
MariaDB 层常用业务
前言 - 简单准备一下前戏
前面写过几篇mariadb 数据的随笔, 多数偏C/C++层面. 这次分享一下平时开发中, 处理的一些数据层面的业务.
对于MariaDB, 不做过多介绍. 如果你有Ubuntu 系统, 可以通过下面来个环境玩玩
# 先搜索要的包, 再去安装 apt-cache search mariadb sudo apt-get install mariadb-server sudo apt-get install mariadb-client # 进入mariadb 开始操作 sudo mysql -uroot status
这里扯一下, 假如你复制mysql 脚本到 mariadb中执行, 出现下面字符串
Display all 475 possibilities? (y or n)
造成原因是MariaDB中对Tab处理的问题, 你需要将脚本串中Tab替换成空格. 如果你用的是notepad++ 可以做下面操作

-> 编程语言多了, 什么扯坑都有. 多习惯就成经验了, 一朝鲜吃遍天~~ 只能开心就好~~.
在好戏出现之前, 我们需要一些测试的基础数据.执行下面的构建脚本
-- 1.1 先构建实验前戏 create database test; use test; create table t_rand ( -- 推荐 设计主键的时候 id 为 bigint, int 为历史原因 id int unsigned not null primary key ); -- 4.1 先构建数据, 我们就以 t_rand 表为例 drop table if exists t_score; create table t_score(score int); insert into t_score value(1); insert into t_score value(2); insert into t_score value(10); insert into t_score value(10); insert into t_score value(10); insert into t_score value(3); insert into t_score value(4); insert into t_score value(6); insert into t_score value(5); select * from t_score;
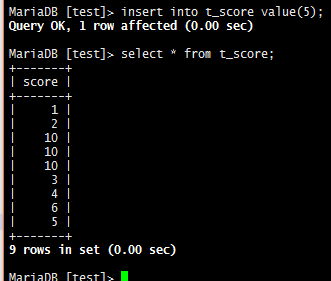
-> 到这基本的储备工作已经完成了, 那我们开始吧~
正文 - 从实际业务出发
扯个谈吧, 这篇文章挺不错的 你为什么会离开游戏行业?
1. 生成8位随机数业务
有时候按照产品需求希望生成int 8位的随机id. 常见做法是单独搞一个随机数表,这样做有点小恶心.
后面我弄了投机取巧的办法.八位随机数范围[10000000, 99999999] 我把它切分为
[10000000, 89999999] and [90000000, 99999999]两部分生成,
前半分采用rand and check. 后半部分采用 max + 1. 总的思路如下
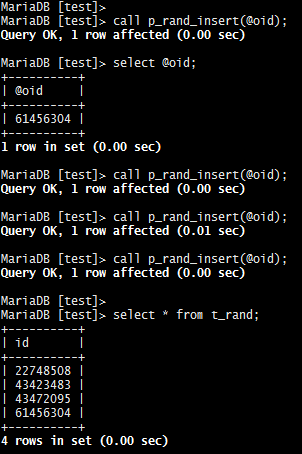
-- 1.2 开始构建存储过程 drop procedure if exists p_rand_insert; delimiter $ create procedure p_rand_insert(out oid int unsigned) begin declare mi int unsigned; declare si int unsigned default 10000000; declare ei int unsigned default 70000000; declare i tinyint default 3; declare f tinyint default 0; while i > 0 && f = 0 do set f = 1; set mi = floor(si + ei * rand()); select 0 into f from t_rand where id = mi limit 1; set i = i - 1; end while; if f = 0 then select max(id) into mi from t_rand; if mi < ei + si then set mi = ei + si; end if; set mi = mi + 1; end if; insert into t_rand value(mi); set oid = mi; end $ delimiter ;
不妨测试一下,
-- 1.3 开始构建测试数据 truncate table t_rand; call p_rand_insert(@oid); select @oid; call p_rand_insert(@oid); call p_rand_insert(@oid); call p_rand_insert(@oid); select * from t_rand;
得到的结果如下, 扯一点这个需求前期在于保护游戏内部一些隐私数据. 哈哈, 其实对于隐私数据就可以不显示才是最好.
2. 清除db上面所有数据
经常需要清除数据, 这里写了个脚本直接清除指定DB上所有数据. 大家可以尝试用一下.
-- 2. 清除db上面所有数据 drop procedure if exists p_truncate; delimiter $ create procedure p_truncate(dbname varchar(64)) begin declare tname varchar(64); declare lop tinyint default 1; -- 声明游标 declare getnames cursor for select table_name from information_schema.tables where table_type = 'BASE TABLE' and table_schema = dbname; -- 声明handler 必须在游标声明之后, 当游标数据读取完毕会触发下面set declare continue handler for not found set lop = 0; -- 打开游标 open getnames; -- 操作游标, 读取第一行数据 fetch getnames into tname; while lop = 1 do set @tsql = concat('truncate table ', dbname, '.', tname); prepare stmt from @tsql; execute stmt; deallocate prepare stmt; -- 读取下一个行数据 fetch getnames into tname; end while; -- 关闭游标 close getnames; end $ delimiter ;
使用也很简单, 看下面小例子, 后面也有数据图演示
-- 2.1 测试清除所有数据 select * from test.t_rand; call p_truncate('test'); select * from test.t_rand;
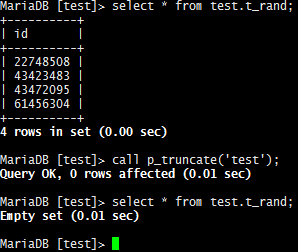
对于实现的细节部分, 查查帮助手册就明白了. 再补充一点, truncate 和 delete 区别. 直观上前者特别快.
后者慢在 删除的过程是每次从表中删除一行,并且会将该行的删除操作作为事务记录到日志中.
当然了truncate一个小细节, 它会干掉 auto_increment 当前的种子值, 让其变成0.
3. 导出数据库表结构和表数据
这个在项目移植的时候会用上就一句话
sudo mysqldump -uroot -d test > test_d.sql
-h -p 自己什么环境自己补上, 我就本地测试没有密码. -d 表示不导出表数据. 如果只是为了导出特定的表. 可以写成 test t_rand
写到这里让我想起了那时候刚工作的第二年, 看见运维大拿写出这段话. 当时 心里 就 1万个敬佩, wow 好厉害~
n年过去了, 不知道那些人还好吗, 哈哈, 估计菜鸡的我没机会再敬他们一杯了 ~
4. 后台统计需要排序
这个业务很普遍, 无外乎下面两种. 用 t_score表做测试. 直接看图吧.

-- 4.2 够好排序
select t.score,
(select count(s.score) + 1 from t_score s where s.score > t.score) rank
from t_score t order by t.score desc;
另外一种, 1->2->3...这种来回搞
-- 4.3 都好排序 select t.score, (select count(s.score) + 1 from (select score from t_score group by score) s where s.score > t.score) rank from t_score t order by t.score desc;

到这里基本上数据库(mariadb or mysql) 开发层面的业务也介绍了一些了.哈哈, 下次有机会再补充.
突然毫无征兆想起一句话, 优化是毒药.
后记 - 一切如旧的结束
错误是难免的欢迎指正, O(∩_∩)O哈哈~ 人生路很长, 已在脱贫路上奋勇向前了 (๑╹◡╹)ノ""" 不能给党丢饭~
似水年华 http://music.163.com/#/song?id=399954010


