
SQL common keywords examples and tricks
Case Sensitive Check
1. Return names contain upper case
Select id, name from A where name<>lower(name) collate SQL_Latin1_General_CP1_CS_AS
2. Return same name but diff case
Select id, A.name, B.name from A inner join B on A.name=B.name where A.name<>B.name collate SQL_Latin1_General_CP1_CS_AS
Case when
https://blog.csdn.net/evilcry2012/article/details/52148641
****return result need to be same, i.e. either all varchar or all int or all decimal
1. Calculate sum of different group
国家(country) 人口(population)
中国 600
美国 100
加拿大 100
英国 200
法国 300
日本 250
德国 200
墨西哥 50
印度 250
Result:
洲 人口
亚洲 1100
北美洲 250
其他 700
SELECT SUM(population), CASE country WHEN '中国' THEN '亚洲' WHEN '印度' THEN '亚洲' WHEN '日本' THEN '亚洲' WHEN '美国' THEN '北美洲' WHEN '加拿大' THEN '北美洲' WHEN '墨西哥' THEN '北美洲' ELSE '其他' END FROM Table_A GROUP BY CASE country WHEN '中国' THEN '亚洲' WHEN '印度' THEN '亚洲' WHEN '日本' THEN '亚洲' WHEN '美国' THEN '北美洲' WHEN '加拿大' THEN '北美洲' WHEN '墨西哥' THEN '北美洲' ELSE '其他' END;
2. Calculate total amount of different pay level
SELECT CASE WHEN salary <= 500 THEN '1' WHEN salary > 500 AND salary <= 600 THEN '2' WHEN salary > 600 AND salary <= 800 THEN '3' WHEN salary > 800 AND salary <= 1000 THEN '4' ELSE NULL END salary_class, COUNT(*) FROM Table_A GROUP BY CASE WHEN salary <= 500 THEN '1' WHEN salary > 500 AND salary <= 600 THEN '2' WHEN salary > 600 AND salary <= 800 THEN '3' WHEN salary > 800 AND salary <= 1000 THEN '4' ELSE NULL END;
3. Calculate sum of different group with multiple columns
国家(country) 性别(sex) 人口(population)
中国 1 340
中国 2 260
美国 1 45
美国 2 55
加拿大 1 51
加拿大 2 49
英国 1 40
英国 2 60
Result:
国家 男 女
中国 340 260
美国 45 55
加拿大 51 49
英国 40 60
SELECT country, SUM( CASE WHEN sex = '1' THEN population ELSE 0 END), --male population SUM( CASE WHEN sex = '2' THEN population ELSE 0 END) --female population FROM Table_A GROUP BY country;
Cast & Convert (change data type)
1. Cast is compatible to both sql server and mysql, convert is designed for sql server, and it can have more styles and specially useful for datetime (check datetime part)
select cast(1.73 as int) --return 1 select cast(1.73 as decimal(4,0)) --return 2 --keep 2 decimal, this will round to nearest 2 decimal select cast(1.234 as decimal(10,2)) --return 1.23 select cast(1.236 as decimal(10,2)) --return 1.24 --cast to varchar to display decimal if it is all 0 select cast(1.14 as decimal(10,1)) --if display show 1.1 select cast(1.04 as decimal(10,1)) --if display show 1 select cast(cast(1.04 as decimal(10,1)) as varchar(10)) --if display show 1.0
****cast to varchar, if the string is long than 20, use varchar(100) or varchar(max)
2. Automatic type change when using declare
declare @zz1 decimal(5,4)=2.0 if @zz1=2 select @zz1 --output: 2.0000 so decimal can compare to int declare @zz1 decimal(5,4)=2 if @zz1=2.0 select @zz1 --output: 2.0000 so declare will correct the data type from int to decimal declare @zz2 int=1.0 if @zz2=1.0 select @zz2 --output: 1 so declare will correct the data type from decimal to int --and int can compare to decimal declare @zz3 varchar(100)='2.0' if @zz3=2.0 select @zz3 --output: 2.0, correct way to declare a decimal varchar declare @zz3 varchar(100)='2.0' if @zz3=2 select @zz3 --output: Conversion failed when converting the varchar value '2.0' to data type int. --so if you declare a decimal varchar, it can not be compared with int declare @zz3 varchar=2.0 --wrong declare, this will cause an error: --output: Arithmetic overflow error converting numeric to data type varchar declare @zz4 varchar=4 if @zz4=4.0 select @zz4 --output: 4, if assign a int to varchar, can declare without quote, this equal to declare with int keyword declare @zz5 varchar(100)='4' if @zz5=4.0 select @zz5 --output: 4, this is equal to last one, declare with quote for integer
Constraints (6 basic)
1. SQL NOT NULL
CREATE TABLE ConstraintDemo1 ( ID INT NOT NULL, Name VARCHAR(50) NULL )
In SSMS, leave it unselected
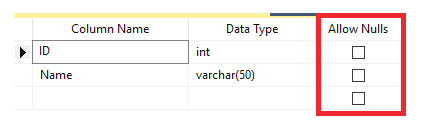
2. UNIQUE
a. Unique can be null, and unique check will not check null values (means you can have multiple nulls)
b. You can have multiple unique constrains for one table but only one primary key
c. Example: phone number, which is unique, but some pp may not leave phone number
CREATE TABLE ConstraintDemo2 ( ID INT UNIQUE, Name VARCHAR(50) NULL )
In SSMS, right click->indexes/keys
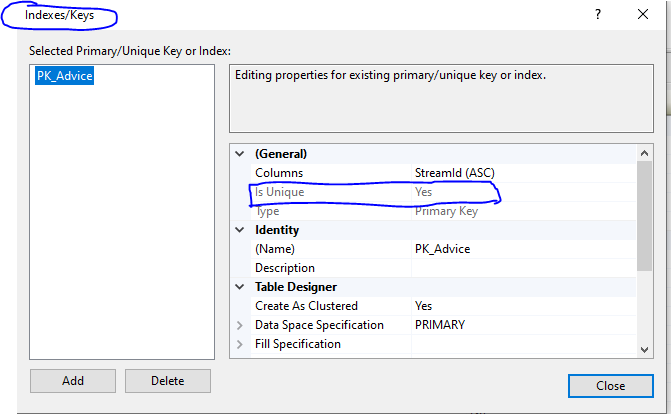
3. PRIMARY KEY (Unique + Not NULL + indexable)
CREATE TABLE ConstraintDemo3 ( ID INT PRIMARY KEY, Name VARCHAR(50) NULL )
In SSMS, right click -> set primary key
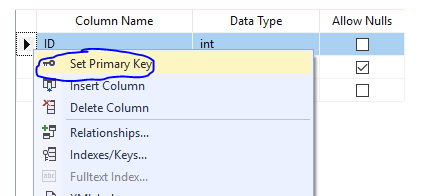
4. FOREIGN KEY
https://www.liaoxuefeng.com/wiki/1177760294764384/1218728424164736
ALTER TABLE courses --main table ADD CONSTRAINT fk_courses_teachers --foreign key name = fk_mainTable_referenceTable FOREIGN KEY (class_id) --col in main table (foreign key) REFERENCES classes (id); -- table(col) of source table for reference, primary key
In SSMS, right click -> relationships -> add
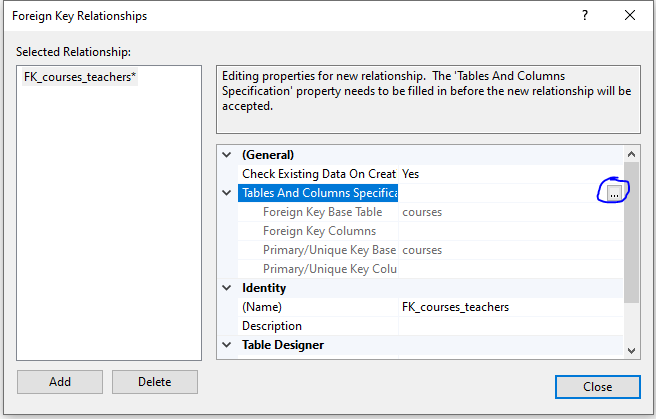
Primary key table is the reference, foreign key table is the main table

a. A foreign key connect main table col and reference table col, to not allow insert rows has invalid col value to main table as per reference table col
b. You can only have col value for main table which exist in reference, but you may have col value in reference which not exists in main table
c. Foreign Key will decrease db performance, in reality companies rely on the logic in code instead of foreign key
d. Why not merge 2 tables? Because divide table into independant ones can separate the popular ones and less popular ones and increase speed by not reading less popular ones all the time
5. CHECK (conditions on value of col when insert)
CREATE TABLE Persons ( ID int NOT NULL, Age int CHECK (Age>=18) );
CREATE TABLE Persons ( ID int NOT NULL, Age int, City varchar(255), CONSTRAINT CONS_Name CHECK (Age>=18 AND City='Sandnes') );
In SSMS, right click -> check constrains -> add -> edit expression
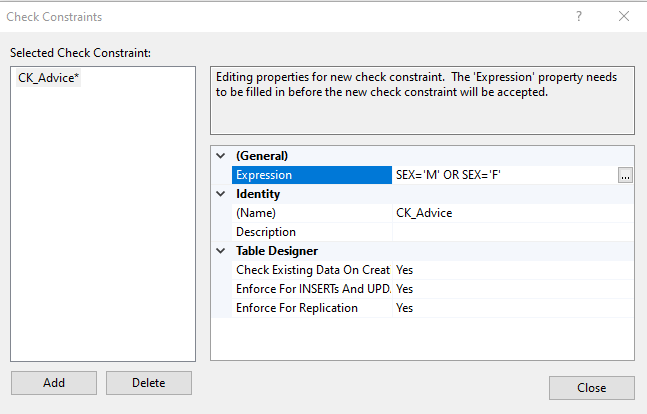
6. DEFAULT (default value of a col on insert if not given)
CREATE TABLE Orders ( ID int NOT NULL, OrderNumber int NOT NULL, OrderDate date DEFAULT GETDATE() );
In SSMS, in column properties ->use (value), value can be string, number or function()

Create a column of numbers (usually ids)
DECLARE @startnum INT=1000 --start DECLARE @endnum INT=1020 --end ; WITH gen AS ( SELECT @startnum AS num UNION ALL --change number+ i to adjust gap i SELECT num+3 FROM gen WHERE num+1<=@endnum ) SELECT * FROM gen option (maxrecursion 10000)
num
1000
1003
1006
1009
1012
1015
1018
1021
Create a column of strings from one long string
;WITH Split(stpos,endpos) AS( SELECT 0 AS stpos, CHARINDEX(',','Alice,Jack,Tom') AS endpos UNION ALL SELECT endpos+1, CHARINDEX(',','Alice,Jack,Tom',endpos+1) FROM Split WHERE endpos > 0 ) --LTRIM RTRIM to get rid of white space before start or after end of str SELECT RTRIM(LTRIM(SUBSTRING('Alice,Jack,Tom',stpos,COALESCE(NULLIF(endpos,0),LEN('Alice,Jack,Tom')+1)-stpos))) as name into #temp FROM Split
name
Alice
Jack
Tom
Create a single table has columns of strings
SELECT * into #temp FROM (VALUES (1,'Alice'),(2,'Jack'),(3,'Tom')) AS t(id,name)
id name
1 Alice
2 Jack
3 Tom
Create a temp table (copy a table)
1. From a existing table, no need create table (not copy indexing or primary key)
Select id, name, 'placeholder' as sex into #temp from A
Trick to copy a table structure(cols and datatype) but not content
--0=1 to not copy any rows Select id, name into #temp from A where 0=1 --the above query equals to select id, name into #temp from #temp1 delete from #temp1
2. Create temp table (lifespan: current session, drop on close tab)
create table #tmpStudent(Id int IDENTITY(1,1) PRIMARY KEY,Name varchar(50),Age int) insert into #tmpStudent select id,name,age from #tmpStudent
3. Global temp table (##temp, can visit from other tab, drop on close tab where it is created)
4. Using table variable (lifespan: current transaction, drop after running query block)
DECLARE @temp Table ( Id int, Name varchar(20), Age int )
Cursor (only use if you need action diff on each row)
1. A general nested loop to go forward one by one
DECLARE @Class int, @Score int; DECLARE cursor_product CURSOR LOCAL FAST_FORWARD READ_ONLY --fastest config FOR SELECT class, score FROM #Student; OPEN cursor_product; FETCH NEXT FROM cursor_product INTO @Class,@Score; --must have! WHILE @@FETCH_STATUS = 0 BEGIN PRINT 'Class: '+ CAST(@Class AS varchar)+' Score: '+ CAST(@Score AS varchar); FETCH NEXT FROM cursor_product INTO @Class, @Score; END; CLOSE cursor_product; DEALLOCATE cursor_product;
2. User scroll feature to select any line of returning set
select * from #student DECLARE @Class int, @Score int; DECLARE cursor_product CURSOR scroll FOR SELECT class, score FROM #Student; OPEN cursor_product; FETCH next FROM cursor_product INTO @Class,@Score; --next position of current PRINT 'Class: '+ CAST(@Class AS varchar)+' Score: '+ CAST(@Score AS varchar); FETCH first FROM cursor_product INTO @Class,@Score; --very first one PRINT 'Class: '+ CAST(@Class AS varchar)+' Score: '+ CAST(@Score AS varchar); FETCH last FROM cursor_product INTO @Class,@Score; -- very last one PRINT 'Class: '+ CAST(@Class AS varchar)+' Score: '+ CAST(@Score AS varchar); FETCH prior FROM cursor_product INTO @Class,@Score; --current pos -1 PRINT 'Class: '+ CAST(@Class AS varchar)+' Score: '+ CAST(@Score AS varchar); FETCH relative -5 FROM cursor_product INTO @Class,@Score; -- current pos -5 PRINT 'Class: '+ CAST(@Class AS varchar)+' Score: '+ CAST(@Score AS varchar); FETCH absolute 6 FROM cursor_product INTO @Class,@Score; --the 6th of all PRINT 'Class: '+ CAST(@Class AS varchar)+' Score: '+ CAST(@Score AS varchar); CLOSE cursor_product; DEALLOCATE cursor_product;
Datetime
1. Current date/datetime/UTC date, convert datetime to date only
select GETDATE() select GETUTCDATE() select cast(GETDATE() as date) --date only SELECT convert(date, GETDATE() ) --date only
2. Tomorrow/yesterday, next/last hour (simple nearby datetime)
-- add or minus is on day basis select GETDATE()+1 --tomorrow select GETDATE()-1 --yesterday -- need to be 24.0 to return float select GETDATE()+1.0/24 --next hour select GETDATE()-1.0/24/2 --Last 30 min
3. Add/minus any period for a date (use with 4.datediff)
--result is already datetime select DATEADD(yy,-2,'07/23/2009 13:23:44') --2 years ago select DATEADD(mm,5, DATEADD(dd,10,GETDATE())) --5 month and 10 days later
The datepart can be 'year' or 'yy' or 'yyyy', all same

4. Datediff of 2 datetime ( =2nd-1st, result is + or - interger)
select DATEDIFF(mi,GETDATE()+1.0/24, GETDATE()-1.0/24) -- return -120 select DATEDIFF(dd,'2019-11-23', '2019-12-23') --return 30
5. Generate any datetime
select cast('2019-10-23 23:30:59:883' as datetime) --'yyyy-mm-dd' select cast('2019/10/23 23:30:59:883' as datetime) --'yyyy/mm/dd' use ':' for ms select cast('10-23-2019 23:30:59.883' as datetime) --'mm-dd-yyyy' use '.' for ms select cast('10/23/2019 23:30:59.883' as datetime) --'mm/dd/yyyy' --same to use convert SELECT convert(date, '07/23/2009' )
