
2021全球独角兽排行榜爬虫
一、选题的背景
为什么要选择此选题?要达到的数据分析的预期目标是什么?(10 分) 从社会、经济、技术、数据来源等方面进行描述(200 字以内)
科技是第一生产力,科技水平决定这一个国家的经济发展水平和能力,反应着国家的综合国力。所以有硬实力的科技公司是当下时代的香饽饽,商业中投资人总喜欢独角兽这个名称,独角兽是一个行业的龙头,其独特性和垄断性焦距着所有人的目光。所以我选取了天天排行里的2021全球独角兽排行榜进行爬虫,希望能从这次爬虫中了解一些国家、城市的科技水平和独角兽公司的价值
二、主题式网络爬虫设计方案(10 分)
1.主题式网络爬虫名称
2021全球独角兽排行榜爬虫,网址url="http://www.ttpaihang.com/news/daynews/2021/21122123985.htm"
2.主题式网络爬虫爬取的内容与数据特征分析
内容包括排行、企业名称、价值(亿元人民币)、国家、城市、行业,这些数据都能看出一个企业的属性,反应一个企业的方位
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
查看网页,按F12来查看网页的源码,查看是否需要的数据是不是在页面源码中,查看数据所在的标签查看他的特点,思考这样从这些标签中爬取数据,这个爬虫的实现是很简易的,重难点在于数据的分析和可视化方面
三、主题页面的结构特征分析(10 分)
1.主题页面的结构与特征分析
网页如下
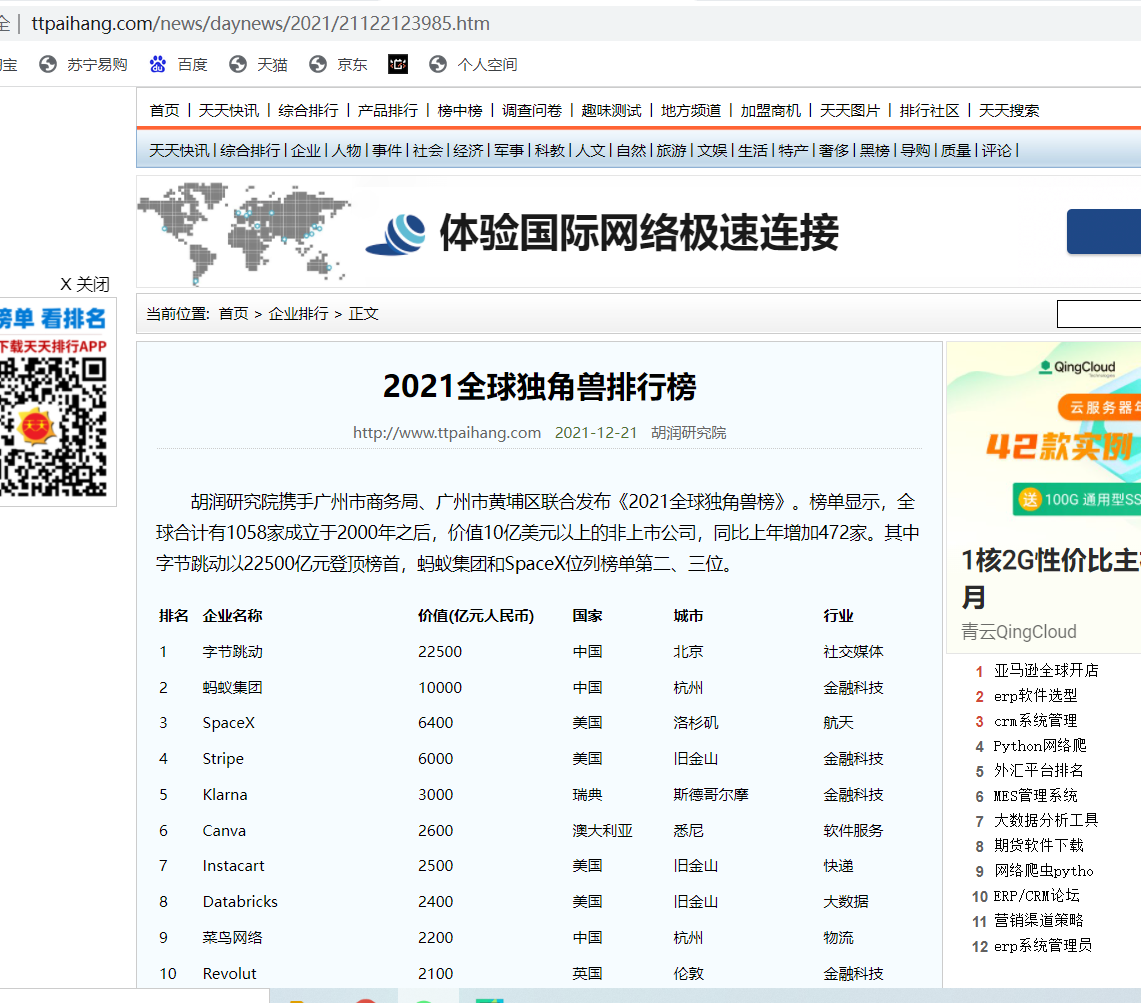
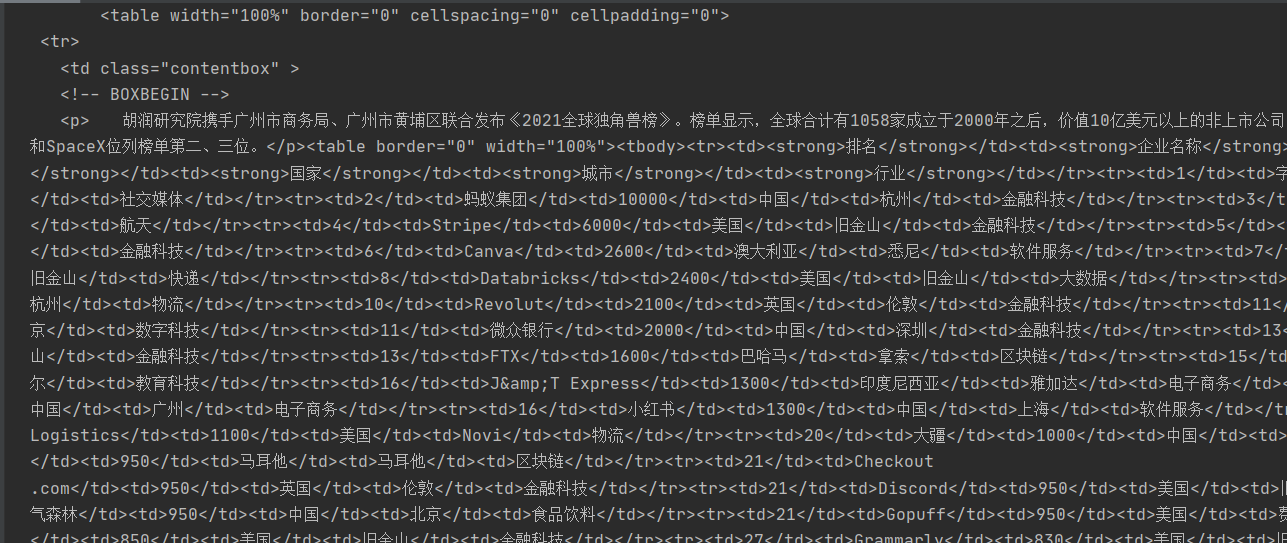
他的结构大概是html->body->table->td->table->td,排行榜的数据都在td中
2.Htmls 页面解析

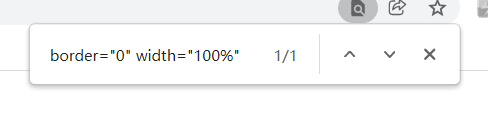
观察页面发现他在table页面下的这个属性下面,而且经过搜索发现这个属性具有唯一性,所以我们可以从这个标签来定位获取

数据都在table标签下的td标签里,所以可以用table获取数据,由于td没有一些属性来定位,可以选用按数量获取的方法得到
3.节点(标签)查找方法与遍历方法 (必要时画出节点树结构)
结构是html->body->table->td->table->td的规律,数据在最后的td标签中查找可以按照倒二的table唯一属性来查找,一个个遍历td标签的数据
四、网络爬虫程序设计(60 分)
数据爬取
1 import requests 2 from bs4 import BeautifulSoup 3 import matplotlib.pyplot as plt 4 import jieba 5 jieba.setLogLevel(jieba.logging.INFO) 6 7 #******获取网页信息的函数****** 8 def getHTMLText(url): 9 #为了让就算网络爬取失败程序也能正常运行,下面用异常处理 10 try: 11 #用get获取网页信息传给response 12 response = requests.get(url) 13 #获取回应的编码,是200则可以正常运行 14 response.raise_for_status() 15 #网页信息的编码一致 16 response.encoding = response.apparent_encoding 17 return response.text 18 except: 19 return "!!!