
什么是函数
函数定义
函数三元素:函数名、函数参数、返回值;其中函数名是必需的,函数参数和返回值是可选的,如果不需要与外部交互,函数参数和返回值可以省略。
函数定义:函数名称应该能够表达函数封装代码的功能,方便后续的调用
特性:减少重复代码、使程序变得可扩展、易于维护。
函数语法:
函数名的命名规则
可以由 字母、下划线和数字组成
不能以数字开头
不能与关键字重名
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
函数内容以冒号起始,并且缩进。
注意:定义一个函数不会默认执行,只能通过调用方式执行。
快捷键使用:
F8 Step Over可以单步执行代码,会把函数调用看作是一行代码直接执行
F7 Step Into可以单步执行代码,如果是函数,会进入函数内部
def test1(): #函数名
print("is the tes1")
test1() # 定义好函数之后,只表示这个函数封装了一段代码而已如果不主动调用函数,函数是不会主动执行的
文档注释
注释在程序中不是必需的,但是必要的,不管单行注释还是多行注释在程序编译后都会被编译器去掉,无法在程序中通过代码来动态获取单行/多行注释,而文档注释作为程序的一部分一起存储,通过代码可以动态获取这些注释。
def add(x,y): "计算两个数的和" #添加文档注释 return x+y #使用"__doc__"函数属性获取add函数的文档属性,也可以直接使用help函数获取文档注释 print(add.__doc__) help(add)
参数
形参:变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参:在函数调用的时候给函数传递的值.加实参,实际执行的时候给函数传递的信息;可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
传参:给函数传递信息的时候将实际参数交给形式参数的过程被称为传参;
必备参数/位置参数
须以正确的顺序传入函数。调用时的数量必须和声明时的一样。形参就是一个变量名,实参就是值 传参就是在赋值;
def stu(name,age,sex): # 形参 print("我叫{},今年{},性别{}".format(name,age,sex)) stu("flowers",12,"女") # 实参 # 编写函数,给函数传递两个参数a,b a,b相加 返回a参数和b参数相加的和 def f (a,b): c = a+b return c num = f(3,5) print(num) # 编写函数,给函数传递两个参数a,b 比较a,b的大小 返回a,b中最大的那个数 def g(a,b): # if a>b: # return a # else: # return b #使用三元运算符简写 c = a if a>b else b return c re = g(8,12) print(re)
关键字参数
函数调用使用关键字参数来确定传入的参数值。调用使用关键字参数的函数时,以param = value的方式传递数据
好处 :清晰地指出了参数值,提高程序的可读性;关键字参数不用考虑顺序,对于包含大量参数的函数很有帮助,不用去记住这些函数的参数的顺序和含义
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。关键参数必须放在位置参数之后。
def fun2(name, age,eat): print("{}今年{}岁,爱吃{}".format(name,age,eat)) fun2(age=5,eat="大米",name="miki") def fun3(name, age,color): print("{}今年{}岁,喜欢{}".format(name,age,color)) fun3("flowers",18,color="红色") # 注意:必须先声明在位置参数,才能声明关键字参数
缺省参数/混合参数(默认值),
调用函数时,缺省参数的值如果没有传入,则被认为是默认值(参数都是一样的, 一般用默认参数)。
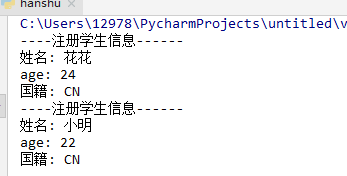
def student(name,age,country='CN'): # 注意:必须先声明在位置参数,才能声明默认参数 print("----注册学生信息------") print("姓名:{}\nage:{}\n国籍{}:".format(name, age,country)) print("----信息录入完毕------") student("花花",24) student("小明",22)
结果图:
不定长参数(动态参数)
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,
注意: 形参的顺序: 位置参数 , 动态参数 , 默认参数
在参数位置用*表示接受任意参数
