1.大数据概述
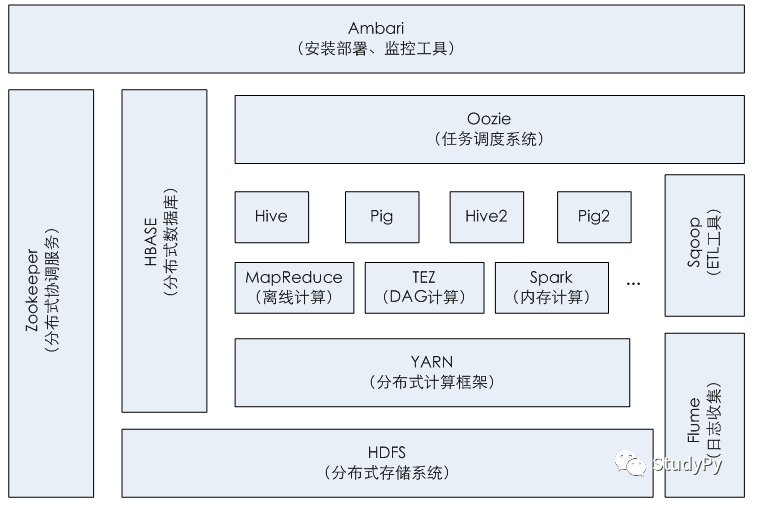
- 列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
Hadoop生态组件包括:HDFS、HBASE、Mapreduce、hive、pig、Sqoop、Flume、Ambari等功能组件。
2.对比Hadoop与Spark的优缺点
(1)Spark对标于Hadoop中的计算模块MR,但是速度和效率比MR要快得多;
(2)Spark没有提供文件管理系统,所以,它必须和其他的分布式文件系统进行集成才能运作,它只是一个计算分析框架,专门用来对分布式存储的数据进行计算处理,它本身并不能存储数据;
(3)Spark可以使用Hadoop的HDFS或者其他云数据平台进行数据存储,但是一般使用HDFS;
(4)Spark可以使用基于HDFS的HBase数据库,也可以使用HDFS的数据文件,还可以通过jdbc连接使用Mysql数据库数据;Spark可以对数据库数据进行修改删除,而HDFS只能对数据进行追加和全表删除;
(5)Spark数据处理速度秒杀Hadoop中MR;
(6)Spark处理数据的设计模式与MR不一样,Hadoop是从HDFS读取数据,通过MR将中间结果写入HDFS;然后再重新从HDFS读取数据进行MR,再刷写到HDFS,这个过程涉及多次落盘操作,多次磁盘IO,效率并不高;而Spark的设计模式是读取集群中的数据后,在内存中存储和运算,直到全部运算完毕后,再存储到集群中;
(7)Spark是由于Hadoop中MR效率低下而产生的高效率快速计算引擎,批处理速度比MR快近10倍,内存中的数据分析速度比Hadoop快近100倍(源自官网描述);
(8)Spark中RDD一般存放在内存中,如果内存不够存放数据,会同时使用磁盘存储数据;通过RDD之间的血缘连接、数据存入内存中切断血缘关系等机制,可以实现灾难恢复,当数据丢失时可以恢复数据;这一点与Hadoop类似,Hadoop基于磁盘读写,天生数据具备可恢复性;
(9)Spark引进了内存集群计算的概念,可在内存集群计算中将数据集缓存在内存中,以缩短访问延迟,对7的补充;
(10)Spark中通过DAG图可以实现良好的容错。
3.如何实现Hadoop与Spark的统一部署?
一方面,由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代的,比如,Storm可以实现毫秒级响应的流计算,但是,Spark则无法做到毫秒级响应。另一方面,企业中已经有许多现有的应用,都是基于现有的Hadoop组件开发的,完全转移到Spark上需要一定的成本。因此,在许多企业实际应用中,Hadoop和Spark的统一部署是一种比较现实合理的选择。
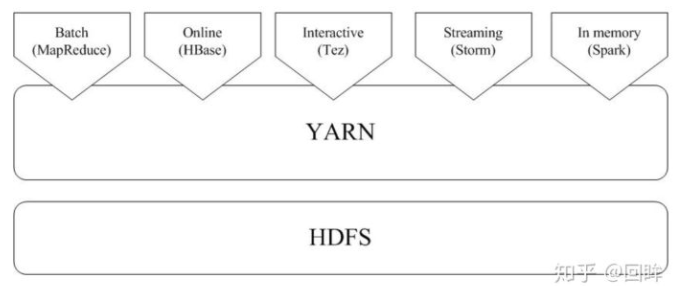
由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署(如图9-16所示)。这些不同的计算框架统一运行在YARN中,可以带来如下好处: