

Python爬取OPGG里英雄联盟位置排名数据,及其可视化
一、选题背景
近年来电子竞技在当今社会越来越来受欢迎,同时电子竞技也成了亚运会项目之一。英雄联盟便是奥运会上的项目类型之一,我国便曾在亚运会的英雄联盟项目上拿下冠军。所以我便选择了,英雄联盟这个项目来作为我的设计目标。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称
OPGG里英雄联盟位置排名数据,及其可视化
2.主题式网络爬虫爬取的内容与数据特征分析
爬取opgg中上单及射手的排名,名字,胜率,出场率,并对其进行分析。
数据来源:" http://www.op.gg/champion/statistics"
3.主题式网络爬虫设计方案概述
(1)实现思路
先对目标页面进行分析,利用urllib.爬虫库和BeautifulSoup库进行爬取解析,后分别用BeautifulSoup和正则表达式,分别查找所需要的数据。然后再保存为.csv文件,最后进行可视化分析。
(2)技术难点
request库出现问题,被迫学习使用urllib.request库,在编写re库的正则表达式中,发现自己熟练程度低,出错较多,在数据可视化上也出现了忘记代码的问题。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
首先得了解到本次爬取的网页为” http://www.op.gg/champion/statistics”
首先是本机的usr-agent查询,做准备
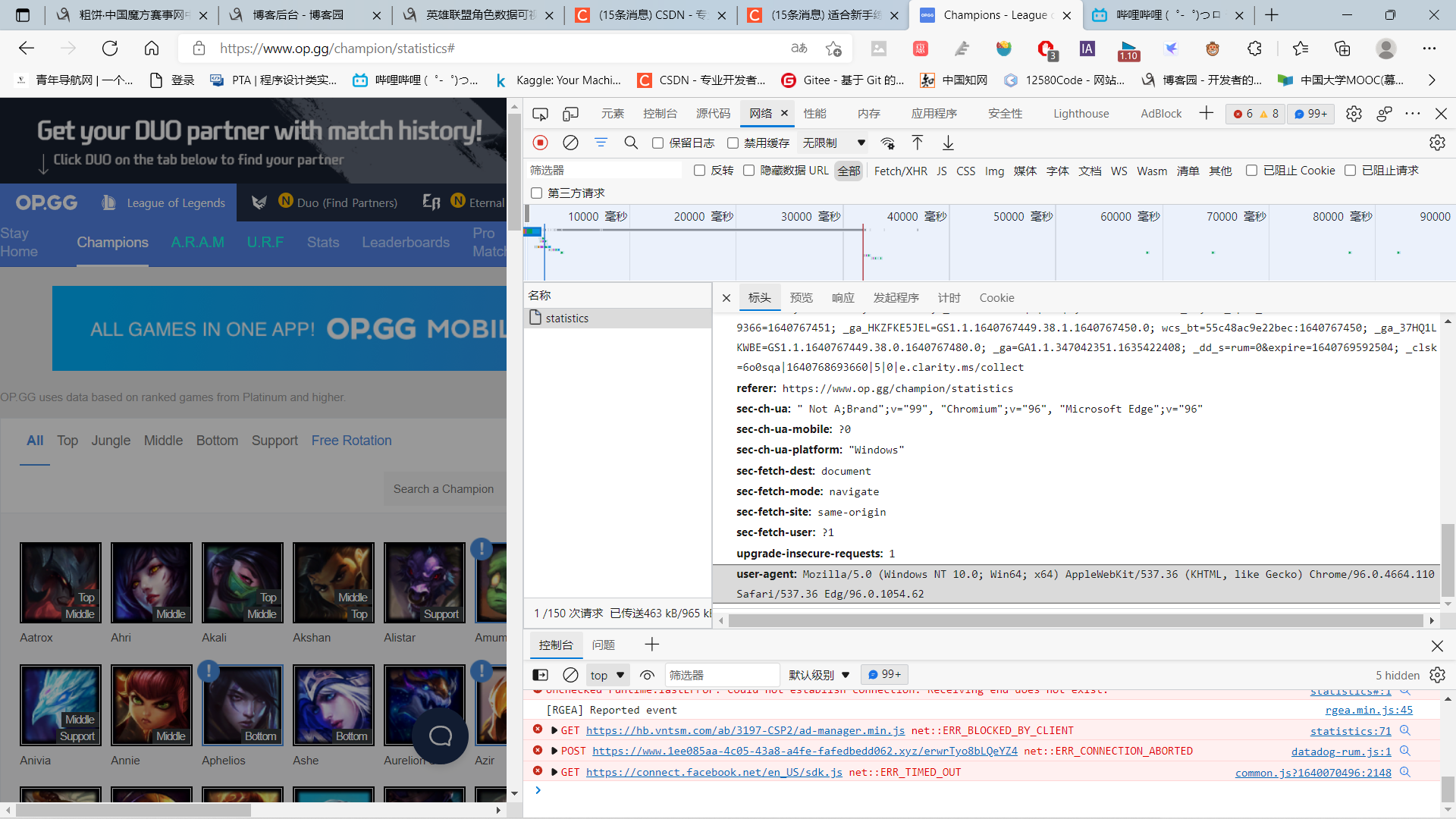
由网站界面可以看出,右侧有英雄的详细信息,以Garen为例,胜率为53.84%,选取率为16.99%,常用位置为上单。

2.Htmls 页面解析
现对网页源代码进行分析
代码中共有5个tbody标签(tbody标签开头结尾均有”tbody”,故共有10个”tbody”),对字段内容分析,分别为上单、打野、中单、ADC、辅助信息。
再对tbody标签进行查找

由此代码可看出,英雄名、胜率及选取率都在td标签中,而每一个英雄信息在一个tr标签中,td父标签为tr标签,tr父标签为tbody标签

3.节点(标签)查找方法与遍历方法
计划将Beautifulsoup查找,re库.正则表达式搭配查找
四、网络爬虫程序设计
1.数据爬取与采集
1 def askurl(urlbase):
2 import.urllib.request 引用urllib.request库
3 #模拟浏览器头部信息,向网站发送信息
4 header={
5 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62"
6 }
7 #模拟用户代理
8 request = urllib.request.Request(urlbase,headers=header)
9 #异常超时处理
10 try:
11 # html=""
12 response = urllib.request.urlopen(request,timeout=5)
13 html = response.read().decode("utf-8")
14 # print(html)
15 except Exception as a:
16 print(a)
17 return html
2.数据解析与整理
(1)采用BeautifulSoup解析提取数据
1 import pandas as pd #导入pandas库
2 import bs4 # 导入bs4库
3 from bs4 import BeautifulSoup # 导入BeautifulSoup库
4 url = "http://www.op.gg/champion/statistics"
5 # 获得html文档信息
6 html = askurl(url)
7 #解析数据
8 soup = BeautifulSoup(html,"html.parser")
9 top = []
10 name = [] #建立空列表用于储存数据
11 winRate = []
12 pickRate = []
13 # 遍历上单tbody标签的儿子标签
14 for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children:
15 # 判断tr是否为标签类型,去除空行
16 if isinstance(tr,bs4.element.Tag):
17 # 查找tr标签下的td标签
18 tds = tr('td')
19 #排名
20 top.append(tds[0].string)
21 # 英雄名
22 name.append(tds[3].find(attrs = "champion-index-table__name").string)
23 # 胜率 %百分号对后续有影响,去除
24 winRate.append(tds[4].string.replace('%',''))
25 # 选取率
26 pickRate.append(tds[5].string.replace('%',''))
27
28 #将准确获得的数据保存到列表中
29 df1 = pd.DataFrame(data=[top, name, winRate, pickRate], index=['排名', '英雄名', '英雄胜率', '英雄出场率'])
30 # 对文本进行,行换列,列换行
31 df2 = pd.DataFrame(df1.values.T, columns=df1.index)
32 # 保存数据到xlsx文件中
33 df2.to_excel('上单top.xlsx')
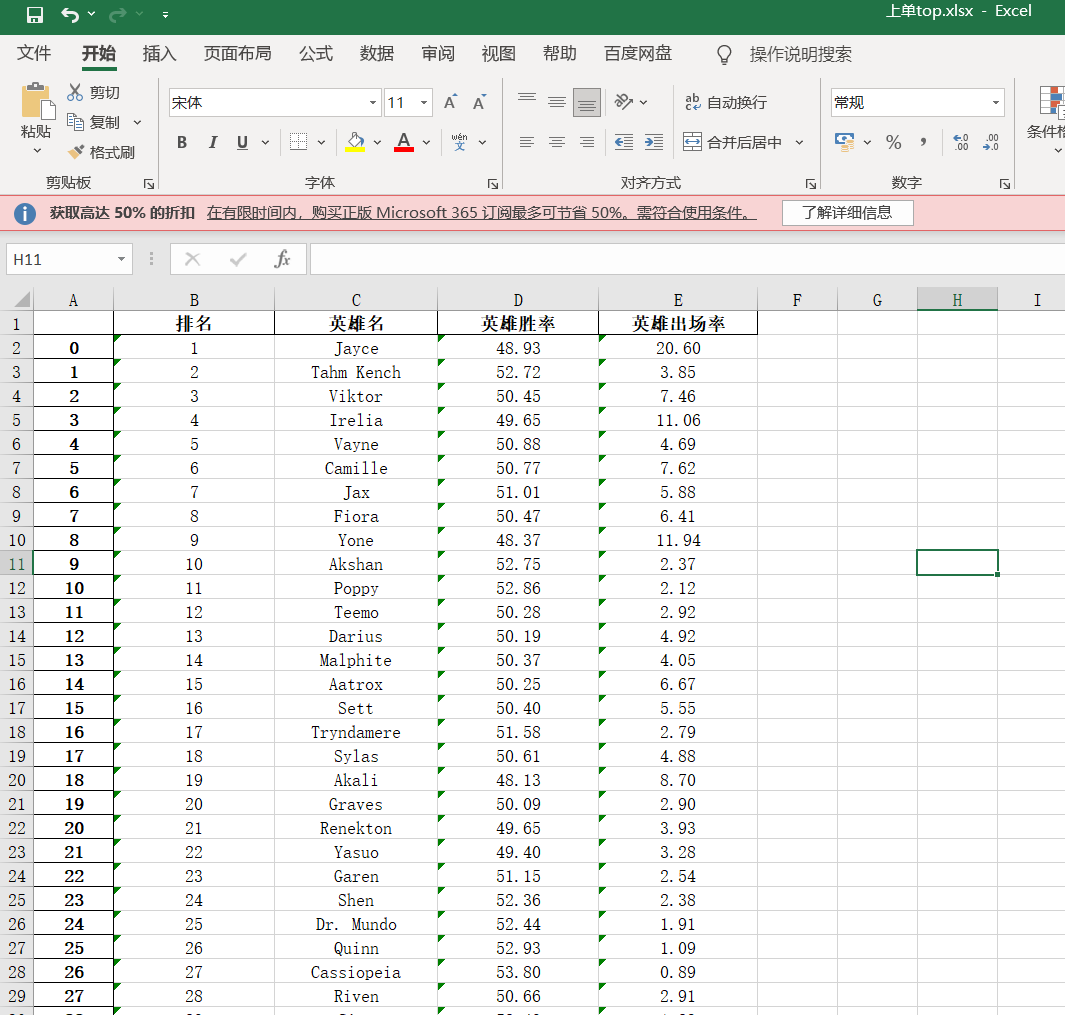
(2)利用正则提取法提取数据
1 from bs4 import BeautifulSoup
2 import re
3 import pandas as pd
4 ADtop = []
5 ADname = [] # 设立空表格
6 ADwinrate = []
7 ADpickrate = []
8 url = "http://www.op.gg/champion/statistics"
9 # 获得html文档信息
10 html = askurl(url)
11 # 解析数据
12 soup = BeautifulSoup(html, "html.parser")
13 # 取得射手标签内容
14 ADCdata = soup.find_all("tbody", class_="tabItem champion-trend-tier-ADC")
15 # 将BeautifulSoup类型转换为字符串类型,以便使用re库下的正则搜索
16 strADCdata = str(ADCdata)
17 # 通过网页源码得知,需要收集的排名,英雄名信息为23条
18 for i in range(0, 23):
19 # 排名 设定约束
20 findTop = re.compile(r'<td class="champion-index-table__cell champion-index-table__cell--rank">(\d*?)</td>')
21 # 运用约束查找
22 ADtop.append(re.findall(findTop, strADCdata)[i])
23 # 英雄名字 设定约束
24 findName = re.compile(r'<div class="champion-index-table__name">(.*?)</div>')
25 # 运用约束查找
26 ADname.append(re.findall(findName, strADCdata)[i])
27 # 运用正则表达式查找时发现胜率与选取率除了标签,内容完全相同,导致在上面的循环中会出现交叉获得的问题出现。
28 for i in range(0, 46, 2):
29 # 英雄胜率 设定约束 获得偶数的胜率
30 findWin = re.compile(
31 r'<td class="champion-index-table__cell champion-index-table__cell--value">(\d{0,3}\.\d{2})%</td>')
32 ADwinrate.append(re.findall(findWin, strADCdata)[i])
33 # 英雄出场率 设定约束 获得奇数的出场率
34 findappear = re.compile(
35 r'<td class="champion-index-table__cell champion-index-table__cell--value">(\d{0,3}\.\d{2})%</td')
