

MongoDB中如何优雅地删除大量数据
删除大量数据,无论是在哪种数据库中,都是一个普遍性的需求。除了正常的业务需求,我们需要通过这种方式来为数据库“瘦身”。
为什么要“瘦身”呢?
-
表的数据量到达一定量级后,数据量越大,表的查询性能会越差。
毕竟数据量越大,B+树的层级会越高,需要的IO也会越多。
-
表的数据有冷热之分,将很多无用或很少用到的数据存储在数据库中会消耗数据库的资源。
譬如会占用缓存;会增加备份集的大小,进而影响备份的恢复时间等。
所以,对于那些无用的数据,我们会定期删除。
对于那些很少用到的数据,则会定期归档。归档,一般是将数据写入到归档实例或抽取到大数据组件中。归档完毕后,会将对应的数据从原实例中删除。
一般来说,这种删除操作涉及的数据量都比较大。
对于这类删除操作,很多开发童鞋的实现就是一个简单的DELETE操作。看上去,简单明了,干净利落。
但是,这种方式,危害性却极大。
以 MySQL 为例:
-
会造成大事务
大事务会导致主从延迟,而主从延迟又会影响数据库的高可用切换。
-
回滚表空间会不断膨胀
在MySQL 8.0之前,回滚表空间默认是放到系统表空间中,而系统表空间一旦”膨胀“,就不会收缩。
-
锁定的记录多
相对而言,更容易导致锁等待。
即使是分布式数据库,如TiDB,如果一次删除了大量数据,这批数据在进行Compaction时有可能会触发流控。
所以,对于线上的大规模删除操作,建议分而治之。具体来说,就是批量删除,每次只删除一部分数据,分多次执行。
就如何删除大量数据,接下来我们看看MongoDB中的落地方案。
本文主要包括以下四部分内容。
- MongoDB中删除数据的三种方式。
- 三种方式的执行效率对比。
- 通过Write Concern规避主从延迟。
- 删除过程中碰到的Bug。
MongoDB中删除数据的三种方式
在MongoDB中删除数据,可通过以下三种方式:
-
db.collection.remove()
删除单个文档或满足条件的所有文档。
-
db.collection.deleteMany()
删除满足条件的所有文档。
-
db.collection.bulkWrite()
批量操作接口,可执行批量插入、更新、删除操作。
接下来,对比下这三种方式的执行效率。
三种方式的执行效率对比
环境:MongoDB 3.4.4,副本集。
测试思路:分别使用 remove、deleteMany、bulkWrite 删除 10w 条记录(每批删除 5000 条),交叉执行 5 次。
1. remove
// delete_date是删除条件
var delete_date = new Date("2021-01-01T00:00:00.000Z");
// 获取程序开始时间
var start_time = new Date();
// 获取满足删除条件的记录数
rows = db.test_collection.find({"createtime": {$lt: delete_date}}).count()
print("total rows:", rows);
// 定义每批需要删除的记录数
var batch_num = 5000;
while (rows > 0) {
// rows也可理解为剩余记录数
// 如果剩余记录数小于batch_num,则将剩余记录数赋值给batch_num
// 为什么要怎么做,后面会提到。
if (rows < batch_num) {
batch_num = rows;
}
// 获取满足删除条件的最小的5000个_id(ObjectID)
var cursor = db.test_collection.find({"createtime": {$lt: delete_date}}, {"_id": 1}).sort({"_id": 1}).limit(batch_num);
rows = rows - batch_num;
cursor.forEach(function (each_row) {
// 通过remove删除记录,这里指定了"justOne": true,每次只能删除一条记录。
// 为了避免误删除,这里同时指定了主键和删除条件。
db.test_collection.remove({'_id': each_row["_id"], "createtime": {'$lt': delete_date}}, {
"justOne": true,
w: "majority"
})
});
}
// 获取程序结束时间
var end_time = new Date();
// 两者的差值,即为程序执行时长
print((end_time - start_time) / 1000);
2. deleteMany
实例思路同remove类似,只不过会将待删除的_id放到一个数组中,最后再通过deleteMany一次性删除。
具体代码如下:
var delete_date = new Date("2021-01-01T00:00:00.000Z");
var start_time = new Date();
rows = db.test_collection.find({"createtime": {$lt: delete_date}}).count()
print("total rows:", rows);
var batch_num = 5000;
while (rows > 0) {
if (rows < batch_num) {
batch_num = rows;
}
var cursor = db.test_collection.find({"createtime": {$lt: delete_date}}, {"_id": 1}).sort({"_id": 1}).limit(batch_num);
rows = rows - batch_num;
var delete_ids = [];
// 将满足条件的主键值放入到数组中。
cursor.forEach(function (each_row) {
delete_ids.push(each_row["_id"]);
});
// 通过deleteMany一次删除5000条记录。
db.test_collection.deleteMany({
'_id': {"$in": delete_ids},
"createTime": {'$lt': delete_date}
},{w: "majority"})
}
var end_time = new Date();
print((end_time - start_time) / 1000);
3. bulkWrite
实现思路同deleteMany类似,也是将待删除的_id放到一个数组中,最后再调用bulkWrite进行删除。
具体代码如下:
var delete_date = new Date("2021-01-01T00:00:00.000Z");
var start_time = new Date();
rows = db.test_collection.find({"createtime": {$lt: delete_date}}).count()
print("total rows:", rows);
var batch_num = 5000;
while (rows > 0) {
if (rows < batch_num) {
batch_num = rows;
}
var cursor = db.test_collection.find({"createtime": {$lt: delete_date}}, {"_id": 1}).sort({"_id": 1}).limit(batch_num);
rows = rows - batch_num;
var delete_ids = [];
cursor.forEach(function (each_row) {
delete_ids.push(each_row["_id"]);
});
db.test_collection.bulkWrite(
[
{
deleteMany: {
"filter": {
'_id': {"$in": delete_ids},
"createTime": {'$lt': delete_date}
}
}
}
],
{ordered: false},
{writeConcern: {w: "majority", wtimeout: 100}}
)
}
var end_time = new Date();
print((end_time - start_time) / 1000);
接下来,看看三者的执行效率。
| 删除方式 | 平均执行时间(s) | 第一次 | 第二次 | 第三次 | 第四次 | 第五次 |
|---|---|---|---|---|---|---|
| remove | 47.341 | 49.606 | 48.487 | 49.314 | 47.572 | 41.727 |
| deleteMany | 16.951 | 16.566 | 18.669 | 17.932 | 18.66 | 12.928 |
| bulkWrite | 16.476 | 17.247 | 14.181 | 16.151 | 18.403 | 16.397 |
结合表中的数据,可以看出,
- 执行最慢的是remove,执行最快的是bulkWrite,前者差不多是后者的 2.79 倍。
- deleteMany 和 bulkWrite 的执行效率差不多,但就语法而言,前者比后者简洁。
所以线上如果要删除大量数据,推荐使用 deleteMany + ObjectID 进行批量删除。
通过 Write Concern 规避主从延迟
虽然是批量删除,但在MySQL中,如果没控制好节奏,还是很容易导致主从延迟。在MongoDB中,其实也有类似的担忧,不过我们可以通过 Write Concern 进行规避。
Write Concern,可理解为写安全策略,简单来说,它定义了一个写操作,需要在几个节点上应用(Apply)完,才会给客户端反馈。
看下面这个原理图。
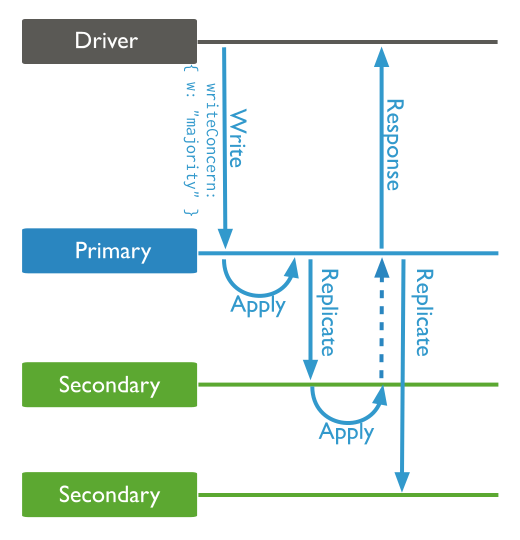
图中是一个一主两从的副本集,设置了w: "majority",代表一个写操作,需要等待副本集中绝大多数节点(本例中是两个)应用完,才能给客户端反馈。
在前面的代码中,无论是remove,deleteMany还是bulkWrite方法,都设置了w: "majority"。
之所以这样设置,一方面是为了保证数据的安全性,毕竟删除操作能在多个节点落盘,另一方面,还能有效降低批量操作可能导致的主从延迟风险。
Write Concern的完整语法如下,
{ w: <value>, j: <boolean>, wtimeout: <number> }
其中,
w:指定节点数或tags。其有如下取值:
-
<number>:显式指定节点数量。
设置为0,无需Server端反馈。
设置为1,只需Primary节点反馈。
设置为2,在副本集中,需要一个Primary节点(Primary节点必需)和一个Secondary节点反馈。
需要注意的是,这里的Secondary节点必须是数据节点,可以是隐藏节点、延迟节点或Priority为 0 的节点,但仲裁节点(Arbiter)绝对不行。
