
20199109 2019-2020-2 《网络攻防实践》期末综合实践大作业
我选择的论文是RAZZER: Finding Kernel Race Bugs Through Fuzzing
我将从论文综述、设计细节、论文复现、思考与感悟四个部分来介绍。
一 论文综述
1、文章简介
本文发表在IEEE Symposium on Security and Privacy 2019。作者是Dae R. Jeong, Kyungtae Kim, Basavesh Shivakumar, Byoungyoung Lee, Insik Shin。发表单位为KAIST, Purdue University, Seoul National University。
2、摘要
内核中的数据竞争可能导致许多有害行为,严重影响了相关系统的可靠性和安全性。比如造成内核无响应,或更严重的是,攻击者可能触发权限提升攻击以获取root权限。
因此作者设计并提出了针对内核中的数据竞争类型漏洞的模糊测试(fuzzing)工具RAZZER。一般的模糊测试是通过输入畸形数据来触发目标程序的崩溃进而再通过手动分析确定是否存在安全问题的,但是这种方式不仅很难对竞争漏洞进行针对性测试,而且很难发现由于竞争漏洞而导致的潜在安全问题。与传统方案的不同,RAZZER的核心思想是引导Fuzzing工具去执行可能存在数据竞争漏洞的代码。这包含了两种技术,一是通过静态分析来对潜在的内核数据竞争点进行定位,从而引导Fuzzer更有效地在内核中搜索数据竞争。二是一种确定性的线程交错技术,用来控制线程调度,以提供精确的并行执行信息,降低不确定性,从而保证内核竞争的稳定触发。本工作并没有去解决同步机制对多线程fuzzing的影响。
作者针对Linux内核实现了RAZZER的原型,并使用RAZZER运行了最新的Linux内核(从v4.16-rc3到v4.18-rc3)。发现了30个新的内核的数据竞争漏洞,其中16个已经被确认。根据RAZZER生成的漏洞报告,有14个已经被修补。
3、论文核心
本文的目标就是挖掘竞争漏洞,核心思想也就是引导Fuzzing工具去执行可能存在数据竞争漏洞的代码。
本文提出的RAZZER的关键在于,它将模糊测试推向内核中潜在的数据竞争点。为了实现这一目标,RAZZER采用了混合方法,同时利用了静态和动态分析,以扩大两种技术的优势,同时弥补其劣势。首先,RAZZER进行静态分析以获得潜在的数据竞争点。基于这些数据竞争点的信息,RAZZER执行两阶段的动态模糊测试。第一阶段涉及单线程模糊测试,该测试着重于查找执行潜在竞争点的单线程输入程序(不考虑程序是否确实触发了竞争)。第二阶段是多线程模糊测试。它构造了一个多线程程序,该程序进一步利用了定制的hypervisor,以在潜在的数据竞争点执行。这样,RAZZER避免了任何外部因素来使竞争行为具有确定性,从而使其成为数据竞争的有效模糊器。
