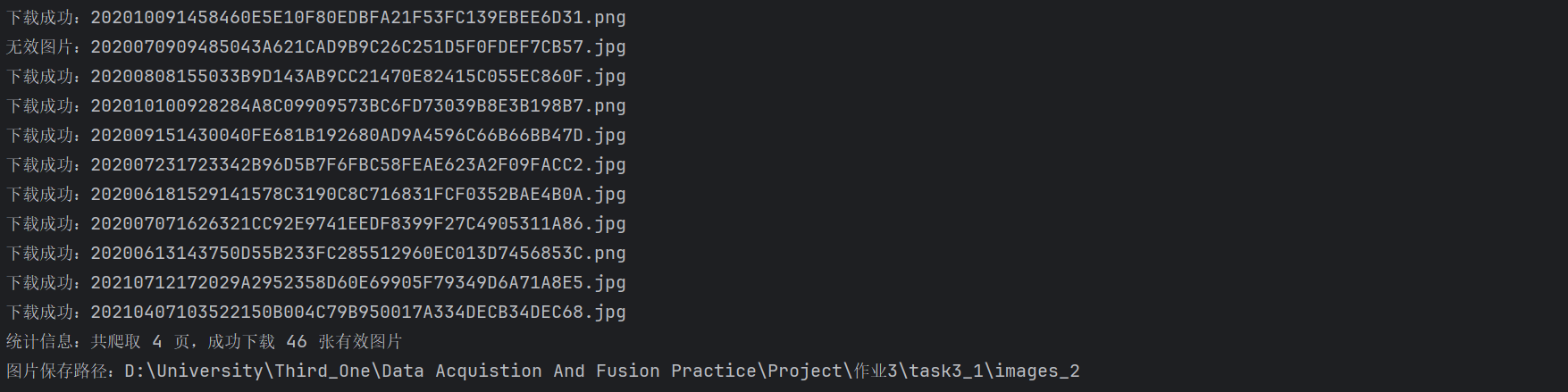
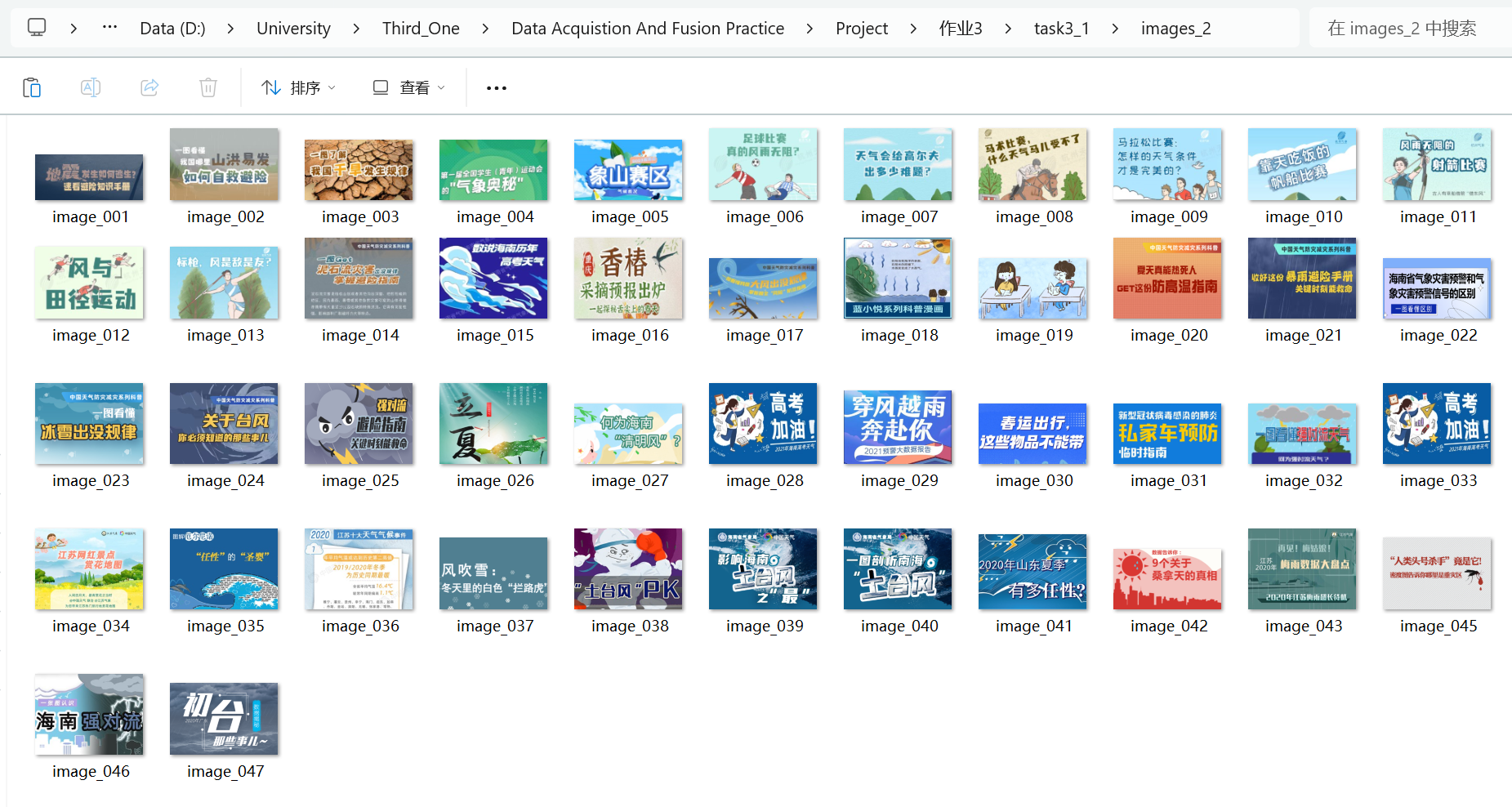
Gitee文件夹链接:https://gitee.com/liuxuannn/data-acquistion-and-fusion-practice_-project1/tree/master/作业3/task3_1
心得体会:
单线程时:在爬取过程中,我遇到了图片链接失效和分页结构不稳定的问题。通过引入预检机制和双路径捕获策略,解决了无效下载和遗漏内容的情况。多线程时:我最初尝试让多个线程同时进行页面解析和图片下载,结果出现了重复采集和线程阻塞的问题。然后通过将URL收集与文件下载分离才解决重复采集问题。
作业2:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
输出信息:MySQL数据库存储和输出格式如下,表头应是英文命名(例如:序号id,股票代码:bStockNo......),由同学们自行定义设计表头:
| 序号 | 股票代码 | 名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
核心代码设计逻辑:
请求层时通过动态拼接分页参数实现批量数据采集;解析时用正则表达式处理特殊格式的JSON响应。
爬虫核心代码stock_spider.py:
点击查看代码
class EastMoneySpider(scrapy.Spider):
name = 'eastmoney_stock'
market_params = {"沪深京A股": "f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048"}
def start_requests(self):
#生成前2页请求
for param in self.market_params.values():
for page in range(1, 3):
url = f"https://98.push2.eastmoney.com/api/qt/clist/get?cb=jQuery&pn={page}&pz=20&po=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=%7C0%7C0%7C0%7Cweb&fid={param}&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18"