36 ADpickrate.append(re.findall(findappear, strADCdata)[i + 1])
37
38 # 将数据保存到列表中
39 df3 = pd.DataFrame(data=[ADtop, ADname, ADwinrate, ADpickrate], index=['排名', '英雄名', '英雄胜率', '英雄出场率'])
40 # 对文本进行,行换列,列换行
41 df4 = pd.DataFrame(df3.values.T, columns=df3.index)
42 # 保存数据到xlsx文件中
43 df4.to_excel('射手top.xlsx')
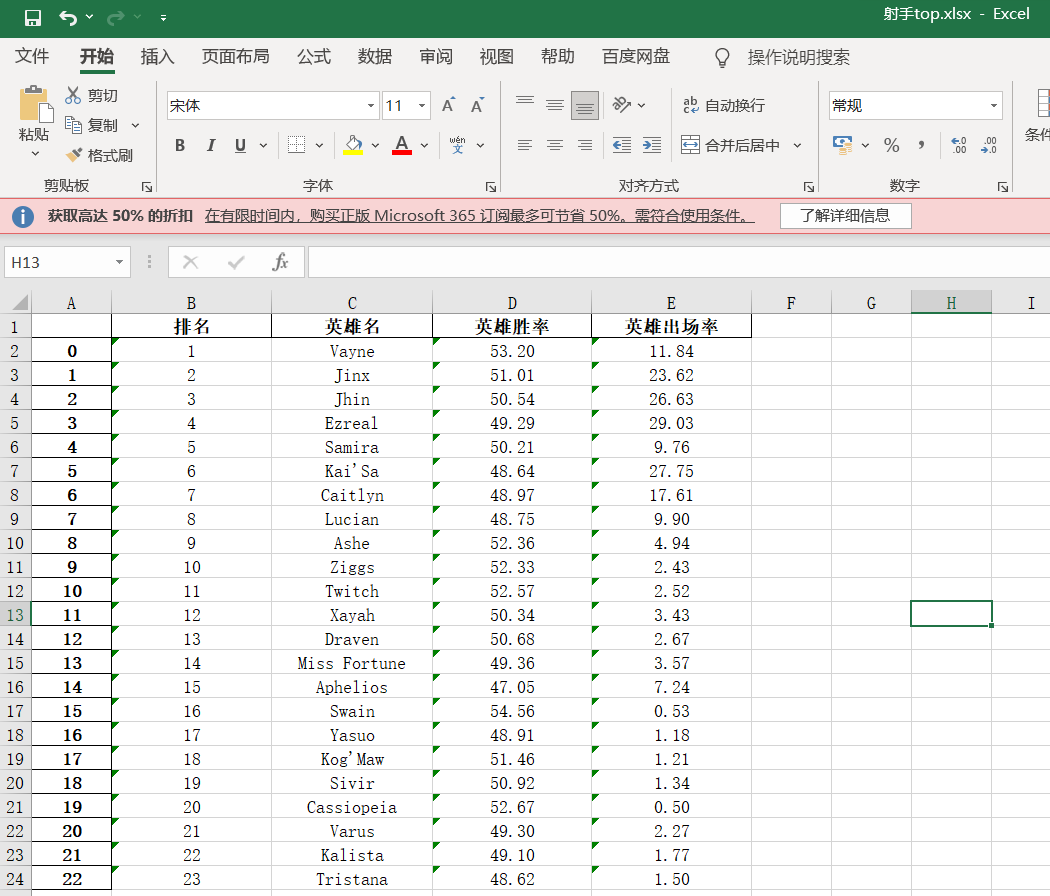
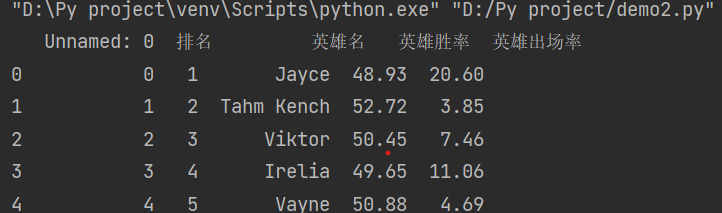
3.对数据进行清洗和处理
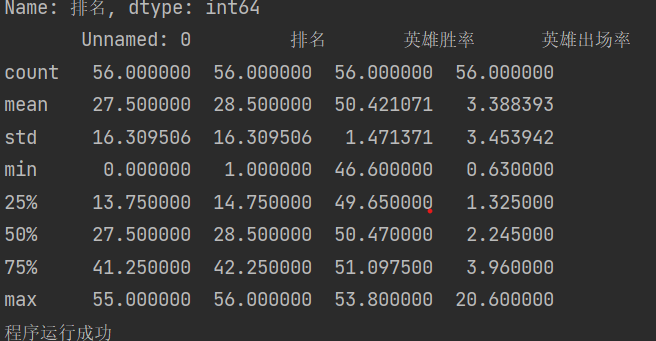
TOPrank = pd.DataFrame(pd.read_excel('上单top.xlsx')) print(TOPrank.head()) # #无无效列 # 检查是否有重复值 print(TOPrank.duplicated()) # 检查是否有空值 print(TOPrank['排名'].isnull().value_counts()) # 异常值处理 print(TOPrank.describe()) # 发现“排名”字段的最大值为56而平均值为28,假设异常值为56 # print(top.replace([56, top['排名'].mean()]))

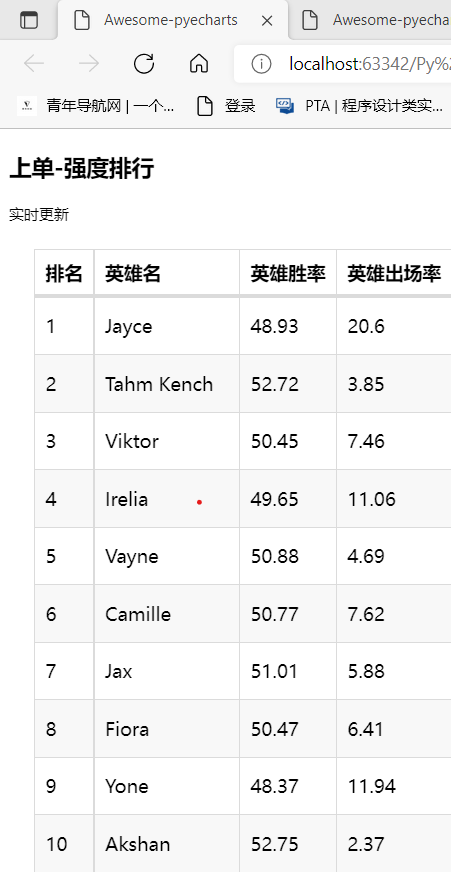
4.数据分析与可视化
1:运用pyecharts制作表格视图
1 import pandas as pd
2 from pyecharts.components import Table
3 from pyecharts.options import ComponentTitleOpts
4
5 # 分别导入上单数据
6 df_top = pd.read_excel('上单top.xlsx')
7 TOPTop = df_top['排名'].values.tolist()
8 TOPName = df_top['英雄名'].values.tolist()
9 TOPWin = df_top['英雄胜率'].values.tolist()
10 TOPpick = df_top['英雄出场率'].values.tolist()
11
12 #绘制上单表格视图
13 table2 = Table()
14 headers2 = ["排名", "英雄名", "英雄胜率", "英雄出场率"]
15 rows2 = [
16
17 ]
18 for i in range(0, 56):
19 rows2.append(df_top.iloc[i].values.tolist()[1:]) #转换插入格式
20 table2.add(headers2, rows2) #插入数据
21 table2.set_global_opts(
22 title_opts=ComponentTitleOpts(title="上单-强度排行", subtitle="实时更新") #设置标题与副标题
23 )
24 table2.render("上单pyecharts表格.html")
2:运用pyecharts制作柱状图
1 import pandas as pd
2 from pyecharts.charts import Bar
3 from pyecharts.globals import ThemeType
4 from pyecharts.options import global_options as opts
5
6 # 分别导入上单数据
7 df_top = pd.read_excel('上单top.xlsx')
8 TOPTop = df_top['排名'].values.tolist()
9 TOPName = df_top['英雄名'].values.tolist()
10 TOPWin = df_top['英雄胜率'].values.tolist()
11 TOPpick = df_top['英雄出场率'].values.tolist()