6. Get day/week/month/year part of a datetime
--these pairs are same to get dd,mm,yy part of a datetime, return integer select Datepart(dd,GETDATE()),day(GETDATE()) select Datepart(mm,GETDATE()),month(GETDATE()) select Datepart(yyyy,GETDATE()),year(GETDATE()) select Datepart(dy,'2019-08-11') --get day of year: 223 select datename(mm,'2000-5-17') --return 'May' select datename(weekday,'2000-5-17') --return 'Wednesday'
7. Convert datetime format (input need to be datetime only, result is a string)
-- not working!!!! return '2019-05-17', as it detect input is string, 103 is ignored select convert(varchar, '2019-05-17', 103) --input is datetime, reutrn formatted string '17/05/2019' select convert(varchar, cast('2019-05-17' as datetime), 103)
for a full list of datetime format code (smilar to 103)
| DATE ONLY FORMATS | ||
| Format # | Query | Sample |
|---|---|---|
| 1 | select convert(varchar, getdate(), 1) | 12/30/06 |
| 2 | select convert(varchar, getdate(), 2) | 06.12.30 |
| 3 | select convert(varchar, getdate(), 3) | 30/12/06 |
| 4 | select convert(varchar, getdate(), 4) | 30.12.06 |
| 5 | select convert(varchar, getdate(), 5) | 30-12-06 |
| 6 | select convert(varchar, getdate(), 6) | 30 Dec 06 |
| 7 | select convert(varchar, getdate(), 7) | Dec 30, 06 |
| 10 | select convert(varchar, getdate(), 10) | 12-30-06 |
| 11 | select convert(varchar, getdate(), 11) | 06/12/30 |
| 12 | select convert(varchar, getdate(), 12) | 061230 |
| 23 | select convert(varchar, getdate(), 23) | 2006-12-30 |
| 101 | select convert(varchar, getdate(), 101) | 12/30/2006 |
| 102 | select convert(varchar, getdate(), 102) | 2006.12.30 |
| 103 | select convert(varchar, getdate(), 103) | 30/12/2006 |
| 104 | select convert(varchar, getdate(), 104) | 30.12.2006 |
| 105 | select convert(varchar, getdate(), 105) | 30-12-2006 |
| 106 | select convert(varchar, getdate(), 106) | 30 Dec 2006 |
| 107 | select convert(varchar, getdate(), 107) | Dec 30, 2006 |
| 110 | select convert(varchar, getdate(), 110) | 12-30-2006 |
| 111 | select convert(varchar, getdate(), 111) | 2006/12/30 |
| 112 | select convert(varchar, getdate(), 112) | 20061230 |
| TIME ONLY FORMATS | ||
| 8 | select convert(varchar, getdate(), 8) | 00:38:54 |
| 14 | select convert(varchar, getdate(), 14) | 00:38:54:840 |
| 24 | select convert(varchar, getdate(), 24) | 00:38:54 |
| 108 | select convert(varchar, getdate(), 108) | 00:38:54 |
| 114 | select convert(varchar, getdate(), 114) | 00:38:54:840 |
| DATE & TIME FORMATS | ||
| 0 | select convert(varchar, getdate(), 0) | Dec 12 2006 12:38AM |
| 9 | select convert(varchar, getdate(), 9) | Dec 30 2006 12:38:54:840AM |
| 13 | select convert(varchar, getdate(), 13) | 30 Dec 2006 00:38:54:840AM |
| 20 | select convert(varchar, getdate(), 20) | 2006-12-30 00:38:54 |
| 21 | select convert(varchar, getdate(), 21) | 2006-12-30 00:38:54.840 |
| 22 | select convert(varchar, getdate(), 22) | 12/30/06 12:38:54 AM |
| 25 | select convert(varchar, getdate(), 25) | 2006-12-30 00:38:54.840 |
| 100 | select convert(varchar, getdate(), 100) | Dec 30 2006 12:38AM |
| 109 | select convert(varchar, getdate(), 109) | Dec 30 2006 12:38:54:840AM |
| 113 | select convert(varchar, getdate(), 113) | 30 Dec 2006 00:38:54:840 |
| 120 | select convert(varchar, getdate(), 120) | 2006-12-30 00:38:54 |
| 121 | select convert(varchar, getdate(), 121) | 2006-12-30 00:38:54.840 |
| 126 | select convert(varchar, getdate(), 126) | 2006-12-30T00:38:54.840 |
| 127 | select convert(varchar, getdate(), 127) | 2006-12-30T00:38:54.840 |
8. Calculate the current week number of the year, considering 1st Monday is 1st week
set datefirst 1 -- to set Monday as week start --to check if 2023-01-01 is Monday, if yes week number correct if not -1 select case when DATEPART(DW, cast(cast(datepart(YYYY,'2023-01-08') as varchar)+'-01-01' as date)) =1 then datename(WEEK,'2023-01-08') else datename(WEEK,'2023-01-08')-1 end
Delete duplicate rows (entire same or partialy same)
0. create example table
create table #Student (id int, Class int, Score int ) insert into #Student values(1,1,88) insert into #Student values(2,1,66) insert into #Student values(3,2,30) insert into #Student values(4,2,70) insert into #Student values(5,2,60) insert into #Student values(6,3,70) insert into #Student values(7,3,80)
1. Select duplicate rows based on 1 column
select * from students where id in ( select id FROM students group by id having count(*)>1 )
2. Select duplicate rows based on multiple columns
select * from students a right join ( select firstname, lastname from students group by firstname, lastname having count(*)>1 ) b on a.firstname=b.firstname and a.lastname=b.lastname
3. Select rows that has unique combination of colums(filter out all duplicate rows)
select * from students except( select a.* --need to select all columns here from students a right join ( select firstname, lastname from students group by firstname, lastname having count(*)>1 ) b on a.firstname=b.firstnameand a.lastname =b.lastname )
4. Select/delete rows of totally identical values
select distinct * from tableName --save the result equals to delete duplicated rows already
5. Delete duplicate rows in table which has unique id
delete from #temp where id not in( select max(id) from #temp group by col1, col2 --the columns used when checking duplicate having count(*)>1 )
6. Delete duplicate rows in table which does not have id
