
C 简单处理excel 转成 json
引言
工作中常需要处理excel转json问题. 希望这篇博文能简单描述这个问题.并提供一种解决
思路.提升感悟.
今天我们处理的事就是为了把 xlsm => json. 一种方式是. 去 google 在 stackover上搜
c readxlsm/readxls 库. 也可以解决. 但是跨平台需要配置. 这里介绍一种有意思的方式. 来处理read.
首先我们的目标文件是
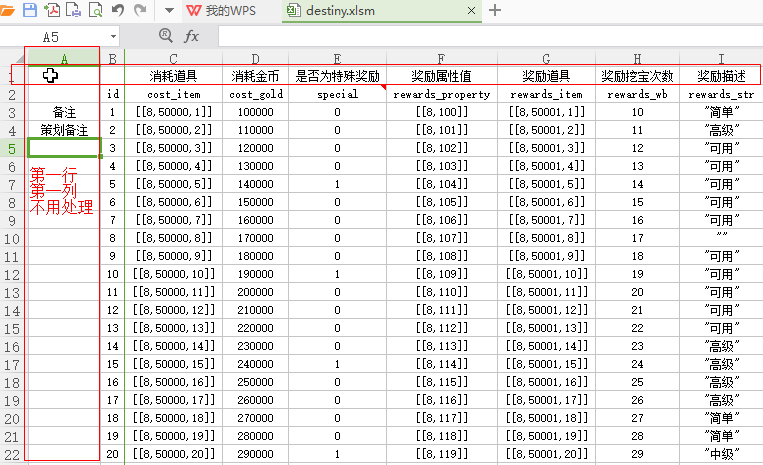
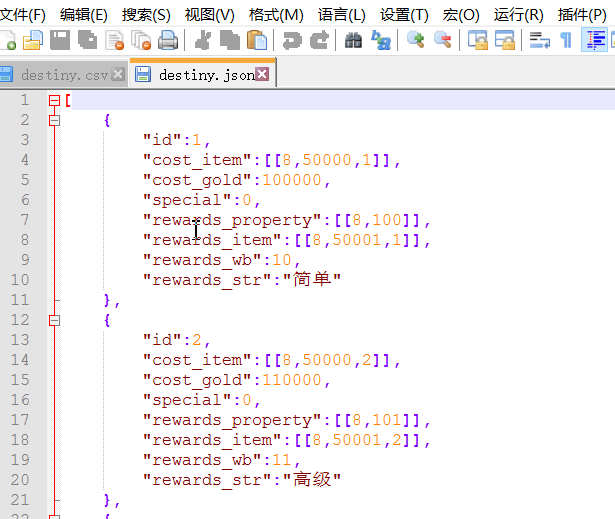
生成的最后内容希望是
前言
这里会扯一点C能够处理xlsm, 但是这些高级文件格式还是上层语言处理的爽一点. C去处理真的是屠龙刀杀泥鳅.
心累.但是本文一定会处理的哪怕再复杂. 就是要倚天剑烤鸡翅.
首先来点开胃小菜. C 如何生成一个 下面的demo.xlsm

处理代码 demo.c
#include <stdio.h> /* 生成一个 xlsm 文件 * * demo.xlsm * hello world * begin end * 加油 新的开始 */ int main(int argc, char* argv[]) { FILE* xlsm = fopen("demo.xlsm", "wb"); if(xlsm == NULL) { fprintf(stderr, "fopen demo.xlsm is error\n"); return -1; } // 处理输出 fprintf(xlsm,"hello\tworld\n"); fprintf(xlsm,"begin\tend\n"); fprintf(xlsm,"\t加油\t新的开始\n"); fclose(xlsm); puts("demo.xlsm 生成成功!"); return 0; }
是不是很有意思. 其实生成的本质, 我们用 Notepad++ 打开 demo.xlsm
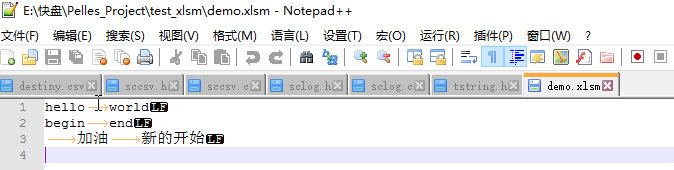
其实是我们使用的 execel处理工具为我们解析成了excel格式. 也是一种方式吧. 欢迎尝试. 这里扯一点.
我一直使用WPS, 也很喜欢WPS. 但是觉得WPS适合个人阅读. 对于工作处理特别是VBA 感觉不好. 关于工作
中 excel => json都是内部VBA 代码在 Ctrl + S的时候执行的. 最近想优化一下公司的 vba代码,但是自己用的
是wps 有心无力. (wps 处理文件还是有点慢, 宏和vba专业功能支持的蛋疼.)
推荐逼格高, 还是用微软的 office最新版专业(旗舰)破解版吧. 毕竟Microsoft 是通过 office 腾飞的. 值得用破解版.
下面我们要到正题了.
本文需要用的辅助文件. 后面源码中处理的函数调用实现都在下面文件找找到定义.
