
ng-深度学习-课程笔记-12: 深度卷积网络的实例探究(Week2)
1 实例探究( Cast Study )
这一周,ng对几个关于计算机视觉的经典网络进行实例分析,LeNet-5,AlexNet,VGG,ResNet,Inception。
2 经典网络( Classic networks )
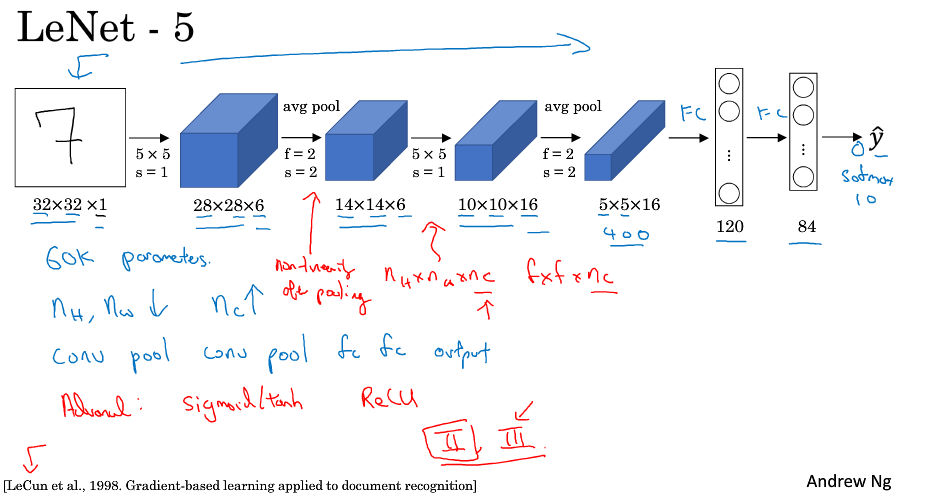
LeNet-5是1998年写的,大约有6万个参数,基本的网络结构跟今天差不多,只是有几点不同:
激活函数用sigmoid或tanh,没有用relu;当时比较流行使用平均池化;池化后使用了sigmoid激活函数;没有使用pdding;
当时的每个卷积核是跟原图像的通道数是一样的,是因为当时计算能力弱,为了减少计算量用了很复杂的运算进行,现在一般都不这么用了;
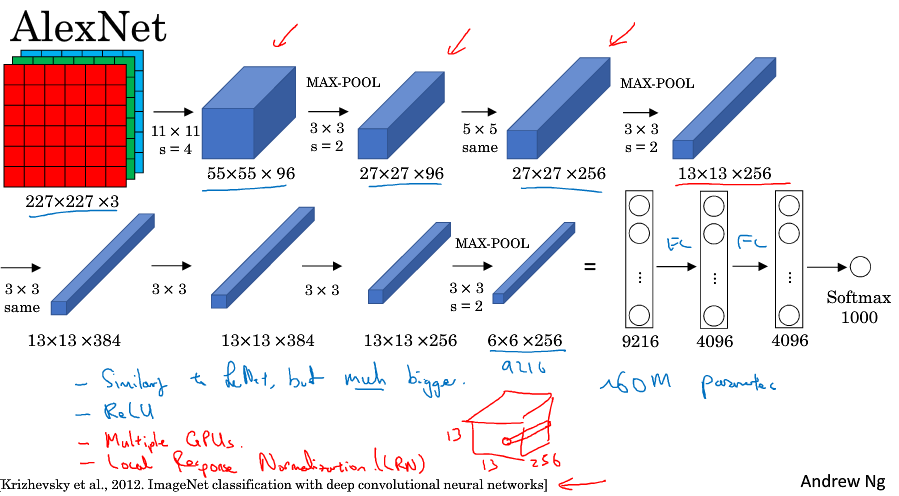
AlexNet的命名来源于论文的第一作者,AlexNet使用的图像是227*227*3,paper的原文中说是224,但是实际上根据后面的网络参数推导一下发现是227才对。
AlextNet和LeNet类似,但是网络大了很多,参数大约有6000万个;相比于LeNet-5它使用了relu激活函数;当时的GPU运行还比较慢,用了多GPU的方式训练。