6.1 Delete directly from original table by "Partition" keyword
WITH tempVw AS ( SELECT *, ROW_NUMBER() OVER ( --over() is required for Row_Number() PARTITION BY --this reset the rowNumber to 1 for different group col1, col2 --which used as identifier to check duplicate ORDER BY --order by is required in Over() col1, col2 --keep same as above ) row_num FROM YourTable ) delete FROM tempVw WHERE row_num > 1 select * from YourTable --duplicated rows should be removed in original table
6.2 Add unique ID first so it is similar as point 5
--Use views to add rowId for table without unique id with tempVw as( select ROW_NUMBER() over (order by SurveyTypeid, surveyid ) as rowid,* from YourTable ) --define 2 views together, tempVw2 is all duplicated rows ,tempVw2 as ( select rowid,a.col1,a.col2 from tempVw a right join ( select col1, col2 from tempVw group by col1, col2 having count(*)>1 ) b on a.col1=b.col1 and a.col2=b.col2 ) --query after view, delete rows in view will delete original table delete from tempVw where rowid in ( --return all duplicated rows except 1 row for each group that we will keep select rowid from tempVw2 where rowid not in ( --return 1 row for each identifier of duplicated rows select min (rowid) from tempVw2 group by col1, col2 having count(*)>1 ) ) select * from YourTable --duplicated rows should be removed in original table
Dynamic SQL (EXEC)
1. Query without quote
declare @sql varchar(max)= 'select * from #StudentMarks' exec (@sql)
2. If there is any single quote inside query, double it
--the end has 3 quote because: double single quote + end quote of the query varchar declare @sql varchar(max)= 'select * from #StudentMarks where name=''Alice''' exec (@sql)
3. if you have single quote inside a string, you need doule it
-- output: 2019's, you need double the quote as it is in a string: 2019''s select *,'2019''s' as category from #StudentMarks where name='Alice' declare @sql varchar(max)= 'select *,''2019''''s'' as category from #StudentMarks where name=''Alice''' exec (@sql)
4. If you add a number var to a dynamic query, you need to cast to varchar, no need for extra quote
declare @Math int=90 declare @sql varchar(max)= 'select * from #StudentMarks where Math='+cast(@Math as varchar)+' and Science=40' exec (@sql)
5. If you add a string var to a dynamic query, you need quote the input, and double the quote
declare @Name varchar(max)='Alice' --first 3 quotes = double the left quote of @Name + end quote of 1st part of query -- 4 quotes = start quote of 3rd part+ double the right quote of @Name + end quote of 3rd part declare @sql varchar(max)= 'select * from #StudentMarks where name='''+@Name+'''' exec (@sql)
6. Connect multiple query string together
--double the left and right quote around Alice inside the query declare @sql2 varchar(max)=' where name = ''Alice'' ' --do not forget to leave a space after each query declare @sql varchar(max)= 'select * from #StudentMarks '+ @sql2 exec (@sql)
Except (check difference between 2 tables of same colums) & Intersect
1. Rows which included in A but not B
Select * from A except Select * from B
2. Return any diff bewteen A and B
Select * from A except Select * from B union all Select * from B except Select * from A
3. Return duplicated rows between A and B
Select * from A Intersect Select * from B
EXEC output to Variable
1. Using table variable
declare @temp table(id int,Name varchar(50),sex varchar(10)) declare @sql varchar(max)= 'select id,name,''male'' from student where id<3' insert into @temp exec (@sql)
2. Using sp_executesql
DECLARE @sql nvarchar(1000), @input varchar(75)='Fenton', @output varchar(75) SET @sql = 'SELECT top 1 @firstname=firstname FROM [AspNetUsers] WHERE surname = @surname' EXECUTE sp_executesql @sql, N'@surname varchar(75),@firstname varchar(75) OUTPUT', @surname = @input, @firstname=@output OUTPUT select @output
Exists
1. To add any condition for the select (Same as if)
Select col1, col2 from A where exists (Select 1 from B where id=99) --inside exists you can select 1 or anything, it will return TRUE equally
2. To select new user in A but not in B
Select id, name from A where not exists (Select 1 from B where B.id=A.id) --this equals to use IN keyword Select id, name from A where id not in (Select id from B)
Format
1.Mobile or phone number
select format(+61414123456 ,'+##-###-###-###') --+61-414-123-456 select format(0061414123456 ,'+##-###-###-###') --+61-414-123-456 select format(0414123456 ,'+61-###-###-###') --+61-414-123-456
2.Number separator
select format(123456789,'#,#') --123,456,789 select format(123456789,'#,#,') --123,457
3.Add 0 if necessary
select format(7081990, '0#######') --07081990 select format(17081990,'0#######') --17081990
4. Decimal and percentage
select format(1234.5678,'#.##') --1234.57 select format(1234.5678,'#%') --123457%
Group by (only work with count(), AVG(), MAX(), MIN(), Sum() )
--student number for each class select class,count (*) as total from Student group by class --average score for each class select class,avg(score) as AvgScore from Student group by class --highest score for each class select class,max(score) as HighestScore from Student group by class --total donation for each class select class,sum(donation) as TotalDonation from Student group by class
To get top x rows or the xth place in each group, use row_number()
Import data from excel
SELECT * --INTO #Cars FROM OPENROWSET('Microsoft.ACE.OLEDB.12.0', 'Excel 12.0 Xml;HDR=YES;Database=C:\cars.xlsx','SELECT * FROM [sheet1$]');
Indexing
1.
Insert into
1. Mutiple rows with values
insert into #temp(id,name) values (1,'Alice'),(2, 'Jack')
2. From existing tables
insert into #temp(id,name, sex) select id, name,'male' from students where sex=1
3. From exec (Assign EXEC output to Variable)
declare @temp table(id int,Name varchar(50),sex varchar(10)) declare @sql varchar(max)= 'select id,name,''male'' from student where id<3' insert into @temp exec (@sql)
Join
1. cross join
(https://blog.csdn.net/xiaolinyouni/article/details/6943337)
Select * from A cross join B Select * from A,B --same as above

2. Left join, right join, inner join
Left join: contains all rows from left table A, if A.key=B.key, return result in new table, if multiple B.key match A.key, return multiple rows, if no B.key match, return row with null values
inner join: only return if A.key=B.key, can be one to one or one to many
Like and Regex
(http://www.sqlservertutorial.net/sql-server-basics/sql-server-like/)
- The percent wildcard (%): any string of zero or more characters.
- The underscore (_) wildcard: any single character.
- The [list of characters] wildcard: any single character within the specified set.
- The [character-character]: any single character within the specified range.
- The [^]: any single character not within a list or a range.
Not start with special symbol, 3rd character is number or letter
Select * from where name LIKE ' [^.$#@-]_ [a-z0-9]%'
Login history delete for SSMS
C:\Users\*********\AppData\Roaming\Microsoft\SQL Server Management Studio\18.0\UserSettings.xml
- Open it in any Texteditor like Notepad++
- ctrl+f for the username to be removed
- then delete the entire
<Element>.......</Element>block that surrounds it.
Pivot, unpivot (merge multiple cols or split into multiple cols)
1. Convert multiple columns into one
0. Create example table
Name Math Science English
Alice 90 40 60
Tom 30 20 10
CREATE TABLE #StudentMarks(Name varchar(100),Math int,Science int, English int) insert into #StudentMarks values('Alice',90,40,60) insert into #StudentMarks values('Tom',30,20,10)
1.1 Result
name subject marks
Alice Math 90
Alice Science 40
Alice English 60
Tom Math 30
Tom Science 20
Tom English 10
1.2 Convert multiple columns into one (unpivot)
--can be any col in #studentmarks + subject+ marks select name, subject, marks from #studentmarks unpivot ( marks --marks: actual values for subject in (Math, Science, English) --subject: col names ) a
1.3 Convert multiple columns into one (cross join)
select name, subject, case subject --this select the right subject score value to put in new col when 'Maths' then math when 'Science' then science when 'English' then english end as Marks from #studentmarks Cross Join (values('Maths'),('Science'),('English')) AS Subjct(Subject)
2. Split one column value to different columns
the following code convert multiple rows of 1 col into multiple col of 1 row
select 'col1' name,1 value union all select 'col2' name,2 value union all select 'col3' name,3 value union all select 'col4' name,4 value SELECT * from (SELECT cast([name] AS nvarchar(MAX)) [name], row_number() over( ORDER BY value) AS id FROM (select 'col1' name,1 value union all select 'col2' name,2 value union all select 'col3' name,3 value union all select 'col4' name,4 value )a )b pivot ( max([name]) FOR id IN ([1], [2], [3], [4] ) )pvt
if it is static and only a few diff values, use "case when" (search 'case when' in blog)
0. Create sample example
CREATE TABLE #Source( [Id] [int] IDENTITY(1,1) NOT NULL, [Name] [varchar](50) NULL, [FieldCode] [varchar](50) NULL, [Value] int NULL ) ON [PRIMARY] INSERT INTO #Source([Name],[FieldCode],[Value]) SELECT 'Alice','English',60 UNION ALL SELECT 'Jack','Math',70 UNION ALL SELECT 'Tom','Science',80 UNION ALL SELECT 'Tom','Math',75 UNION ALL SELECT 'Tom','English',57 UNION ALL SELECT 'Jack','English',80 UNION ALL SELECT 'Alice','Science',100
2.1 Pivot to dynamic split one col to multiple


--**rename the reference col as name, sourceCol as 'fieldcode', value as 'value' DECLARE @SourceTable VARCHAR(500)='#Source' DECLARE @place_holder_len VARCHAR(500)='1000' --*****if get error 'String or binary data would be truncated', need increase size of this str --1000 length, this is random string placeholder of the col data length when using PIVOT function DECLARE @place_holder VARCHAR(8000)= space(@place_holder_len); --this should work as above --The max len of varchar is 8000, so need to divide sql str into a few varchar DECLARE @sql_current_str VARCHAR(8000) ='' DECLARE @sql_str1 VARCHAR(8000) ='' DECLARE @sql_str2 VARCHAR(8000) ='' DECLARE @sql_str3 VARCHAR(8000) ='' DECLARE @sql_str4 VARCHAR(8000) ='' DECLARE @sql_str5 VARCHAR(8000) ='' DECLARE @sql_str6 VARCHAR(8000) ='' DECLARE @sql_str7 VARCHAR(8000) ='' DECLARE @sql_str8 VARCHAR(8000) ='' DECLARE @sql_str9 VARCHAR(8000) ='' DECLARE @sql_str10 VARCHAR(8000) ='' DECLARE @sql_str998 VARCHAR(8000) ='' --to replace the placeholder to empty string and select result DECLARE @sql_str999 VARCHAR(8000) ='' --to replace the placeholder to empty string and select result DECLARE @all_survey_data_cols VARCHAR(8000) DECLARE @col VARCHAR(8000)='' --current col in loop of all the cols DECLARE @count int =1 DECLARE @index int =1 DECLARE @FieldTable Table (fieldcode varchar(1000)) SET @sql_str1 = 'select distinct (fieldcode) from '+ @SourceTable +' (nolock)' Insert @FieldTable Exec (@sql_str1) select *,ROW_NUMBER() over (order by fieldcode) as i into #Field_ASC from (select * from @FieldTable) a select @count=max(i) from #Field_ASC select @all_survey_data_cols = ISNULL(@all_survey_data_cols + ',','') + QUOTENAME(fieldcode) FROM (select fieldcode from #Field_ASC) a SET @sql_str1 = ' SELECT distinct name,data.* into #temp FROM '+ @SourceTable +' inner join ( SELECT * FROM (select fieldcode,'''+@place_holder+''' as zz from #Field_ASC) p PIVOT (max(zz) FOR fieldcode IN ( '+ @all_survey_data_cols +') ) AS pvt ) data on 1=1 ' while (@index<@count+1) begin select @col = fieldcode from #Field_ASC where i=@index --this is to divide the sql string as max size of varchar is 8000 if (len(@sql_str9)>7000) begin set @sql_current_str= @sql_str10 end else if (len(@sql_str8 )>7000) begin set @sql_current_str= @sql_str9 end else if (len(@sql_str7 )>7000) begin set @sql_current_str= @sql_str8 end else if (len(@sql_str6 )>7000) begin set @sql_current_str= @sql_str7 end else if (len(@sql_str5 )>7000) begin set @sql_current_str= @sql_str6 end else if (len(@sql_str4 )>7000) begin set @sql_current_str= @sql_str5 end else if (len(@sql_str3 )>7000) begin set @sql_current_str= @sql_str4 end else if (len(@sql_str2 )>7000) begin set @sql_current_str= @sql_str3 end else if (len(@sql_str1 )>7000) begin set @sql_current_str= @sql_str2 end else begin set @sql_current_str= @sql_str1 end set @sql_current_str =@sql_current_str +' update a set a.