schead.h


#ifndef _H_SCHEAD #define _H_SCHEAD #include <stdio.h> #include <stdlib.h> #include <stdbool.h> #include <errno.h> #include <string.h> #include <time.h> #include <stdint.h> #include <stddef.h> /* * 1.0 错误定义宏 用于判断返回值状态的状态码 _RF表示返回标志 * 使用举例 : int flag = scconf_get("pursue"); if(flag != _RT_OK){ sclog_error("get config %s error! flag = %d.", "pursue", flag); exit(EXIT_FAILURE); } * 这里是内部 使用的通用返回值 标志 */ #define _RT_OK (0) //结果正确的返回宏 #define _RT_EB (-1) //错误基类型,所有错误都可用它,在不清楚的情况下 #define _RT_EP (-2) //参数错误 #define _RT_EM (-3) //内存分配错误 #define _RT_EC (-4) //文件已经读取完毕或表示链接关闭 #define _RT_EF (-5) //文件打开失败 /* * 1.1 定义一些 通用的函数指针帮助,主要用于基库的封装中 * 有构造函数, 释放函数, 比较函数等 */ typedef void* (*pnew_f)(); typedef void (*vdel_f)(void* node); // icmp_f 最好 是 int cmp(const void* ln,const void* rn); 标准结构 typedef int (*icmp_f)(); /* * c 如果是空白字符返回 true, 否则返回false * c : 必须是 int 值,最好是 char 范围 */ #define sh_isspace(c) \ ((c==' ')||(c>='\t'&&c<='\r')) /* * 2.0 如果定义了 __GNUC__ 就假定是 使用gcc 编译器,为Linux平台 * 否则 认为是 Window 平台,不可否认宏是丑陋的 */ #if defined(__GNUC__) //下面是依赖 Linux 实现,等待毫秒数 #include <unistd.h> #include <sys/time.h> #define SLEEPMS(m) \ usleep(m * 1000) #else // 这里创建等待函数 以毫秒为单位 , 需要依赖操作系统实现 #include <Windows.h> #include <direct.h> // 加载多余的头文件在 编译阶段会去掉 #define rmdir _rmdir /** * Linux sys/time.h 中获取时间函数在Windows上一种移植实现 **tv : 返回结果包含秒数和微秒数 **tz : 包含的时区,在window上这个变量没有用不返回 ** : 默认返回0 **/ extern int gettimeofday(struct timeval* tv, void* tz); //为了解决 不通用功能 #define localtime_r(t, tm) localtime_s(tm, t) #define SLEEPMS(m) \ Sleep(m) #endif /*__GNUC__ 跨平台的代码都很丑陋 */ //3.0 浮点数据判断宏帮助, __开头表示不希望你使用的宏 #define __DIFF(x, y) ((x)-(y)) //两个表达式做差宏 #define __IF_X(x, z) ((x)<z&&(x)>-z) //判断宏,z必须是宏常量 #define EQ(x, y, c) EQ_ZERO(__DIFF(x,y), c) //判断x和y是否在误差范围内相等 //3.1 float判断定义的宏 #define _FLOAT_ZERO (0.000001f) //float 0的误差判断值 #define EQ_FLOAT_ZERO(x) __IF_X(x,_FLOAT_ZERO) //float 判断x是否为零是返回true #define EQ_FLOAT(x, y) EQ(x, y, _FLOAT_ZERO) //判断表达式x与y是否相等 //3.2 double判断定义的宏 #define _DOUBLE_ZERO (0.000000000001) //double 0误差判断值 #define EQ_DOUBLE_ZERO(x) __IF_X(x,_DOUBLE_ZERO) //double 判断x是否为零是返回true #define EQ_DOUBLE(x,y) EQ(x, y, _DOUBLE_ZERO) //判断表达式x与y是否相等 //4.0 控制台打印错误信息, fmt必须是双引号括起来的宏 #ifndef CERR #define CERR(fmt, ...) \ fprintf(stderr,"[%s:%s:%d][error %d:%s]" fmt "\r\n",\ __FILE__, __func__, __LINE__, errno, strerror(errno),##__VA_ARGS__) #endif/* !CERR */ //4.1 控制台打印错误信息并退出, t同样fmt必须是 ""括起来的字符串常量 #ifndef CERR_EXIT #define CERR_EXIT(fmt,...) \ CERR(fmt,##__VA_ARGS__),exit(EXIT_FAILURE) #endif/* !ERR */ #ifndef IF_CERR /* *4.2 if 的 代码检测 * * 举例: * IF_CERR(fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP), "socket create error!"); * 遇到问题打印日志直接退出,可以认为是一种简单模板 * code : 要检测的代码 * fmt : 必须是""括起来的字符串宏 * ... : 后面的参数,参照printf */ #define IF_CERR(code, fmt, ...) \ if((code) < 0) \ CERR_EXIT(fmt, ##__VA_ARGS__) #endif //!IF_CERR #ifndef IF_CHECK /* * 是上面IF_CERR 的简化版很好用 */ #define IF_CHECK(code) \ if((code) < 0) \ CERR_EXIT(#code) #endif // !IF_CHECK //5.0 获取数组长度,只能是数组类型或""字符串常量,后者包含'\0' #ifndef LEN #define LEN(arr) \ (sizeof(arr)/sizeof(*(arr))) #endif/* !ARRLEN */ //6.0 程序清空屏幕函数 #ifndef CONSOLE_CLEAR #ifndef _WIN32 #define CONSOLE_CLEAR() \ system("printf '\ec'") #else #define CONSOLE_CLEAR() \ system("cls") #endif/* _WIN32 */ #endif /*!CONSOLE_CLEAR*/ //7.0 置空操作 #ifndef BZERO //v必须是个变量 #define BZERO(v) \ memset(&v,0,sizeof(v)) #endif/* !BZERO */ //9.0 scanf 健壮的 #ifndef SAFETY_SCANF #define SAFETY_SCANF(scanf_code,...) \ while(printf(__VA_ARGS__),scanf_code){\ while(getchar()!='\n');\ puts("输入出错,请按照提示重新操作!");\ }\ while(getchar()!='\n') #endif /*!SAFETY_SCANF*/ //10.0 简单的time帮助宏 #ifndef TIME_PRINT #define TIME_PRINT(code) {\ clock_t __st,__et;\ __st=clock();\ code\ __et=clock();\ printf("当前代码块运行时间是:%lf秒\n",(0.0+__et-__st)/CLOCKS_PER_SEC);\ } #endif /*!TIME_PRINT*/ /* * 10.1 这里是一个 在 DEBUG 模式下的测试宏 * * 用法 : * DEBUG_CODE({ * puts("debug start..."); * }); */ #ifndef DEBUG_CODE # ifdef _DEBUG # define DEBUG_CODE(code) code # else # define DEBUG_CODE(code) # endif // ! _DEBUG #endif // !DEBUG_CODE //11.0 等待的宏 是个单线程没有加锁 #define _STR_PAUSEMSG "请按任意键继续. . ." extern void sh_pause(void); #ifndef INIT_PAUSE # ifdef _DEBUG # define INIT_PAUSE() atexit(sh_pause) # else # define INIT_PAUSE() (void)316 /* 别说了,都重新开始吧 */ # endif #endif/* !INIT_PAUSE */ //12.0 判断是大端序还是小端序,大端序返回true extern bool sh_isbig(void); /** * sh_free - 简单的释放内存函数,对free再封装了一下 **可以避免野指针 **pobj:指向待释放内存的指针(void*) **/ extern void sh_free(void** pobj); /** * 获取 当前时间串,并塞入tstr中长度并返回 ** 使用举例 char tstr[64]; sh_times(tstr, LEN(tstr)); puts(tstr); **tstr : 保存最后生成的最后串 **len : tstr数组的长度 ** : 返回tstr首地址 **/ extern int sh_times(char tstr[], int len); /* * 比较两个结构体栈上内容是否相等,相等返回true,不等返回false * a : 第一个结构体值 * b : 第二个结构体值 * : 相等返回true, 否则false */ #define STRUCTCMP(a, b) \ (!memcmp(&a, &b, sizeof(a))) #endif/* ! _H_SCHEAD */