从这篇论文开始,计算机视觉研究者开始关注深度学习,并相信深度学习可以应用于计算机视觉领域,此后,深度学习在计算机视觉及其它领域的影响力与日俱增。
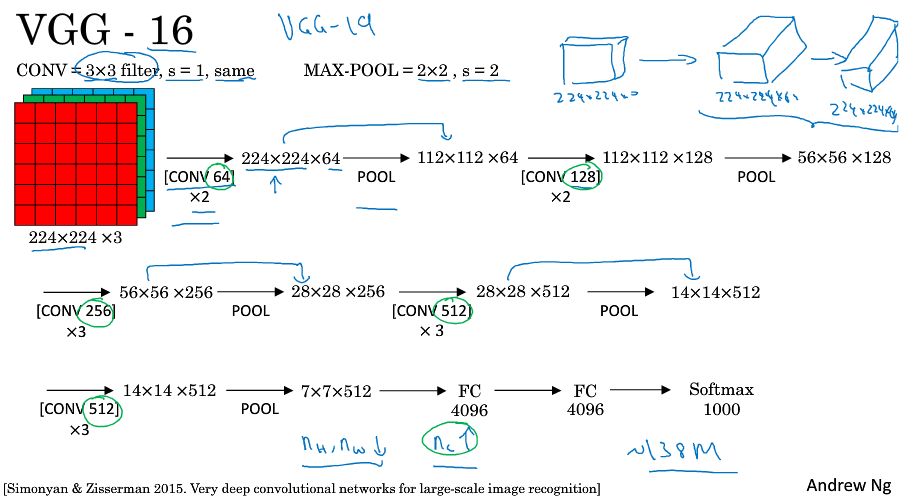
VGG-16总共包含约1.38亿个参数,但是它的结构并不复杂,很整齐,卷积核大小和池化参数固定,几个卷积后面跟着一个池化,卷积核的数量以加倍的方式变化,每次池化后图片高度宽度减半,这种相对一致的网络结构对研究者很有吸引力。而主要缺点在于需要训练的参数特点多。VGG-19比VGG-16更大,只是它们的效果差不多,所以很多人还是用VGG-16。
如果想研读论文的话,ng的建议顺序是AlexNet(比较好懂),VGG,LeNet-5(比较晦涩)。
3 残差网络( Residual Networks, ResNets )
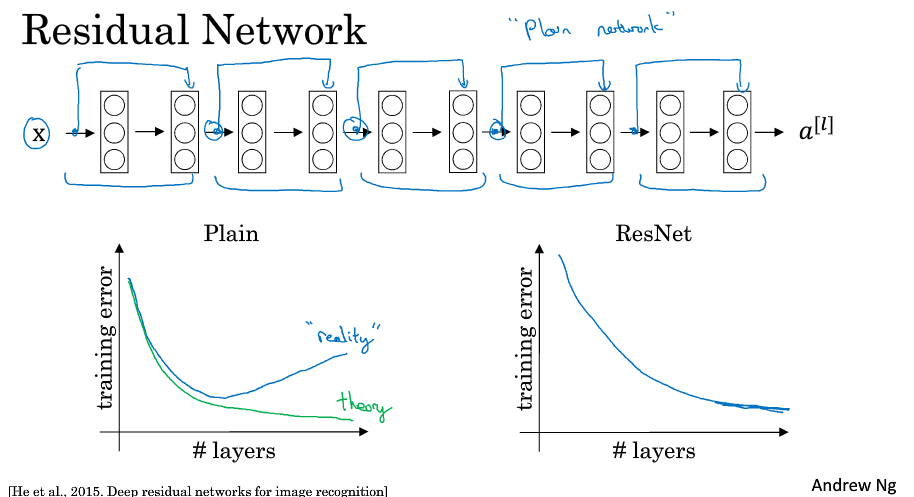
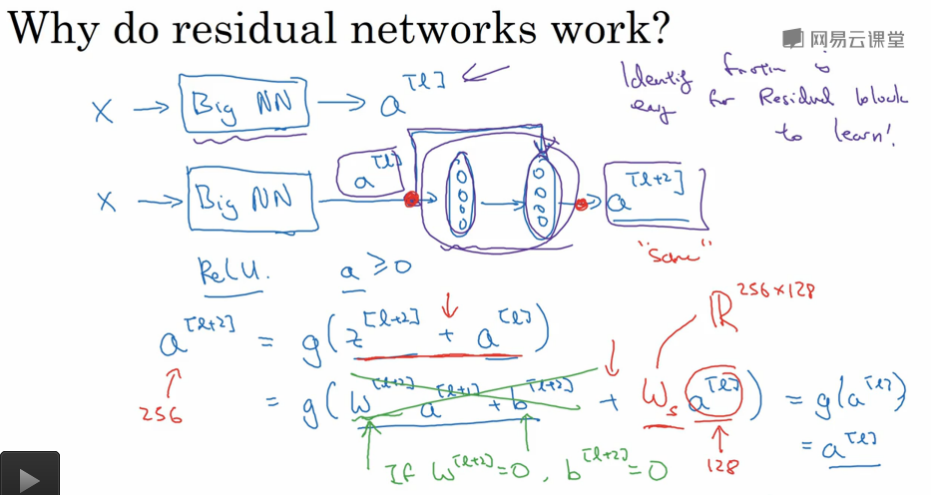
因为存在梯度消失和梯度爆炸的问题,深度很深的网络是很难训练的。我们可以通过跳过连接( skip connections ) ,来构建能训练深度网络的ResNets。
残差网络是由残差块构成的。正常的网络按照一个主路径传递,如果我们在某层的输出后跳过了一层(或者好几层),直接达到后层的激活函数之前,这条路就是捷径,含有捷径的这一块(包含主路径)就叫残差块。