爬取失败!!!" 20 21 #这是放所有信息的列表 22 container=[] 23 #获取信息的函数 24 def getinfo(container,gettext): 25 #按照html.parser准则来解析网页 26 soup=BeautifulSoup(gettext, 'html.parser') 27 #属性字典 28 dict1={ 'class':'contentbox'} 29 dict2={'border':"0", 'width':"100%"} 30 #按节点和字典要求获取信息 31 find= soup.find('td', dict1).find('table',dict2) 32 for f in find: 33 for i in f: 34 #n用来计数分组 35 n=0 36 #p是用来装6个字符串的列表 37 p=[] 38 for j in i: 39 n+=1 40 p.append(j.string) 41 #每6个刷新一次 42 if n%6==0: 43 container.append(p) 44 #定时刷新 45 p=[] 46 47 #数据显示的函数 48 def infodiplay(container): 49 one= "%-4s\t%-12s\t%-12s\t%-6s\t%-10s\t%-8s" 50 print(one%("排名", "企业名称", "价值(亿元人民币)", "国家", "城市","行业")) 51 #用来去除第一组列表的输出,已达到较为整齐的效果 52 onedel=0 53 for cont in container: 54 onedel+=1 55 if onedel!=1: 56 print("%-4s\t%-12s\t%-18s\t%-6s\t%-10s\t%-8s"%(cont[0],cont[1],cont[2],cont[3],cont[4],cont[5])) 57 58 def main(): 59 #天天排行 独角兽http://www.ttpaihang.com/news/daynews/2021/21122123985.htm 60 url="http://www.ttpaihang.com/news/daynews/2021/21122123985.htm" 61 gettext=getHTMLText(url) 62 getinfo(container,gettext) 63 infodiplay(container) 64 65 if __name__ == '__main__': 66 main()
效果图

词云
1 #******词云和jieba****** 2 # 通过对歌词文件lyrics.txt的内容分析,提取前50个权重高的词,按照tim.jpg的样式,生成词云图。 3 4 import jieba.analyse 5 import numpy as np 6 from PIL import Image, ImageSequence 7 from wordcloud import WordCloud, ImageColorGenerator 8 9 #所有城市放进cloud 10 cloud=[] 11 #所有行业放进cloud2 12 cloud3=[] 13 for i in container: 14 cloud.append(i[-2]) 15 cloud3.append(i[-1]) 16 17 cloud2=' '.join(cloud) 18 cloud4=' '.join(cloud3) 19 20 # 用jieba.analyse分词,分析权重 21 # 待处理语句字符串cloud2,topK关键字的个数,withWeight:是否返回权重值,默认false 22 jiebar= jieba.analyse.textrank(cloud2, topK=50, withWeight=True) 23 jiebar2=jieba.analyse.textrank(cloud4, topK=50, withWeight=True) 24 25 # 打开背景图 26 image = Image.open('D:\\reqiqiu.JPG') 27 na = np.array(image) # 读取背景图 28 wc = WordCloud(font_path='D:\\rooms\\SimHei.ttf', 29 background_color='White', 30 max_words=50, 31 mask=na) 32 33 #创建列表默认值为0 34 dict1 = dict.fromkeys(jiebar,0) 35 dict2= dict.fromkeys(jiebar2,0) 36 for i in jiebar: 37 dict1[i[0]]=i[1] 38 for i in jiebar2: 39 dict2[i[0]]=i[1] 40 41 # 按城市的频率的词云 42 wc.generate_from_frequencies(dict1) 43 plt.imshow(wc) 44 plt.axis('off') 45 plt.show() 46 wc.to_file("D:\\reqiqiuCloud.JPG") 47 48 # 按行业的频率的词云 49 wc.generate_from_frequencies(dict2) 50 plt.imshow(wc) 51 plt.axis('off') 52 plt.show() 53 wc.to_file("D:\\reqiqiuCloud2.JPG")
效果图


数据分析和可视化(饼图、折线图、散点图)
1 #******Python数据分析和可视化分析****** 2 #数据分析 3 import pandas as pd 4 a=[] 5 df=pd.DataFrame(container[1:],columns=container[0]) 6 df.describe() 7 8 #国家占比的饼图 9 #用来放置国家的列表 10 country=[] 11 for i in container: 12 country.append(i[-3]) 13 #用set方法取重复 14 countryset=set(country) 15 countrylist=list(countryset) 16 #转为字符串类型用取后面count方法的计数 17 countstr=''.join(country) 18 amount=[] 19 for i in countrylist: 20 amount.append(countstr.count(i)) 21 #为plt设置字体,让他能显示中文 22 plt.rcParams['font.sans-serif']=['SimHei'] 23 plt.rcParams['axes.unicode_minus'] = False 24 plt.pie(x = amount, labels=countrylist) 25 plt.show() 26 27 #城市的饼图 28 #用来放置城市的列表 29 city=[] 30 for i in container: 31 city.append(i[-2]) 32 #用set方法取重复 33 cityset=set(city) 34 citylist=list(cityset) 35 #转为字符串类型用取后面count方法来计数 36 citystr=' '.join(city) 37 amount2=[] 38 for i in citylist: 39 amount2.append(citystr.count(i)) 40 #为plt设置字体,让他能显示中文 41 plt.rcParams['font.sans-serif']=['SimHei'] 42 plt.rcParams['axes.unicode_minus'] = False 43 plt.pie(x = amount2, labels=citylist) 44 plt.show() 45 46 #排名和价值的折线图 47 import pandas as pd 48 import matplotlib.pyplot as plt 49 import seaborn as sns 50 #排名列表 51 pm = [] 52 for i in container: 53 pm.append(i[0]) 54 #价值列表 55 jz = [] 56 for i in container: 57 jz.append(i[2]) 58 # Seaborn折线图 59 data = pd.DataFrame({'x': pm, 'y': jz}) 60 sns.lineplot(x="x", y="y", data=data) 61 plt.show() 62 63 #散点图 64 x=[] 65 y=[] 66 for i in container: 67 x.append(i[0]) 68 y.append(i[2]) 69 # Matplotlib散点图 70 plt.scatter(x,y,marker='x') 71 plt.show()
