
ng-深度学习-课程笔记-14: 人脸识别和风格迁移(Week4)
1 什么是人脸识别( what is face recognition )
在相关文献中经常会提到人脸验证(verification)和人脸识别(recognition)。
verification就是输入图像,名字或id,判断是不是。而人脸识别是输入图像,输出这个人的名字或id。
我们先构造一个准确率高的verification,然后再把它应用到人脸识别中。
2 一次学习( One-shot learning )
假设现在要做一个人脸识别,但是你的数据库对于每个人只有一张照片,要怎么做?
这个时候可能会觉得怎么可能只有一张照片,你要做人脸识别肯定要有足够的数据啊,没数据就去收集啊。
那现在数据库中对于每个人都有充足的样本数据,你构建了一个卷积神经网络,最后用softmax输出来判断这个人是数据库的哪个人,或者都不是。
那么,如果你的数据库加入了新的人呢,比如说公司入职一批新员工,这要怎么做呢?再收集一波,然后加一批输出单元然后重新训练网络吗?这似乎不是个好办法。
在人脸识别中,有一个挑战就是,你有时只能通过一个样本学习到是不是这个人,这就是一次学习。
所以我们要学习的是相似度的计算,你的神经网络要学习的是,输入两张图片,然后输出这两张图片的差异,你希望输入同一个人的两张照片后输出很小的值,而输入两个人的照片后输出很大的值,我们就可以说当两张图片的差异小于某个阈值的时候,就预测是同一个人。这就是解决verification的一个可行办法。
识别任务就是拿输入的照片和数据库中的照片做比较,可以产生很多差异值,取最小的差异值,就能从数据库找到这个人的身份。如果某个人不在数据库中,那么它跟数据库中的照片的差异值都会很大。