所谓构建残差网络就是通过很多这样的残差块堆积在一起,形成一个深度神经网络。
在普通网络中,论文的术语称为plain network,理论上随着深度的加深,错误率不断下降,但是实际上因为太深的原因难以训练,到了后面训练错误率会上升。
在残差网络中,随着深度的不断增加,错误率不断下降。
为什么残差会有用呢?看个例子,假定使用relu激活函数,现在a[l]跳过了l+1层,那么有a[l+2] = g ( z[i+2] + a[l] ),如果我们做了权重衰减,那么假设w[l+2]和b[l+2]等于0,这个时候a[l+2] = g (a[l]) = a[l],因为使用的是relu,而且a[l]是已经被激活过的,结果表明残差块学习这个恒等式函数并不难,即使中间隔着两层我们还是能得到a[l+2] = a[l]。
值得注意的是这里z[i+2] 和 a[l]要能相加需要保持维度一致,所以残差网络中使用了很多相同的卷积来保留维度。如果维度不一致的话,z[i+2] + a[l]的时候,在a[l]前面乘上一个权重,来保持维度一致,这个维度是网络自己学习得到的参数,它用0填充a[l]或者其它手段使得维度一致。
4 网络中的网络以及1*1卷积( Network in Nework and 1*1 convolutions )
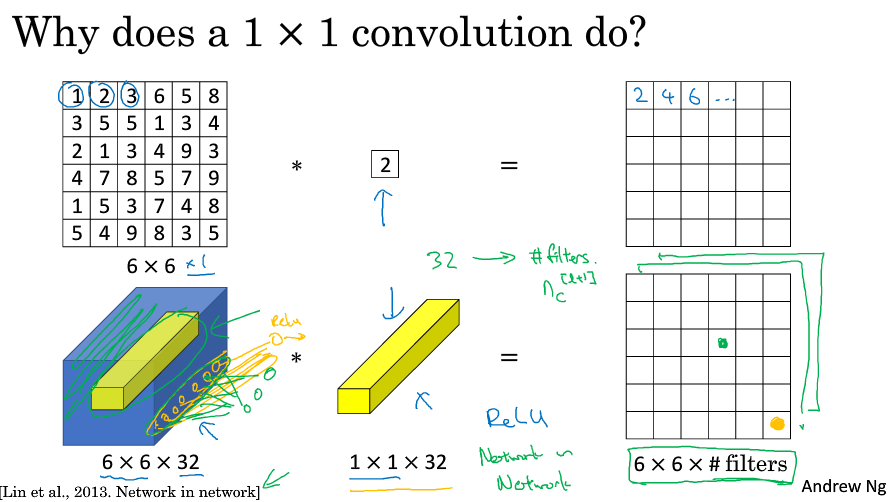
1*1卷积似乎作用不大,就是乘以一个数字而已。但是考虑多通道的图片,它进行了多通道的乘积和。
