ng-深度学习-课程笔记-10: 机器学习策略2(Week2)
1 误差分析( Carrying out error analysis )
假设你训练了一个猫的二分类模型,在开发集上的错误率是10%,你想分析这10%的错误率来自哪里,怎么做呢?
先把这些错分的图片找出来,你注意到算法把一些狗错分成了猫,那么你可以收集更多的狗图,或者针对狗的数据来调整你的模型。
在这之前,应该先分析一下,这些错误的图片有多少是把狗错分成猫,如果说100张图片里只有5张是把狗错分成了猫,这个时候需要考虑一下值不值得花这个精力去针对狗做调整工作,它给你带来的性能提升空间太小了,最多只能把你的错误率减少到9.5%;但是如果100张图片有50张是把狗错分成了猫,那就很值得你去做这个处理了。
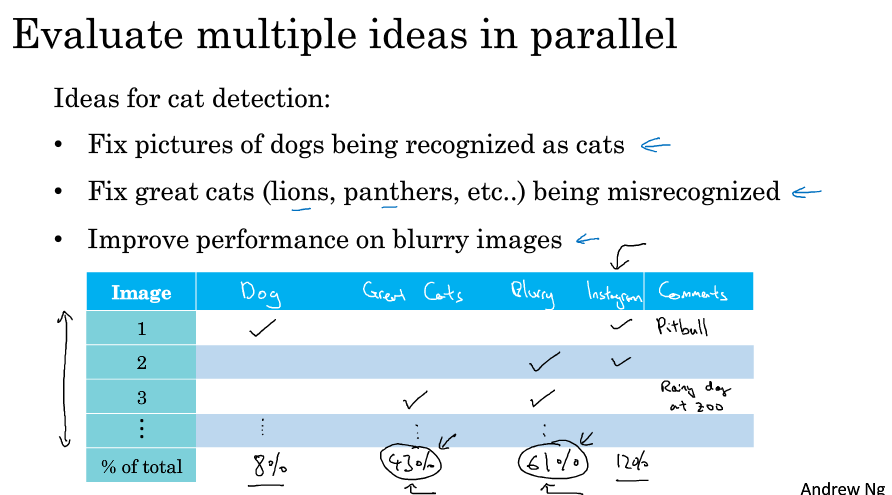
如果我们有改善模型的多个想法,可以并行地分析这些想法是否值得尝试,如下图所示,可能狗,猫科动物,或者图像模糊,这三种情况我们把它错分成猫了,就列个表,过一遍错分的数据,看看它们属于哪个问题,然后统计它们的比例,就知道哪个问题对性能的提升空间最大,同时可以打上备注描述具体的出错信息便于之后的分析。在这个过程中我们可能发现更多的影响因素,就可以加多一列的属性进行分析。
这个分析结果也不是说你一定要处理问题出现最多的因素,但它能给你一个概念,让你明白最应该选择哪些问题着手,也让你知道某个问题的解决对性能的提升空间有多大。另外,如果你发现了多个影响表现的因素,就可以分几个团队,每个团队去解决一个因素,并行处理,提高效率。
2 处理标注错误的数据( Cleaning up Incorrectly labeled data )
假设你看了一些数据样本,发现有些样本的标注是错误的,应该如何做呢?