12
13 # 绘制上单柱状图
14 c = (
15 Bar({"theme": ThemeType.MACARONS})
16 .add_xaxis(TOPName) # 设置x轴
17 .add_yaxis("英雄胜率", TOPWin) # 添加柱状体
18 .add_yaxis("英雄出场率", TOPpick)
19 .set_global_opts(
20 title_opts={"text": "上单强度-示意图", "subtext": "综合胜率与出场率"}, # 设置标题与副标题
21 datazoom_opts=opts.DataZoomOpts(), # 分段
22 xaxis_opts=opts.AxisOpts(name_rotate=60, name="英雄名", axislabel_opts={"rotate": 35}) # 字体倾斜角度
23
24 )
25 .render("上单强度柱状图.html")
26 )

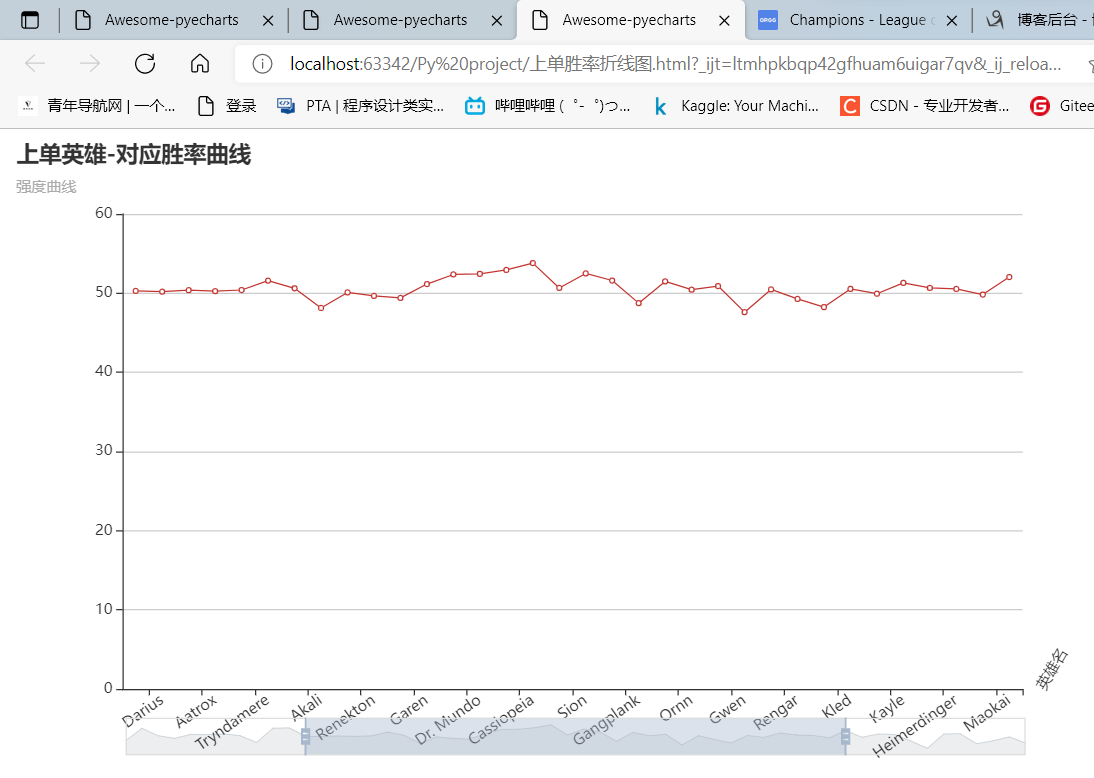
3:运用pyecharts制作折线图
1 import pandas as pd
2 import pyecharts.options as opts
3 from pyecharts.charts import Line
4 # 分别导入上单数据
5 df_top = pd.read_excel('上单top.xlsx')
6 TOPTop = df_top['排名'].values.tolist()
7 TOPName = df_top['英雄名'].values.tolist()
8 TOPWin = df_top['英雄胜率'].values.tolist()
9 TOPpick = df_top['英雄出场率'].values.tolist()
10 (
11 Line()
12 .set_global_opts(
13 tooltip_opts=opts.TooltipOpts(is_show=False),
14 xaxis_opts=opts.AxisOpts(type_="category"),
15 yaxis_opts=opts.AxisOpts(
16 type_="value",
17 axistick_opts=opts.AxisTickOpts(is_show=True),
18 splitline_opts=opts.SplitLineOpts(is_show=True),
19 ),
20 )
21 .add_xaxis(xaxis_data=TOPName)
22 .add_yaxis(
23 series_name="",
24 y_axis=TOPWin,
25 symbol="emptyCircle",
26 is_symbol_show=True,
27 label_opts=opts.LabelOpts(is_show=False),
28 )
29 .set_global_opts(
30 title_opts={"text": "上单英雄-对应胜率曲线", "subtext": "强度曲线"} ,
31 datazoom_opts=opts.DataZoomOpts(),#分段
32 xaxis_opts=opts.AxisOpts(name_rotate=60, name="英雄名", axislabel_opts={"rotate": 35})#字体倾斜角度
33 )
34 .render("上单胜率折线图.html")
35 )
5.完整代码
1 # -*- coding = utf-8 -*-
2 # @Time : 2021/12/24 14:49
3 # @Author : 真建彬
4 # @Student Number: 2003010221
5 # @File : demo2.py
6
7 def askurl(urlbase):
8 import urllib.request
9 #模拟浏览器头部信息,向网站发送信息
10 header={
11 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62"
12 }
13 #模拟用户代理
14 request = urllib.request.Request(urlbase,headers=header)
15 #异常超时处理
16 try:
17 # html=""
18 response = urllib.request.urlopen(request,timeout=5)
19 html = response.read().decode("utf-8")
20 # print(html)
21 except Exception as a:
22 print(a)
23 return html
24
25 def main():
26 from pyecharts.charts import Bar
27 from pyecharts.globals import ThemeType
28 import re
29 import pandas as pd
30 import bs4 # 导入bs4库
31 from bs4 import BeautifulSoup # 导入BeautifulSoup库
32 import pyecharts.options as opts
33 from pyecharts.charts import Line
34 from pyecharts.components import Table
35 from pyecharts.options import ComponentTitleOpts
36 url = "http://www.op.gg/champion/statistics"
37 # 获得html文档信息
38 html = askurl(url)
39 #解析数据
40 soup = BeautifulSoup(html,"html.parser")
41 top = []
42 name = [] #建立空列表用于储存数据
43 winRate = []
44 pickRate = []
45 # 遍历上单tbody标签的儿子标签
46 for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children:
47 # 判断tr是否为标签类型,去除空行
48 if isinstance(tr,bs4.element.Tag):
49 # 查找tr标签下的td标签
50 tds = tr('td')
51 #排名
52 top.append(tds[0].string)
53 # 英雄名
54 name.append(tds[3].find(attrs = "champion-index-table__name").string)
55 # 胜率 %百分号对后续有影响,去除
56 winRate.append(tds[4].string.replace('%',''))
57 # 选取率
58 pickRate.append(tds[5].string.replace('%',''))
59
60 #将准确获得的数据保存到列表中
61 df1 = pd.DataFrame(data=[top, name, winRate, pickRate], index=['排名', '英雄名', '英雄胜率', '英雄出场率'])
62 # 对文本进行,行换列,列换行
63 df2 = pd.DataFrame(df1.values.T, columns=df1.index)
64 # 保存数据到xlsx文件中
65 df2.to_excel('上单top.xlsx')
66 ##读取文件
67 TOPrank = pd.DataFrame(pd.read_excel('上单top.xlsx'))
68 print(TOPrank.head())
69
70 # #无无效列
71
72 # 检查是否有重复值
73 print(TOPrank.duplicated())
74
75 # 检查是否有空值
76 print(TOPrank['排名'].isnull().value_counts())
77
78 # 异常值处理
79 print(TOPrank.describe())
80 # 发现“排名”字段的最大值为56而平均值为28,假设异常值为56
81 # print(top.replace([56, top['排名'].mean()]))
82
83
84
85 ADtop=[]
86 ADname=[] #设立空表格
87 ADwinrate=[]
88 ADpickrate=[]
89 #取得射手标签内容
90 ADCdata = soup.find_all("tbody", class_="tabItem champion-trend-tier-ADC")