1*1卷积可以根据自己意愿,或压缩,或保持,或增加输入层中的通道数量。
1*1卷积有时也被称为network in network,在相关论文中有详述,虽然没有得到广泛应用,但是它的理念却很有影响力,Inception网络也受到它的影响。
5 Inception网络( Inception network )
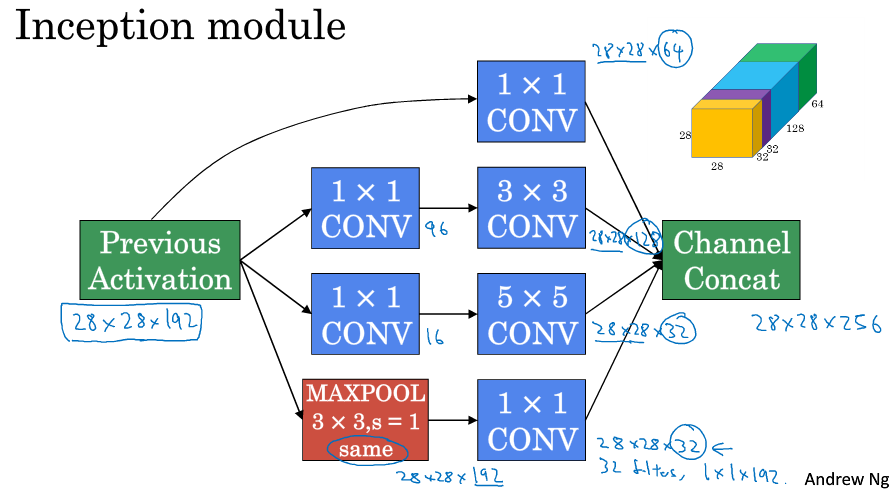
Inception的作用就是代替人工来确定卷积层中的卷积核类型,或者确定是否需要创建卷积层或池化层。
对于一个输入的图像,是用1*1,还是3*3,还是5*5的卷积,还是做一种特殊的池化,Inception会把他们都计算出来叠在一起,由网络自己学习应该采用什么运算。
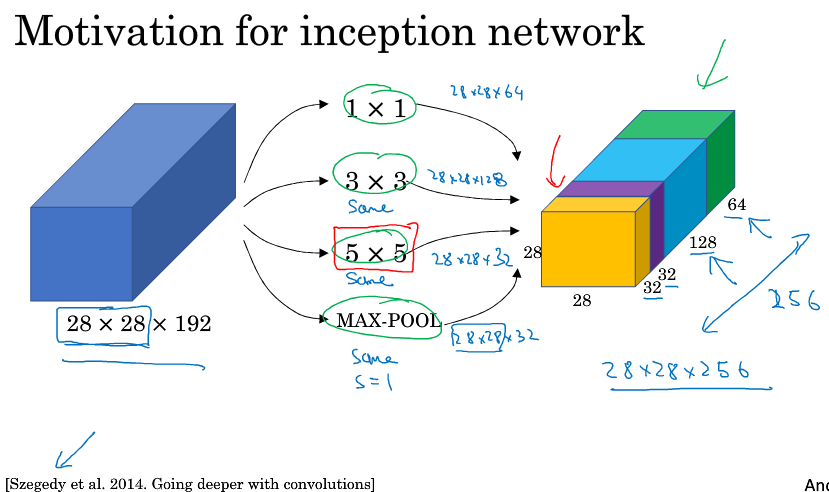
考虑5*5的卷积,从28*28*192卷积到28*28*32,计算一下我们需要计算的乘法次数,对于一小块卷积我们需要做5*5*192次乘法,最后生成的是28*28*32块的输出,所以总共需要5*5*192*28*28*32 约等于1.2亿次的乘法运算。
现在考虑先用1*1的卷积,构造一个瓶颈层,再通过5*5的卷积来得到28*28*32的图像,这样得到最后的28*28*32,这样需要计算的乘法运算次数约等于1200千万次,比之前缩小了10倍,如下图所示。
