
k近邻算法学习
一.K近邻(K-Nearest Neighbor, KNN)是一种最经典和最简单的有监督学习方法之一。K-近邻算法是最简单的分类器,没有显式的学习过程或训练过程,是懒惰学习(Lazy Learning)。K近邻算法既能够用来解决分类问题,也能够用来解决回归问题。该方法有着非常简单的原理:当对测试样本进行分类时,首先通过扫描训练样本集,找到与该测试样本最相似的个训练样本,根据这个样本的类别进行投票确定测试样本的类别。也可以通过个样本与测试样本的相似程度进行加权投票。如果需要以测试样本对应每类的概率的形式输出,可以通过个样本中不同类别的样本数量分布来进行估计。
二.算法步骤
k-近邻算法步骤如下:
计算已知类别数据集中的点与当前点之间的距离;
按照距离递增次序排序;
选取与当前点距离最小的k个点;
确定前k个点所在类别的出现频率;
返回前k个点所出现频率最高的类别作为当前点的预测分类。

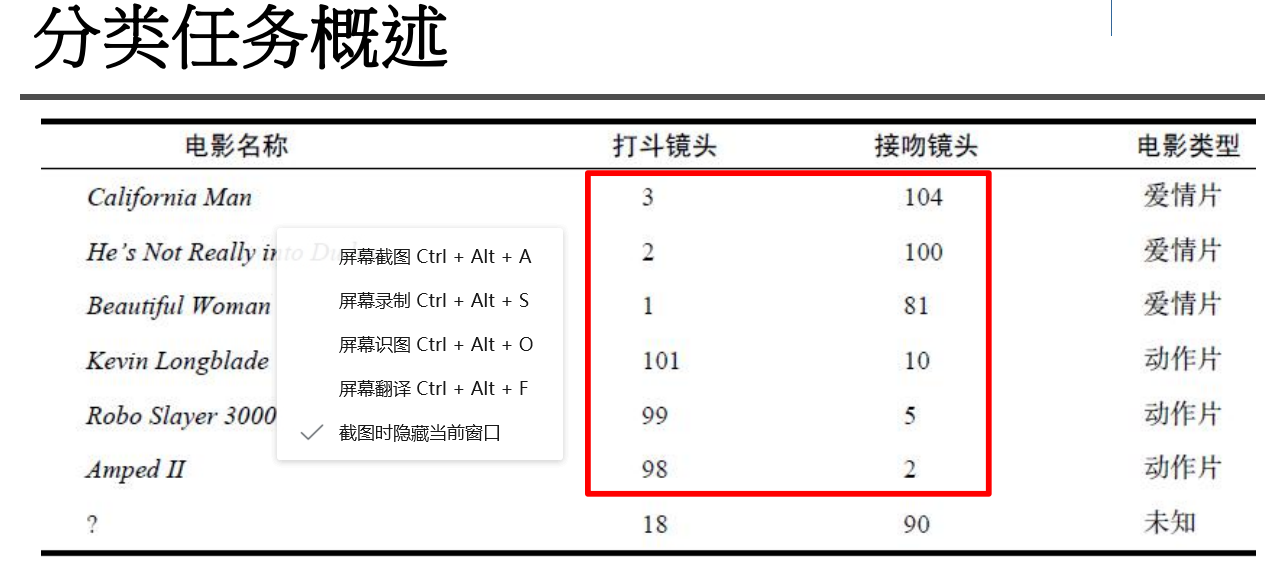

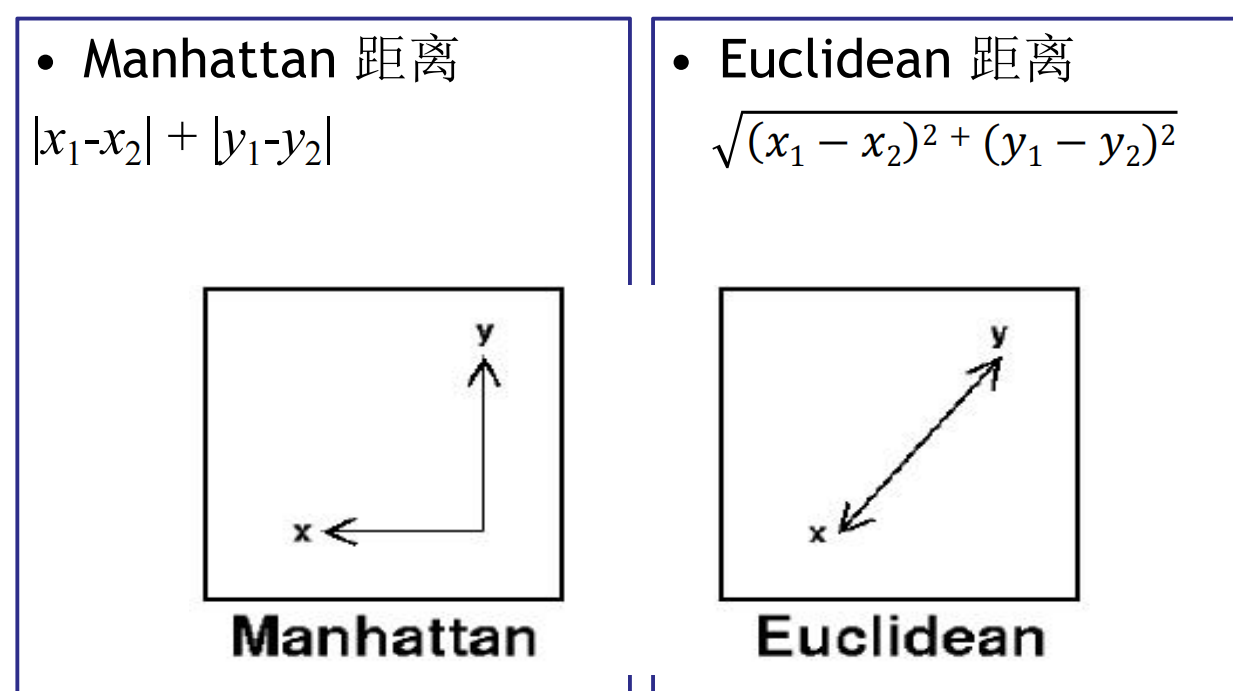