91 #将BeautifulSoup类型转换为字符串类型,以便使用re库下的正则搜索
92 strADCdata = str(ADCdata)
93 #通过网页源码得知,需要收集的排名,英雄名信息为23条
94 for i in range(0,23):
95 #排名 设定约束
96 findTop = re.compile(r'<td class="champion-index-table__cell champion-index-table__cell--rank">(\d*?)</td>')
97 #运用约束查找
98 ADtop.append(re.findall(findTop,strADCdata)[i])
99 #英雄名字 设定约束
100 findName=re.compile(r'<div class="champion-index-table__name">(.*?)</div>')
101 #运用约束查找
102 ADname.append(re.findall(findName,strADCdata)[i])
103 #运用正则表达式查找时发现胜率与选取率除了标签,内容完全相同,导致在上面的循环中会出现交叉获得的问题出现。
104 for i in range(0,46,2):
105 #英雄胜率 设定约束 获得偶数的胜率
106 findWin=re.compile(r'<td class="champion-index-table__cell champion-index-table__cell--value">(\d{0,3}\.\d{2})%</td>')
107 ADwinrate.append(re.findall(findWin,strADCdata)[i])
108 #英雄出场率 设定约束 获得奇数的出场率
109 findappear=re.compile(r'<td class="champion-index-table__cell champion-index-table__cell--value">(\d{0,3}\.\d{2})%</td')
110 ADpickrate.append(re.findall(findappear,strADCdata)[i+1])
111
112 # 将数据保存到列表中
113 df3 =pd.DataFrame(data=[ADtop, ADname, ADwinrate, ADpickrate], index=['排名','英雄名','英雄胜率','英雄出场率'])
114 # 对文本进行,行换列,列换行
115 df4 = pd.DataFrame(df3.values.T, columns=df3.index)
116 # 保存数据到xlsx文件中
117 df4.to_excel('射手top.xlsx')
118
119 ADCrank = pd.DataFrame(pd.read_excel('射手top.xlsx'))
120 print(ADCrank.head())
121
122 # #无无效列
123
124 # 检查是否有重复值
125 print(ADCrank.duplicated())
126
127 # 检查是否有空值
128 print(ADCrank['排名'].isnull().value_counts())
129
130 # 异常值处理
131 print(ADCrank.describe())
132 # 发现“排名”字段的最大值为23而平均值为12,假设异常值为23
133 # print(top2.replace([23, top2['排名'].mean()]))
134
135 #数据可视化:
136
137
138 #分别导入射手数据
139 df_ADC = pd.read_excel('射手top.xlsx')
140 ADCTop = df_ADC['排名'].values.tolist()
141 ADCName = df_ADC['英雄名'].values.tolist()
142 ADCWin = df_ADC['英雄胜率'].values.tolist()
143 ADCpick = df_ADC['英雄出场率'].values.tolist()
144
145 #分别导入上单数据
146 df_top = pd.read_excel('上单top.xlsx')