# 收到的结果是一个tuple元祖 def eat(*args): print('我想吃',args) eat('大米饭','中米饭','小米饭') # 动态参数必须在位置参数后面 def eat1(a,b,*args): print('我想吃',args,a,b) # 结果我想吃 ('小米饭',) 大米饭 中米饭 eat1('大米饭','中米饭','小米饭') # 形参的顺序: 位置参数 , 动态参数 , 默认参数 def li(a,b,*args,c=9): print(a,b,args,c) #结果:1 2 (3, 4) 9 li(1,2,3,4,) # 计算任意多个数字的和 def sum_numbers(*args): num = 0 # 遍历 args 元组顺序求和 for n in args: num += n return num print(sum_numbers(1, 2, 3))
动态接收关键字参数
在python中可以动态的位置参数,但是这种情况只能接收位置参数无法接收关键字参数,在python中使用**来接收动态关键字参数,动态关键字参数最后获取的是一个dict字典形式;
def test4( arg1, *args,**kwargs ): #**kwatgs 把多个传入的参数变成一个dict形式 print (arg1, args,kwargs) test4( 70, 60, 50,30,41,22 ,sex="flower",province="beijign") # 结果:70 (60, 50, 30, 41, 22) {'sex': 'flower', 'province': 'beijign'}
最终顺序:
位置参数 > args(动态位置参数) > 默认值参数 > *kwargs(动态默认参数)
return返回值
总结:
函数中遇到return,此函数结束.不在继续执行
如果return什么都不写或者干脆就没写return,返回的结果就是None
如果return后面写了一个值,返回给调用者这个值
如果return后面写了多个结果,返回给调用者一个tuple(元祖),调用者可以直接使用解构获取多个变量;
def measure(): """测量温度和湿度""" print("测量开始...") temp = 39 wetness = 50 print("测量结束...") # 元组-可以包含多个数据,因此可以使用元组让函数一次返回多个值 # 如果函数返回的类型是元组,小括号可以省略 # return (temp, wetness) return temp, wetness # 元组 result = measure() print(result) # 需要单独的处理温度或者湿度 - 不方便 print(result[0]) print(result[1]) # 如果函数返回的类型是元组,同时希望单独的处理元组中的元素 # 可以使用多个变量,一次接收函数的返回结果 # 注意:使用多个变量接收结果时,变量的个数应该和元组中元素的个数保持一致 gl_temp, gl_wetness = measure() print(gl_temp) print(gl_wetness)
变量进阶
变量的引用:
变量和数据都是保存在内存中的,在 `Python` 中函数的参数传递以及返回值都是靠引用传递的
变量和数据是分开存储的,数据保存在内存中的一个位置,变量中保存着数据在内存中的地址,变量中记录数据的地址,就叫做引用使用 `id()` 函数可以查看变量中保存数据所在的内存地址
注意:如果变量已经被定义,当给一个变量赋值的时候,本质上是修改了数据的引用;
变量 不再对之前的数据引用;
变量改为对新赋值的数据引用;
#调用函数传递实参的引用 def test(num): print("在函数内部 %d 对应的内存地址是 %d" % (num, id(num))) # 1. 定义一个数字的变量 a = 10 # 数据的地址本质上就是一个数字 print("a 变量保存数据的内存地址是 %d" % id(a)) test(a) #函数返回值传递引用 def test(num): print("在函数内部 %d 对应的内存地址是 %d" % (num, id(num))) # 1> 定义一个字符串变量 result = "hello" print("函数要返回数据的内存地址是 %d" % id(result)) # 2> 将字符串变量返回,返回的是数据的引用,而不是数据本身 return result # 1. 定义一个数字的变量 a = 10 # 数据的地址本质上就是一个数字 print("a 变量保存数据的内存地址是 %d" % id(a)) r = test(a) print("%s 的内存地址是 %d" % (r, id(r)))
可变和不可变类型:
不可变类型内存中的数据不允许被修改:
数字类型 `int`, `bool`, `float`, `complex`, `long(2.x)`
字符串 `str`
元组 `tuple`
可变类型内存中的数据可以被修改:
列表 `list`
字典 `dict`
注意:
1. 可变类型的数据变化,是通过方法来实现的
2. 如果给一个可变类型的变量,赋值了一个新的数据,引用会修改,变量不再对之前的数据引用,变量改为对新赋值的数据引用;