对于训练集的数据,因为深度学习算法对于训练集的随机错误具有很好的鲁棒性,所以有时候放着不管也可以,只要你的样本数量足够大,实际误差不会太高。注意的是如果你的错误是系统性的话,影响就很大,比如你总是把白色的狗识别成猫。
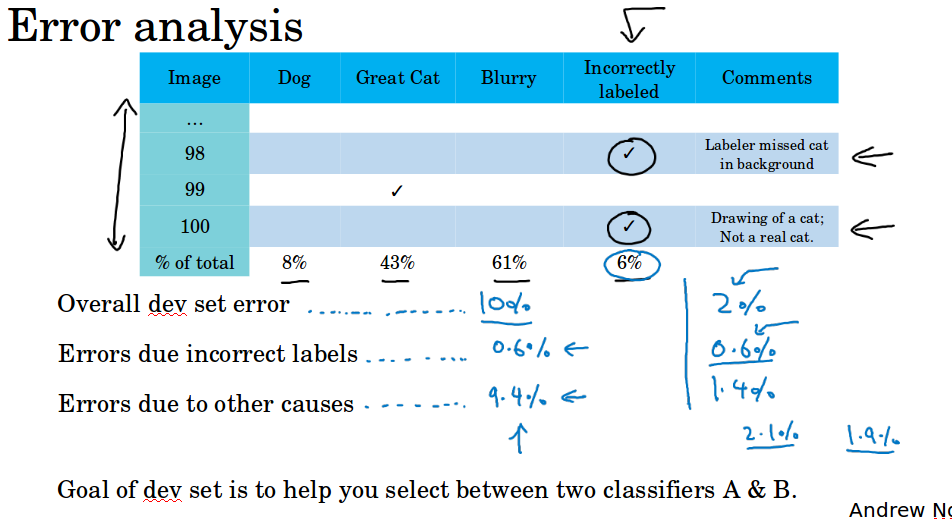
对于开发集和测试集的数据,你可以在误差分析表格(上节中提到的)中加多一列属性Incorrectly labeled,统计错误标注的数据比例,如果它严重影响了模型在开发集的表现,那么就应该花精力去处理。你可以观察三个指标去判断值不值得,首先是开发集上的错误率比如是10%,其次是标注错误带来的错误率比如是0.6%,最后是其它因素带来的错误率比如是9.4%,这个时候显然更应该把精力放在那9.4%的错误上。如果这三个指标是2%, 0.6%, 1.4%, 那么有30%的错误来自于错误标注,这个时候就要考虑去处理错误标注的问题。
在处理错误样本时,要同时处理开发集和测试集以保证它们处于同一分布。开发集和测试集来自同一分布很重要,而训练集有稍微的不同影响不大。
在检查样本的时候不仅要检查预测错误的,还应该检查预测正确的,因为可能预测为正确的样本也标注错了,只是你的分类器刚好预测到它标注错的那个类。这一点在实际上很难做,但也是要考虑的。通常不会这么做,原因是如果你的分类器很准确的话,预测正确的样本太多了,要去检查很花时间。
很多工程师和研究人员在构建深度学习系统的时候不愿意亲自去看这些数据,也许做这件事很无聊,坐下来看100或几百个例子来统计错误数量,但ng表示自己经常这么做,他想知道系统所犯的错误,他会亲自去看看这些数据,并和一部分错误做斗争,他相信花这些时间检查数据非常值得,ng强烈建议我们这么做。
3 快速搭建系统并迅速迭代( Build your first system quickly, then iterate)
如果你要建立一个全新的机器学习应用,ng的建议是快速搭建第一个系统,然后开始迭代。
首先快速设立开发集和测试集,还有评估指标,这决定了你的目标所在,如果目标定错了,之后再改也可以,但一定要设立一个目标。
然后快速搭建一个初始的模型,训练一下,看看效果,理解你的算法表现如何,在开发集测试集,你的评估指标如何。
搭建了模型后,就可以用到之前说的偏差方差分析,还有错误分析,来确定下一步做什么,如果错误分析能让你了解到大部分的错误来自于某个问题,你就有很好的理由去研究某一个问题,针对性地去解决问题来提高你的模型表现。
这是一个建议,如果你在这个领域有很多经验,那么这个建议的适用程度要低一些。
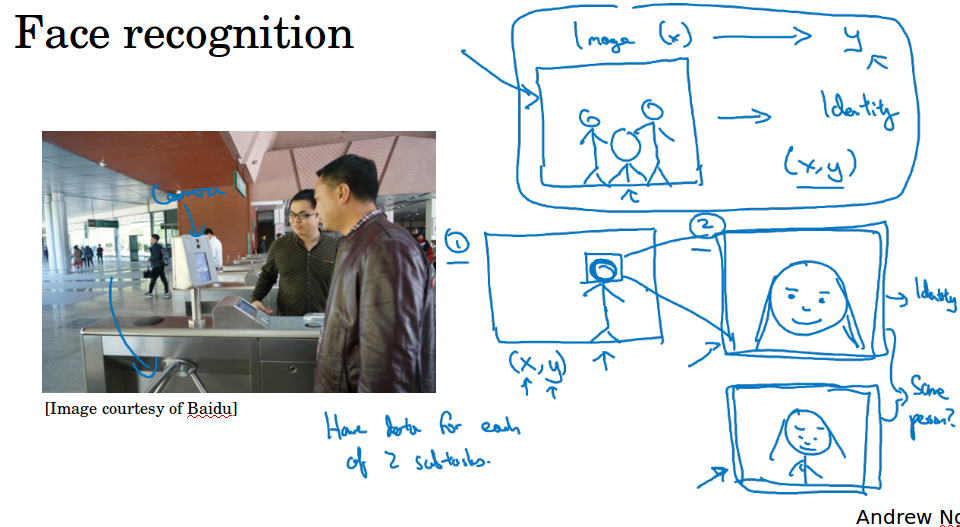