yield scrapy.Request(url, callback=self.parse_stock)
def parse_stock(self, response):
#解析jQuery包裹的JSON数据
json_data = re.search(r'jQuery\((.*?)\);', response.text).group(1)
stock_data = json.loads(json_data)['data']['diff']
for stock in stock_data.values():
item = StockItem()
#封装字段
item['stock_code'] = stock.get('f12', 'N/A')
item['stock_name'] = stock.get('f14', 'N/A')
item['latest_price'] = stock.get('f2', 'N/A')
item['change_rate'] = stock.get('f3', 'N/A')
item['change_amount'] = stock.get('f4', 'N/A')
item['volume'] = stock.get('f5', 'N/A')
turnover = stock.get('f6', 0)
item['turnover'] = round(float(turnover)/100000000, 2) if turnover != 'N/A' else 0.00 #单位转换
item['amplitude'] = stock.get('f7', 'N/A')
item['highest'] = stock.get('f15', 'N/A')
item['lowest'] = stock.get('f16', 'N/A')
item['opening_price'] = stock.get('f17', 'N/A')
item['previous_close'] = stock.get('f18', 'N/A')
yield item
存储核心代码pipelines.py:
点击查看代码
class StockMySQLPipeline:
def __init__(self, host, port, user, password, db):
self.conn_params = (host, port, user, password, db)