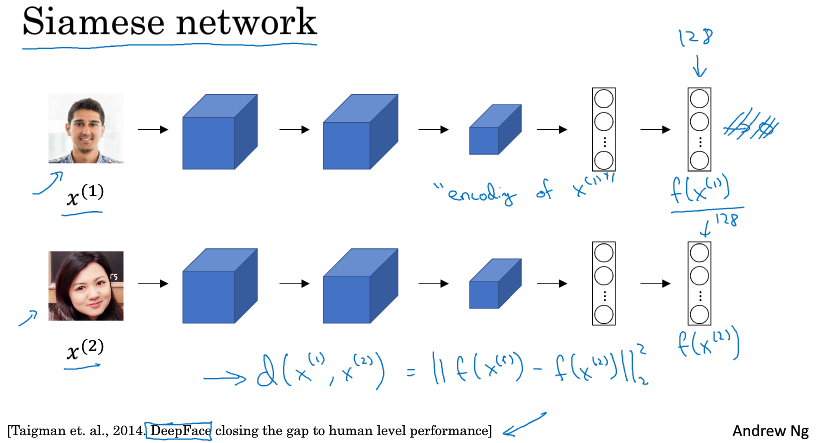
3 Siamese网络( Siamese Network )
输入图片x1,经过卷积网络后,在最后一层输出的128维向量,称为f(x1)
输入图片x2,喂给同样结构同样参数的网络,得到另一个128维向量,称为f(x2)
最后,如果你相信f(x)能很好地代表输入的图片,那么定义差异d 为 f(x1) 和 f(x2)的距离范数,用d作为损失,来训练这个网络。
4 三元组损失( triplet loss)
具体如何定义这个表示距离的损失函数呢?
三元指的是我们的网络要看三种性质人脸,anchor,positive,negative。anchor作为对比的目标,positive表示是和anchor是同一个人,negative表示和anchor不是同一个人。
我们把这三种人简写成A, P, N。
我们要做的是 $d(f(A),f(P)) \leqslant d(f(A),f(N))$ 即 $\left \| f(A) - f(P)) \right \|_2^2 \;-\; \left \| f(A) - f(N)) \right \|_2^2 \;\leqslant\; 0$。
这个公式需要改写一下,有种情况虽然满足但是不是我们想要的,0-0=0的情况。
为了防止这种情况,我们把公式右边的0改成一个间隔参数α,这里α是负的。间隔参数拉大了它们之间的差异。
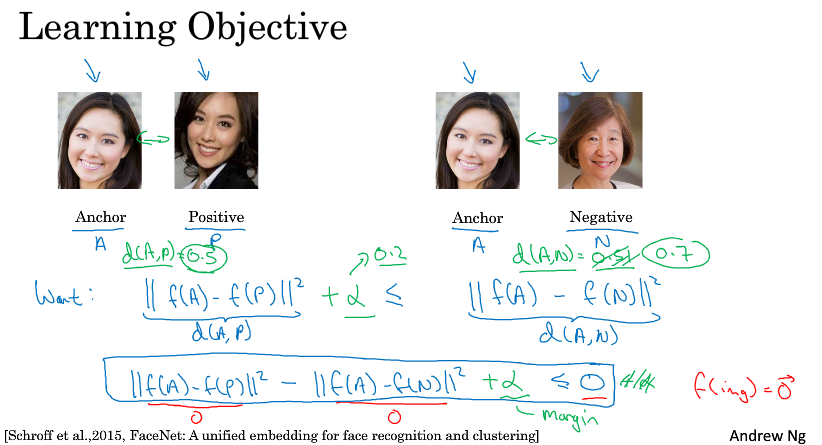
那么可以定义如下的损失函数,为了使损失非负,用了一个max(0, ),这样优化的目标就是使得图中绿色框中的差异项为<=0的值,这里的α是正的。
假如你现在有1w张图片,你现在要做的就是构造出三元组,然后训练你的算法。
构建训练集的时候需要注意,A和N如果差异太大的话,这个网络的分辨能力就会比较弱,所以要选A和N比较像的数据,或者说d(A,P)和d(A,N)要尽量接近,选择“难训练”的样本作为训练集,这样网络才会尽力地去区分N和P,才能训练出分辨能力强的网络。
做人脸识别的商业公司,它们一般都用百万,千万,亿级别的数据来训练,这么大的数据集并不容易获得,幸运的是一些公司已经训练了这些大型的网络并上传了网络模型参数,所以,可以下载别人的预训练模型来使用。

5 脸部验证和二分类( Face verification and binary classification )
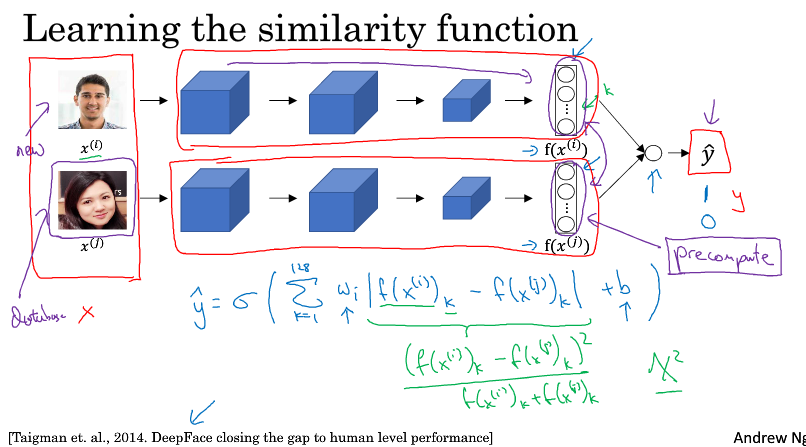
除了triplet loss还有其它学习参数的方法,让我们来看看怎么把人脸验证当作一个二分类问题。
另一个方法是选一对神经网络,这两个神经网络的参数是相同的,输入两行图片,同时计算两个128维的向量,计算差异作为特征,最后接一层逻辑回归,做二分类。
有个计算上的技巧,就是对于数据库已有的人脸,可以先计算出最后一层前的向量,存起来要用的时候直接拿出来用,这样就不用每次识别的时候又计算一次。
6 深度卷积网络在学什么( what are deep convNets learning )
假如我们训练好一个深度卷积网络,我们在每一层的某个通道(channel)中找到最大激活的9个feature map(不同样本中找)。然后换一个通道,循环这个过程,找出一堆这样的图像。
发现,第一层似乎在寻找一些边缘,阴影的东西;第二层似乎学习到了更复杂的一些纹理和图案;
第三层则学到了一些轮胎,形状,人,还有一些比较难看出来;第四层开始学到了狗,动物的脚,钟,螺旋状的图案;
第五层检测出了键盘,人,眼睛,文本,狗,花;
可以感受到卷积的过程中,提取的特征从简单到复杂。

