文件操作 字符编码、深浅拷贝
一、字符编码:
python解释器与文件本编辑对操作文件的流程:
1.先启动python解释器\文件本编辑
2.将文件内容从硬盘读入内存
3. python解释器:将文件内容读入内存后,可不是为了给你瞅一眼python代码写的啥,而是为了执行python代码、会识别python语法
文本编辑器:将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法
二、编码(encode)与解码(decode)
注:在文件的头部 加 # coding utf-8或gbk 才能在python2中使用文件
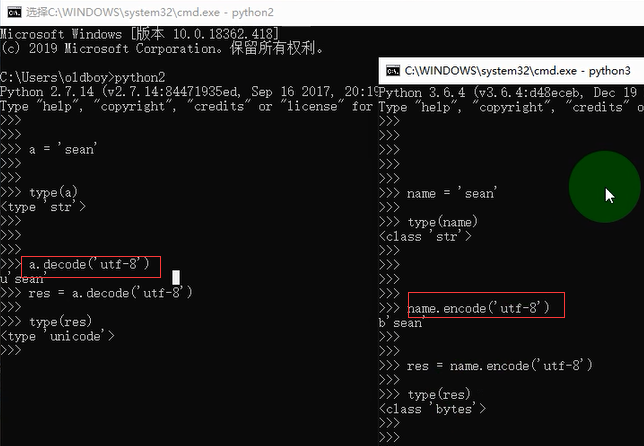
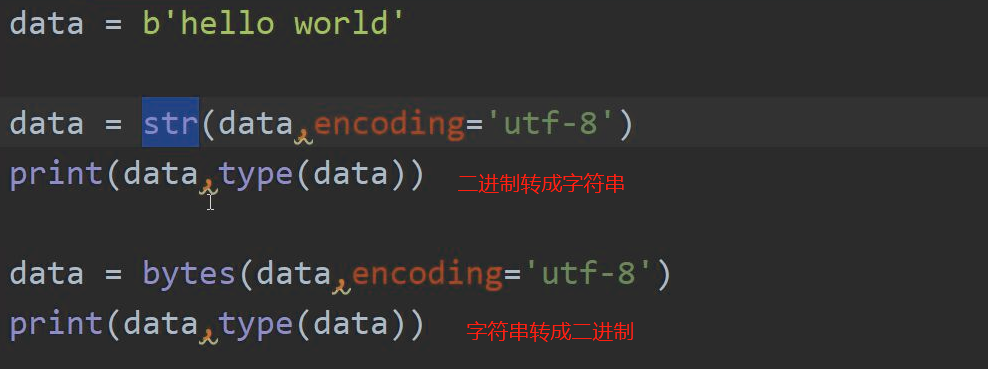
1.由unicode转换成其他编码,或字符转换成内存中的unicode的过程,都称为编码encode
2.由其他编码转换成unicode,或内存中的unicode转换成字符的过程,都称为解码decode
3.在Python3中,字符串类的值都是使用unicode格式来存储
4.在Python2中,字符串类的值都是使用8个bit位格式来存储
5.python2推出了在字符串类型前加u,则会将字符串类型强制存储unicode
x='上' # 在python3在'上'被存成unicode
res=x.encode('utf-8') # unicode编码成了utf-8格式
res,type(res) # 而编码的结果为bytes类型
例子:
6.保证不乱码核心:
用什么编码存的数据,就用什么编码取
utf-8: 英文 1个字节,汉字3个字节
gbk:英文半角1个字节,英文全角2个字节,汉字3个字节
三、文件
1、什么是文件:操作系统提供给你操作硬盘的一个工具
2、为什么要用文件: 因为人类和计算机要永久保存数据
3、怎么用文件
相对路径: a.txt 必须与当前py文件在同一级目录.相对路径要有一个参照文件的
绝对路径: 要找到根目录
4.打开文件的方法:
open 函数
f=open('a.txt',mode='r',encoding='utf-8') # mode表示类型,可以省略不写mode单词。 r 既是 rt (read text) rb 既是 read bytes
f=open('a.txt','r',encoding='utf-8') # 相对路径,打开模式为r
f=open(D:\项目路径\python13期\day07\a.txt,'r',encoding='utf-8') # 绝对路径,打开模式为r
with open(r'dir\b.txt','w',encoding='gbk')as f: # 相对路径,打开模式为w r表示转义特殊字符\ as f 表示文件简化成 f 方便 运 用文件的方法
with open(r'D:\项目路径\python13期\day07\a.txt','w',encoding='gbk')as f: # 绝对路径,打开模式为w r表示转义特殊字符\
with 表示会自动帮你回收操作系统的资源,无需自己操作,不用自己取关闭文件
5.文件的内置方法
f.read() 表示把文件里的文字一次性依次读出,缺点:当数据过大时,内存溢出
f.read(数字) 数字表示从光标往后对几个字符
f.readline() 表示执行一次读出一行内容
f.readlines() 表示把文件里的文字读到列表里
f.readable() 表示判断当前文件是否可读,返回布尔值
f.close() 表示关闭,释放空间,回收操作系统的资源
f.closed() 表示判断文件是否关闭了
f.write() 表示往文件里的文字依次写东西
f.writable() 表示判断当前文件是否可写,返回布尔值
f.wtitelines() 表示for+f.write()
f.encoding() 表示查看文件是以什么编码存的