schead.c
#include <schead.h> //简单通用的等待函数 void sh_pause(void) { rewind(stdin); printf(_STR_PAUSEMSG); getchar(); } //12.0 判断是大端序还是小端序,大端序返回true bool sh_isbig(void) { static union { unsigned short _s; unsigned char _c; } __u = { 1 }; return __u._c == 0; } /** * sh_free - 简单的释放内存函数,对free再封装了一下 **可以避免野指针 **@pobj:指向待释放内存的指针(void*) **/ void sh_free(void** pobj) { if (pobj == NULL || *pobj == NULL) return; free(*pobj); *pobj = NULL; } #if defined(_MSC_VER) /** * Linux sys/time.h 中获取时间函数在Windows上一种移植实现 **tv : 返回结果包含秒数和微秒数 **tz : 包含的时区,在window上这个变量没有用不返回 ** : 默认返回0 **/ int gettimeofday(struct timeval* tv, void* tz) { time_t clock; struct tm tm; SYSTEMTIME wtm; GetLocalTime(&wtm); tm.tm_year = wtm.wYear - 1900; tm.tm_mon = wtm.wMonth - 1; //window的计数更好写 tm.tm_mday = wtm.wDay; tm.tm_hour = wtm.wHour; tm.tm_min = wtm.wMinute; tm.tm_sec = wtm.wSecond; tm.tm_isdst = -1; //不考虑夏令时 clock = mktime(&tm); tv->tv_sec = (long)clock; //32位使用,接口已经老了 tv->tv_usec = wtm.wMilliseconds * 1000; return _RT_OK; } #endif /** * 获取 当前时间串,并塞入tstr中C长度并返回 ** 使用举例 char tstr[64]; puts(gettimes(tstr, LEN(tstr))); **tstr : 保存最后生成的最后串 **len : tstr数组的长度 ** : 返回tstr首地址 **/ int sh_times(char tstr[], int len) { struct tm st; time_t t = time(NULL); localtime_r(&t, &st); return (int)strftime(tstr, len, "%F %X", &st); }
sclog.h
#ifndef _H_SCLOG #define _H_SCLOG //-------------------------------------------------------------------------------------------| // 第一部分 共用的参数宏 //-------------------------------------------------------------------------------------------| // //关于日志切分,需要用第三方插件例如crontab , 或者下次我自己写一个监测程序. #define _INT_LITTLE (64) //保存时间或IP长度 #define _INT_LOG (1024<<3) //最多8k日志 #define _STR_SCLOG_PATH "log" //日志相对路径目录,如果不需要需要配置成"" #define _STR_SCLOG_LOG "sc.log" //普通log日志 DEBUG,INFO,NOTICE,WARNING,FATAL都会输出 #define _STR_SCLOG_WFLOG "sc.log.wf" //级别比较高的日志输出 FATAL和WARNING /** * fstr : 为标识串 例如 _STR_SCLOG_FATAL, 必须是双引号括起来的串 ** ** 拼接一个 printf 输出格式串 **/ #define SCLOG_PUTS(fstr) \ "%s][" fstr "][%s:%d:%s][logid:%u][reqip:%s][mod:%s]" #define _STR_SCLOG_FATAL "FATAL" //错误,后端使用 #define _STR_SCLOG_WARNING "WARNING" //警告,前端使用错误,用这个 #define _STR_SCLOG_NOTICE "NOTICE" //系统使用,一般标记一条请求完成,使用这个日志 #define _STR_SCLOG_INFO "INFO" //普通的日志打印 #define _STR_SCLOG_TRACE "TRACE" #define _STR_SCLOG_DEBUG "DEBUG" //测试用的日志打印,在发布版这些日志会被清除掉 /** * fstr : 只能是 _STR_SCLOG_* 开头的宏 ** fmt : 必须是""括起来的宏.单独输出的格式宏 ** ... : 对映fmt参数集 ** ** 拼接这里使用的宏,为sl_printf 打造一个模板,这里存在一个坑,在Window \n表示 CRLF, Unix就是LF **/ #define SCLOG_PRINTF(fstr, fmt, ...) \ sl_printf(SCLOG_PUTS(fstr) fmt "\n", sl_get_times(), __FILE__, __LINE__, __func__, \ sl_get_logid(), sl_get_reqip(), sl_get_mod(), ##__VA_ARGS__) /** * FATAL... 日志打印宏 ** fmt : 输出的格式串,需要""包裹起来 ** ... : 后面的参数,服务于fmt **/ #define SL_FATAL(fmt, ...) SCLOG_PRINTF(_STR_SCLOG_FATAL, fmt, ##__VA_ARGS__) #define SL_WARNING(fmt, ...) SCLOG_PRINTF(_STR_SCLOG_WARNING, fmt, ##__VA_ARGS__) #define SL_NOTICE(fmt, ...) SCLOG_PRINTF(_STR_SCLOG_NOTICE, fmt, ##__VA_ARGS__) #define SL_INFO(fmt, ...) SCLOG_PRINTF(_STR_SCLOG_INFO, fmt, ##__VA_ARGS__) // 发布状态下,关闭SL_DEBUG 宏,需要重新编译,没有改成运行时的判断,这个框架主要围绕单机部分多服务器 #if defined(_DEBUG) # define SL_TRACE(fmt, ...) SCLOG_PRINTF(_STR_SCLOG_TRACE, fmt, ##__VA_ARGS__) # define SL_DEBUG(fmt, ...) SCLOG_PRINTF(_STR_SCLOG_DEBUG, fmt, ##__VA_ARGS__) #else # define SL_TRACE(fmt, ...) (void)0x123 /* 人生难道就是123*/ # define SL_DEBUG(fmt, ...) (void)0xa91 /* 爱过哎 */ #endif //-------------------------------------------------------------------------------------------| // 第二部分 对日志信息体操作的get和set,这里隐藏了信息体的实现 //-------------------------------------------------------------------------------------------| /** * 线程的私有数据初始化 ** ** mod : 当前线程名称 ** reqip : 请求的ip ** return : _RT_OK 表示正常,_RF_EM内存分配错误 **/ extern int sl_pecific_init(const char* mod, const char* reqip); /** * 重新设置线程计时时间 ** 正常返回 _RT_OK, _RT_EM表示内存没有分配 **/ int sl_set_timev(void); /** * 获取日志信息体的唯一的logid **/ unsigned sl_get_logid(void); /** * 获取日志信息体的请求ip串,返回NULL表示没有初始化 **/ const char* sl_get_reqip(void); /** * 获取日志信息体的时间串,返回NULL表示没有初始化 **/ const char* sl_get_times(void); /** * 获取日志信息体的名称,返回NULL表示没有初始化 **/ const char* sl_get_mod(void); //-------------------------------------------------------------------------------------------| // 第三部分 对日志系统具体的输出输入接口部分 //-------------------------------------------------------------------------------------------| /** * 日志系统首次使用初始化,找对对映日志文件路径,创建指定路径 **/ extern void sl_start(void); /** * 这个函数不希望你使用,是一个内部限定死的日志输出内容.推荐使用相应的宏 **打印相应级别的日志到对映的文件中. ** ** format : 必须是""号括起来的宏,开头必须是 [FALTAL:%s]后端错误 ** [WARNING:%s]前端错误, [NOTICE:%s]系统使用, [INFO:%s]普通信息, ** [DEBUG:%s] 开发测试用 ** ** return : 返回输出内容长度 **/ int sl_printf(const char* format, ...); #endif // !_H_SCLOG
sclog.c
#include <sclog.h> #include <schead.h> #include <scatom.h> #include <pthread.h> #include <stdarg.h> //-------------------------------------------------------------------------------------------| // 第二部分 对日志信息体操作的get和set,这里隐藏了信息体的实现 //-------------------------------------------------------------------------------------------| //线程私有数据 __lkey, __lonce为了__lkey能够正常初始化 static pthread_key_t __lkey; static pthread_once_t __lonce = PTHREAD_ONCE_INIT; static unsigned __logid = 0; //默认的全局logid,唯一标识 //内部简单的释放函数,服务于pthread_key_create 防止线程资源泄露 static void __slinfo_destroy(void* slinfo) { //printf("pthread 0x%p:0x%p destroy!\n", pthread_self().p, slinfo); free(slinfo); } static void __gkey(void) { pthread_key_create(&__lkey, __slinfo_destroy); } struct slinfo { unsigned logid; //请求的logid,唯一id char reqip[_INT_LITTLE]; //请求方ip char times[_INT_LITTLE]; //当前时间串 struct timeval timev; //处理时间,保存值,统一用毫秒 char mod[_INT_LITTLE]; //当前线程的模块名称,不能超过_INT_LITTLE - 1 }; /** * 线程的私有数据初始化 ** ** mod : 当前线程名称 ** reqip : 请求的ip ** return : _RT_OK 表示正常,_RF_EM内存分配错误 **/ int sl_pecific_init(const char* mod, const char* reqip) { struct slinfo* pl; //保证 __gkey只被执行一次 pthread_once(&__lonce, __gkey); if((pl = pthread_getspecific(__lkey)) == NULL){ //重新构建 if ((pl = malloc(sizeof(struct slinfo))) == NULL) return _RT_EM; //printf("pthread 0x%p:0x%p create!\n", pthread_self().p,pl); } gettimeofday(&pl->timev, NULL); pl->logid = ATOM_ADD_FETCH(__logid, 1); //原子自增 strcpy(pl->mod, mod); //复制一些数据 strcpy(pl->reqip, reqip); //设置私有变量 pthread_setspecific(__lkey, pl); return _RT_OK; } /** * 重新设置线程计时时间 ** 正常返回 _RT_OK, _RT_EM表示内存没有分配 **/ int sl_set_timev(void) { struct slinfo* pl = pthread_getspecific(__lkey); if (NULL == pl) return _RT_EM; gettimeofday(&pl->timev, NULL); return _RT_OK; } /** * 获取日志信息体的唯一的logid **/ unsigned sl_get_logid(void) { struct slinfo* pl = pthread_getspecific(__lkey); if (NULL == pl) //返回0表示没有找见 return 0u; return pl->logid; } /** * 获取日志信息体的请求ip串,返回NULL表示没有初始化 **/ const char* sl_get_reqip(void) { struct slinfo* pl = pthread_getspecific(__lkey); if (NULL == pl) //返回NULL表示没有找见 return NULL; return pl->reqip; } /** * 获取日志信息体的时间串,返回NULL表示没有初始化 **/ const char* sl_get_times(void) { struct timeval et; //记录时间 unsigned td; struct slinfo* pl = pthread_getspecific(__lkey); if (NULL == pl) //返回NULL表示没有找见 return NULL; gettimeofday(&et, NULL); //同一用微秒记 td = 1000000 * (et.tv_sec - pl->timev.tv_sec) + et.tv_usec - pl->timev.tv_usec; snprintf(pl->times, LEN(pl->times), "%u", td); return pl->times; } /** * 获取日志信息体的名称,返回NULL表示没有初始化 **/ const char* sl_get_mod(void) { struct slinfo* pl = pthread_getspecific(__lkey); if (NULL == pl) //返回NULL表示没有找见 return NULL; return pl->mod; } //-------------------------------------------------------------------------------------------| // 第三部分 对日志系统具体的输出输入接口部分 //-------------------------------------------------------------------------------------------| //错误重定向宏 具体应用 于 "mkdir -p \"" _STR_SCLOG_PATH "\" >" _STR_TOOUT " 2>" _STR_TOERR #define _STR_TOOUT "__out__" #define _STR_TOERR "__err__" #define _STR_LOGID "__lid__" //保存logid,持久化 static struct { //内部用的私有变量 FILE* log; FILE* wf; bool isdir; //标志是否创建了目录 } __slmain; /** * 日志关闭时候执行,这个接口,关闭打开的文件句柄 **/ static void __sl_end(void) { FILE* lid; void* pl; // 在简单地方多做安全操作值得,在核心地方用算法优化的才能稳固 if (!