147 TOPTop = df_top['排名'].values.tolist()
148 TOPName = df_top['英雄名'].values.tolist()
149 TOPWin = df_top['英雄胜率'].values.tolist()
150 TOPpick = df_top['英雄出场率'].values.tolist()
151
152 #利用pyecharts做表格视图
153
154 #绘制射手表格视图
155 table1 = Table()
156 headers1 = ["排名", "英雄名", "英雄胜率", "英雄出场率"] #设置表头
157 rows1 = [
158
159 ]
160 for i in range(0, 23):
161 rows1.append(df_ADC.iloc[i].values.tolist()[1:]) #转换插入格式
162 table1.add(headers1, rows1) #插入数据
163 table1.set_global_opts(
164 title_opts=ComponentTitleOpts(title="射手-强度排行", subtitle="实时更新") #设置标题与副标题
165 )
166 table1.render("射手pyecharts表格.html")
167
168
169 #绘制上单表格视图
170 table2 = Table()
171 headers2 = ["排名", "英雄名", "英雄胜率", "英雄出场率"]
172 rows2 = [
173
174 ]
175 for i in range(0, 56):
176 rows2.append(df_top.iloc[i].values.tolist()[1:]) #转换插入格式
177 table2.add(headers2, rows2) #插入数据
178 table2.set_global_opts(
179 title_opts=ComponentTitleOpts(title="上单-强度排行", subtitle="实时更新") #设置标题与副标题
180 )
181 table2.render("上单pyecharts表格.html") #记录
182
183 #利用pyecharts绘制柱状图
184
185 #绘制射手柱状图
186 c = (
187 Bar({"theme": ThemeType.MACARONS})
188 .add_xaxis(ADCName) #设置x轴
189 .add_yaxis("英雄胜率", ADCWin) #添加柱状体
190 .add_yaxis("英雄出场率", ADCpick)
191 .set_global_opts(
192 title_opts={"text": "射手强度-示意图", "subtext": "综合胜率与出场率"}, #设置标题与副标题
193 datazoom_opts=opts.DataZoomOpts(), # 分段
194 xaxis_opts=opts.AxisOpts(name_rotate=60, name="英雄名", axislabel_opts={"rotate": 35}) # 字体倾斜角度
195
196 )
197 .render("ADC强度柱状图.html")
198 )
199 #绘制上单柱状图
200 c = (
201 Bar({"theme": ThemeType.MACARONS})
202 .add_xaxis(TOPName) #设置x轴
203 .add_yaxis("英雄胜率", TOPWin) #添加柱状体
204 .add_yaxis("英雄出场率", TOPpick)
205 .set_global_opts(
206 title_opts={"text": "上单强度-示意图", "subtext": "综合胜率与出场率"}, #设置标题与副标题
207 datazoom_opts=opts.DataZoomOpts(), # 分段
208 xaxis_opts=opts.AxisOpts(name_rotate=60, name="英雄名", axislabel_opts={"rotate": 35}) # 字体倾斜角度
209
210 )
211 .render("上单强度柱状图.html")
212 )
213