['+@col+']= CONVERT(varchar(8000), b.value) from #temp a inner join (select * from '+ @SourceTable +' (nolock) ) b on a.name=b.name and b.fieldcode='''+@col+ '''' --this is to divide the sql string as max size of varchar is 8000 if (len(@sql_str9)>7000) begin set @sql_str10 = @sql_current_str end else if (len(@sql_str8 )>7000) begin set @sql_str9 = @sql_current_str end else if (len(@sql_str7 )>7000) begin set @sql_str8 = @sql_current_str end else if (len(@sql_str6 )>7000) begin set @sql_str7 = @sql_current_str end else if (len(@sql_str5 )>7000) begin set @sql_str6 = @sql_current_str end else if (len(@sql_str4 )>7000) begin set @sql_str5 = @sql_current_str end else if (len(@sql_str3 )>7000) begin set @sql_str4 = @sql_current_str end else if (len(@sql_str2 )>7000) begin set @sql_str3 = @sql_current_str end else if (len(@sql_str1 )>7000) begin set @sql_str2 = @sql_current_str end else begin set @sql_str1 = @sql_current_str end set @index=@index+1 end set @index=1 while (@index<@count+1) begin select @col = fieldcode from #Field_ASC where i=@index if (len(@sql_str998)>7000) --if exceed 8000 size then store the rest in new str begin set @sql_str999 =@sql_str999 +' update #temp set ['+ @col +'] ='''' where len(['+ @col+']) =0' --replace placeholder by '' end else begin set @sql_str998 =@sql_str998 +' update #temp set ['+ @col +'] ='''' where len(['+ @col+']) =0'--replace placeholder by '' end set @index=@index+1 end set @sql_str999 =@sql_str999 + ' select * from #temp' PRINT ( @sql_str1 + @sql_str2+ @sql_str3 + @sql_str4 + @sql_str5 + @sql_str6 + @sql_str7+ @sql_str8 + @sql_str9 + @sql_str10 + @sql_str998+ @sql_str999 ) EXEC ( @sql_str1 + @sql_str2+ @sql_str3 + @sql_str4 + @sql_str5 + @sql_str6 + @sql_str7+ @sql_str8 + @sql_str9 + @sql_str10 + @sql_str998+ @sql_str999 ) --to check if the sql string is overflow print ('string 1: ' + cast (len ( @sql_str1 ) as varchar(100)) + ' string 2: ' + cast (len ( @sql_str2) as varchar(100)) +' string 3: ' + cast (len ( @sql_str3 ) as varchar(100))+' string 4: ' + cast (len ( @sql_str5 ) as varchar(100)) +' string 5: ' + cast (len ( @sql_str5 ) as varchar(100)) +' string 6: ' + cast (len ( @sql_str6 ) as varchar(100)) + ' string 7: ' + cast (len ( @sql_str7) as varchar(100)) +' string 8: ' + cast (len ( @sql_str8 ) as varchar(100)) +' string 9: ' + cast (len ( @sql_str9 ) as varchar(100))+' string 10: ' + cast (len ( @sql_str10 ) as varchar(100)) +' string 998: ' + cast (len ( @sql_str998 ) as varchar(100))+' string 999: ' + cast (len ( @sql_str999 ) as varchar(100))) drop table #Field_ASC
Random id (GUID), string, number
1. Random Guid
select NEWID() --315FC5A3-BE07-41BB-BE4F-75055729FA5B
2. Random string
SELECT CONVERT(varchar(255), NEWID())
3. Random number (round to integer)
SELECT RAND() -- 0<=decimal<1 SELECT RAND()*15+5; -- 5<=decimal<20 (if include 20 need *16) SELECT FLOOR(22.6) --22 SELECT CEILING(22.6) --23 SELECT ROUND(22.6,0) -- 23.0 SELECT ROUND(22.6,-1) --20.0
Row_number(), Rank() and Dense_rank() (must use with over(order by ...) )
1. Add row id by row_number()
select *,row_number() over(order by class) rowid from #Student

2. if there is identiacal value for the colomn used for order by: Rank() and Dense_rank()
select *,rank() over(order by class) rowid from #Student --if 1st has 2 pp, next is 3rd select *,dense_rank() over(order by class) rowid from #Student --if 1st has 2 pp, next is 2nd
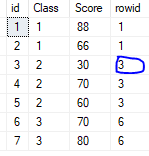
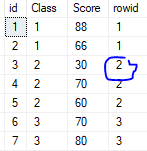
3. Partition by: Assign row id for different group, each group start with 1
select *,row_number() over(partition by class order by class) rowid from #Student
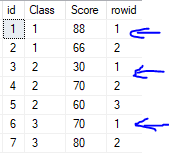
4. Select top 2, the 2nd second place for each group
select * from ( select *,row_number() over(partition by class order by class) rowid from #Student )a where rowid<2 select * from ( select *,row_number() over(partition by class order by class) rowid from #Student )a where rowid=2
Search any "keyword" in database
1. Search keyword for all cols in one table
USE [YourDB] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO /* [SearchOneTable] 'ASPnetusers','2019' [SearchOneTable] 'ASPnetusers','8',1,1,0 */ CREATE PROC [dbo].[SearchOneTable] ( @TableName nvarchar(256), @Keyword nvarchar(100), @SearchDate bit=0, @SearchNumber bit=0, @SearchString bit=1 ) AS BEGIN SET NOCOUNT ON if PARSENAME(@TableName, 2) is null begin set @TableName = 'dbo.' + QUOTENAME(@TableName, '"') end SET @Keyword = QUOTENAME('%' + @Keyword + '%','''') DECLARE @ColumnName nvarchar(128) = '' DECLARE @ColumnNameTableVar table(ColumnName nvarchar(128)) --table var to store exec result into var DECLARE @sql varchar(max)='' DECLARE @StringTypes varchar(1000)='''char'', ''varchar'', ''nchar'', ''nvarchar''' DECLARE @DateTypes varchar(1000)='''date'', ''time'', ''datetime'', ''timestamp''' DECLARE @NumberTypes varchar(1000)='''int'', ''decimal'', ''float'', ''bit''' DECLARE @results TABLE(ColumnName nvarchar(370), ColumnValue nvarchar(3630)) IF @TableName <> '' BEGIN WHILE (@TableName IS NOT NULL) AND (@ColumnName IS NOT NULL) BEGIN set @sql='SELECT MIN(QUOTENAME(COLUMN_NAME)) FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA = PARSENAME('''+@TableName+''', 2) AND TABLE_NAME = PARSENAME('''+@TableName+''', 1) AND QUOTENAME(COLUMN_NAME) > '''+@ColumnName+''' AND DATA_TYPE IN (' + case when @SearchDate=1 and @SearchNumber=0 then @DateTypes +' , ' when @SearchDate=0 and @SearchNumber=1 then @NumberTypes +' , ' when @SearchDate=1 and @SearchNumber=1 then @DateTypes +' , ' + @NumberTypes +' , ' else ' ' end + case when @SearchString=1 then @StringTypes else '''''' end + ')' delete from @ColumnNameTableVar --empty table first insert into @ColumnNameTableVar exec ( @sql ) select top 1 @ColumnName=ColumnName from @ColumnNameTableVar IF @ColumnName IS NOT NULL BEGIN INSERT INTO @results EXEC ( 'SELECT ''' + @TableName + '.' + @ColumnName + ''', LEFT(' + @ColumnName + ', 3630) FROM ' + @TableName + ' WITH (NOLOCK) ' + ' WHERE ' + @ColumnName + ' LIKE ' + @Keyword ) END END END SELECT ColumnName, ColumnValue FROM @results END GO
