
数据结构第七章学习小结
一、学习内容
|
线性表查找 (静态查找表) |
特点 |
ASL |
时间复杂度 |
优缺点 |
|
顺序查找 |
有序/无序 存储结构:顺序/链式 |
(n+1)/2 |
O(n) |
算法简单,对结构无要求; n越大,查找效率越低。 |
|
二分查找 |
有序 存储结构:顺序 |
Log(2)(n+1)-1 |
O(log(2)(n)) |
查找效率高,但对结构要求高。 |
|
分块查找 |
块内无序,块间有序 |
La+Lb (La:查找索引表 Lb:块内查找) |
较大 |
插入删除操作较容易;要增加一个索引表的存储空间并对初始化索引表进行排序运算。 |
关于二分查找变形:https://www.cnblogs.com/curo0119/p/8589554.html(参考资料)
基本格式:
1 while (left <= right) {//必须是等号 2 mid = (left + right) / 2; 3 if (key ? arr[mid]) { 4 right = mid - 1; 5 } else { 6 left = mid + 1; 7 } 8 } 9 return ?;
根据要求的值的位置,先确定比较符号,再确定返回值
比较符号:小于,大于等于:>=
小于等于,大于:>
返回值:要比较的值在key左边,返回right;
要比较的值在key右边,返回left;
***先进行right=mid-1;和先进行left = mid + 1;在规律上有差别(体现在找与key相等的两种情况中)***
|
树表的查找 (动态查找表) |
概括 |
ASL |
时间复杂度 |
优缺点 |
|
二叉排序树 (二叉搜索树) |
中序遍历后得到一个有序表,再进行逐步缩小范围的查找。 |
最坏情况:(n+1)/2 最好情况:与log(2)(n)成正比 |
与树的形态有关 树高为h:O(h) 高度越小速度越快。 |
插入删除查找操作简单,只需修改指针。 |
|
平衡二叉树 (AVL树) |
任一结点平衡因子的绝对值不大于1。 |
|
O(log(2)(n)) |
高度小,时间复杂度低,速度较快 |
|
B-树 |
多路搜索树 每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null。
|
|
|
必须用中序遍历的方法按序扫库。 |
|
B+树 |
多路搜索树 只有叶子节点存储data,叶子节点包含了这棵树的所有键值,叶子节点不存储指针。 |
|
|
保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。 |
哈希表(hash table):又称散列表,其基本思路是,设要存储的元素个数是n,设置一个长度为m的连续存储单元,以每个元素的关键字作为自变量,通过哈希函数(h(k))把k映射到一个内存单元,并把该元素存在这个内存单元中,把像这样构造的线性表存储结构称为哈希表。
哈希冲突(hash collisions):在构建哈希表时,出现两个不同关键词对应相同的哈希值,这种现象称作哈希冲突。
装填因子(loading factor):设哈希表空间大小为n,填入表中元素个数为m,则α=m/n,α为哈希表的装填因子。
构造:
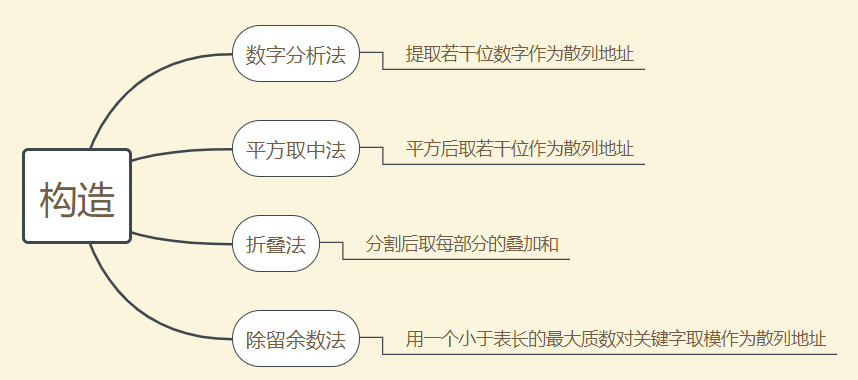
处理冲突的方法:

对比:
|
方法 |
缺点 |
优点 |
|
|
开放地址法 |
线性探测法 |
会产生“二次聚集”现象 |
只要散列表未填满,总能找到一个不发生冲突的地址 |
|
二次探测法 |
不能保证一定找到不发生冲突的地址 |
可以避免“二次聚集”现象 |
|
|
伪随机探测法 |
|||
|
链地址法 |
指针需要额外的空间 |
非同义词不会冲突,无“二次聚集”现象; 链表上结点空间动态申请,更适用于表长不确定的情况。 |
|
散列表性能分析:
散列查找的平均查找长度取决于以下因素:
(1)散列函数是否均匀
(2)处理冲突的方法
(3)散列表的装填因子
最后以本次PTA作业题为例,理清楚该算法的思路(采用了二次探测法):
(关于素数的判断函数需要重温一下~)
1 #include <iostream> 2 using namespace std; 3 4 bool IsPrime(int n) //判断素数 5 { 6 if(n<=1) return 0; 7 for(int i=2;i<n;i++) 8 { 9 if((n%i)==0) return 0; //能被任意n-1中的一个数整除 10 } 11 return 1; 12 } 13 14 int main() 15 { 16 int MSize, N; 17 cin >> MSize >> N; 18 19 while((IsPrime(MSize)==0)) //若输入的表长不是素数 20 { 21 MSize++; 22 } 23 int a[10007]={0};//表 24 int x; //要插入的数 25 for(int i=0;i<N;i++) 26 { 27 cin >> x; 28 int j=0; 29 int k = x%MSize; 30 int temp = k; 31 while(j<MSize) 32 { 33 if((a[k])==0) 34 { 35 a[k] = x; 36 cout << k; 37 break; 38 } 39 else 40 { 41 j++; 42 k = (temp+j*j) % MSize; 43 } 44 } 45 if(j==MSize) cout << "-"; 46 if(i!=N-1) cout << " "; 47 } 48 49 return 0; 50 }
二、学习心得
在本章内容学习中,个人认为内容较之前的简单一点点,算法思路都比较易懂,学起来也比较快,而且部分算法思路之前也有接触过,很奇妙;虽然如此,但是本章内容各部分方法较多样,要更好的区分并且熟记。希望在往后的学习中也能保持现在的热情和头脑!