还有一种情况适用程度更低,就是当这个领域有很多可以借鉴的学术文献的时候,处理的问题和你要解决的问题几乎完全相同,比如,人脸识别 face recognition就有很多学术文献,如果你要做人脸识别文献,可以从现有的大量学术文献为基础出发,一开始就搭建比较复杂的系统。
4 在不同的分布训练和测试( training and testing on different distributions )
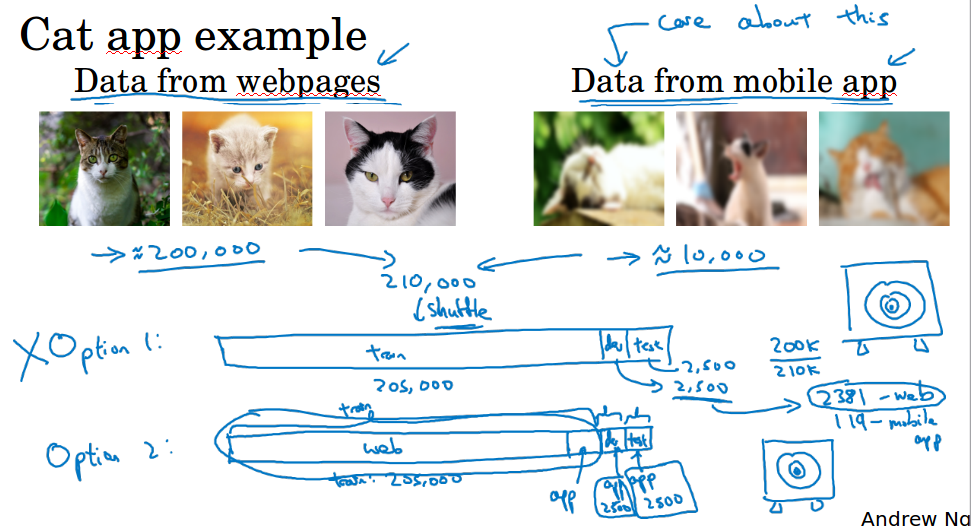
假设现在要做猫的识别,你有20w数据是从网页上爬下来的,有1w的数据是手机用户上传的,那么问题来了,你之后部署的应用是要给手机用户用的,那么正常来讲你应该用那1w数据来进行训练,但是1w数据又太少了,那20w数据又和手机用户上传的图片来自不同分布。
有一种做法就是把这两组数据加起来,然后随机分为205000的训练,2500的验证,2500的测试,这样的好处是训练,验证,测试来自同一分布。坏处的话很明显,因为我们的数据集中有20/21是来自网页的,也就是说在验证集和测试集中,大部分数据来自网页,那么你大部分的优化目标都在网页的数据上,这不是我们想要的。所以不要这儿做。
我们可以把20w网页数据加上5000手机用户的数据作为训练集,剩下5000的手机用户数据,2500验证,2500测试。这样做的好处就是,我们瞄准的目标(验证集)是我们要优化的目标,因为验证集是来自手机用户的数据。缺点在于你的训练集和验证测试集处于不同分布,但事实证明,这样能够在长时间内给你带来更好的系统性能。
5 数据分布不一致时候的偏差方差分析( Bias and Variance with mismatched data distributions )
当训练集和验证测试集的分布不一致时,偏差和方差的分析有些不一样。
当training error为1%,dev error为10%的时候,此时你无法判断方差为9%,因为dev和train处于不同分布,你无法判断这9%有多少是因为算法没有学习到dev的数据,有多少是因为分布不一致导致的。所以我们引入一个新的数据集。从training里取一部分作为training-dev,这个时候training和贝叶斯误差之间的差距视为偏差,training和training-dev的差距可以视为方差,training-dev和dev之间的差距可以视为数据不匹配带来的问题。另外dev和test的差距可以视为对dev过拟合的问题,如果开发集表现好而测试集表现不好,则是对开发集过拟合了,需要扩大开发集。
有一个有趣的现象,如下图右侧所示,dev和test的error高于train和train-dev的error,这是因为在验证测试集的数据比较容易学习。

6 处理信息不匹配( Addressing data mismatch )
显然因为数据分布不一致,在误差分析的时候引入了一个新的问题,数据不匹配。有什么好办法可以处理数据不匹配呢?实话说,并没有系统解决数据不匹配问题的办法。