demo_list = [1, 2, 3] print("定义列表后的内存地址 %d" % id(demo_list)) demo_list.append(999) demo_list.pop(0) demo_list.remove(2) demo_list[0] = 10 demo_list = [] #可变类型的数据使用方法改变数据引用地址不会改变,一旦重新赋值,引用地址就会发生变化 print("修改数据后的内存地址 %d" % id(demo_list)) demo_dict = {"name": "小明"} # 注意:字典的 `key` 只能使用不可变类型的数据 print("定义字典后的内存地址 %d" % id(demo_dict)) demo_dict["age"] = 18 demo_dict.pop("name") demo_dict["name"] = "老王" print("修改数据后的内存地址 %d" % id(demo_dict))
变量作用域
Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python的作用域一共有4种,分别是:
- L (Local) 局部作用域
- E (Enclosing) 闭包函数外的函数中
- G (Global) 全局作用域
- B (Built-in) 内置作用域(内置函数所在模块的范围)
以 L –> E –> G –>B 的规则查找,即:在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找;
局部变量和全局变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量:只能在其被声明的函数内部访问使用,函数执行结束后,函数内部的局部变量,会被系统回收,不同的函数,可以定义相同的名字的局部变量,但是彼此之间不会产生影响;
全局变量:可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。
#不同函数之间相同的变量,之间互不影响 def demo1(): num = 10 print(num) num = 20 print("修改后 %d" % num) def demo2(): num = 100 print(num) demo1() demo2() print("over") # 全局变量:可以在整个程序范围内访问 num = 10 def demo1(): print("demo1 ==> %d" % num) num+=num def demo2(): print("demo2 ==> %d" % num) demo1() demo2() total = 0 # 全局变量 def sum( a, b ): total = a + b # total局部变量. print ("函数内是局部变量 : ", total) #30 return total sum( 10, 20 ) print ("函数外是全局变量 : ", total) #0
global、nonlocal关键字
全局变量是在函数外部定义的变量(没有定义在某一个函数内),所有函数内部都可以使用这个变量
注意:为了保证所有的函数都能够正确使用到全局变量,应该将全局变量定义在其他函数的上方;
命名规则:为了避免局部变量和全局变量出现混淆,在定义全局变量时,局变量名前应该增加 `g_` 或者 `gl_` 的前缀;
# 修改全局变量的值,在 python 中,不允许直接修改全局变量的值,如果使用赋值语句,会在函数内部,定义一个局部变量 num = 10 def demo1(): """修改全局变量,使用 `global` 进行声明""" global num num = 99 print("demo1 ==> %d" % num) def demo2(): print("demo2 ==> %d" % num) demo1() demo2() print("全局变量是 ==> %d" %num) # nonlocal 只修改上一层变量,如果上一层中没有变量就往上找一层,只会找到函数的最外层,不会找到全局进行修改 a = 10 def func1(): a = 20 def func2(): nonlocal a a = 30 print("fun2 ==> %d" %a) func2() print("fun1 ==> %d" %a) func1() print("全局变量是 ==> %d" %a) #三层嵌套并加了nonlocal, 只修改上一层变量 a = 1 def fun_1(): a = 2 # 3 def fun_2(): a = 3 # 6 def fun_3(): nonlocal a a = 4 # 9 print("fun_3变量是4 ==> %d" %a) # 10 print("fun_2变量是3 ==> %d" %a) # 7 fun_3() # 8 print("fun_2变量是3 ==> %d" %a) # 11 print("fun_1变量是2 ==> %d" %a) # 4 fun_2() # 5 print("fun_1变量是2 ==> %d" %a) # 12 print("全局变量是1 ==> %d" %a) # 1 fun_1() # 2 print("全局变量是1 ==> %d" %a) # 13 # 全局变量是1 ==> 1 # fun_1变量是2 ==> 2 # fun_2变量是3 ==> 3 # fun_3变量是4 ==> 4 # fun_2变量是3 ==> 4 # fun_1变量是2 ==> 2 # 全局变量是1 ==> 1
问题 1:在函数内部,针对参数使用赋值语句,会不会影响调用函数时传递的实参变量? —— 不会!
