前言:
网上很多的文章都建议在使用IK分词器的时候,建立索引的时候使用ik_max_word模式;搜索的时候使用ik_smart模式。理由是max_word模式分词的结果会包含smart分词的结果,这样操作会使得搜索的结果很全面。
但在实际的应用中,我们会发现,有些时候,max_word模式的分词结果并不能够包含smart模式下的分词结果。
下面,我们就看一个简单的测试实例:
假设我们现在要分别在max_word模式和smart模式下搜索“2022年”,搜索结果如下表所示:
|
max_word模式
|
0 - 4 : 2022 | ARABIC
4 - 5 : 年 | COUNT
|
|
smart模式
|
0 - 5 : 2022年 | TYPE_CQUAN
|
我们会发现max_word模式下的分词结果并没有覆盖smart模式下的分词结果。这是什么原因导致的呢?
下面,我们通过分析IK分词器的处理流程来寻找答案。
IK分词器实现原理剖析
IKAnalyzer中包含3个子分词器
|
LetterSegmenter
|
处理英文字母和阿拉伯数字的分词器
|
|
CN_QuantifierSegmenter
|
处理中文数量词的分词器
|
|
CJKSegmenter
|
处理中文和日韩字符的分词器
|
下面我们看下这三个子分词器分别是如何工作的。
英文字符及阿拉伯数字子分词器
假设我们现在对“111aaa222bbb”这个字符串在max_word模式下进行分词处理,其分词的处理结果如下所示:
0 - 12 : 111aaa222bbb | LETTER
0 - 3 : 111 | ARABIC
3 - 6 : aaa | ENGLISH
6 - 9 : 222 | ARABIC
9 - 12 : bbb | ENGLISH
上面的第一列代表的是词元的起始位移和偏移量,中间列是词元字符信息,第三列是词元属性。
现在我们将上面的字符串做一些改变,对字符串“111aaa@222bbb”进行分词处理,我们会发现其分词结果如下所示:
0 - 13 : 111aa@a222bbb | LETTER
0 - 3 : 111 | ARABIC
3 - 5 : aa | ENGLISH
6 - 7 : a | ENGLISH
7 - 10 : 222 | ARABIC
10 - 13 : bbb | ENGLISH
现在我们再将上面的字符串做一些修改,变成“111aaa 222bbb”,那么我们会得到如下的分词结果:
0 - 6 : 111aaa | LETTER
0 - 3 : 111 | ARABIC
3 - 6 : aaa | ENGLISH
7 - 13 : 222bbb | LETTER
7 - 10 : 222 | ARABIC
10 - 13 : bbb | ENGLISH
上面的三个字符串除了中间的字符外其他地方是一样的,但是得到的分词结果却是有很多相同。
从分词结果中,我们可以看到LetterSegmenter会拆分出三种词性的词元,分别是LETTER(数字英文混合),ARABIC(数字),ENGLISH(英文)。这三种不同的词元属性分别对应了三种不同的处理流程。
细心的同学可能还会有一个疑问,字符串"111aaa@222bbb"与字符串"111aaa 222bbb"解析出来的混合词元不一样。这是因为@字符是英文字符的链接符号,但空格并不是。
中文数量词子分词器
主要分为数词处理流程和量词处理流程两部分组成,处理流程比较简单,这里不再进行详细叙述。
中文-日韩文子分词器
主要是根据处理词典中的词库进行分词处理,那么如果我们要处理的词语在词库中并不存在的话,会出现什么情况呢?
因为IK分词是一个基于词典的分词器,只有包含在词典的词才能被正确切分,IK解决分词歧义只是根据几条最佳的分词实践规则,并没有用到任何概率模型,也不具有新词发现的功能。
因此,如果我们要处理的文本在词库中不存在的时候,就会被切分成单个字符的模式。
分词歧义裁决器
我们尝试一下在smart模式下对"111aaa 222bbb"进行分词处理,我们会得到如下的分词结果:
0 - 6 : 111aaa | LETTER
7 - 13 : 222bbb | LETTER
那么为什么smart模式下的分词结果会和max_word模式下的分词结果不同呢?通过阅读IK分词器的源代码,我们会发现IK分词器下的smart模式主要是通过IKArbitrator这个类来实现的。
这个类是分词结果的歧义处理类。在了解IKArbitrator这个类的处理流程之前,我们需要先了解两个数据结构,Lexeme,QuickSortSet和LexemePath。
Lexeme是分词器中解析出来的词元结果,其主要的字段包括:
// 词元的起始位移
private int offset;
// 词元的相对起始位置
private int begin;
// 词元的长度
private int length;
// 词元文本
private String lexemeText;
// 词元类型
private int lexemeType;
QuickSortSet是IK分词器中用来对词元进行排序的集合。其中的排序规则是词元相对起始位置小的优先;相对起始位置相同的情况下,词元长度大的优先。
LexemePath继承了QuickSortSet,其代表的是词元链。在IK分词器的smart模式下,会出现多个词元链的候选集。
那么,我们怎么选择最优的词元链呢?选择的关键就在LexemePath的compareTo方法中。
public int compareTo(LexemePath o) {
// 比较有效文本长度
if (this.payloadLength > o.payloadLength) {
return -1;
} else if (this.payloadLength < o.payloadLength) {
return 1;
} else {
// 比较词元个数,越少越好
if (this.size() < o.size()) {
return -1;
} else if (this.size() > o.size()) {
return 1;
} else {
// 路径跨度越大越好
if (this.getPathLength() > o.getPathLength()) {
return -1;
} else if (this.getPathLength() < o.getPathLength()) {
return 1;
} else {
// 根据统计学结论,逆向切分概率高于正向切分,因此位置越靠后的优先
if (this.pathEnd > o.pathEnd) {
return -1;
} else if (pathEnd < o.pathEnd) {
return 1;
} else {
// 词长越平均越好
if (this.getXWeight() > o.getXWeight()) {
return -1;
} else if (this.getXWeight() < o.getXWeight()) {
return 1;
} else {
// 词元位置权重比较
if (this.getPWeight() > o.getPWeight()) {
return -1;
} else if (this.getPWeight() < o.getPWeight()) {
return 1;
}
}
}
}
}
}
return 0;
}
接下来,我们看看IK分词器是如何选择出最优词元链的?其主要处理流程如下:
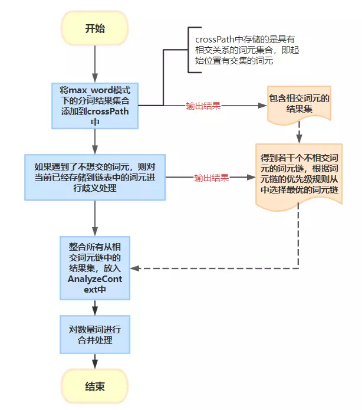
总结:
现在回到前言部分中我们提及的问题,经过我们对IK分词器处理流程地分析,我们很容易得到答案。
这是因为2022是数词,而年是量词。在max_word模式下,数词和量词不会进行合并处理。但是在smart模式下,数词和量词会进行合并处理。
通过阅读IK分词器的源码,我们会发现它并没有采用任何先进的算法模型,但是该分词器依然被广泛地被使用。
IK分词器被广泛使用,从某种意义上说明,很多真实的应用场景,并不需要使用那些先进而复杂的深度学习算法模型。低成本的浅层特征模型也仍然可以达到十分具有竞争力的准确率和召回率。
加入技术交流群,请扫描下方二维码。