但是你可以做一些尝试,可能会有帮助,那就是手动分析,尝试去理解训练集和验证集的差异。当你意识到验证集的错误性质后,你可以尝试把训练数据变得更像验证集,比如收集更多和验证集相似的数据。比如你在做语音识别的时候发现验证集的数据是含有一些噪音的,你可以在训练集中添加噪音。
添加噪音可以采用人工合成的方式,用一小时的汽车噪音,和汽车上的语音合成。需要注意的是,如果你只用一小时的汽车噪音,然后用大量的汽车正常语音都跟这一段汽车噪音合成,那么就容易对这段汽车噪音过拟合。可能人耳无法分辨1小时汽车噪音和1w小时汽车噪音的区别,但是对于机器来说,它们是不同的,你构造的1小时噪音,对噪音的样本空间来说可能只是很小很小的一部分。
人工合成的方式,可能会导致过拟合,因为你合成的数据可能只是巨大的样本空间中的很小的一部分。
7 迁移学习( Transfer learning )
有时候神经网络可以从一个任务中学到知识,并将这些知识或部分知识应用到另一个独立的任务中,这就是所谓的迁移学习。
比如你在训练了一个图像识别的神经网络后,你可以把最后一层输出层去掉,然后接上一个新的输出层(也可以添多几层),随机初始化新层的权重,形成新的神经网络,应用于放射诊断上。
然后用放射诊断的数据重新训练这个网络,如果你的数据小的话,你可能只需要训练最后一层或最后两层的权重;如果你有足够大的数据的话,可以重新训练整个网络,这个时候之前用于图像识别的网络训练就称为预训练( pre-training ),而后在放射诊断数据上的训练就称为微调( fine tuning )。
为什么这样做会有效呢,因为在图像处理的时候,可能前层做了一些边缘检测,曲线检测等等,学习到了很多结构信息,图像形状信息等等。从非常大的图像数据库学到的这些能力,可能有助于你在算法在放射诊断中做得更好。
迁移学习一般用于从大数据的神经网络学习迁移到只有少量数据的问题上。如果现在你在猫的识别上用100张训练的网络,想迁移到1000张数据的放射诊断问题上,就没什么用了,因为你这100张学到的知识,比不上那1000张放射数据学到的知识。
总结一下,任务A迁移到任务B,首先,AB两个任务的输入要一样;其次,A的数据要比B多;如果A的低层特征对B有帮助的话,迁移效果更好。

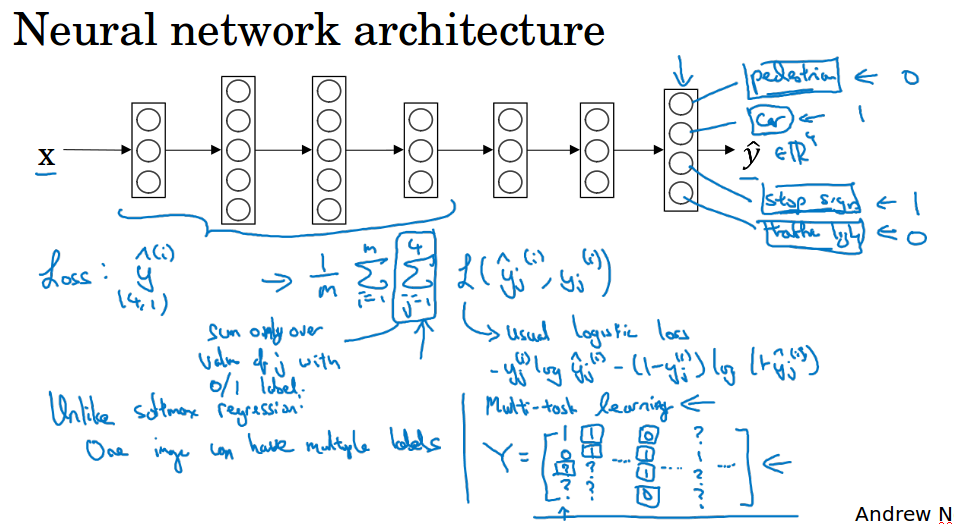
8 多任务学习( Multi-task learning )
多任务的学习中,神经网络同时学习几件任务,输出层含有多个输出单元,计算损失的时候,对每个单元计算逻辑回归的损失然后求平均。
与softmax回归不同,虽然输出单元都是多个,但是softmax是多个选一个,只有一个标签;而多任务学习是多个“二选一”,可以有很多个标签。