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
port=crawler.settings.get('MYSQL_PORT'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
db=crawler.settings.get('MYSQL_DB')
)
def open_spider(self, spider):
#连接MySQL并创建表
self.conn = pymysql.connect(*self.conn_params, charset='utf8mb4')
self.cursor = self.conn.cursor()
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS stock_info (
id INT AUTO_INCREMENT PRIMARY KEY,
stock_code VARCHAR(10) NOT NULL,
stock_name VARCHAR(50) NOT NULL,
latest_price DECIMAL(10,2),
change_rate DECIMAL(5,2),
change_amount DECIMAL(10,2),
volume BIGINT,
turnover DECIMAL(10,2),
amplitude DECIMAL(5,2),
highest DECIMAL(10,2),
lowest DECIMAL(10,2),
opening_price DECIMAL(10,2),
previous_close DECIMAL(10,2)
)
""")
def process_item(self, item, spider):
#插入数据
self.cursor.execute("""
INSERT INTO stock_info (stock_code, stock_name, latest_price, change_rate, change_amount, volume, turnover, amplitude, highest, lowest, opening_price, previous_close)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
""", (item['stock_code'], item['stock_name'], item['latest_price'], item['change_rate'],
item['change_amount'], item['volume'], item['turnover'], item['amplitude'],
item['highest'], item['lowest'], item['opening_price'], item['previous_close']))
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
运行结果:
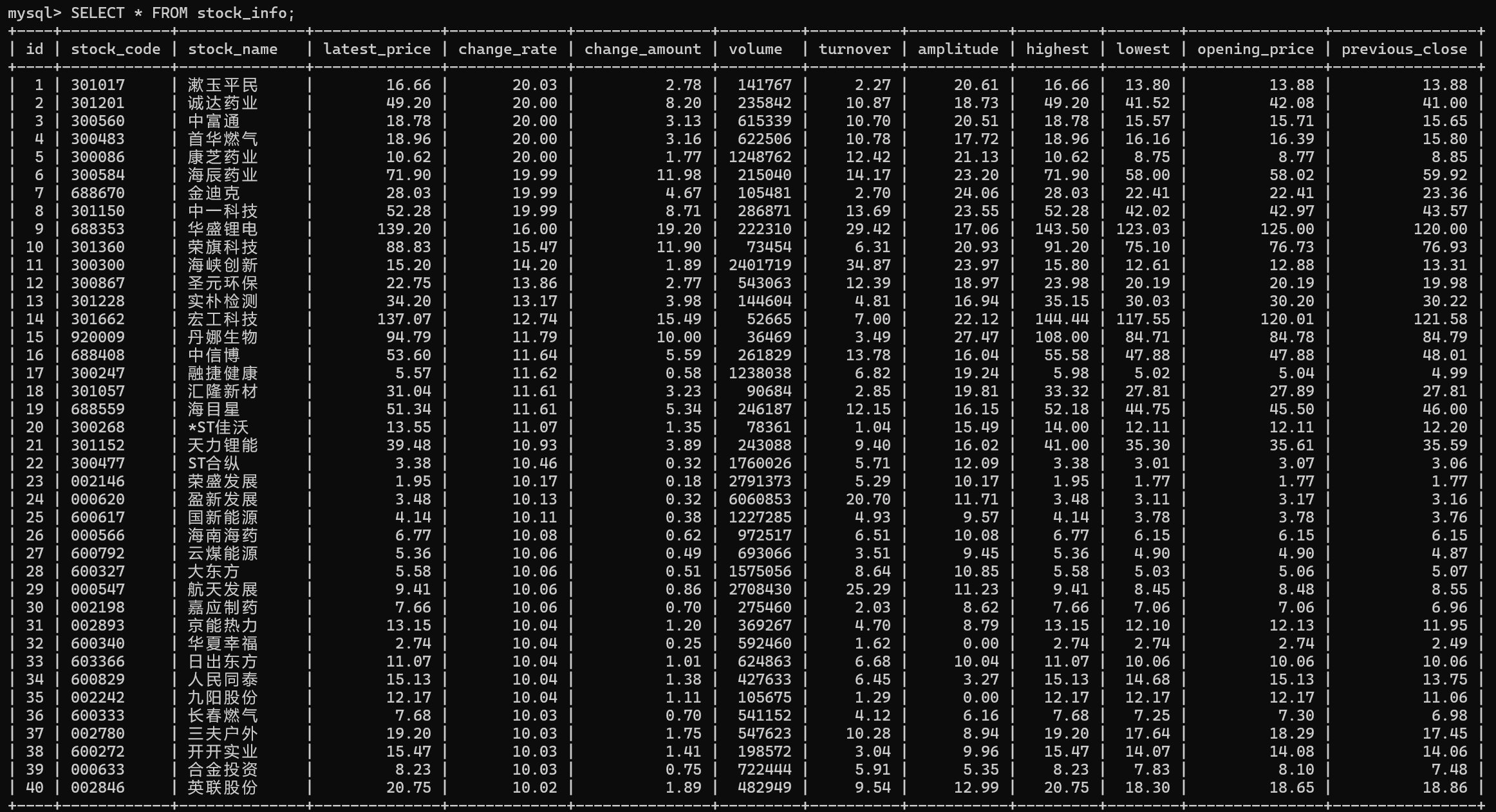
Gitee文件夹链接:https://gitee.com/liuxuannn/data-acquistion-and-fusion-practice_-project1/tree/master/作业3/task3_2
心得体会:
运行代码时显示成交额设置数值不合理,把成交额换成亿元单位去解决数据库里面数值溢出问题。
作业3:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用 scrapy 框架+Xpath+MySQL 数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:(MySQL 数据库存储和输出格式)
| Currency | TBP | CBP | TSP | CSP | Time |
|---|---|---|---|---|---|
| 美元 | 198.58 | 192.31 | 199.98 | 206.59 | 11:27:14 |
核心代码设计逻辑:
爬虫时直接提取所有有效数据行并进行字段清洗与映射。
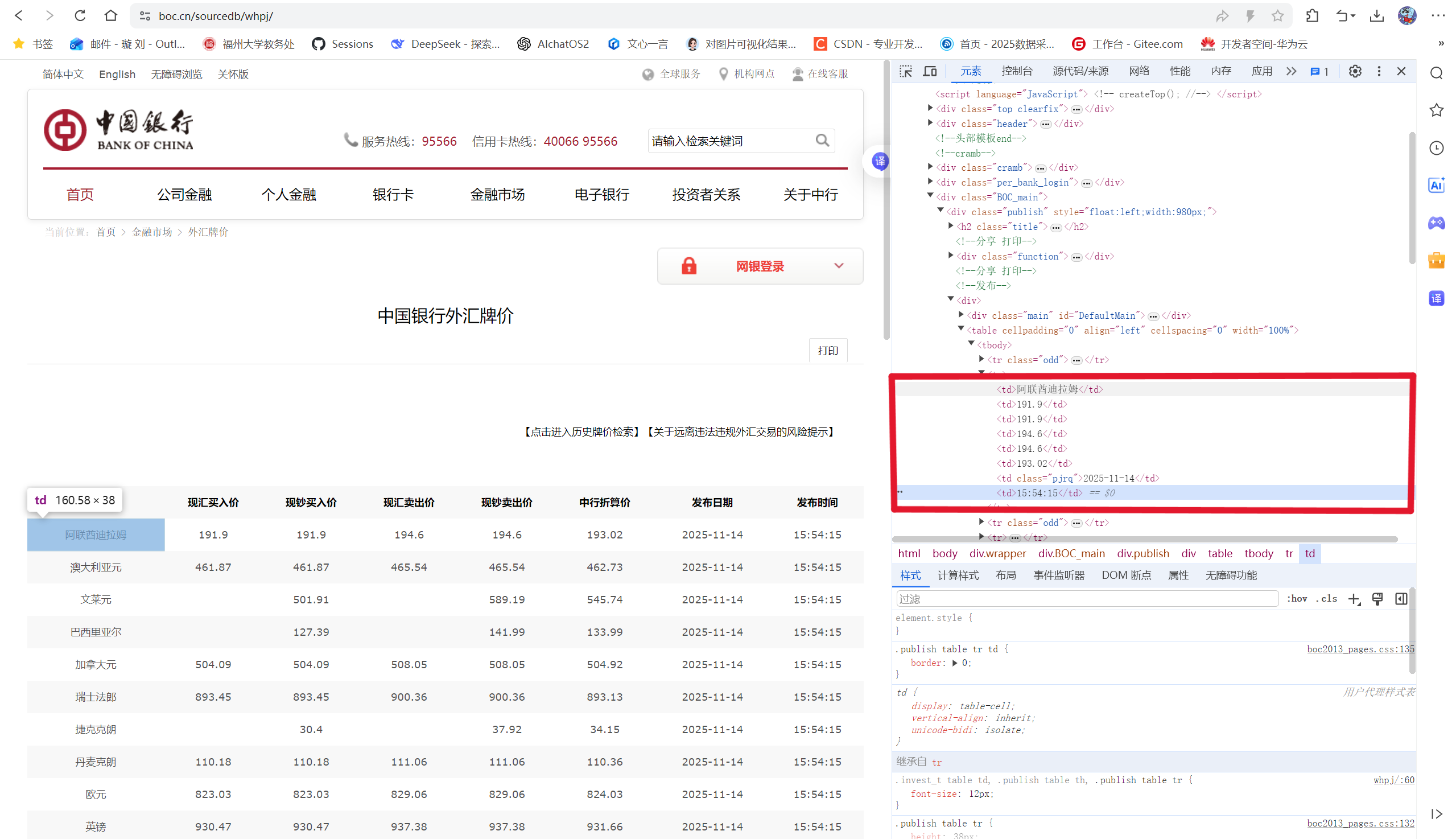
数据模型核心代码items.py:
点击查看代码
import scrapy
class BOCExchangeItem(scrapy.Item):
currency_name = scrapy.Field() # 货币名称
spot_buy = scrapy.Field() # 现汇买入价
cash_buy = scrapy.Field() # 现钞买入价
spot_sell = scrapy.Field() # 现汇卖出价
cash_sell = scrapy.Field() # 现钞卖出价
update_time = scrapy.Field() # 更新时间
爬虫核心代码exchange_spider.py:
点击查看代码
class BOCSpider(scrapy.Spider):
name = "boc_exchange"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
#提取所有表格行,过滤表头和空行
all_rows = response.xpath('//table//tr')
for row in all_rows:
cols = row.xpath('.//td/text()').getall()
cols = [col.strip() for col in cols if col.strip()] #清洗空值和空格
if len(cols) >= 8:
item = BOCExchangeItem()
item['currency_name'] = cols[0]
#价格字段容错:非数字转为0.00
item['spot_buy'] = cols[1] if cols[1].replace('.', '').isdigit() else '0.00'
item['cash_buy'] = cols[2] if cols[2].replace('.', '').isdigit() else '0.00'
item['spot_sell'] = cols[3] if cols[3].replace('.', '').isdigit() else '0.00'
item['cash_sell'] = cols[4] if cols[4].replace('.', '').isdigit() else '0.00'
item['update_time'] = cols[7] #对应页面"发布时间"列
yield item
存储核心代码pipelines.py:
点击查看代码
class BOCMySQLPipeline:
def __init__(self, host, port, user, pwd, db):
self.host = host
self.port = port
self.user = user
self.pwd = pwd
self.db = db
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST', 'localhost'),
port=crawler.settings.get('MYSQL_PORT', 3306),
user=crawler.settings.get('MYSQL_USER', 'root'),