本文通过LLVM传递来实现RAZZER的静态分析,以进行points-to分析,并且通过针对x86-64,修改QEMU和KVM开发了hypervisor。开发了相应的两阶段模糊测试框架,以对内核的系统调用接口进行模糊测试,同时利用静态分析结果以及量身定制的管理程序。一旦RAZZER识别出数据竞争,它不仅输出用于重现竞争的输入程序,而且还提供详细的报告,使我们了解竞争的根本原因。
我们对RAZZER的评估表明,RAZZER确实是一种随时可以部署的竞争检测工具。
二、设计细节
1、数据竞争
定义:如果目标程序内两条内存访问的指令,满足以下3个条件,就是数据竞争。
(1)访问的内存地址相同;
(2)至少其中一条指令是对内存的写指令;
(3)两条指令可以并发执行。
数据竞争对底层系统的可靠性和安全性会造成影响。尤其是对于内核,数据竞争是各种有害行为的根本原因。
1.如果数据竞争引入了循环锁定行为,则由于导致的死锁,造成内核无响应。
2.如果出现在内核中的安全性断言,内核将自行重启,从而导致拒绝服务。
3.数据竞争还可能会导致严重的安全攻击,若数据竞争导致内核中的传统内存损坏(比如缓冲区溢出、UAF等),进而导致权限提升攻击。例如CVE-2016-8655,CVE-2017-2636和CVE-2017-17712。
举个例子来说明数据竞争是怎么发生的:CVE-2017-2636。
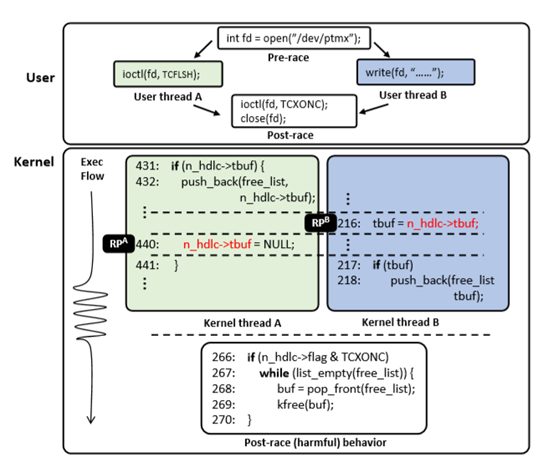
我们从上图可以看到,该程序本应以特定顺序调用特定的系统调用列表,但因为对抗性多线程用户程序引起数据竞争,从而在内核处理此类系统调用,导致了双重释放double-free问题。
两个线程分别调用ioctl(fd,TCFLSH)和write(fd,”......”),对变量n_hdlc->tbuf的并发读写导致竞争n_hdlc->tbuf = NULL与tbuf = n_hdlc->tbuf。n_hdlc->tbuf是一个指针,〖RP〗^A的432行被push到free_list(之后会被free),在440行处置零,〖RP〗^B的216行将tbuf取出,并在后面也将其push进free_list,可以看到,如果出现图中的执行顺序,就会导致Double-free的产生,从而允许攻击者启动权限提升攻击。
2、静态分析
静态分析的目标是发现内核中所有的〖RacePair〗_cand(候选竞争对),每个〖RacePair〗_cand由两条内存访问指令组成。通常来说,用Points-to分析会是一个比较好的选择,然而Points-to在准确性和性能上都有缺陷。在准确性上,Points-to有很高的假阳性概率。性能上,时间复杂度是O(n^3),n代表被分析程序的大小,会用很长的时间去分析整个内核。
RAZZER用两个方法解决了这些问题:在准确性上,RAZZER遵循了Points-to的方法,它允许points-to分析十分逼近〖RacePair〗_cand集,对于假阳性的结果,通过后面的动态分析过滤。在性能上,RAZZER将内核根据模块进行分区分析,并对每个模块进行预分析。并且在对每个模块执行预分析时,RAZZER也始终提供核心内核模块。
3、hypervisor
RAZZER的经过修改的hypervisor为guest内核提供了以下功能:
(1)为每个虚拟CPU核心设置断点
(2)恢复执行内核线程
(3)检测竞争结果

hypervisor执行恢复的工作流程如上图所示。首先,假设两个内核线程在其各自的断点(即1和2)处停止,并且已调用hcall_set_order()。 为了恢复,RAZZER选择hcall_set_order()指定的vCPU(即vCPU0),并对该vCPU执行单步操作以在执行一条指令(3)之后立即停止。 按照hcall_set_order()的命令,此单步操作可确保vCPU0在vCPU1之前运行。 最后,RAZZER恢复vCPU0和vCPU1(4)的执行。
4、两阶段模糊测试
RAZZER的模糊测试分为两个阶段进行
首先是单线程模糊测试阶段,找到触发任何〖RacePair〗_cand的单线程用户程序;之后进入多线程模糊测试阶段,最终找到一个基于单线程阶段的结果触发有害竞争的多线程用户程序。每个模糊阶段均由生成器和执行器两个部分组成,生成器创建用户程序,然后执行器运行该程序。
下图是RAZZER的整体结构

三、论文复现
1、实验环境
基于Intel(R) Xeon(R) CPU E5-4655 v4 @ 2.50GHz (30MB缓存) ,512GB内存 - Ubuntu 16.04 / Linux 4.15.12 64-bit
首先配置实验环境
通过source scripts/envsetup.sh设置必要的环境变量。这里我选择内核版本v4.17

因为该项目中使用的内核源代码在另一个子目录中,作为子模块包含在其中。 要初始化子模块,应执行以下命令git submodule update --init --depth=1 kernels_repo。
接下来还要进行一系列的安装
sudo apt install zlib libglib-dev python-setuptools quilt libssl-dev dwarfdump
最后scripts/install.sh安装其他必要的工具
2、静态分析
基于LLVM4.0.0和SVF。points-to分析:处理内核内存分配/释放;处理堆/全局结构中的非指针变量。输出:〖RacePair〗_cand(含源文件名+行号),编译利用GCC的调试信息将之转化为二进制地址。
3、hypervisor
基于QEMU 2.5.0和KVM(基于内核的虚拟机)硬件加速;Capstone反汇编来检查〖RacePair〗_cand指令;RAZZER基于Google开发的内核模糊器Syzkaller实现。
4、实验结果
文章的原作者测试的Linux内核,版本包括了从v4.16-rc3到v4.18-rc3,总共跑了大约7个星期。下图是作者最终发现的漏洞,总共发现了30个恶性的数据竞争,在报告后,其中16个已经被确认,这里面的14个已经提交了补丁。
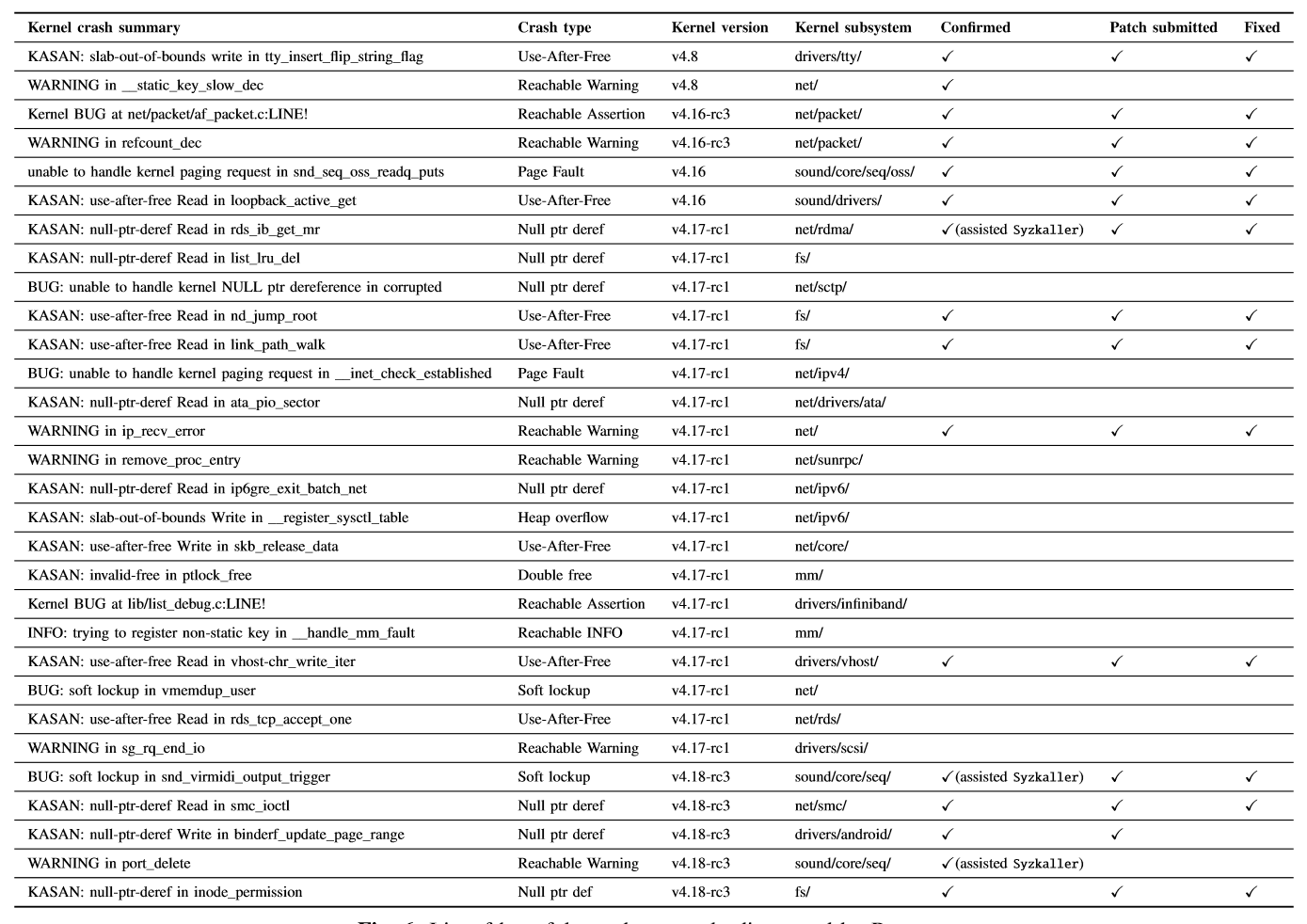