ng这里举的例子是无人驾驶中,同时识别是否有行人,是否有汽车,是否有停车标志,是否有交通灯。
你也可以训练多个网络来做这个多任务,但是神经网络的一些前层特征,在识别不同物体时都会用到,所以训练一个神经网络做多件事情,会比训练多个独立的神经网络的性能要好。
多任务学习什么时候有意义呢?
第一,如果你训练的一组任务可以共用低层次的特征;
第二,如果每个任务的数据量很接近,这个准则没有那么绝对,是ng从很多成功的深度学习系统学习到的经验;
第三,能够训练一个足够大的网络,有研究人员发现,神经网络不够大的情况下,训练一个网络同时完成多个任务,比训练多个网络独立完成多个任务的表现要差。
实践中,多任务学习的频率要低于迁移学习。ng见过很多迁移学习的应用,你需要解决一个问题,但你的训练数据很少,所以你需要找一个数据很多的相关问题来预学习,并将知识迁移到新问题上。但多任务学习比较少见,你需要同时处理很多任务,都要做好,ng认为这可能是现实中比较难找到一组类似的问题可以用同一个神经网络来解决,可能计算机视觉中的物体检测是个例子,人们经常训练一个网络来识别多个目标。
9 端到端学习( end-to-end deep learning )
传统的语音识别中,音频可能要经过一系列的流水线处理,得到特征,得到发音,得到单词,最后转化为文本。端到端学习的意思就是省去了中间这些步骤,直接拿x音频和y文本训练就能得到处理方法。
端到端学习的一个挑战是你可能需要大量数据才能让系统表现良好,比如你只有3000小时的数据,传统的流水线处理能得到比较好的结果。而如果你有1万或者10万小时的数据,那端到端学习的表现会更好。
在人脸识别中,通常不是拿到图片x(拍的角度,方位会有差异),直接计算出y,比如需要先检测出人脸的位置,然后用这个人脸跟数据库的人脸做比较。为什么两步法更好呢?
一是你解决的两个问题,每个问题实际上要简单得多。
二是两个子任务的训练数据都很多。输入图片,输出人脸的位置;输入两个人脸,判断两个人脸是否同一个人;很多业界的大公司都有很多这样的人脸数据集。相比之下,如果你想一步到位,你想输入图片x,输出那个人的身份,这样的数据就少很多,你没有足够的数据去解决这个端到端的学习。
机器翻译传统上也要经过一系列的流水线处理,但是你可以通过大量的翻译数据,使用端到端学习来解决。
根据孩子的x光照片来估计年龄,一般采用传统的分段处理来做,先分割出每块骨头,然后计算每块骨头的长度,然后查表得出什么样的骨头长度对应什么年龄。如果想直接通过照片来估测年龄,这种做法今天还不行,因为没有足够的数据来训练这个任务。
端到端学习的好处:让数据说话,防止引入人类的偏见;减少需要的手工组件;
端到端学习的缺点:需要大量数据;排除了可能有用的手工组件,精心设计的人工组件可能非常有用,尤其在数据量小的时候
是否需要使用端到端学习:关键在于你是否有足够的数据能学习到x到y之间的复杂函数