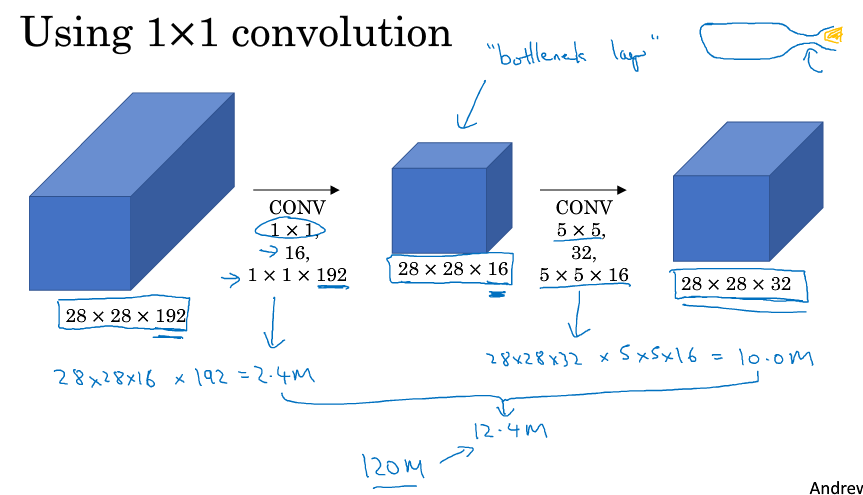
利用1*1卷积可以减小计算量,把这个和上面说的Inception结合起来,可以得到下图所示模块。
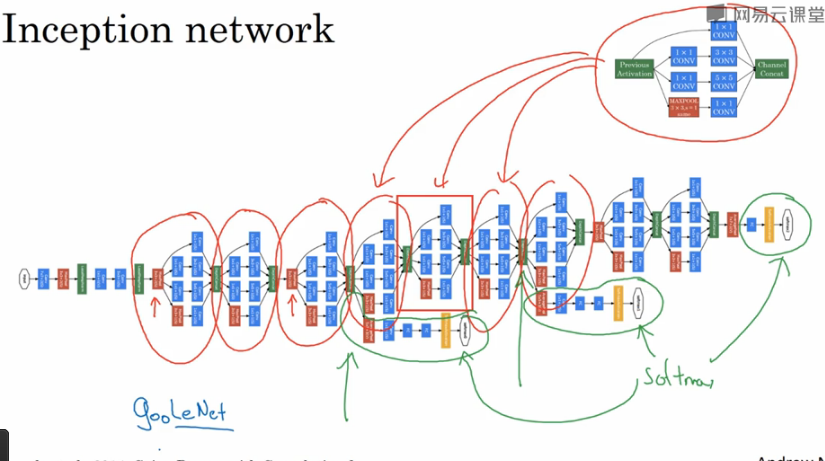
这些一个个Inception模块堆叠起来,就是一个大的Inception网络,如下图所示。可以注意到除了最后的输出外,还有几个分支输出,这些分支输出是根据中间隐藏层进行预测的输出,它确保了中间隐藏层也参与了特征计算,它们也能预测图片的分类,它起到一种调整的作用,并且能防止网络过拟合。
6 迁移学习( transer learning )
很多人已经用ImageNet, MS COCO, PACAL AOC的数据集训练过它们的算法,可能这些训练花费了好几周并且需要很多GPU,经历了艰难的优化过程,你可以下载这些别人花了几周甚至几个月而做出来的开源的权重参数,把它当作一个很好的初始化,用在你的神经网络上,用迁移学习把公共数据集的知识迁移到你自己的问题上。
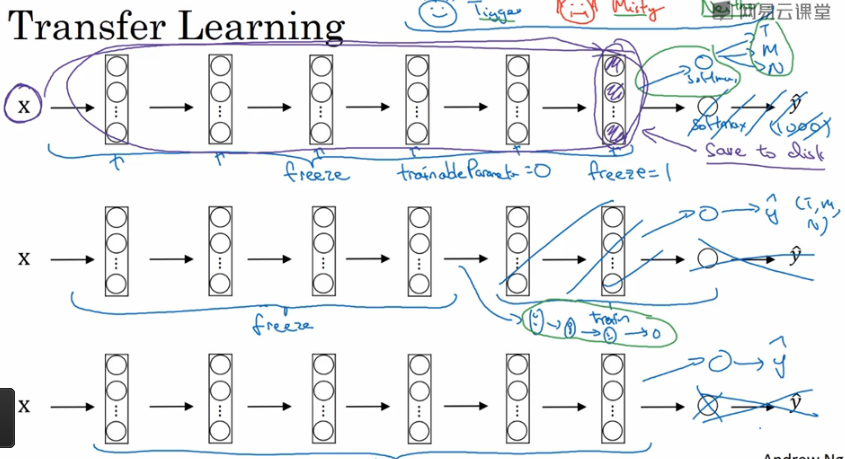
下载好别人的网络,有如下几种选择可以考虑。
如果你数据量比较小的话,除了输出层,前面的全部冻结,计算倒数第二层的输出作为特征存起来,直接用这个特征接上你的输出层比如softmax做训练。