def demo(num, num_list): print("函数内部的代码") # 在函数内部,针对参数使用赋值语句,不会修改到外部的实参变量 num = 100 num_list = [1, 2, 3] print(num) print(num_list) print("函数执行完成") gl_num = 99 gl_list = [4, 5, 6] demo(gl_num, gl_list) print(gl_num) print(gl_list) 结果: 函数内部的代码 100 [1, 2, 3] 函数执行完成 99 [4, 5, 6]
问题 2:如果传递的参数是可变类型,在函数内部,使用方法修改了数据的内容,同样会影响到外部的数据
def mutable(num_list): #num_list = [1, 2, 3] num_list.extend([1, 2, 3]) num_list.append(20) print(num_list) gl_list = [6, 7, 8] mutable(gl_list) print(gl_list) 结果: [6, 7, 8, 1, 2, 3, 20] [6, 7, 8, 1, 2, 3, 20]
问题3:在 `python` 中,列表变量调用 `+=` 本质上是在执行列表变量的 `extend` 方法,不会修改变量的引用
def demo(num, num_list): print("函数内部代码") # num = num + num ,结果18 num += num #num_list.extend(num_list) #由于是调用方法,所以不会修改变量的引用 # 函数执行结束后,外部数据同样会发生变化 #num_list += num_list print(num) print(num_list) print("函数代码完成") gl_num = 9 gl_list = [1, 2, 3] demo(gl_num, gl_list) print(gl_num) print(gl_list) 结果: 函数内部代码 18 [1, 2, 3, 1, 2, 3] 函数代码完成 9 [1, 2, 3, 1, 2, 3]
问题4:元组和字典的拆包
在调用带有多值参数的函数时,如果希望:将一个元组变量,直接传递给 `args`,将一个 **字典变量**,直接传递给 `kwargs`,就可以使用拆包,简化参数的传递;
拆包的方式是:在元组变量前增加 一个`*`,在字典变量前,增加两个‘**’;
def demo (*args,**kwargs): print(args) print(kwargs) # 需要将一个元组变量/字典变量传递给函数对应的参数 gl_nums = (1,2,3) gl_name = {"name":"flower","age":12} #demo(gl_nums,gl_name) # 会把gl_nums和gl_name 作为元组传递个 args((1, 2, 3), {'name': 'flower', 'age': 12}) demo(*gl_nums,**gl_name) #拆包