__slmain.isdir) return; //重置当前系统打开文件结构体 fclose(__slmain.log); fclose(__slmain.wf); BZERO(__slmain); //写入文件 lid = fopen(_STR_LOGID, "w"); if (NULL != lid) { fprintf(lid, "%u", __logid); fclose(lid); } //主动释放私有变量,其实主进程 相当于一个线程是不合理的!还是不同的生存周期的 pl = pthread_getspecific(__lkey); __slinfo_destroy(pl); pthread_setspecific(__lkey, NULL); } /** * 日志系统首次使用初始化,找对对映日志文件路径,创建指定路径 **/ void sl_start(void) { FILE *lid; //单例只执行一次 if (!__slmain.isdir) { __slmain.isdir = true; //先多级创建目录,简易不借助宏实现跨平台,system返回值是很复杂,默认成功! system("mkdir -p \"" _STR_SCLOG_PATH "\" >" _STR_TOOUT " 2>" _STR_TOERR); rmdir("-p"); remove(_STR_TOOUT); remove(_STR_TOERR); } if (NULL == __slmain.log) { __slmain.log = fopen(_STR_SCLOG_PATH "/" _STR_SCLOG_LOG, "a+"); if (NULL == __slmain.log) CERR_EXIT("__slmain.log fopen %s error!", _STR_SCLOG_LOG); } //继续打开 wf 文件 if (NULL == __slmain.wf) { __slmain.wf = fopen(_STR_SCLOG_PATH "/" _STR_SCLOG_WFLOG, "a+"); if (NULL == __slmain.wf) { fclose(__slmain.log); //其实这都没有必要,图个心安 CERR_EXIT("__slmain.log fopen %s error!", _STR_SCLOG_WFLOG); } } //读取文件内容 if ((lid = fopen(_STR_LOGID, "r")) != NULL) { //读取文件内容,持久化 fscanf(lid, "%u", &__logid); } //这里可以单独开启一个线程或进程,处理日志整理但是 这个模块可以让运维做,按照规则搞 sl_pecific_init("main thread","0.0.0.0"); //注册退出操作 atexit(__sl_end); } int sl_printf(const char* format, ...) { char tstr[_INT_LITTLE];// [%s] => [2016-01-08 23:59:59] int len; va_list ap; char logs[_INT_LOG]; //这个不是一个好的设计,最新c 中支持 int a[n]; if (!__slmain.isdir) { CERR("%s fopen %s | %s error!",_STR_SCLOG_PATH, _STR_SCLOG_LOG, _STR_SCLOG_WFLOG); return _RT_EF; } //初始化参数 sh_times(tstr, _INT_LITTLE - 1); len = snprintf(logs, LEN(logs), "[%s ", tstr); va_start(ap, format); vsnprintf(logs + len, LEN(logs) - len, format, ap); va_end(ap); // 写普通文件 log fputs(logs, __slmain.log); //把锁机制去掉了,fputs就是线程安全的 // 写警告文件 wf if (format[4] == 'F' || format[4] == 'W') { //当为FATAL或WARNING需要些写入到警告文件中 fputs(logs, __slmain.wf); } return _RT_OK; }
sccsv.h
#ifndef _H_SCCSV #define _H_SCCSV /* * 这里是一个解析 csv 文件的 简单解析器. * 它能够帮助我们切分文件内容,保存在数组中. */ struct sccsv { //内存只能在堆上 int rlen; //数据行数,索引[0, rlen) int clen; //数据列数,索引[0, clen) const char* data[]; //保存数据一维数组,希望他是二维的 rlen*clen }; typedef struct sccsv* sccsv_t; /* * 从文件中构建csv对象, 最后需要调用 sccsv_die 释放 * path : csv文件内容 * : 返回构建好的 sccsv_t 对象 */ extern sccsv_t sccsv_new(const char* path); /* * 释放由sccsv_new构建的对象 * pcsv : 由sccsv_new 返回对象 */ extern void sccsv_die(sccsv_t* pcsv); /* * 获取某个位置的对象内容,这个函数 推荐声明为内联的, window上不支持 * csv : sccsv_t 对象, new返回的 * ri : 查找的行索引 [0, csv->rlen) * ci : 查找的列索引 [0, csv->clen) * : 返回这一项中内容,后面可以用 atoi, atof, str_dup 等处理了... */ extern inline const char* sccsv_get(sccsv_t csv, int ri, int ci); #endif // !_H_SCCSV
sccsv.c
#include <schead.h> #include <sccsv.h> #include <sclog.h> #include <tstring.h> //从文件中读取 csv文件内容 char* __get_csv(FILE* txt, int* prl, int* pcl) { int c, n; int cl = 0, rl = 0; TSTRING_CREATE(ts); while((c=fgetc(txt))!=EOF){ if('"' == c){ //处理这里数据 while((c=fgetc(txt))!=EOF){ if('"' == c) { if((n=fgetc(txt)) == EOF) { //判断下一个字符 SL_WARNING("The CSV file is invalid one!"); free(ts.str); return NULL; } if(n != '"'){ //有效字符再次压入栈 ungetc(n, txt); break; } } //都是合法字符 保存起来 if (_RT_OK != tstring_append(&ts, c)) { free(ts.str); return NULL; } } //继续判断,只有是c == '"' 才会下来,否则都是错的 if('"' != c){ SL_WARNING("The CSV file is invalid two!"); free(ts.str); return NULL; } } else if(',' == c){ if (_RT_OK != tstring_append(&ts, '\0')) { free(ts.str); return NULL; } ++cl; } else if('\r' == c) continue; else if('\n' == c){ if (_RT_OK != tstring_append(&ts, '\0')) { free(ts.str); return NULL; } ++cl; ++rl; } else {//其它所有情况只添加数据就可以了 if (_RT_OK != tstring_append(&ts, c)) { free(ts.str); return NULL; } } } if(cl % rl){ //检测 , 号是个数是否正常 SL_WARNING("now csv file is illegal! need check!"); return NULL; } // 返回最终内容 *prl = rl; *pcl = cl; return ts.str; } // 将 __get_csv 得到的数据重新构建返回, 执行这个函数认为语法检测都正确了 sccsv_t __get_csv_new(const char* cstr, int rl, int cl) { int i = 0; sccsv_t csv = malloc(sizeof(struct sccsv) + sizeof(char*)*cl); if(NULL == csv){ SL_FATAL("malloc is error one !"); return NULL; } // 这里开始构建内容了 csv->rlen = rl; csv->clen = cl / rl; do { csv->data[i] = cstr; while(*cstr++) //找到下一个位置处 ; }while(++i<cl); return csv; } /* * 从文件中构建csv对象, 最后需要调用 sccsv_die 释放 * path : csv文件内容 * : 返回构建好的 sccsv_t 对象 */ sccsv_t sccsv_new(const char* path) { FILE* txt; char* cstr; int rl, cl; DEBUG_CODE({ if(!path || !