效果图
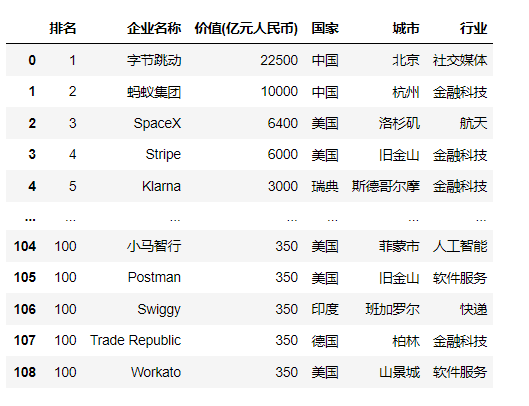

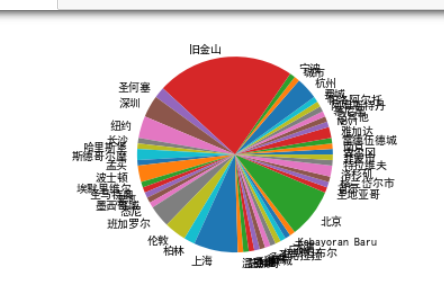
数据持久化
1 #******数据写入Excel文件中****** 2 from openpyxl import Workbook 3 mb= Workbook() 4 book = mb.active 5 for i in container: 6 book.append(i) 7 #放的文件地址 8 mb.save('要保存的地方')
效果图
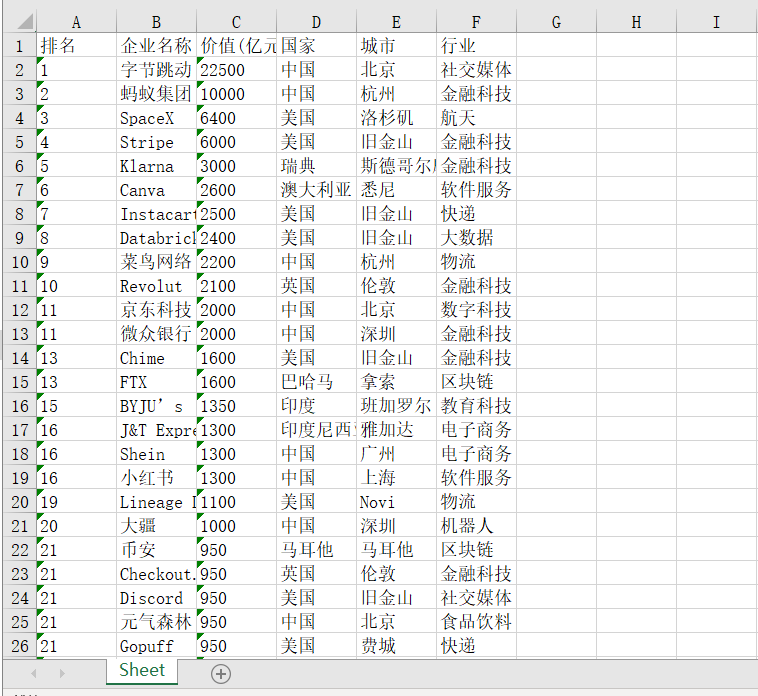
全部代码
1 # --*-- coding:utf-8 --*-- 2 import requests 3 from bs4 import BeautifulSoup 4 import matplotlib.pyplot as plt 5 import jieba 6 jieba.setLogLevel(jieba.logging.INFO) 7 8 #******获取网页信息的函数****** 9 def getHTMLText(url): 10 #为了让就算网络爬取失败程序也能正常运行,下面用异常处理 11 try: 12 #用get获取网页信息传给response 13 response = requests.get(url) 14 #获取回应的编码,是200则可以正常运行 15 response.raise_for_status() 16 #网页信息的编码一致 17 response.encoding = response.apparent_encoding 18 return response.text 19 except: 20 return "!!!爬取失败!!!" 21 22 #这是放所有信息的列表 23 container=[] 24 #获取信息的函数 25 def getinfo(container,gettext): 26 #按照html.parser准则来解析网页 27 soup=BeautifulSoup(gettext, 'html.parser') 28 #属性字典 29 dict1={ 'class':'contentbox'} 30 dict2={'border':"0", 'width':"100%"} 31 #按节点和字典要求获取信息 32 find= soup.find('td', dict1).find('table',dict2) 33 for f in find: 34 for i in f: 35 #n用来计数分组 36 n=0 37 #p是用来装6个字符串的列表 38 p=[] 39 for j in i: 40 n+=1 41 p.append(j.string) 42 #每6个刷新一次 43 if n%6==0: 44 container.append(p) 45 #定时刷新 46 p=[] 47 48 #数据显示的函数 49 def infodiplay(container): 50 one= "%-4s\t%-12s\t%-12s\t%-6s\t%-10s\t%-8s" 51 print(one%("排名", "企业名称", "价值(亿元人民币)", "国家", "城市","行业")) 52 #用来去除第一组列表的输出,已达到较为整齐的效果 53 onedel=0 54 for cont in container: 55 onedel+=1 56 if onedel!