2. Search keyword for all cols in all tables (Extremely slow!!!)
USE [YourDB] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO /* *******don't use it in large db, which will be extremely slow********** [SearchAllTables] 'survey' */ CREATE PROC [dbo].[SearchAllTables] ( @Keyword nvarchar(100), @SearchDate bit=0, @SearchNumber bit=0, @SearchString bit=1 ) AS BEGIN SET NOCOUNT ON SET @Keyword = QUOTENAME('%' + @Keyword + '%','''') CREATE TABLE #Results (ColumnName nvarchar(370), ColumnValue nvarchar(3630)) DECLARE @TableName nvarchar(256)='' DECLARE @ColumnName nvarchar(128) DECLARE @ColumnNameTableVar table(ColumnName nvarchar(128)) --table var to store exec result into var DECLARE @sql varchar(max)='' DECLARE @StringTypes varchar(1000)='''char'', ''varchar'', ''nchar'', ''nvarchar'' ' DECLARE @DateTypes varchar(1000)='''date'', ''time'', ''datetime'', ''timestamp''' DECLARE @NumberTypes varchar(1000)='''int'', ''decimal'', ''float'', ''bit''' WHILE @TableName IS NOT NULL BEGIN SET @ColumnName = '' SET @TableName = ( SELECT MIN(QUOTENAME(TABLE_SCHEMA) + '.' + QUOTENAME(TABLE_NAME)) FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE' AND QUOTENAME(TABLE_SCHEMA) + '.' + QUOTENAME(TABLE_NAME) > @TableName AND OBJECTPROPERTY( OBJECT_ID( QUOTENAME(TABLE_SCHEMA) + '.' + QUOTENAME(TABLE_NAME) ), 'IsMSShipped' ) = 0 ) WHILE (@TableName IS NOT NULL) AND (@ColumnName IS NOT NULL) BEGIN set @sql='SELECT MIN(QUOTENAME(COLUMN_NAME)) FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA = PARSENAME('''+@TableName+''', 2) AND TABLE_NAME = PARSENAME('''+@TableName+''', 1) AND QUOTENAME(COLUMN_NAME) > '''+@ColumnName+''' AND DATA_TYPE IN (' + case when @SearchDate=1 and @SearchNumber=0 then @DateTypes +' , ' when @SearchDate=0 and @SearchNumber=1 then @NumberTypes +' , ' when @SearchDate=1 and @SearchNumber=1 then @DateTypes +' , ' + @NumberTypes +' , ' else ' ' end + case when @SearchString=1 then @StringTypes else '''''' end + ')' delete from @ColumnNameTableVar --empty table first insert into @ColumnNameTableVar exec ( @sql ) select top 1 @ColumnName=ColumnName from @ColumnNameTableVar IF @ColumnName IS NOT NULL BEGIN INSERT INTO #Results EXEC ( 'SELECT ''' + @TableName + '.' + @ColumnName + ''', LEFT(' + @ColumnName + ', 3630) FROM ' + @TableName + 'WITH (NOLOCK) ' + ' WHERE ' + @ColumnName + ' LIKE ' + @Keyword ) END END END SELECT ColumnName, ColumnValue FROM #Results END GO
3. Search keyword for all the cols name in all tables
--to search "keyword" in any cols, in any tables of db SELECT b.name as tables, a.name as cols FROM sys.columns as a inner join sys.tables as b on a.object_id=b.object_id where a.name like '%keyword%' order by b.name
4. Search keyword in whole text of the proc (may not working very well if proc is very long)
--to search "keyword" in stored procedure whole text SELECT ROUTINE_NAME, ROUTINE_DEFINITION FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_DEFINITION LIKE '%keyword%' AND ROUTINE_TYPE='PROCEDURE'
Short Keys for text selection
1. Using SHIFT+ALT+(arrow key or cursor) to Select block of values among multiple rows

2. Using CTRL+SHIFT+END to Select Text till end (CTRL+ END can move cursor to end)

3. Using CTRL+SHIFT+HOME to Select Text till start (CTRL+HOME can move cursor to end)

4. User CTRL+ arrow key can move cursor jump between words not letters
String edit
Note: SQL index start from 1 not 0
1. left and right
select left('hello world',5) --return: hello select right('hello world!',6) --return:world!
