


R 读取, 列,某行,操作,保存
导入数据,观察数据,操作数据,可视化展示,关闭数据
data<-read.csv("xx.csv",header=1)#第一行是header,不是值 。
- 取数据时候,较有用的参数还有stringsasfactor=Fasle,这样就不会把所有的字符型变量转换成Factor因子。因子是不能用与字符串操作的,如分割字符串strsplit()
- 参数skip=1/2,跳过第一行/第二行后开始,header是第二行。
-
read.csv后,View($dataframe) 查看部分内容,观察表头、数据正常。
- dataframe$column观察。R对列内容中的末尾/前置的空格敏感,所以导入后通过dataframe$column观察这列内容是否含空格。包含的话用excel的TRIM()函数处理简便.
- 用R 去除单元格的首位空格等空白字符trimws($vector).如
![]()
- 用R 去除单元格的首位空格等空白字符trimws($vector).如

head(data) #观察数据
rownames(data)=data$memberid #把meberid列作为每行的索引key
R 对$,和[]引用方式是不同的, 方括号内逗号前指行,逗号后指列
列名,index索引一个意思
取列:
d$列名
d[,列名]
不建议d[[第几列]]
数据框d按第三列height列排序。列名是height
d[order(d$height),] 或
d[order(d[,3]),]
d[order(d[,3])][,c(1,3,6)] #数据框按第三列排序后,只列出1,3,6列
R 选择某写行观测值组成子数据框,这行的在某列值是95
d[d$value="95",]
操作列的时候建议加上,drop=False 防止字符串转为因子
取前两列d[1:2]
取第三行,5、6列 d[3:3,5:6]
取特定id的某列值 data["20211105","paymoney"]
取paymoney最大的行data[which.max(data$paymoney),]
最小的 which.min
取行:
d[1:2,]前两行
按行索引key取行data["20211105",]
取多行
data[c("20211105","20211104"),]
保存数据框到csv,用write_excel_csv($dataframe,"~/some.csv") #先library(tidyverse)
尤其对含中文的数据框保存时候必须用,不然用write.csv()的话,其他软件再打开保存文件显示中文是乱码(R软件读取都是正常)