*path){ SL_WARNING("params is check !path || !*path ."); return NULL; } }); // 打开文件内容 if((txt=fopen(path, "r")) == NULL){ SL_WARNING("fopen %s r is error!", path); return NULL; } // 如果解析 csv 文件内容失败直接返回 cstr = __get_csv(txt, &rl, &cl); fclose(txt); // 返回最终结果 return cstr ? __get_csv_new(cstr, rl, cl) : NULL; } /* * 释放由sccsv_new构建的对象 * pcsv : 由sccsv_new 返回对象 */ void sccsv_die(sccsv_t* pcsv) { if (pcsv && *pcsv) { // 这里 开始释放 free(*pcsv); *pcsv = NULL; } } /* * 获取某个位置的对象内容 * csv : sccsv_t 对象, new返回的 * ri : 查找的行索引 [0, csv->rlen) * ci : 查找的列索引 [0, csv->clen) * : 返回这一项中内容,后面可以用 atoi, atof, str_dup 等处理了... */ inline const char* sccsv_get(sccsv_t csv, int ri, int ci) { DEBUG_CODE({ if(!csv || ri<0 || ri>=csv->rlen || ci<0 || ci >= csv->clen){ SL_WARNING("params is csv:%p, ri:%d, ci:%d.", csv, ri, ci); return NULL; } }); // 返回最终结果 return csv->data[ri*csv->clen + ci]; }
tstring.h
#ifndef _H_TSTRING #define _H_TSTRING #include <schead.h> //------------------------------------------------简单字符串辅助操作---------------------------------- /* * 主要采用jshash 返回计算后的hash值 * 不冲突率在 80% 左右还可以, 不要传入NULL */ extern unsigned str_hash(const char* str); /* * 这是个不区分大小写的比较函数 * ls : 左边比较字符串 * rs : 右边比较字符串 * : 返回 ls>rs => >0 ; ls = rs => 0 ; ls<rs => <0 */ extern int str_icmp(const char* ls, const char* rs); /* * 这个代码是 对 strdup 的再实现, 调用之后需要free * str : 待复制的源码内容 * : 返回 复制后的串内容 */ extern char* str_dup(const char* str); //------------------------------------------------简单文本字符串辅助操作---------------------------------- #ifndef _STRUCT_TSTRING #define _STRUCT_TSTRING //简单字符串结构,并定义文本字符串类型tstring struct tstring { char* str; //字符串实际保存的内容 int len; //当前字符串大小 int size; //字符池大小 }; typedef struct tstring* tstring; #endif // !_STRUCT_TSTRING //文本串栈上创建内容,不想用那些技巧了,就这样吧 #define TSTRING_CREATE(var) \ struct tstring var = { NULL, 0, 0} #define TSTRING_DESTROY(var) \ free(var.str) /* * tstring 的创建函数, 会根据str创建一个 tstring结构的字符串 * * str : 待创建的字符串 * * ret : 返回创建好的字符串,如果创建失败返回NULL */ extern tstring tstring_create(const char* str); /* * tstring 完全销毁函数 * tstr : 指向tsting字符串指针量的指针 */ extern void tstring_destroy(tstring* tstr); /* * 向简单文本字符串tstr中添加 一个字符c * tstr : 简单字符串对象 * c : 待添加的字符 * ret : 返回状态码 见 schead 中 _RT_EB 码等 */ extern int tstring_append(tstring tstr, int c); /* * 向简单文本串中添加只读字符串 * tstr : 文本串 * str : 待添加的素材串 * ret : 返回状态码主要是 _RT_EP _RT_EM */ extern int tstring_appends(tstring tstr, const char* str); /* * 复制tstr中内容,得到char* 返回,需要自己free释放 *假如你要清空tstring 字符串只需要 设置 len = 0.就可以了 * tstr : 待分配的字符串 * : 返回分配好的字符串首地址 */ extern char* tstring_mallocstr(tstring tstr); //------------------------------------------------简单文件辅助操作---------------------------------- /* * 简单的文件帮助类,会读取完毕这个文件内容返回,失败返回NULL. * 需要事后使用 tstring_destroy(&ret); 销毁这个字符串对象 * path : 文件路径 * ret : 返回创建好的字符串内容,返回NULL表示读取失败 */ extern tstring file_malloc_readend(const char* path); /* * 文件写入,没有好说的,会返回 _RT_EP _RT_EM _RT_OK * path : 文件路径 * str : 待写入的字符串 * ret : 返回写入的结果 */ extern int file_writes(const char* path, const char* str); /* * 文件追加内容, 添加str内同 * path : 文件路径 * str : 待追加的文件内同 * : 返回值,主要是 _RT_EP _RT_EM _RT_OK 这些状态 */ extern int file_append(const char* path, const char* str); #endif // !_H_TSTRING
tstring.c
#include <tstring.h> #include <sclog.h> /* * 主要采用jshash 返回计算后的hash值 * 不冲突率在 80% 左右还可以, 不要传入NULL */ unsigned str_hash(const char* str) { unsigned i, h = (unsigned)strlen(str), sp = (h >> 5) + 1; unsigned char* ptr = (unsigned char*)str; for (i = h; i >= sp; i -= sp) h ^= ((h<<5) + (h>>2) + ptr[i-1]); return h ? h : 1; } /* * 这是个不区分大小写的比较函数 * ls : 左边比较字符串 * rs : 右边比较字符串 * : 返回 ls>rs => >0 ; ls = rs => 0 ; ls<rs => <0 */ int str_icmp(const char* ls, const char* rs) { int l, r; if(!ls || !rs) return (int)(ls - rs); do { if((l=*ls++)>='a' && l<='z') l -= 'a' - 'A'; if((r=*rs++)>='a' && r<='z') r -= 'a' - 'A'; } while(l && l==r); return l-r; } /* * 这个代码是 对 strdup 的再实现, 调用之后需要free * str : 待复制的源码内容 * : 返回 复制后的串内容 */ char* str_dup(const char* str) { size_t len; char* nstr; DEBUG_CODE({ if (NULL == str) { SL_WARNING("check is NULL == str!!"); return NULL; } }); len = sizeof(char) * (strlen(str) + 1); if (!