=1: 57 print("%-4s\t%-12s\t%-18s\t%-6s\t%-10s\t%-8s"%(cont[0],cont[1],cont[2],cont[3],cont[4],cont[5])) 58 59 def main(): 60 #天天排行 独角兽http://www.ttpaihang.com/news/daynews/2021/21122123985.htm 61 url="http://www.ttpaihang.com/news/daynews/2021/21122123985.htm" 62 gettext=getHTMLText(url) 63 getinfo(container,gettext) 64 infodiplay(container) 65 66 if __name__ == '__main__': 67 main() 68 69 #******词云和jieba****** 70 # 通过对歌词文件lyrics.txt的内容分析,提取前50个权重高的词,按照tim.jpg的样式,生成词云图。 71 72 import jieba.analyse 73 import numpy as np 74 from PIL import Image, ImageSequence 75 from wordcloud import WordCloud, ImageColorGenerator 76 77 #所有城市放进cloud 78 cloud=[] 79 #所有行业放进cloud2 80 cloud3=[] 81 for i in container: 82 cloud.append(i[-2]) 83 cloud3.append(i[-1]) 84 85 cloud2=' '.join(cloud) 86 cloud4=' '.join(cloud3) 87 88 # 用jieba.analyse分词,分析权重 89 # 待处理语句字符串cloud2,topK关键字的个数,withWeight:是否返回权重值,默认false 90 jiebar= jieba.analyse.textrank(cloud2, topK=50, withWeight=True) 91 jiebar2=jieba.analyse.textrank(cloud4, topK=50, withWeight=True) 92 93 # 打开背景图 94 image = Image.open('D:\\reqiqiu.JPG') 95 na = np.array(image) # 读取背景图 96 wc = WordCloud(font_path='D:\\rooms\\SimHei.ttf', 97 background_color='White', 98 max_words=50, 99 mask=na) 100 101 #创建列表默认值为0 102 dict1 = dict.fromkeys(jiebar,0) 103 dict2= dict.fromkeys(jiebar2,0) 104 for i in jiebar: 105 dict1[i[0]]=i[1] 106 for i in jiebar2: 107 dict2[i[0]]=i[1] 108 109 # 按城市的频率的词云 110 wc.generate_from_frequencies(dict1) 111 plt.imshow(wc) 112 plt.axis('off') 113 plt.show() 114 wc.to_file("D:\\reqiqiuCloud.JPG") 115 116 # 按行业的频率的词云 117 wc.generate_from_frequencies(dict2) 118 plt.imshow(wc) 119 plt.axis('off') 120 plt.show() 121 wc.to_file("D:\\reqiqiuCloud2.JPG") 122 123 #******Python数据分析和可视化分析****** 124 #数据分析 125 import pandas as pd 126 a=[] 127 df=pd.DataFrame(container[1:],columns=container[0]) 128 df.describe() 129 130 #国家占比的饼图 131 #用来放置国家的列表 132 country=[] 133 for i in container: 134 country.append(i[-3]) 135 #用set方法取重复 136 