数据框在第二列后新增列 data2<-cbind(data1[,1:2],y,data1[,3:ncol(data1)])
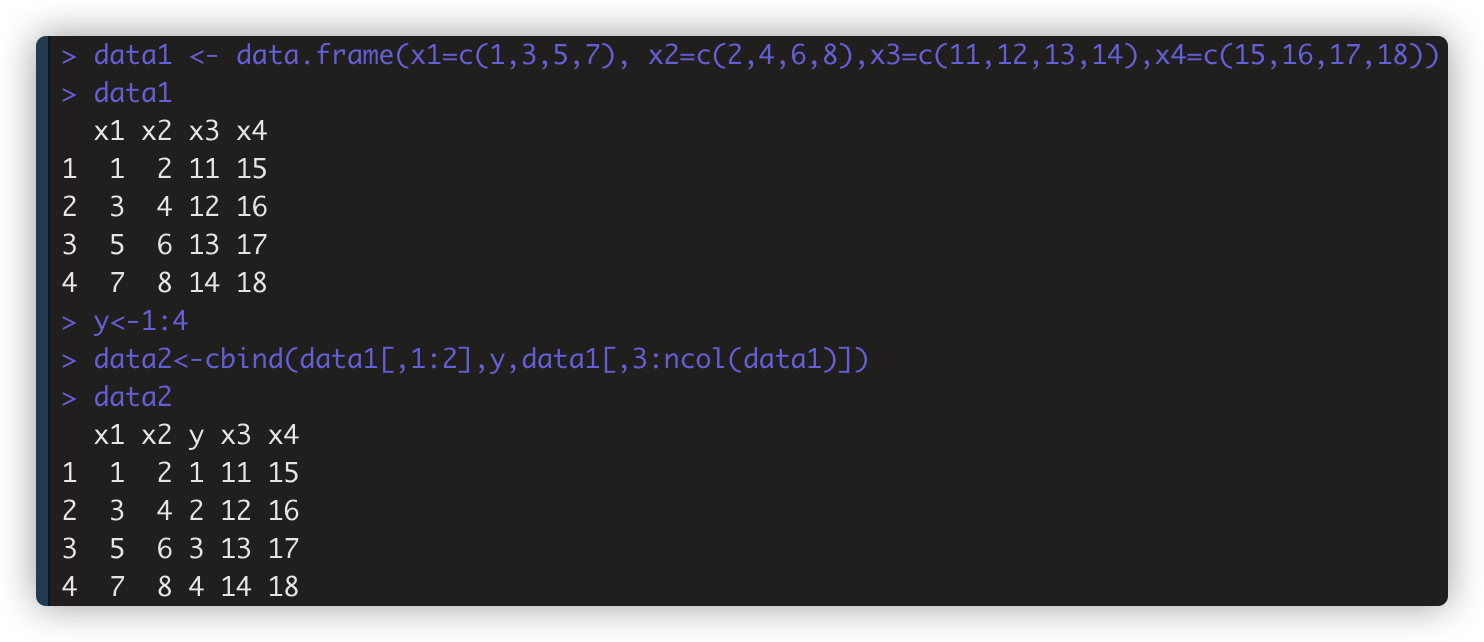
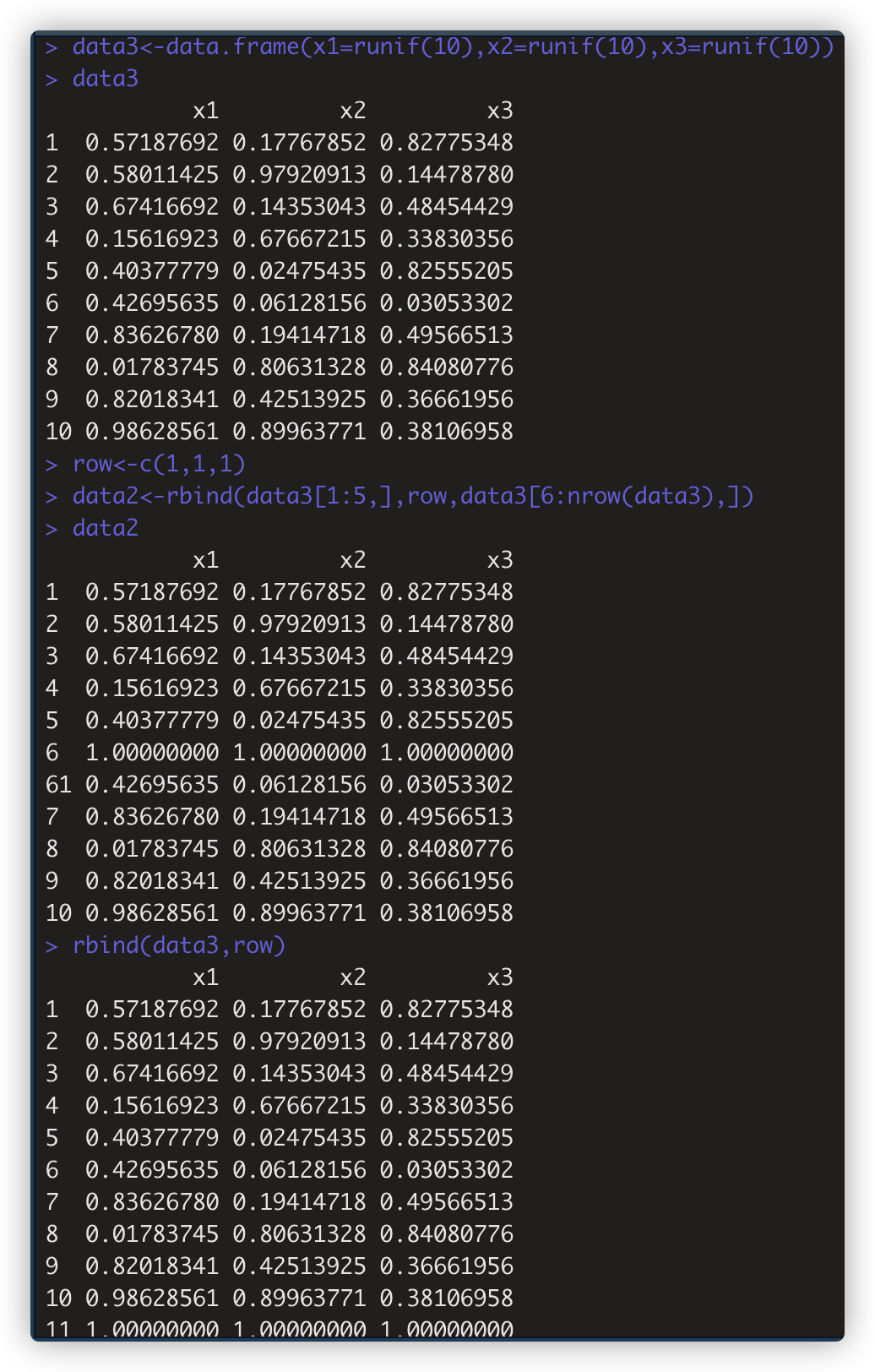
数据框在第5行后/最后新增行 data2<-rbind(data3[1:5,],row,data3[6:nrow(data3),])
rbind(data3,row)
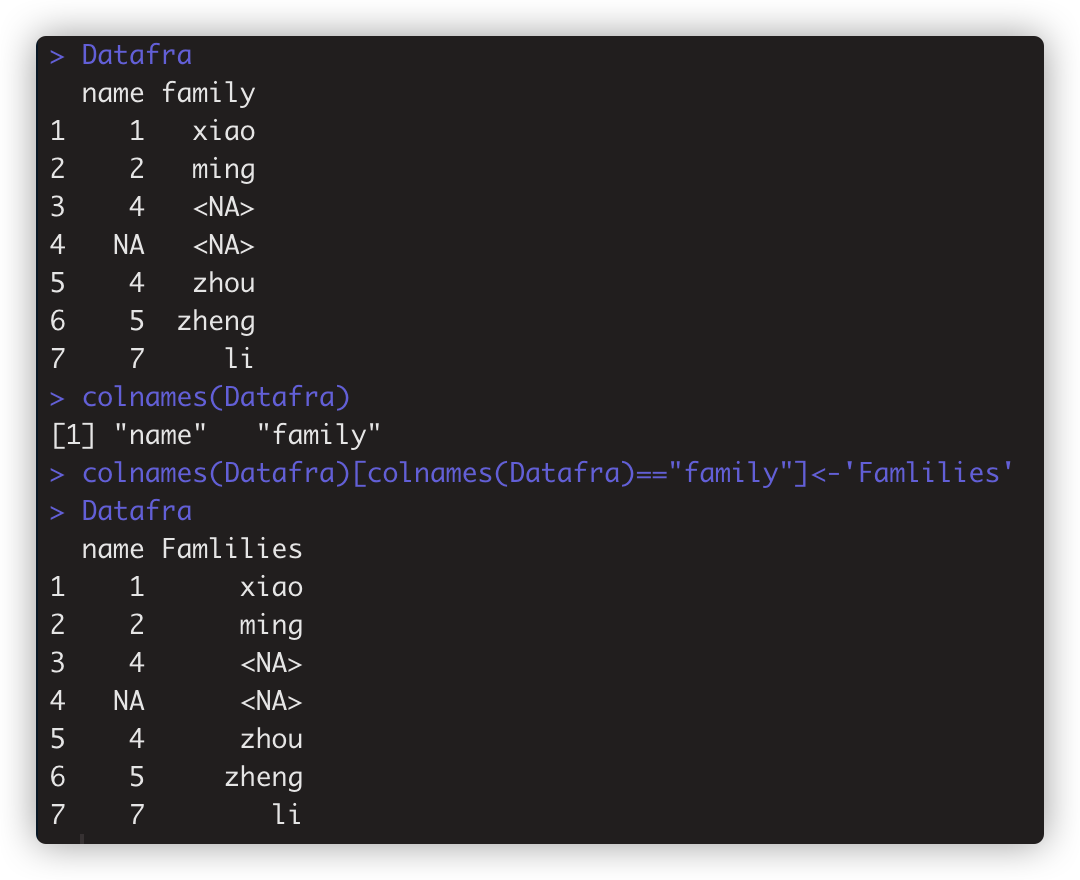
更改数据框的列名,colnames(Datafra)[colnames(Datafra)=="family"]<-'Famlilies'
更改列名 如 改第一列列名 colnames(baseline)[1]<-"Sample.ID"

本文来自博客园,作者:BioinformaticsMaster,转载请注明原文链接:https://www.cnblogs.com/koujiaodahan/p/15512824.html
posted on 2021-11-05 13:27 BioinformaticsMaster 阅读(8773) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号