pwd=crawler.settings.get('MYSQL_PASSWORD', ''),
db=crawler.settings.get('MYSQL_DB', 'boc_exchange')
)
def open_spider(self, spider):
#连接数据库并创建表
self.conn = pymysql.connect(
host=self.host, port=self.port, user=self.user, password=self.pwd,
database=self.db, charset='utf8mb4'
)
self.cursor = self.conn.cursor()
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS rate_info (
id INT AUTO_INCREMENT PRIMARY KEY,
currency_name VARCHAR(50),
spot_buy DECIMAL(10,2),
cash_buy DECIMAL(10,2),
spot_sell DECIMAL(10,2),
cash_sell DECIMAL(10,2),
update_time VARCHAR(20)
)
""")
self.conn.commit()
def process_item(self, item, spider):
#插入数据
self.cursor.execute("""
INSERT INTO rate_info (currency_name, spot_buy, cash_buy, spot_sell, cash_sell, update_time)
VALUES (%s, %s, %s, %s, %s, %s)
""", (
item['currency_name'], float(item['spot_buy']), float(item['cash_buy']),
float(item['spot_sell']), float(item['cash_sell']), item['update_time']
))
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
运行结果:
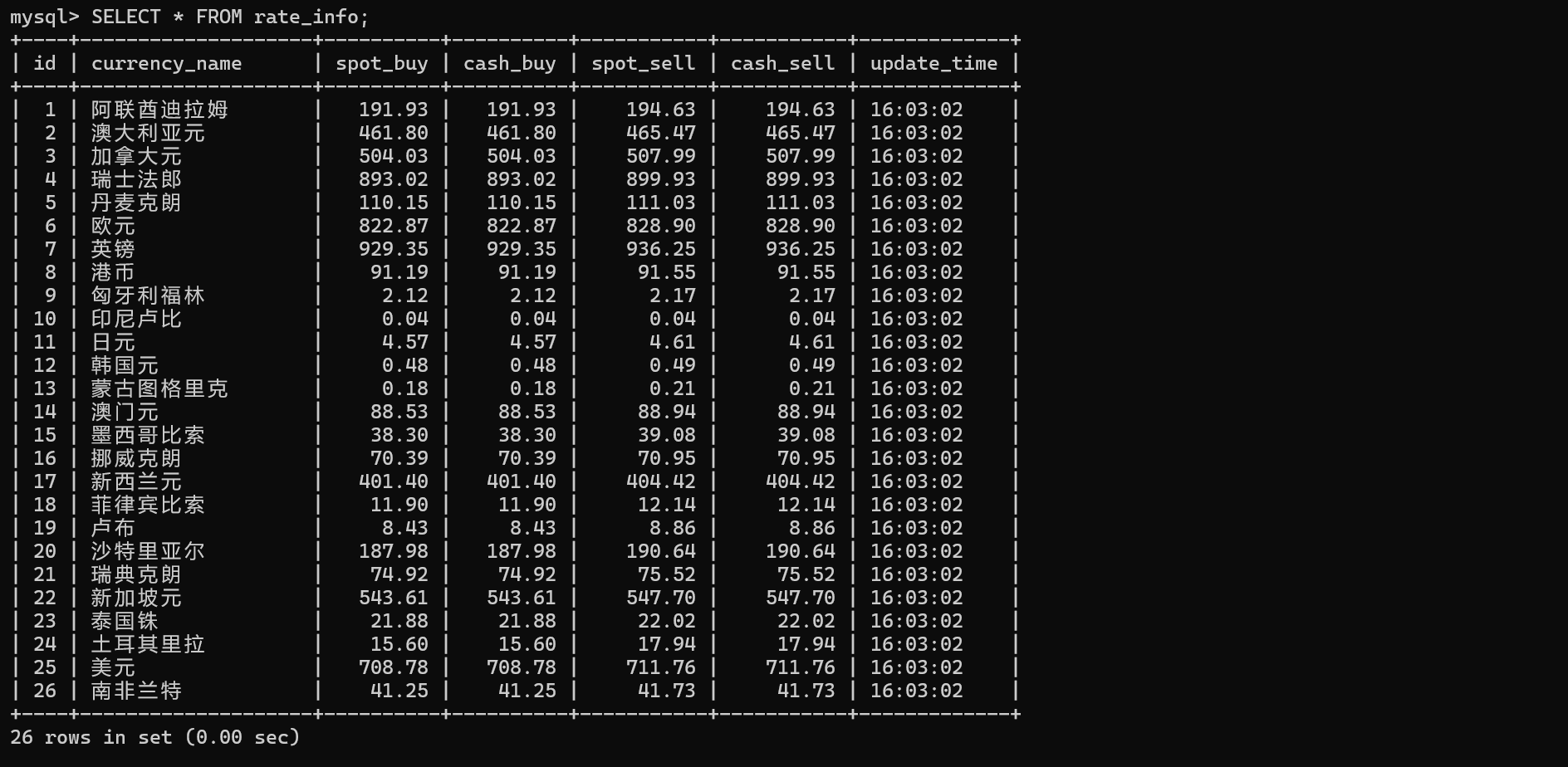

 浙公网安备 33010602011771号
浙公网安备 33010602011771号