2. Substring
select substring('hello world',7,5) --return: world
3. Replace (by expression or by index)
select REPLACE('123456','34','new') --return 12new56 select stuff('123456',3,2,'new') --same as above, start index=3, length=2
4. Split (not exist in sql, need use LEFT+ RIGHT + CHARINDEX)
--split 'hello world' by space select left('hello world',CHARINDEX(' ','hello world')-1) select right('hello world',len('hello world')-CHARINDEX(' ','hello world'))
5. Delete white space
SELECT LTRIM(' Sample '); --return 'Sample ' SELECT RTRIM(' Sample '); --return ' Sample'
6. Delete enter, tab, space
--char(13)+CHAR(10) = enter print 'first line'+char(13)+CHAR(10)+'Second line' --2 lines --char(9) is tab, the outsode replace delete all space print REPLACE(REPLACE(REPLACE(REPLACE('first line Second line',CHAR(13),''),CHAR(10),''),CHAR(9),''),' ','')

 is newline in XML, try search it if still newline
7. Search a regex in string
SELECT PATINDEX('%[mo]%', 'W3Schools.com'); --return m or o which appear first
8. Repeat string a few times
select REPLICATE('hello world ',3) --return: hello world hello world hello world
9. Revers a string by characters
select REVERSE('1234567') --return 7654321
10. Create an empty fixed length string (only contains spaces)
select 'a'+SPACE(5)+'b' --return a b
Top
1. select rows between m and n place of highest score
select top 2 * from ( --between 4 and 5, 5-4+1=2 select top 5 * from #Student order by score desc)a order by score
2. Select 2nd second place by add row_number()
-- if there are multiple highest score, will select highest score select * from ( select *,row_number() over( order by score desc) rowid from #Student )a where rowid=2 --if there are multiple highest score, still select second highest score select * from ( select *,rank() over( order by score desc) rowid from #Student )a where rowid=2
-- rowid between m and n -- rows between order of the m place to n place
Transaction
1. Begin, rollback,commit tran
Declare @isDebug bit=0 begin tran -- insert/update/delete queries if @isDebug=0 and @@error=0 --prod run and no errors begin commit tran end else -- test run or any error begin rollback tran end
2. trasaction with try/catch
Declare @isDebug bit=1 BEGIN TRY BEGIN tran if @isDebug=0 --test run begin -- insert/update/delete queries end else --prod run begin -- insert/update/delete queries end COMMIT tran --commit if above code has no error END TRY BEGIN CATCH ROLLBACK tran --if any error jump to this to rollback select ERROR_NUMBER() as ErrorNumber, ERROR_MESSAGE() as ErrorMessage, ERROR_PROCEDURE() as ErrorProcedure END CATCH
Output (to log result along with query)
1. You can output deleted or inserted rows with the query
CREATE TABLE #temp (ID INT, Val VARCHAR(100)) INSERT #temp (ID, Val) VALUES (1,'FirstVal') INSERT #temp (ID, Val) VALUES (2,'SecondVal') CREATE TABLE #log (ID INT, Val VARCHAR(100), Query VARCHAR(100)) SELECT * FROM #temp INSERT #temp (ID, Val) output inserted.ID,inserted.Val,'Insert' into #log VALUES (3,'ThirdVal') --you can also output both deleted and inserted values Update #temp set Val='NewVal' output Deleted.ID, Deleted.Val,'Delete' into #log where id=3 Update #temp set Val='NewVal' output inserted.ID,inserted.Val,'Insert' into #log where id=3 DELETE FROM #temp OUTPUT Deleted.ID, Deleted.Val,'Delete' into #log WHERE ID IN (1,2) SELECT * FROM #log SELECT * FROM #temp DROP TABLE #temp DROP TABLE #log
Union, Union All
1. Union not return duplicated rows (by duplicated mean all the values are exactly same)
2. Union All return all rows include duplicated rows
3. Both Union and Union all need to have exactly same number of total columns (col name can be diff but type need to be same)
4. Union All is much faster than Union
Update one colomn from column in another table
UPDATE a SET a.marks = b.marks FROM tempDataView a INNER JOIN tempData b ON a.Name = b.Name
Variables (declare, set, select)
1. Declare multiple vars and initialize the value
declare @a int =1, @b varchar(max)='abc'
2. Set can only set single values
set @a=2
3. Set values by using query
set @a=(select 2)
4. Select can assign value to multiple vars
select @a=2, @b='new'
5. Select to assign values by query
select top 1 @a=ClientId, @b=Surname from [AspNetUsers]
6. EXEC to a variable
DECLARE @sql nvarchar(1000), @input varchar(75)='Fenton', @output varchar(75) SET @sql = 'SELECT top 1 @firstname=firstname FROM [AspNetUsers] WHERE surname = @surname' EXECUTE sp_executesql @sql, N'@surname varchar(75),@firstname varchar(75) OUTPUT', @surname = @input, @firstname=@output OUTPUT select @output
View (with ... as (CTE_query))
CTE=Common Table Expression
**delete or update view will influence original table, delete or update or insert values to original table will influence on view
with StudentVw as( select top 100 ROW_NUMBER() over (order by SurveyTypeid, surveyid ) as rowid,* from ##temp order by channelid -- if use order by must have top keyword ) select * from StudentVw --must come with a query and only 1 query
ZZZZ Examples
0. Create Sample tables
CREATE TABLE students (sno VARCHAR(3) NOT NULL, sname VARCHAR(4) NOT NULL, ssex VARCHAR(2) NOT NULL, sbirthday DATETIME, class VARCHAR(5)) CREATE TABLE courses (cno VARCHAR(5) NOT NULL, cname VARCHAR(10) NOT NULL, tno VARCHAR(10) NOT NULL) CREATE TABLE scores (sno VARCHAR(3) NOT NULL, cno VARCHAR(5) NOT NULL, degree NUMERIC(10, 1) NOT NULL) CREATE TABLE teachers (tno VARCHAR(3) NOT NULL, tname VARCHAR(4) NOT NULL, tsex VARCHAR(2) NOT NULL, tbirthday DATETIME NOT NULL, prof VARCHAR(60), depart VARCHAR(100) NOT NULL) INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (108 ,'aa' ,'m' ,'1977-09-01',95033); INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (105 ,'bb' ,'m' ,'1975-10-02',95031); INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (107 ,'cc' ,'f' ,'1976-01-23',95033); INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (101 ,'dd' ,'m' ,'1976-02-20',95033); INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (109 ,'ee' ,'f' ,'1975-02-10',95031); INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (103 ,'ff' ,'m' ,'1974-06-03',95031); INSERT INTO COURSES(CNO,CNAME,TNO)VALUES ('3-105' ,'computer',825); INSERT INTO COURSES(CNO,CNAME,TNO)VALUES ('3-245' ,'os' ,804); INSERT INTO COURSES(CNO,CNAME,TNO)VALUES ('6-166' ,'data' ,856); INSERT INTO COURSES(CNO,CNAME,TNO)VALUES ('9-888' ,'math' ,100); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (103,'3-245',86); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (105,'3-245',75); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (109,'3-245',68); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (103,'3-105',92); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (105,'3-105',88); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (109,'3-105',76); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (101,'3-105',64); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (107,'3-105',91); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (108,'3-105',78); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (101,'6-166',85); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (107,'6-106',79); INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (108,'6-166',81); INSERT INTO TEACHERS(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART) VALUES (804,'uu','m','1958-12-02','pro','computer depart'); INSERT INTO TEACHERS(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART) VALUES (856,'vv','m','1969-03-12','lecture','electric depart'); INSERT INTO TEACHERS(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART) VALUES (825,'ww','f','1972-05-05','assis','computer depart'); INSERT INTO TEACHERS(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART) VALUES (831,'xx','f','1977-08-14','assis','electric depart');
1. Find student sno, who enroll in both 105 and 245
SELECT [sno] FROM [DashboardShaperData_64].[dbo].[scores] where cno='3-105' or cno='3-245' group by sno having count(*)>1
2. Find students sno whose 105 degree is higher than 245 degree
SELECT a.sno,a.degree as '105', b.degree as "245" FROM (select sno,degree from scores where cno='3-105' )a inner join (select sno,degree from scores where cno='3-245')b on a.sno=b.sno where a.degree>b.degree
--return 1