这其中有一些漏洞是在内核里存在了很久的古老漏洞,例如refcount_dec是从Linux v2.6.20(2007年)引入的漏洞,以及写入 tty_insert_flip_string_fixed_flag 的KASAN: slab-out-of-bounds在2011年以来就存在(Linux v2.6.38)。
效率对比
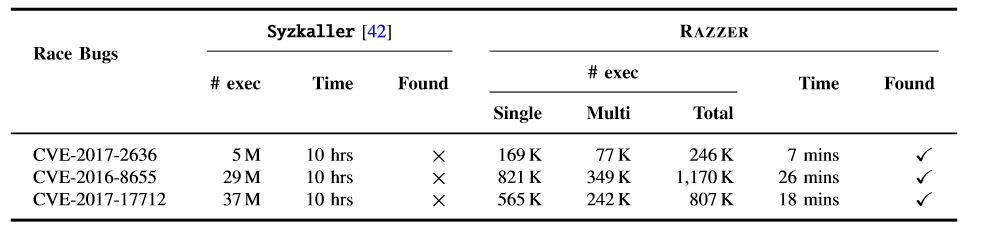
与Syzkaller在发现错误所需的时间上作比较。我们对RAZZER和Syzkaller使用了相同的配置,结果下图所示,RAZZER在合理的时间内(即从7分钟到26分钟)找到了所有先前已知的竞争,并在合理的执行次数(即246K到1,170K)中进行了执行。但是,Syzkaller在10h内未能找到所有这些情况,说明RAZZER在发现恶性数据竞争的速度比Syzkaller快得多(至少23-86倍)。
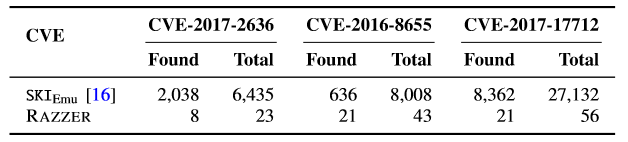
与SKI进行对比,由于SKI的源码没办法获得,作者通过使用SKI的随机线程交织功能扩展RAZZER来实现SKIEmu。实现SKIEmu的关键在于实现其随机线程交错功能,这是通过修改RAZZER的多线程模糊测试阶段来完成的。实验结果如下图,RAZZER的效率比SKI高很多,因为RAZZER的搜索空间比较小,只测试与〖RacePair〗_cand有关的线程交织,所以所需执行次数就少得多,范围从30倍到398倍,而SKI很多做的是无用功。
四、思考与感悟
网络攻防这门课不得不说是本学期最让人头疼的一门课,每周需要用大量的时间去学习。在学习的时候最大的感受就是要学的东西好多好杂,根本记不住,很难形成一个体系,在脑子里没有一个非常清晰的脉络。看实践要求的时候也感觉一头雾水,需要参考同学的博客才能完成。刚开始的时候我觉得跟着同学的博客边做边学就好了,后来老师说要自己思考再去做实践,所以我之后也有在努力思考、查资料,能自己完成的部分就自己做,经过不断努力得到的成果真的让人很有成就感,并且想要一直不断地去做。但是有时的内容可能稍难一些,在电脑前捣鼓一整天也毫无进展,就让人有点失落,毕竟每次实践只有几天的时间去完成,第二天可能就会去参考别人的博客,但是也不是像刚开始的时候一样,像个躯壳一样去跟着实践,在实践时受到启发之后会在此基础上自己继续去完成实践。我觉得我的性格属于比较急躁的,很多时候缺乏耐心,心态容易崩溃。但是这学期一直独自在家学习,不得不说锻炼了我的性子,因为所有事情都需要你自己一步一步去完成,遇到bug也要不断百度去尝试去解决,着急也没用。在此过程中我发现,不断失败最后获得的成功有时比一次就成功要更开心,所以现在不会像以前一样惧怕失败。有时一门课到最后学到多少知识也许并不是最重要的,疫情期间的居家学习确实锻炼了我。
总的来说,这一学期的学习掌握了很多攻防的基础知识还有动手实践的技能,最重要的是锻炼了耐心和毅力,这在以后不管是科研还是工作过程中我相信都是很有帮助的。