如果数据量比较大的话,冻结少一些前层,然后训练后面的层(或者把后面的层去掉接上你自己设计的层),输出层换成你自己的输出层。
你有越多的数据,那么冻结的层就应该越少。
如果你有很多很多的数据,就不要冻结,直接用它的网络和权重作为初始化进行训练,输出层换成你自己的输出层。
7 数据增强( data augment )
计算机视觉上常常遇到的问题就是数据不够用,可以用数据增强来扩充你的数据集。比如,水平翻转,随机裁剪一部分,旋转,扭曲,色彩转换等等。
8 计算机视觉现状( the state of computer vision )
当一个问题有很多数据的时候,我们往往可以用更简单的算法,更少的手工工程去解决。
但是对于一个问题如果你的数据比较少的话,就需要比较多精心的人工设计,人工设计组件是非常有技巧性的任务,需要很多方面的洞察力。
所以说知识的来源主要有两方面,一个是labeled data, 一个是手工工程。
正是因为在计算机视觉方面,我们的数据不够(现实世界是有很多这样的数据,但是相对于我们的需要来说,还是不够),所以我们才会人工地设计出那么多复杂的网络。
当你只有少量数据的时候,可以考虑使用迁移学习。
有几个tips适用于基准测试和竞赛,不过不适合用在生产中。一是集成,训练几个网络然后取平均;二是multi-crop,在测试阶段把你的图片变多几次,分别运算出结果取平均。
在设计网络结构和实现的时候多多参考开源代码和论文。
考虑使用迁移学习进行预训练和微调。