214
215 #利用pyecharts绘制折线图:
216
217 #绘制射手折线图
218 (
219 Line()
220 .set_global_opts(
221 tooltip_opts=opts.TooltipOpts(is_show=False),
222 xaxis_opts=opts.AxisOpts(type_="category"),
223 yaxis_opts=opts.AxisOpts(
224 type_="value",
225 axistick_opts=opts.AxisTickOpts(is_show=True),
226 splitline_opts=opts.SplitLineOpts(is_show=True),
227 ),
228 )
229 .add_xaxis(xaxis_data=ADCName)
230 .add_yaxis(
231 series_name="",
232 y_axis=ADCWin,
233 symbol="emptyCircle",
234 is_symbol_show=True,
235 label_opts=opts.LabelOpts(is_show=False),
236 )
237 .set_global_opts(
238 title_opts={"text": "射手英雄-对应胜率曲线", "subtext": "强度曲线"},
239 datazoom_opts=opts.DataZoomOpts(), # 分段
240 xaxis_opts=opts.AxisOpts(name_rotate=60, name="英雄名", axislabel_opts={"rotate": 35}) # 字体倾斜角度
241
242 )
243 .render("ADC胜率折线图.html")
244 )
245
246 #绘制上单折线图
247 (
248 Line()
249 .set_global_opts(
250 tooltip_opts=opts.TooltipOpts(is_show=False),
251 xaxis_opts=opts.AxisOpts(type_="category"),
252 yaxis_opts=opts.AxisOpts(
253 type_="value",
254 axistick_opts=opts.AxisTickOpts(is_show=True),
255 splitline_opts=opts.SplitLineOpts(is_show=True),
256 ),
257 )
258 .add_xaxis(xaxis_data=TOPName)
259 .add_yaxis(
260 series_name="",
261 y_axis=TOPWin,
262 symbol="emptyCircle",
263 is_symbol_show=True,
264 label_opts=opts.LabelOpts(is_show=False),
265 )
266 .set_global_opts(
267 title_opts={"text": "上单英雄-对应胜率曲线", "subtext": "强度曲线"},
268 datazoom_opts=opts.DataZoomOpts(), # 分段
269 xaxis_opts=opts.AxisOpts(name_rotate=60, name="英雄名", axislabel_opts={"rotate": 35}) # 字体倾斜角度
270
271 )
272 .render("上单胜率折线图.html")
273 )
274
275
276
277
278
279 #调用主函数
280 if __name__=="__main__":
281 main()
282 print('程序运行成功')
五、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
结论:
(1)游戏里英雄强度强,并不代表着高选取率高胜率的结果。
(2)获取和处理数据上我巩固了许多知识,使运用他们变得更加熟悉。
达到了预期的目标。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
收获:熟练了爬虫的操作,且能更好的运用正则表达式
建议:有很多小细节卡了我很久,还是需要稳固基础。