匿名函数
python 使用 lambda 来创建匿名函数。
lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
sum = lambda arg1, arg2: arg1 + arg2; print "相加后的值为 : ", sum( 10, 20 ) print "相加后的值为 : ", sum( 20, 20 )
以上实例输出结果:
相加后的值为 : 30
相加后的值为 : 40
7.递归
如果一个函数在内部调用自己,这个函数就是递归函数。
递归特性:
1. 必须有一个明确的结束条件,通常被称为递归的出口,否则会出现死循环;
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出
def sum_numbers(num): print(num) #当参数满足一个条件时,函数不再执行 #递归的出口很重要,否则会出现死循环 if num ==1: return sum_numbers(num - 1) sum_numbers(3)
解析:
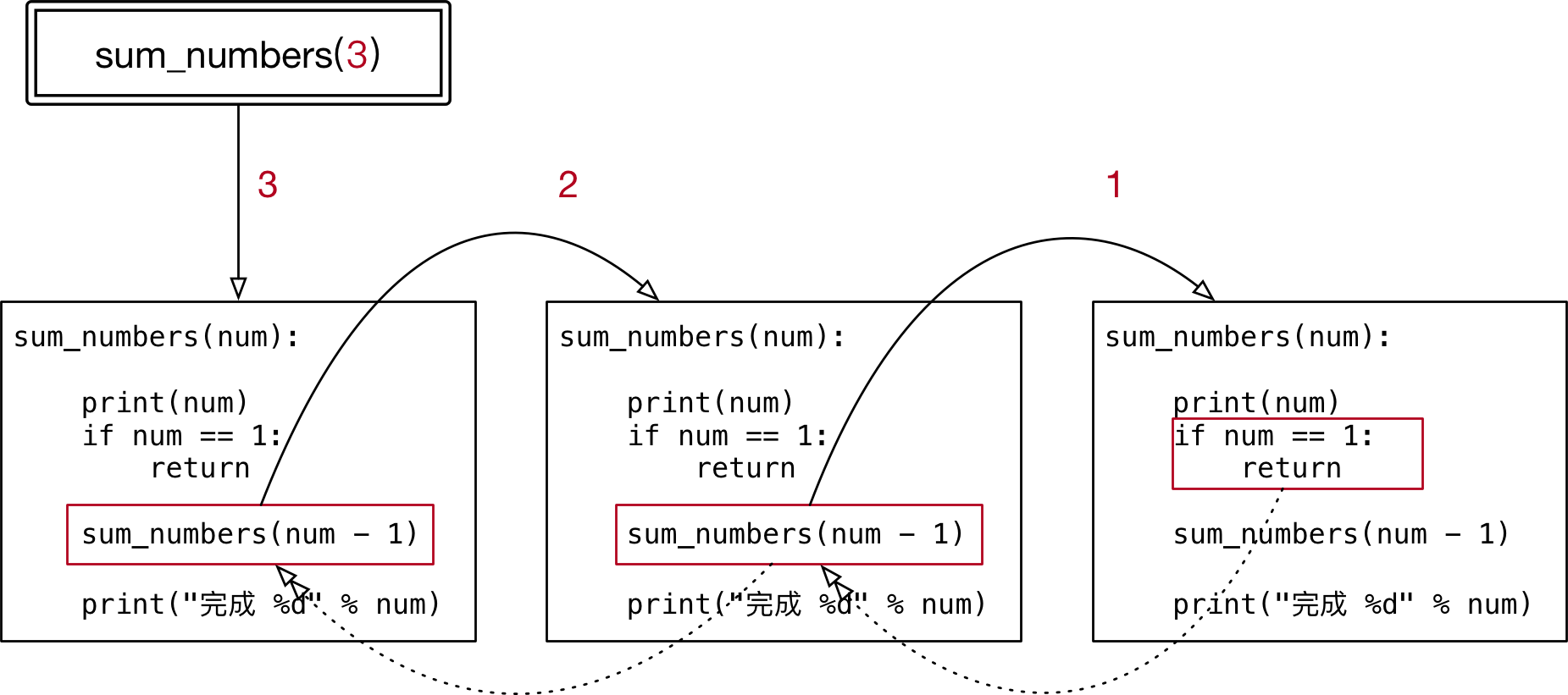
计算数字累加练习:
1. 定义一个函数 `sum_numbers`
2. 能够接收一个 `num` 的整数参数
3. 计算 1 + 2 + ... num 的结果
def sum_numbers(num): if num == 1: return 1 # 假设 sum_numbers 能够完成 num - 1 的累加 temp = sum_numbers(num - 1) # 函数内部的核心算法就是 两个数字的相加 return num + temp print(sum_numbers(2))
解析:
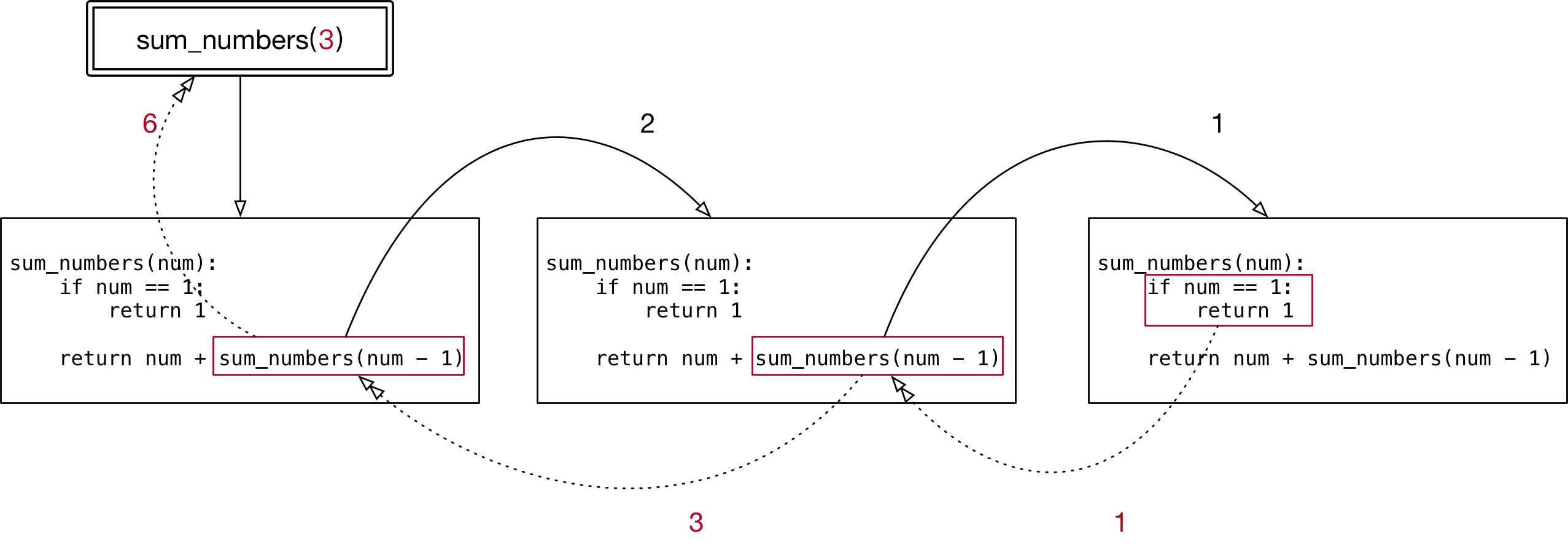
内嵌函数
函数里面嵌套函数
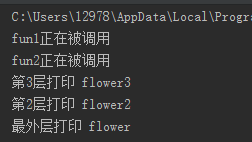
def fun1(): print ("fun1正在被调用") def fun2(): print ("fun2正在被调用") fun2() fun1() # 三层嵌套 name = "flower" def change_name(): name = "flower2" def change_name2(): name = "flower3" print("第3层打印", name) change_name2() # 调用内层函数 print("第2层打印", name) change_name() print("最外层打印", name)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号