查询语句、单表查询、多表查询
今日学习总结:
一、查询语句的基础操作
1、select # 表示查询
2、 from # 表示从什么中
3、where # 表示约束条件
4、group by # 表示分组
5、 having # 表示过滤,留下什么
6、distinct # 表示去重
7、 order by # 表示排序,默认是升序
8、limit # 表示限制
9、聚合函数: count, max, min, avg, sum
二、单表查询
1、select 2、from 3、where: 约束条件
书写顺序:select--->from--->where
执行顺序:from--->where--->select
select * from emp; # 若数据比较多,比较凌乱,可以在表后面+ \G
select * from emp\G # 若数据比较多,比较凌乱,可以在表后面+ \
01、查询id大于等于3,小于等于6的数据
select * from emp where id >= 3 and id <= 6; # and: 与
select * from emp where id between 3 and 6; # between: 在什么什么之间
02、查询薪资是20000或者18000或者17000的数据
select * from emp where salary = 20000 or salary = 18000 or salary = 17000; # or:或者
select * from emp where salary in (20000, 18000, 17000); # in: 在什么什么中
03、查询员工姓名中包含o字母 的 员工姓名 和 薪资
select name, salary from emp where name like '%o%'; # 模糊匹配: like %: 匹配多个任意的字符
04、查找名字个数为4个的员工 名字 与 薪资
select name, salary from emp where name like '____'; # 模糊匹配: like _: 匹配一个任意的字符
select name, salary from emp where char_length(name) = 4; # char_length(name): 计算名字字符的长度
05、查询id小于3或者大于6的数据
select * from emp where id not in (3, 4, 5, 6); # not in: 不再什么什么中
select * from emp where id not between 3 and 6; # between...and... 什么什么之间
06、查询薪资不在20000,18000,17000范围的数据
select * from emp where salary not in (20000, 18000, 17000);
07、查询岗位描述为空的 员工名 与 岗位名 post_comment
select name, post from emp where post_comment = null; # 报错
select name, post from emp where post_comment is null; # 注意: 针对null的值 需要使用 is
4、group by: 分组
书写顺序:select--->from--->where--->group by
执行顺序:from--->where--->group by--->select
show variables like "%mode%"; # 表示 设置严格模式:
set global sql_mode="strict_trans_tables,only_full_group_by"; # 表示 全局设置严格模式: 永久有效
若 不设置全局模式,按部门分组时,取的是部门的第一个人
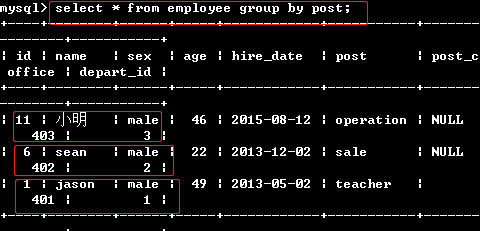
若 设置了全局模式:set global sql_mode="ONLY_FULL_GROUP_BY";后,在按部门分组,
只能select post了


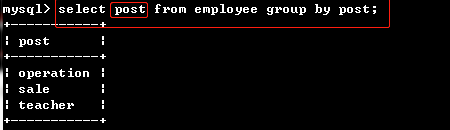
01、根据部门分组
select post, salary from emp group by post; #报错 # 严格模式下不能获取 分组条件post 以外的字段数据
在严格模式下只能 “直接” 获取 分组条件post 字段;
但是可以同聚合函数,间接获取其他字段数据
# 非严格模式下可以获取 分组条件post 以外的字段数据
select post from emp group by post; # 严格模式下,这样写对
02、聚合函数:
count: 计数
max: 最大值
min: 最小值
avg: 平均值
sum: 求和
书写顺序:select--->聚合函数--->from--->where--->group by
执行顺序:from--->where--->group by--->聚合函数--->select # 聚合函数,必须跟在group by 后面(执行顺序);
03、获取每个 部门 的最高工资
select post , max(salary) from emp group by post;
select post as '部门', max(salary) as '最高薪资' from emp group by post; # as 别名: 可以给字段起一个 别名
04、 每个部门的最低工资
select post, min(salary) from emp group by post;
05、每个部门的平均工资
select post, avg(salary) from emp group by post;
06、每个部门的工资总和
select post, sum(salary) from emp group by post;
07、每个部门的员工个数
select post, count(salary) from emp group by post; # count(): 括号中可以填任意非空值
select post, count(post_comment) from emp group by post; # count(): 括号中可以填任意非空值
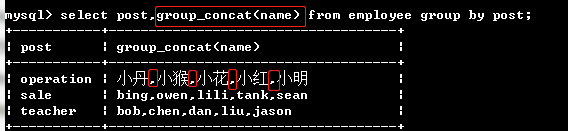
08、 查询 "岗位名" 以及 岗位包含的所有员工名字 用一行展示
select post, group_concat(name) from emp group by post; # group_concat(name): 可以将分组后的 所有名字获取,默认以逗号拼接
select post, group_concat('Name: ', name) from emp group by post; # 指定以 Name: 拼接
select post, group_concat(name, ':') from emp group by post; # 指定以:拼接

09、查询岗位名以及各岗位内包含的员工个数
select post, count(id) from emp group by post;
10、查询公司内男员工和女员工的个数
select sex, count(*) from emp group by sex;
11、查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
select sex, avg(salary) from emp group by sex;
12、统计各部门年龄在30岁以上的员工平均工资:
# 步骤: 先找到表,再找年龄30岁以上,再根据部门分组,最后求平均薪资;
select post, avg(salary) from emp where age > 30 group by post;
5、having: 过滤,having与where的作用是一样的,区别:having后面可以跟聚合函数,但where后面不能跟聚合函数;
书写顺序:select--->from--->where--->group by--->having
执行顺序:from--->where--->group by--->having--->select # having,必须跟在group by 后面(执行顺序)
01、统计各 部门 年龄在30岁以上的员工平均工资,并且保留平均工资大于10000的部门;
select post, avg(salary) from emp where age > 30 group by post having avg(salary) > 10000;
6、distinct: 去重
书写顺序:select--->distinct--->from--->where--->group by--->having
执行顺序:from--->where--->group by--->having--->distinct--->select
01、将重复的部门数据去重
select distinct post from emp; # distinct 后面跟着去重的字段名
select distinct post, id from emp; # 注意:去重的字段名,必须是重复的,只要有不重复的字段,后续字段就无法去重
7、order by: 排序 ,默认升序。asc 表示 升序,desc 表示 降序
书写顺序:select--->from--->where--->group by--->having--->order by
执行顺序:from--->where--->group by--->having--->select--->order by
01、根据薪资进行升序
select salary from emp order by salary asc;
02、根据年龄进行降序排列
select age from emp order by age desc;
03、先按照age升序,再按照salary降序
select age, salary from emp order by age asc, salary desc;
04、统计 各部门(分组) 年龄在10岁以上的员工平均工资,并且保留平均工资大于1000的部门,然后对平均工资进行升序序
select post, avg(salary) from emp where age > 10 group by post having avg(salary) > 1000 order by avg(salary) asc;
select post, avg(salary) from emp where age > 18 group by post having avg(salary) > 1000 order by avg(salary) asc;
8、limit: 限制查询记录的数量 和 分页
书写顺序:select--->from--->order by--->limit
执行顺序:from--->select--->order by--->limit
limit可以有两个参数, 参数1: 是限制的开始位置 + 1, 参数2:是从开始位置展示的条数;
01、从第一条开始,获取4条记录;
select * from emp limit 4;
select * from emp limit 0, 4;
02、从第六条数据开始查找,获取4条
select * from emp limit 5, 4; # 从第五条数据开始查找,获取4条
03、查询工资最高的人的 详细信息
select * from emp order by salary desc limit 1;
select max(salary) from emp; # 聚合函数: 若没有group by 分组,默认将查出来的数据当做一个分组, 也能使用;
9、正则:在编程中,凡是看到reg开头的,基本上都是跟正则有关
select * from emp where name regexp '^程.*(金|银|铜|铁)$'; # 正则中 * 表示 0 或 多个 。 ^ 表示以什么什么开头 。$ 表示以什么什么结尾
三、多表查询
查询 员工 以及所在 部门 的信息;
select * from emp2, dep2 where emp2.dep_id = dep2.id; # 通过where 约束条件
查询 部门 为 技术部 的 员工 及 部门信息
select emp2.name, dep2.* from emp2, dep2 where emp2.dep_id = dep2.id and dep2.name = '技术';
1、联表查询
01、内连接:只取两张表有对应关系的记录(表1 inner join 表2)
例: 查询 员工 以及所在 部门 的信息;
select * from emp2 inner join dep2 on emp2.dep_id = dep2.id;
02、左连接:在内连接的基础上保留左表没有对应关系的记录(表1 left join 表2)
例:查询 员工 以及所在 部门 的信息;
select * from emp2 left join dep2 on emp2.dep_id = dep2.id;
03、右连接:在内连接的基础上保留右表没有对应关系的记录(表1 right join 表2)
例:查询 员工 以及所在 部门 的信息;
select * from emp2 right join dep2 on emp2.dep_id = dep2.id;
04、全连接:在内连接的基础上 保留左、右表没有对应关系的记录(表1 left join 表2 union 表1 right join 表2 )
例:查询 员工 以及所在 部门 的信息;
select * from emp2 left join dep2 on emp2.dep_id = dep2.id
union
select * from emp2 right join dep2 on emp2.dep_id = dep2.id;
2、子查询:就是将一个查询语句的结果用括号括起来,当做另一个查询语句的条件去用
01、查询部门是 技术 或者 人力资源 的员工信息
select * from emp2 where dep_id in
(select id from dep2 where name = '技术' or name = '人力资源'); #部门是 技术 或者 人力资源 的id 先查出来了。
02、查询每个部门最先入职的员工 思路:先查每个部门最先入职的员工,再按部门对应上联表查询
select t1.id, t1.name, t1.hire_date, t2.* # 第四步:查询每个部门最先入职的员工
from
emp as t1
inner join # 第二步:拼接了 t1(emp )与 t2(各部门最先入职的员工数据虚拟表)表的数据
(select post, max(hire_date) as max_date from emp group by post) as t2 # 第一步:子查询获取emp表中的 部门名称与最先入职的时间字段值 生成一张虚拟表
on
t1.post = t2.post
where t1.hire_date = t2.max_date; # 第三步:条件:t1(emp )中的入职时间=t2(各部门最先入职的员工数据虚拟表)中的最大数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号