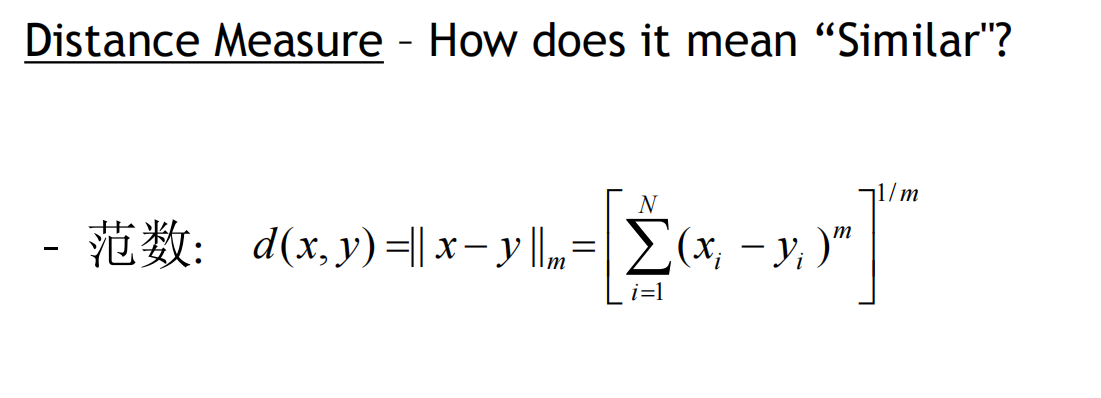

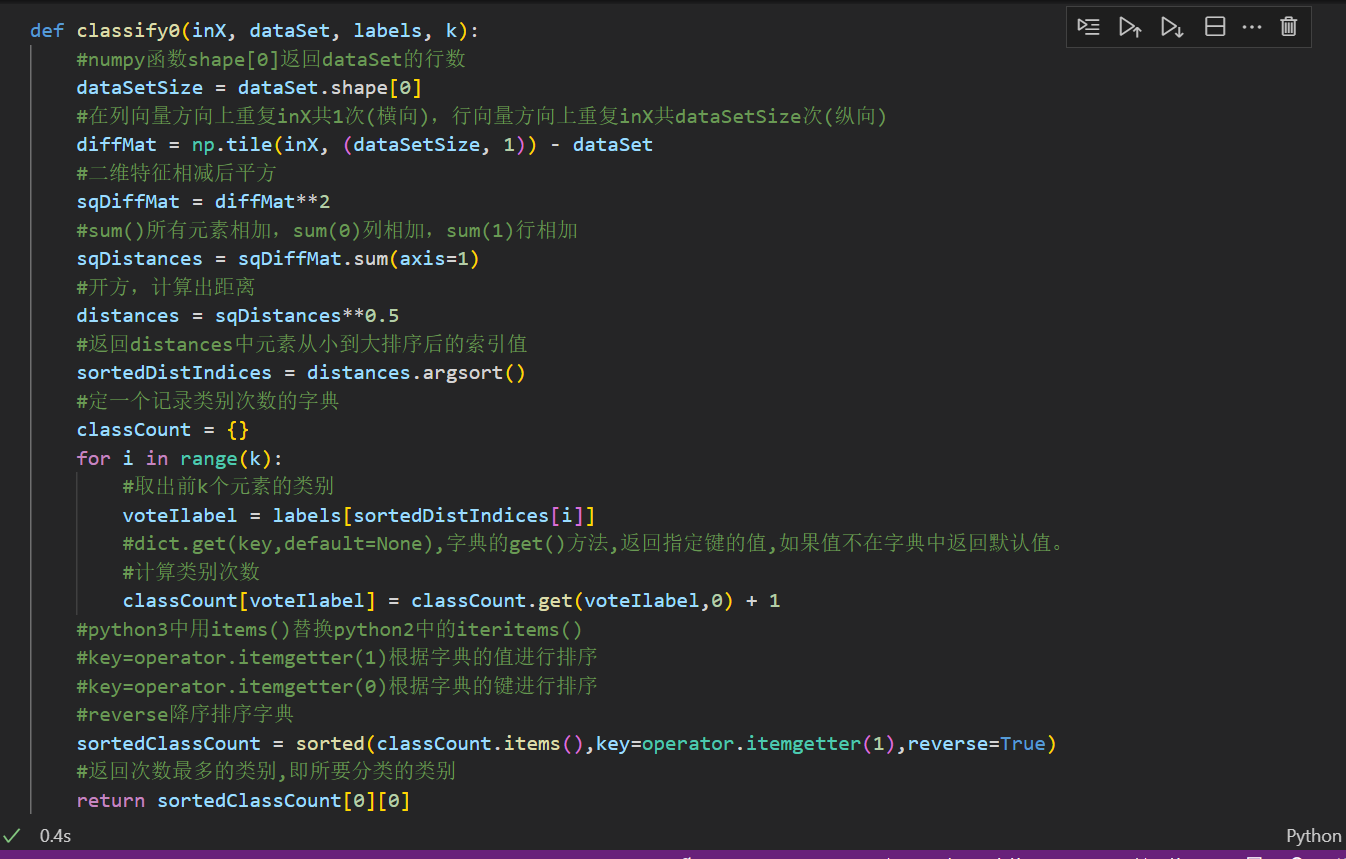
三.导入python数据
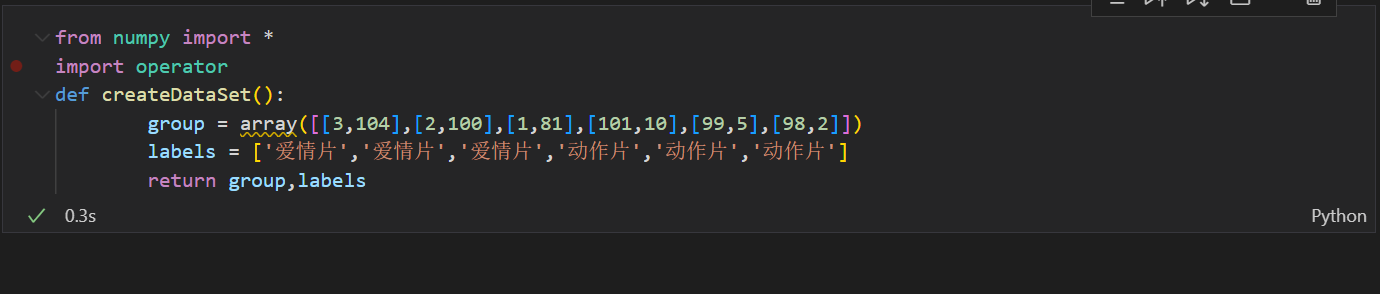
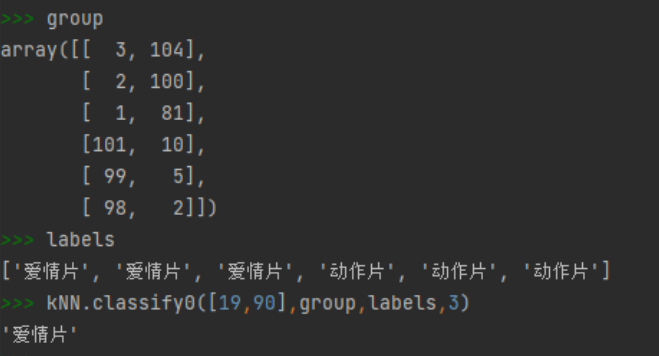
使用k临近算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号