一般来说,设置的节点数越多,数据越安全,写入的效率也会越低。
-
majority:副本集大多数节点。
与上面不一样的是,这里的Secondary节点不仅要求是数据节点,它的votes(members[n].votes)还必须大于0。
-
<custom write concern name>:指定tags。
tag,顾名思义,是给节点打标签。常用于多数据中心部署场景。
如一个集群,有5个节点,跨机房部署。其中3个节点在A机房,另外2个节点在B机房,因为对数据的安全性、一致性要求很高,我们希望写操作至少能在A机房的2个节点落盘,B机房的1个节点落盘。
对于这种个性化的需求,只有通过tags才能实现。
j:是否需要等待对应操作的日志持久化到磁盘中。
在MongoDB中,一个写操作会涉及到三个动作:更新数据,更新索引,写入oplog,这三个动作要么全部成功,要么全部失败,这也是MongoDB单行事务的由来。
对于每个写操作,WiredTiger都会记录一条日志到 journal 中。
日志在写入journal之前,会首先写入到 journal buffer(最大128KB)中。
Journal buffer会在以下场景持久化到 journal 文件中:
-
副本集中,当有操作等待oplog时。
这类操作包括:针对oplog最新位置点的扫描查询;Causally consistent session中的读操作;对于Secondary节点,每次批量应用oplog后。
-
Write Concern 设置了 j: true。
-
每100ms。
由 storage.journal.commitIntervalMs 参数指定。
-
创建新的 journal 文件时。
当 journal 文件的大小达到100MB时会自动创建一个新的journal 文件。
wtimeout:超时时长,单位ms。
不设置或设置为0,命令在执行的过程中,如果遇到了锁等待或节点数不满足要求,会一直阻塞。
如果设置了时间,命令在这个时间内没有执行成功,则会超时报错,具体报错信息如下:
rs:PRIMARY> db.test.insert({"a": 1}, {writeConcern: {w: "majority", wtimeout: 100}})
WriteResult({
"nInserted": 1,
"writeConcernError": {
"code": 64,
"codeName": "WriteConcernFailed",
"errInfo": {
"wtimeout": true
},
"errmsg": "waiting for replication timed out"
}
})
删除过程中遇到的Bug
其实,最开始的删除程序是下面这个版本。
var delete_date = new Date("2021-01-01T00:00:00.000Z");
var start_time = new Date();
var batch_num = 5000;
while (1 == 1) {
var cursor = db.test_collection.find({"createtime": {$lt: delete_date}}, {"_id": 1}).sort({"_id": 1}).limit(batch_num);
delete_ids = []
cursor.forEach(function (each_row) {
delete_ids.push(each_row["_id"])
});
if (delete_ids.length == 0) {
break;
}
db.test_collection.deleteMany({
'_id': {"$in": delete_ids},
"createtime": {'$lt': delete_date}
}, {w: "majority"})
}
var end_time = new Date();
print((end_time - start_time) / 1000);
相对于效率对比章节的版本,这个版本的代码简洁不少。
- 不用额外获取需要删除的记录数。
- batch_num在整个执行过程中也是不变的。
但用这个版本在线上删除数据时,发现了一个问题。
在删除到最后一批时,程序会hang在那里。重试了多次依然如此。分析如下:
-
最后一批的文档数小于batch_num时,会出现这个问题。
删除同实例下另外一个集合,也出现了类似的问题。
但在测试环境,删除一个简单的集合却没有复现出来,怀疑这个Bug与线上集合的记录过长有关。
-
cursor只是一个迭代对象,并不是查询结果。基于cursor可以分批返回记录,类似于Python中的迭代器。
最后一批也不是完全没有返回,而是在返回100条之后才hang在那里。
-
不使用sort没有这个问题。
为什么要使用sort呢?这样可保证得到的id是有序且在物理上的存储是相邻的。这样,在执行批量删除操作时,效率也会相对较高。
经过实际测试,当要删除的数据量较大时,使用sort的效率确实比不使用的要高。
如果删除的数据量较小,使不使用sort则没多大区别。
总结
从最佳实践的角度出发,无论是在哪种数据库中,如果都删除(更新)大量数据,都建议分而治之,分批执行。
在MongoDB中,如果要删除大量数据,推荐使用deleteMany + ObjectID进行批量删除。
为了保证操作的安全性及规避批量操作带来的主从延迟风险,建议在执行删除操作时,将Write Concern设置为w: "majority"。
参考
[1] Journaling
[2] Write Concern

