

MSAA的原理
MSAA的原理
Aliasing(走样)
在介绍MSAA原理之前,我们先对走样(Aliasing)做个简单介绍。在信号处理以及相关领域中,走样(混叠)在对不同的信号进行采样时,导致得出的信号相同的现象。它也可以指信号从采样点重新信号导致的跟原始信号不匹配的瑕疵。它分为时间走样(比如数字音乐、以及在电影中看到车轮倒转等)和空间走样两种(摩尔纹)。这里我们不详细展开。

具体到实时渲染领域中,走样有以下三种:
-
几何体走样(几何物体的边缘有锯齿),几何走样由于对几何边缘采样不足导致。
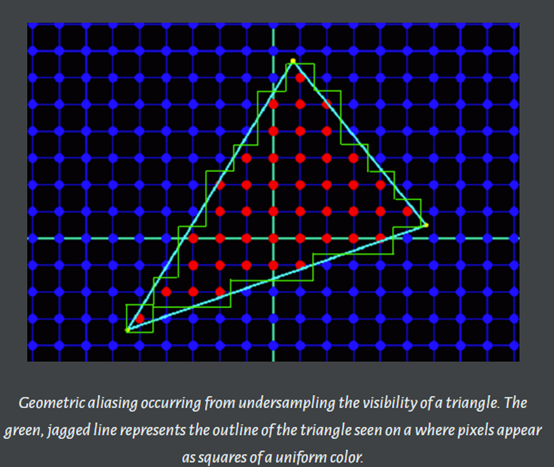
-
着色走样,由于对着色器中着色公式(渲染方程)采样不足导致。比较明显的现象就是高光闪烁。


上面一张图显示了由于对使用了高频法线贴图的高频高光BRDF采样不足时产生的着色走样。下面这张图显示了使用4倍超采样产生的效果。
-
时间走样,主要是对高速运动的物体采样不足导致。比如游戏中播放的动画发生跳变等。
SSAA(超采样反走样)
从名字可以看出,超采样技术就是以一个更大的分辨率来渲染场景,然后再把相邻像素值做一个过滤(比如平均等)得到最终的图像(Resolve)。因为这个技术提高了采样率,所以它对于解决上面几何走样和着色走样都是有效果的。如下图所示,首先经对每个像素取n个子采样点,然后针对每个子像素点进行着色计算。最后根据每个子像素的值来合成最终的图像。

虽然SSAA可以有效的解决几何走样和着色走样问题,但是它需要更多的显存空间以及更多的着色计算(每个子采样点都需要进行光照计算),所以一般不会使用这种技术。顺着上面的思路,如果我们对最终的每个像素着色,而不是每个子采样点着色的话,那这样虽然显存还是那么多,但是着色的数量少了,那它的效率也会有比较大的提高。这就是我们今天想要主要说的MSAA技术。
MSAA(多重采样反走样)
在前面提到的SSAA中,每个子采样点都要进行单独的着色,这样在片断(像素)着色器比较复杂的情况下还是很费的。那么能不能只计算每个像素的颜色,而对于那些子采样点只计算一个覆盖信息(coverage)和遮挡信息(occlusion)来把像素的颜色信息写到每个子采样点里面呢?最终根据子采样点里面的颜色值来通过某个重建过滤器来降采样生成目标图像。这就是MSAA的原理。注意这里有一个很重要的点,就是每个子像素都有自己的颜色、深度模板信息,并且每一个子采样点都是需要经过深度和模板测试才能决定最终是不是把像素的颜色得到到这个子采样点所在的位置,而不是简单的作一个覆盖测试就写入颜色。关于这个的出处,我在接下来的文章里会写出多个出处来佐证这一点。现在让我们先把MSAA的原理讲清楚。
Coverage(覆盖)以及Occlusion(遮挡)
一个支持D3D11的显卡支持通过光栅化来渲染点、线以及三角形。显卡上的光栅化管线把图形的顶点当作输入,这些顶点的位置是在经由透视变换的齐次裁剪空间。它们用来决定这个三角形在当前渲染目标上的像素的位置。这个可见像素由两个因素决定:
-
覆盖 覆盖是通过判断一个图形是否跟一个指定的像素重叠来决定的。在显卡中,覆盖是通过测试一个采样点是否在像素的中心来决定的。接下来的图片说明了这个过程。
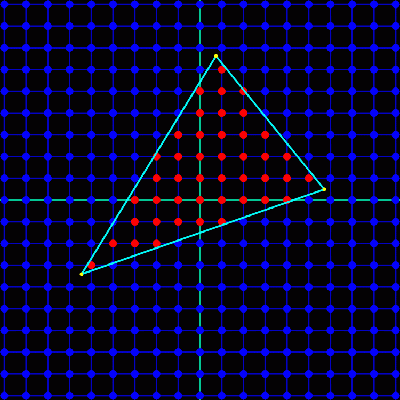
一个三角形的覆盖信息。蓝色的点代表采样点,每一个都在像素的中心位置。红色的点代表三角形覆盖的采样点。
-
遮挡告诉我们被一个图形覆盖的像素是否被其它的像素覆盖了,这种情况大家应该很熟悉就是z buffer的深度测试。
覆盖和遮挡两个一起决定了一个图形的可见性。
就光栅化而言,MSAA跟SSAA的方式差不多,覆盖和遮挡信息都是在一个更大分辨率上进行的。对于覆盖信息来说,硬件会对每个子像素根据采样规则生成n的子采样点。接下来的这张图展示了一个使用了旋转网格(rotated grid)采样方式的子采样点位置。

三角形会与像素的每个子采样点进行覆盖测试,会生成一个二进制覆盖掩码,它代表了这个三角形覆盖当前像素的比例。对于遮挡测试来说,三角形的深度在每一个覆盖的子采样点的位置进行插值,并且跟z buffer中的深度信息进行比较。由于深度测试是在每个子采样点的级别而不是像素级别进行的,深度buffer必须相应的增大以来存储额外的深度值。在实现中,这意味着深度缓冲区是非MSAA情况下的n倍。
MSAA跟SSAA不同的地方在于,SSAA对于所有子采样点着色,而MSAA只对当前像素覆盖掩码不为0的进行着色,顶点属性在像素的中心进行插值用于在片断程序中着色。这是MSAA相对于SSAA来说最大的好处。
虽然我们只对每个像素进行着色,但是并不意味着我们只需要存储一个颜色值,而是需要为每一个子采样点都存储颜色值,所以我们需要额外的空间来存储每个子采样点的颜色值。所以,颜色缓冲区的大小也为非MSAA下的n倍。当一个片断程序输出值时,只有地了覆盖测试和遮挡测试的子采样点才会被写入值。因此如果一个三角形覆盖了4倍采样方式的一半,那么一半的子采样点会接收到新的值。或者如果所有的子采样点都被覆盖,那么所有的都会接收到值。接下来的这张图展示了这个概念:
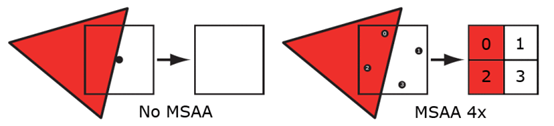
通过使用覆盖掩码来决定子采样点是否需要更新值,最终结果可能是n个三角形部分覆盖子采样点的n个值。接下来的图像展示了4倍MSAA光栅化的过程。
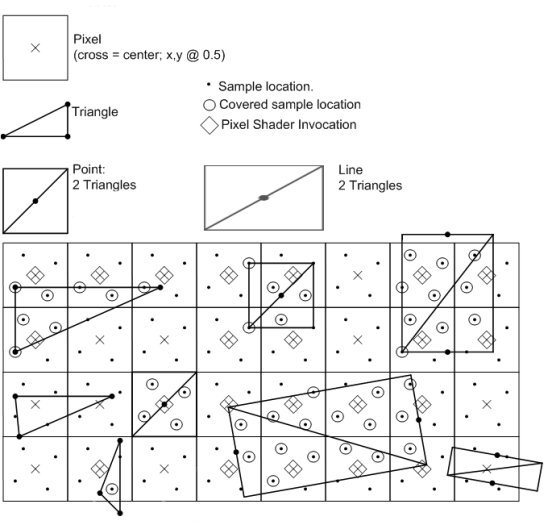
MSAA Resolve(MSAA 解析)
像超采样一样,过采样的信号必须重新采样到指定的分辨率,这样我们才可以显示它。
这个过程叫解析(resolving)。在它最早的版本里,解析过程是在显卡的固定硬件里完成的。一般使用的采样方法就是一像素宽的box过滤器。这种过滤器对于完全覆盖的像素会产生跟没有使用MSAA一样的效果。好不好取决于怎么看它(好是因为你不会因为模糊而减少细节,坏是因为一个box过滤器会引入后走样(postaliasing))。对于三角形边上的像素,你会得到一个标志性的渐变颜色值,数量等于子采样点的个数。接下来的图展示了这一现象:

当然不同的硬件厂商可能会使用不同的算法。比如nVidia的"Quincunx" AA等。随着显卡的不断升级,我们现在可以通过自定义的shader来做MSAA的解析了。
小结
通过上面的解释,我们可以看到,整个MSAA并不是在光栅化阶段就可以完全的,它在这个阶段只是生成覆盖信息。然后计算像素颜色,根据覆盖信息和深度信息决定是否来写入子采样点。整个完成后再通过某个过滤器进行降采样得到最终的图像。大体流程如下所示:
PC与Mobile对比
上面我们讲解了MSAA的基本原理,那么具体到不同显卡厂商以及不同平台上的实现有什么不同吗?下面就让我们做些简单的对比。其实,既然算法已经确定了,那么差异基本上就是在一些细节上的处理,以及GPU架构不同带来的差异。
版本
MSAA是否支持
自定义Shader解析
是否需要更大的颜色 深度 缓冲区
Direct3D 9
是
否
需要
Direct3D 11
是
是
需要
Direct3D 12
是
是
需要
OpenGL ES 2.0
(Multisample rasterization cannot be enabled or disabled after a GL context is created. It is enabled if the value of SAMPLE_BUFFERS is one, and disabled otherwise)
Multisample Texture:
使用GL_EXT_multisampled_render_to_texture扩展
苹果:
APPLE_framebuffer_multisample
安卓:
使用EGL
否
看GPU架构 :
TBR(Mali Qualcomm Adreno(300系列之前)) TBDR(PowerVR) 不需要
IMR(nVidia Tera Qualcomm Adreno 300系列以及之后可以在IMR、TBR之间切换)需要。
如果使用GL_EXT_multisampled_render_to_texture也需要(跟硬件实现有关(enabling MSAA the right way in OpenGL ES))。
OpenGL ES 3.0
是
(The technique is to sample all primitives multiple times at each pixel. The color sample values are resolved to a single, displayable color. For window system-provided framebuffers, this occurs each time a pixel is updated, so the antialiasing appears to be automatic at the application level. For application-created framebuffers, this must be requested by calling the BlitFramebuffer command (see section 4.3.3).)
When rendering textures, emphasis is placed on multisample anti-aliasing (MSAA), which earlier hardware generations could only run against the framebuffer. OpenGL ES 3.0 can presently support MSAA-type rendering for a texture.
否
如果是系统提供的framebuffer,那么同OpenGL ES 2.0的版本。如果是用户创建的framebuffer,那么是需要额外的显存的(跟硬件实现有关???)。
OpenGL ES 3.1
是
是(sampler2DMS)
如果是系统提供的framebuffer,那么同OpenGL ES 2.0的版本。如果是用户创建的framebuffer,那么是需要额外的显存的(跟硬件实现有关???)。
IMR vs TBR vs TBDR
IMR (立即渲染模式)
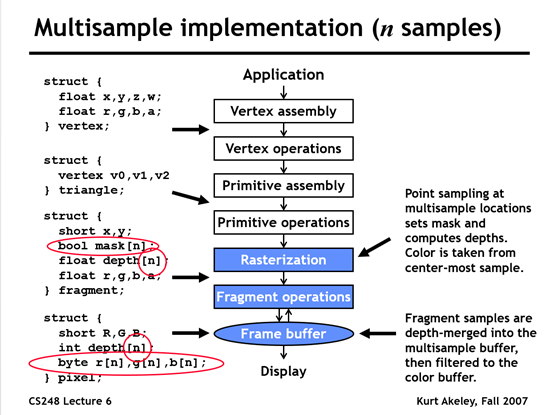
目前PC平台上基本上都是立即渲染模式,CPU提交渲染数据和渲染命令,GPU开始执行。它跟当前已经画了什么以及将来要画什么的关系很小(Early Z除外)。流程如下图所示:

TBR(分块渲染)
TBR把屏幕分成一系列的小块,每个单独来处理,所以可以做到并行。由于在任何时候显卡只需要场景中的一部分数据就可完成工作,这些数据(如颜色 深度等)足够小到可以放在显卡芯片上(on-chip),有效得减少了存取系统内存的次数。它带来的好处就是更少的电量消耗以及更少的带宽消耗,从而会获得更高的性能。

分块
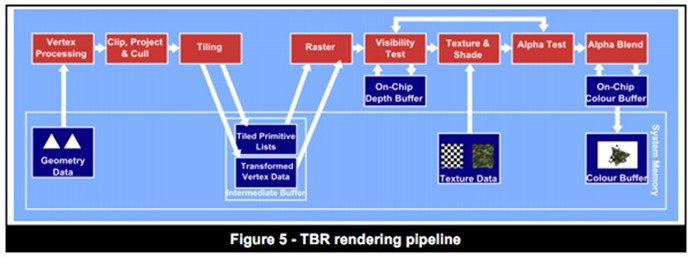
TBDR (分块延迟渲染)
TBDR跟TBR有些相似,也是分块,并使用在芯片上的缓存来存储数据(颜色以及深度等),它还使用了延迟技术,叫隐藏面剔除(Hidden Surface Removal),它把纹理以及着色操作延迟到每个像素已经在块中已经确定可见性之后,只有那些最终被看到的像素才消耗处理资源。这意味着隐藏像素的不必要处理被去掉了,这确保了每帧使用最低可能的带宽使用和处理周期数,这样就可以获取更高的性能以及更少的电量消耗。
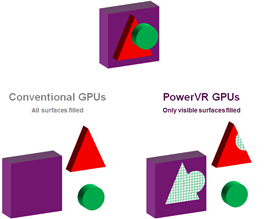
一个简单的对比传统GPU与TBDR
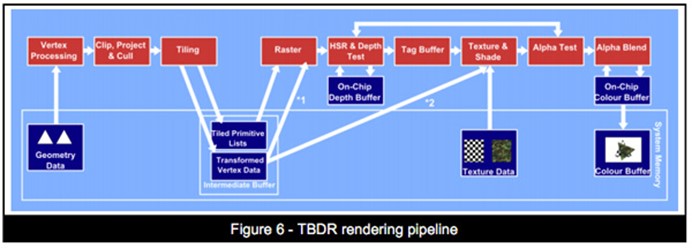
移动平台上的MSAA
有了上面对移动GPU架构的简单了解,下面我们看下在移动平台上是怎么处理MSAA的,如下图所示:
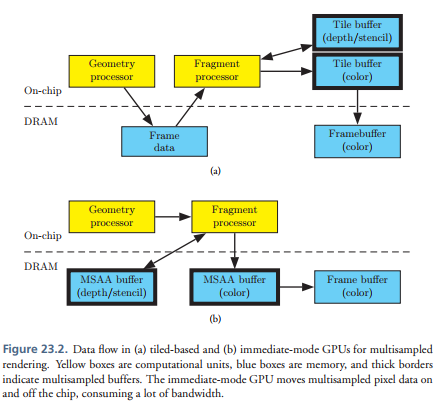
可以看到如果相对于IMR模式的显卡来说,TBR或者TBDR的实现MSAA会省很多,因为好多工作直接在on-chip上就完成了。这里还是有两个消耗:
- 4倍MSAA需要四倍的块缓冲内存。由于芯片上的块缓冲内存很最贵,所以显卡会通过减少块的大小来消除这个问题。减少块的大小对性能有所影响,但是减少一半的大小并不意味着性能会减半,瓶颈在片断程序的只会有一个很小的影响。
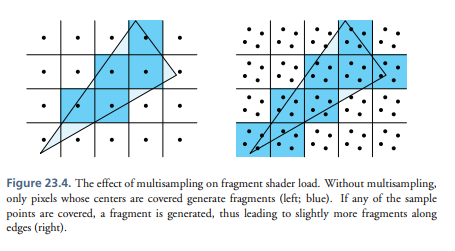
- 第二个影响就是在物体边缘会产生更多的片断,这个在IMR模式下也有。每个多边形都会覆盖更多的像素如下图所示。而且,背景和前景的图形都贡献到一个交互的地方,两片断都需要着色,这样硬件隐藏背面剔除就会剔除更少的像素。这些额外片断的消耗跟场景是由多少边缘组成有关,但是10%是一个比较好的猜测。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号