f.tell() 表示查看文本中光标的位置,返回的是字节
f.seek(指针移动的字节数,模式) 表示移动指针的位置。(原来默认的是在文字的末尾)
注意:
0:表示 指针从文件开头
1:表示 指针从当前位置
2:表示 指针从文件末尾
6.文件的操作
r :只读。如果文件不存在,会报错
w:只写(慎用)
01、如果文件不存在,则新建一个文件写入数据
02、如果文件内存在数据,会将数据清空,重新写入
a:只追加写
01、如果文件内存在数据,会在已有数据的后面追加数据
02、如果文件不存在,则新建一个文件写入数据
7.文件的遍历
for i in f
或者
for line in f
8.文件处理模式:
t:文本模式 :只能用于操作文本文件,无论读写,都以字符串为单位,存取硬盘事物本质是二进制形式
只能与r\w\a连用
默认情况下,是rt模式
必须指定 encoding
b:bytes模式 :针对非文本文件(图片,视频,音频)只能使用b模式。
只能与r\w\a连用
处理二进制数据
一定不能指定 encoding . 因为是用字节读取数据的,数据本身就是二进制。
四、列表的深浅copy
浅拷贝:复本只拷了原本的最外层地址。修改复本的可变类型元素值时,对应的原本的元素的值随之改变。修改复本的不可变类型的元素值时,对应的原本的元素值不改变
深拷贝:复本除了拷贝原本的最外层地址,还继续往里往深层拷贝原本的可变类型元素的地址,直到把所有的可变类型的元素的地址拷贝完。
修改复本的可变类型元素值时,对应的原本的元素的值不改变。修改复本的不可变类型的元素值时,对应的原本的元素值不改变。
既是:复本与原本无任何关系了。
四、列表的深浅copy
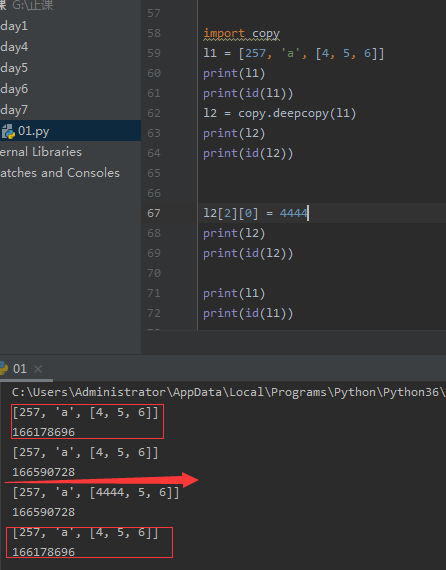
深层拷贝 是外层地址和可变类型的地址 与原来的不一样。不可变类型的地址与原来的一样。修改内层的值时,同不改变原来的。l2 =copy.deepcopy(l1)
浅层拷贝 只是外层地址与原来的不一样。修改内层的值时,同时也改变原来的。 l2=l1.copy()
深层拷贝
import copy #导入 copy l1 = [257, 'a', [4, 5, 6]] print(l1) print(id(l1)) l2 = copy.deepcopy(l1) #深层copy l2[2][0] = 4444 print(l2) print(id(l2))
print(l1) print(id(l1))
结果:
五、文件的修改
方式一: with open ('b.txt',mode='rt',encoding='utf-8') as f: #实现原理:将文件内容一次性读入内存,然后在内存修改完后再覆盖 写入原文件
data=f.read() 优点:在文件修改过程中同一份数据只有一份
with open('b.txt,mode='wt',encofing='utf-8') as f: 缺点:会过多的占用内存
f.write(data.replace('你好傻','大笨蛋'))
方式二: import os
with open('b.txt',mode='rt',encoding='utf-8') as rf,open('bb.txt',mode='wt',encoding='utf-8') as wf:
for line in rf: 实现原理:以读的方式打开原文件,以写的方式打开一个临时文件,一行行读取原 文件内容,修改完后写入临时文件。删除原文件,将临时文件重命名为原文件名
wf.write(line.replace('你好笨',‘大傻子’)) 优点:不会占用过多的内存
os.remove('b.txt') #删除原文件 缺点:在修改过程中数据存了两份
os.rename('bb.txt','b.txt') #把临时文件命名为原文件名

 浙公网安备 33010602011771号
浙公网安备 33010602011771号