(nstr = malloc(len))) { SL_FATAL("malloc is error! len = %d.", len); return NULL; } // 返回最后结果 return memcpy(nstr, str, len); } //------------------------------------------------简单文本字符串辅助操作---------------------------------- /* * tstring 的创建函数, 会根据str创建一个 tstring结构的字符串 * * str : 待创建的字符串 * * ret : 返回创建好的字符串,如果创建失败返回NULL */ tstring tstring_create(const char* str) { tstring tstr = calloc(1, sizeof(struct tstring)); if (NULL == tstr) { SL_NOTICE("calloc is sizeof struct tstring error!"); return NULL; } tstring_appends(tstr, str); return tstr; } /* * tstring 完全销毁函数 * tstr : 指向tsting字符串指针量的指针 */ void tstring_destroy(tstring* tstr) { if (tstr && *tstr) { //展现内容 free((*tstr)->str); free(*tstr); *tstr = NULL; } } //文本字符串创建的度量值 #define _INT_TSTRING (32) //简单分配函数,智力一定会分配内存的, len > size的时候调用这个函数 static int __tstring_realloc(tstring tstr, int len) { int size = tstr->size; for (size = size < _INT_TSTRING ? _INT_TSTRING : size; size < len; size <<= 1) ; //分配内存 char *nstr = realloc(tstr->str, size); if (NULL == nstr) { SL_NOTICE("realloc(tstr->str:0x%p, size:%d) is error!", tstr->str, size); return _RT_EM; } tstr->str = nstr; tstr->size = size; return _RT_OK; } /* * 向简单文本字符串tstr中添加 一个字符c * tstr : 简单字符串对象 * c : 待添加的字符 * ret : 返回状态码 见 schead 中 _RT_EM 码等 */ int tstring_append(tstring tstr, int c) { //不做安全检查 int len = tstr->len + 2; // c + '\0' 而len只指向 字符串strlen长度 //需要进行内存分配,唯一损失 if ((len > tstr->size) && (_RT_EM == __tstring_realloc(tstr, len))) return _RT_EM; tstr->len = --len; tstr->str[len - 1] = c; tstr->str[len] = '\0'; return _RT_OK; } /* * 向简单文本串中添加只读字符串 * tstr : 文本串 * str : 待添加的素材串 * ret : 返回状态码主要是 _RT_EP _RT_EM */ int tstring_appends(tstring tstr, const char* str) { int len; if (!tstr || !str || !*str) { SL_NOTICE("check param '!tstr || !str || !*str'"); return _RT_EP; } len = tstr->len + (int)strlen(str) + 1; if ((len > tstr->size) && (_RT_EM == __tstring_realloc(tstr, len))) return _RT_EM; //这里复制内容 strcpy(tstr->str + tstr->len, str); tstr->len = len - 1; return _RT_OK; } //------------------------------------------------简单文件辅助操作---------------------------------- /* * 简单的文件帮助类,会读取完毕这个文件内容返回,失败返回NULL. * 需要事后使用 tstring_destroy(&ret); 销毁这个字符串对象 * path : 文件路径 * ret : 返回创建好的字符串内容,返回NULL表示读取失败 */ tstring file_malloc_readend(const char* path) { int c; tstring tstr; FILE* txt = fopen(path, "r"); if (NULL == txt) { SL_NOTICE("fopen r path = '%s' error!", path); return NULL; } //这里创建文件对象,创建失败直接返回 if ((tstr = tstring_create(NULL)) == NULL) { fclose(txt); return NULL; } //这里读取文本内容 while ((c = fgetc(txt))!=EOF) if (_RT_OK != tstring_append(tstr, c)){ //出错了就直接销毁已经存在的内容 tstring_destroy(&tstr); break; } fclose(txt);//很重要创建了就要释放,否则会出现隐藏的句柄bug return tstr; } /* * 文件写入,没有好说的,会返回 _RT_EP _RT_EM _RT_OK * path : 文件路径 * str : 待写入的字符串 * ret : 返回写入的结果 */ int file_writes(const char* path, const char* str) { FILE* txt; //检查参数问题 if (!path || !str) { SL_NOTICE("check is '!path || !str'"); return _RT_EP; } if ((txt = fopen(path, "w")) == NULL) { SL_NOTICE("fopen w path = '%s' error!", path); return _RT_EF; } //这里写入信息 fputs(str, txt); fclose(txt); return _RT_OK; } /* * 文件追加内容, 添加str内同 * path : 文件路径 * str : 待追加的文件内同 * : 返回值,主要是 _RT_EP _RT_EM _RT_OK 这些状态 */ int file_append(const char* path, const char* str) { FILE* txt; //检查参数问题 if (!path || !str) { SL_NOTICE("check is '!path || !str'"); return _RT_EP; } if ((txt = fopen(path, "a")) == NULL) { SL_NOTICE("fopen a path = '%s' error!", path); return _RT_EF; } //这里写入信息 fputs(str, txt); fclose(txt); return _RT_OK; } /* * 复制tstr中内容,得到char* 返回,需要自己free释放 * tstr : 待分配的字符串 * : 返回分配好的字符串首地址 */ char* tstring_mallocstr(tstring tstr) { char* str; if (!tstr || tstr->len <= 0) { SL_NOTICE("params is check '!tstr || tstr->len <= 0' error!"); return NULL; } if ((str = malloc(tstr->len + 1)) == NULL){ SL_NOTICE("malloc %d+1 run is error!",tstr->len); return NULL; } //下面就可以复制了,采用最快的一种方式 return memcpy(str, tstr->str, tstr->len + 1); }
正文
那我们开始把将一个xlsm如何转成工作中用的json文件. 再继续重复扯一点, 最优方法是vba, 次优方法利用上层框架例如.net 通过npoi写个批量
处理工具. 最难受的方法就是本文中采用c处理业务代码. 好吧继续. 首先 我们仍然使用 destiny.xlsm文件 . 另存为
destiny.csv
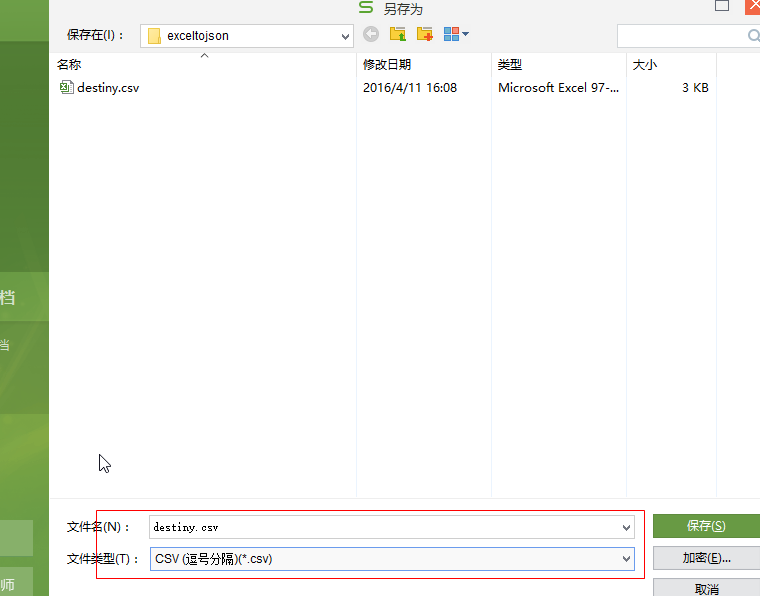
最后的 保存后结果为
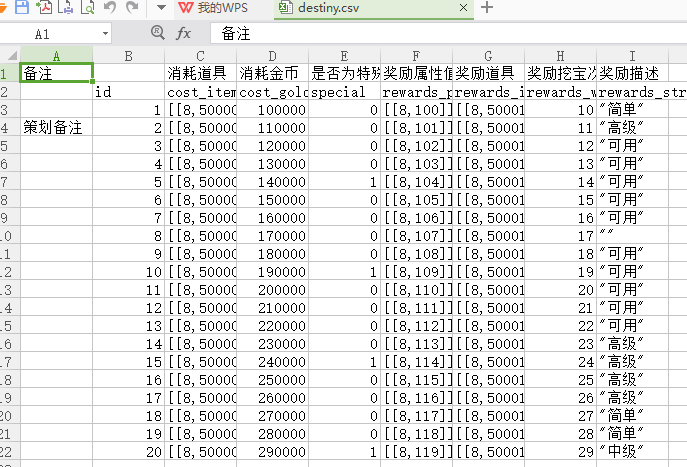
我们查看内部详细文本编码协议
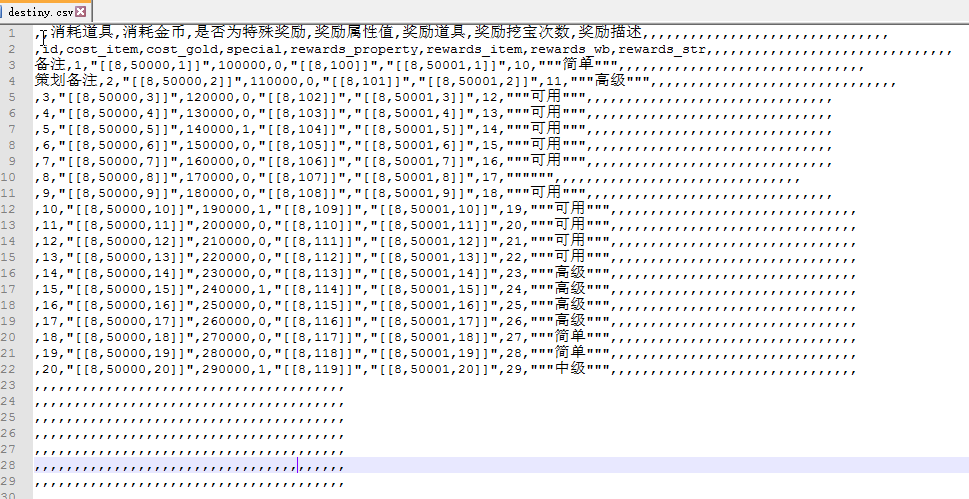
最后得到这个文件. 我们处理方式是.