countryset=set(country) 137 countrylist=list(countryset) 138 #转为字符串类型用取后面count方法的计数 139 countstr=''.join(country) 140 amount=[] 141 for i in countrylist: 142 amount.append(countstr.count(i)) 143 #为plt设置字体,让他能显示中文 144 plt.rcParams['font.sans-serif']=['SimHei'] 145 plt.rcParams['axes.unicode_minus'] = False 146 plt.pie(x = amount, labels=countrylist) 147 plt.show() 148 149 #城市的饼图 150 #用来放置城市的列表 151 city=[] 152 for i in container: 153 city.append(i[-2]) 154 #用set方法取重复 155 cityset=set(city) 156 citylist=list(cityset) 157 #转为字符串类型用取后面count方法来计数 158 citystr=' '.join(city) 159 amount2=[] 160 for i in citylist: 161 amount2.append(citystr.count(i)) 162 #为plt设置字体,让他能显示中文 163 plt.rcParams['font.sans-serif']=['SimHei'] 164 plt.rcParams['axes.unicode_minus'] = False 165 plt.pie(x = amount2, labels=citylist) 166 plt.show() 167 168 #排名和价值的折线图 169 import pandas as pd 170 import matplotlib.pyplot as plt 171 import seaborn as sns 172 #排名列表 173 pm = [] 174 for i in container: 175 pm.append(i[0]) 176 #价值列表 177 jz = [] 178 for i in container: 179 jz.append(i[2]) 180 # 使用Seaborn画折线图 181 data = pd.DataFrame({'x': pm, 'y': jz}) 182 sns.lineplot(x="x", y="y", data=data) 183 plt.show() 184 185 #散点图 186 x=[] 187 y=[] 188 for i in container: 189 x.append(i[0]) 190 y.append(i[2]) 191 # 用Matplotlib画散点图 192 plt.scatter(x,y,marker='x') 193 plt.show() 194 195 #******数据写入Excel文件中****** 196 from openpyxl import Workbook 197 mb= Workbook() 198 book = mb.active 199 for i in container: 200 book.append(i) 201 #放的文件地址 202 mb.save('要保存的地方')
五、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
独角兽公司最多在旧金山,多数的独角兽公司在中国和美国,多数独角兽公司是从事金融、服务、科技、软件、人工智能的,达到了预期了解独角兽公司的目标
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
明白了现在的科技竞争多在中国和美国之间,明白了现在的一些朝阳企业金融、服务、科技、软件、人工智能等,并且发现爬虫是十分有趣的,给我带来极大的成就感,需要改进的是获取的数据还不够多,如果得到更多的数据就能更加了解独角兽公司