7 风格迁移( style transfer )
风格迁移就是把一张图片的风格和另一张图片的内容结合,形成新图片。
风格迁移有三张图片。一张原始内容图,content图,简称C。一张原始风格图,style图,简称S。一张生成的图片,generated图,简称G。

损失函数分为两部分,一部分计算C和G的差异,一部分计算S和G的差异,然后用α和β两个超参来调节两部分的权重。
实际要做的就是,先随机生成一张图片G,然后计算损失,做梯度下降,G就会在内容上越来越接近C,在风格上越来越接近S。
我们用预训练卷积网络,比如VGG,将C, S, G分别输入到3个单独的VGG网络中卷积,称C所在的网络为C-VGG, S所在的网络为S-VGG,G所在的网络为G-VGG。
对于内容损失,取某一层l层,l不会太浅也不会太深,计算C-VGG和G-VGG在这一层的激活值的差异,可以用平方损失。
那么怎么表示风格损失呢?需要稍微解释一下,风格就是不同通道的相关性。
我们之前将深度卷积到底在做什么的时候,在某层的某个单元取出了9个图像块,这9个图像块对应一个通道。
如下图所示,第一个通道,红色通道对应第2个九宫格,表示纹理;第二个通道,黄色通道对应第二行第一个九宫格,表示橙色的区域。
那么如果说一个图片中的纹理部分,出现橙色的概率很高,我们就说这两个通道相关度很高。相关度描述的就是两个通道同时出现的概率。

定义下风格矩阵,把第1个通道的图像对应位置的像素乘以自身再相加,得到矩阵的第一行第一列。把第1个通道的图像和第2个通道的图像对应位置的像素相乘再相加,得到矩阵的第一行第二列...把第k个通道的图像和第k'个通道的图像对应位置的像素相乘再相加,得到矩阵的第k行第k'列...
最后得到nc*nc的矩阵,nc表示通道数。这个矩阵也叫Gram矩阵。下面的F范数,其实就是向量2范数推广到矩阵的概念。
我们同时对S和G的每一层进行这个运算,然后把结果进行差异计算,算出每一层的差异,然后用w对每层的差异做一个加权和,得到风格损失。
最后把内容损失和风格损失加权和,就得到最终的损失。


8 延伸到一维和三维( 1D and 3D generalizations of models )
之前学的是二维上的卷积,那么在一维和三维上的卷积是怎样的呢,它们和二维卷积是类似的,可以类推到相似的结果。
对于1维卷积,假设有n个卷积序列,通道数为nc,那么长度为14*nc的原序列,通过n个长度为5*nc的卷积序列的卷积后,得到长度为10*n的序列。
对于3维卷积,假设有n个卷积核,通道数为nc,那么shape为14*14*14*nc的原张量,通过n个shape为5*5*5*nc的卷积张量的卷积后,得到shape为10*10*10*n的张量。
1维卷积一般用于处理序列数据,2维卷积一般用于处理图像数据,而3维卷积可以用在处理电影视频的数据,对不同时间点的3d图像进行处理。