先读取 这个csv 文件 通过sccsv.h 提供的接口. 拼接一个生成的json内容. 处理代码
test_xlsmtojson.c
#include <schead.h> #include <sclog.h> #include <sccsv.h> #include <tstring.h> // 将csv转换成json文件输出, 成功返回0, 错误见状态码<0 int csvtojson(const char* path); int main(int argc, char* argv[]) { int i = 0, rt; // 简单参数检查 if(argc < 2) { CERR("uage: %s [*.csv]", argv[0]); return 0; } // sccsv 使用了 sclog 需要启动 sclog sl_start(); // 开始解析处理 while(++i<argc){ rt = csvtojson(argv[i]); if(0 == rt) printf("%s 转换成功\n", argv[i]); else printf("%s 转换失败, rt = %d\n", argv[i], rt); } return 0; } // 得到生成json文件的名称, 需要自己free static char* _csvtojsonpath(const char* path) { char *tarp; int len = strlen(path); // 判断后缀名 if(str_icmp(path+len-4, ".csv")){ CERR("path is %s need *.csv", path); return NULL; } // 这里申请内存进行处理 if((tarp = malloc(len+2))==NULL) { CERR("malloc is error!"); return NULL; } // 返回最终结果 memcpy(tarp, path, len - 3); // 添加json后缀名 tarp[len-3] = 'j'; tarp[len-2] = 's'; tarp[len-1] = 'o'; tarp[len] = 'n'; tarp[len + 1] = '\0'; return tarp; } // csv read -> json write static void _csvtojson(sccsv_t csv, FILE* json) { // 第一行, 第一列都是不处理的 int c, r; // 第二行 内容是对象中主键内容 int clen = csv->clen - 1, rlen = csv->rlen - 1; // 先确定最优行和列 while (rlen > 2) { if (*sccsv_get(csv, rlen, 1)) break; --rlen; } while (clen > 1) { if (*sccsv_get(csv, 0, clen)) break; --clen; } // 最外层是个数组 fputs("[\n", json); for (r = 2; r <= rlen; ++r) { // 当对象处理 fputs("\t{\n", json); // 输出当前对象中内容 for (c = 1; c <= clen; ++c) { fprintf(json, "\t\t\"%s\":%s", sccsv_get(csv, 1, c),sccsv_get(csv, r, c)); fputs(c == clen ? "\n" : ",\n", json); } // 最新的json语法支持多个 ',' fputs(r == rlen ? "\t}\n" : "\t},\n", json); } fputs("]", json); } // 将csv转换成json文件输出, 成功返回0, 错误见状态码<0 int csvtojson(const char* path) { char* tarp; FILE* json; sccsv_t csv; if(!path || !*path) { CERR("path is null!"); return _RT_EP; } // 继续判断后缀名 if((tarp = _csvtojsonpath(path)) == NULL ) { CERR("path = %s is error!", path); return _RT_EP; } // 这里开始打开文件, 并判断 if((csv = sccsv_new(path)) == NULL) { free(tarp); CERR("sccsv_new %s is error!", path); return _RT_EF; } if((json = fopen(tarp, "wb")) == NULL ) { sccsv_die(&csv); free(tarp); CERR("fopen %s wb is error!", tarp); return _RT_EF; } // 到这里一切前戏都好了开始转换了 _csvtojson(csv, json); fclose(json); sccsv_die(&csv); free(tarp); return _RT_OK; }
其实还是比较短的. 分析如下
static char* _csvtojsonpath(const char* path)
功能是将 *csv 路径字符串 编程 *.json路径字符串,保存在堆上,需要后续 free.
static void _csvtojson(sccsv_t csv, FILE* json)
上面函数将解析好的 csv结构保存输出到json中.
对于 sccsv.h 的具体使用可以参见
C 封装一个csv 解析库 http://www.cnblogs.com/life2refuel/p/5265167.html
对于开头的两个 while是为了确定最终范围的. 拼接最终结果. 是不是很简单. 从上面看出, 实际处理代码其实很少,主要是
对参数检测健壮性代码占了很多. 其它都是业务转换代码. 核心还是解析csv文件结构和json个数的拼接.
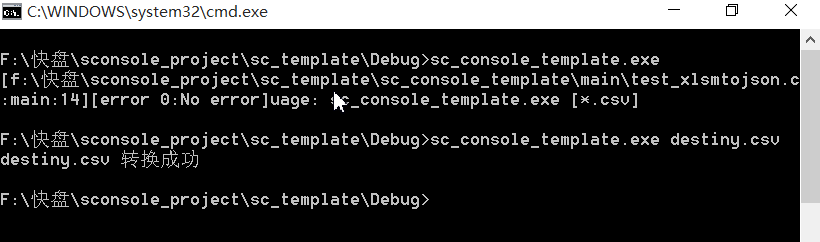
运行结果如下
最终生成的 destiny.json文件结构图

到这里话. 基本的处理方式方法都已经介绍完毕了. 总结C处理业务功能事有点不合时宜了. 上层语言还是值得我们深究的.
有兴趣的可以用上层语言写一个工具来帮我们批量处理excel文件生成json.
再扯一点. json 文件相比xml 文件, 首先内存上小了很多. 处理速度快了. 但是json文件的性能浪费在
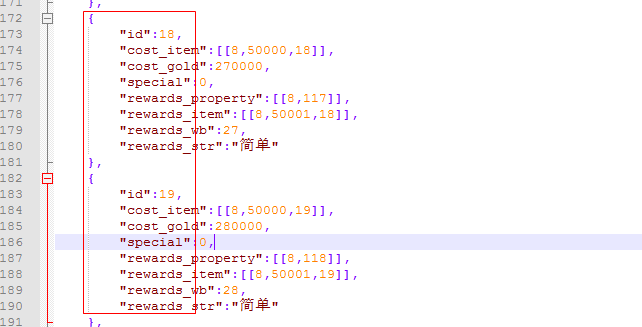
重复的键值. 浪费空间.
再再扩展一下下. 怎么处理优化呢. 一种空间换时间, 转成内存文件避免动态解析生成. 就是承认浪费. 但是一次加载解析到内存中.
还有一种 将 对象编程数组去掉键值但是这样可读性很不好.
其它,希望有更好的协议出现. 或者诞生在博客园...
后记
错误是难免的, 希望这些对问题的分析和深究对你有帮助. 激发大家的思考. 有兴趣的可以写写更好的工具. 交流分享.
拜~~.

