
Python高级应用程序设计任务
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
今日热榜数据爬取 地址:https://tophub.today/
2.主题式网络爬虫爬取的内容与数据特征分析
爬取微博,百度,知乎三个榜单和历史榜单的标题与热度。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
获取到三个平台的链接,构造headers请求头请求网页,使用lxml解析网页,通过观察源码结构提取出热门话题和对应的热度值。
请求需要根据控制台监控的请求模拟构造请求头。
每个平台的热度值表示方式不同,无法使用统一的处理方式获取到其中的数值,最终决定使用正则匹配到数值。
对标题进行文本分析,使用结巴分词提取关键字并且画出词云。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
主题页面为多家平台的榜单数据,选取综合平台中的三家进行爬取。
每家平台的榜单分为当前榜单和历史榜单。
2.Htmls页面解析
两个榜单分别在两个class=table的table中,每条数据都在table中的一个tr里。
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
首先找到两个table,然后遍历table,找到tr,然后遍历tr,第二个td里的a标签中存在着文本,第三个td的文本中有热度值。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
先使用字典遍历下三个平台的名称和对应的url,然后构造一个请求头,通过F12打开控制台观察请求头,挑取其中的user-agent,accent,cookie进行构造。
将请求的字符串文本使用lxml的etree构造成dom对象,使用xpath进行提取内容。
最终将提取的内容保存到csv。
代码如下:
import requests from lxml import etree import pandas as pd ''' 网址:https://tophub.today/ 微博:https://tophub.today/n/KqndgxeLl9 知乎:https://tophub.today/n/mproPpoq6O 百度:https://tophub.today/n/Jb0vmloB1G ''' urls = { '微博': 'https://tophub.today/n/KqndgxeLl9', '知乎': 'https://tophub.today/n/mproPpoq6O', '百度': 'https://tophub.today/n/Jb0vmloB1G', } headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'cookie': 'UM_distinctid=16ef50dda3e9c1-0fe2c80daba785-2393f61-1fa400-16ef50dda3fa9a; Hm_lvt_3b1e939f6e789219d8629de8a519eab9=1576069363,1576902795; CNZZDATA1276310587=1873865941-1576066676-%7C1576904182; Hm_lpvt_3b1e939f6e789219d8629de8a519eab9=1576906643', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36' } for platform, url in urls.items(): data = [] response = requests.get(url, headers=headers) selectore = etree.HTML(response.text) tables = selectore.xpath('.//table[@class="table"]') for table in tables: trs = table.xpath('.//tr') for tr in trs: title = tr.xpath('./td[2]/a/text()')[0] number = tr.xpath('./td[3]/text()')[0] data.append([title, number]) df = pd.DataFrame(data, columns=['title', 'number']) df.to_csv('data/{}.csv'.format(platform), index=False)
2.对数据进行清洗和处理
import json import time import re import pandas as pd from aip import AipNlp # """ 你的 APPID AK SK """ APP_ID = '11703996' API_KEY = '5TetNdgFFeWQxNbI8H4fZ8kq' SECRET_KEY = 'RWmPGTBdcStIiDMtb7GOGGB0PVXMCyce' """ 你的 APPID AK SK """ APP_ID = '' API_KEY = '' SECRET_KEY = '' client = AipNlp(APP_ID, API_KEY, SECRET_KEY) for platform in ['百度', '微博', '知乎']: df = pd.read_csv('data/{}.csv'.format(platform)) # total = df['handle_number'].sum() # df['popularity'] = [round(popularity/total*1000, 3) for popularity in baidu_df['popularity']] df['handle_number'] = 0.0 df['lv1_tag'] = '' for index, row in df.iterrows(): print(index) try: title = row['title'] number = row['number'] find = re.findall('\d+.?\d?', number) if find: df.loc[index, 'handle_number'] = float(find[0]) else: pass content = title * 20 """ 调用api """ topic_result = client.topic(title, content) lv1_tag_list = topic_result.get('item').get('lv1_tag_list') if lv1_tag_list: lv1_tag = lv1_tag_list[0].get('tag') df.loc[index, 'lv1_tag'] = lv1_tag except: pass df = df.sort_values('handle_number', ascending=False) df= df.reset_index(drop=True) df.to_csv('./handle_data/{}.csv'.format(platform), index=None)
3.文本分析(可选):jieba分词、wordcloud可视化
将每个平台的标题进行汇总,加载停用词后使用jieba第三方包进行关键词提取,将提取的关键字和相应权重使用 wordcloud进行可视化词云。
代码如下:
import jieba.analyse import pandas as pd import matplotlib.pyplot as plt from wordcloud import WordCloud import random # 中文乱码和坐标轴负号的处理 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False # df = None for platform in ['百度', '微博', '知乎']: df = pd.read_csv('./handle_data/{}.csv'.format(platform)) # 热度排行榜top10 df = df.sort_values('handle_number', ascending=False) df= df.reset_index(drop=True) fig = plt.figure(figsize=(15, 6)) top10_df = df[:10] x = list(top10_df.index) y = list(top10_df['handle_number'].values) titles = list(top10_df['title'].values) plt.barh(titles, y) fig.tight_layout() for x_, y_, title in zip(x, y, titles): plt.text(y_+50 , title, '%.f' % y_, ha='center', va='bottom') plt.savefig('{}热度排行榜top10.png'.format(platform)) plt.close() # 分类占比 lv1_tag = df['lv1_tag'].value_counts(normalize=True) lv1_tag.plot.pie(subplots=True, figsize=(16, 16), label='分类占比') # autopct="%1.2f%%" plt.savefig('{}分类占比图.png'.format(platform)) plt.close() # 分类热度 lv1_tag = df.groupby('lv1_tag')['handle_number'].sum() lv1_tag = lv1_tag.sort_values() lv1_tag.plot('bar', figsize=(10, 6)) plt.xticks(rotation=60) plt.savefig('{}分类热度图.png'.format(platform)) plt.close() # jieba词云 df.loc[:, 'title'] = df['title'].astype('str') content = list(df['title'].values) content = '。'.join(content) try: jieba.analyse.set_stop_words('./data/stopwords.txt') tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True) keywords = dict() for i in tags: keywords[i[0]]=i[1] wc = WordCloud( font_path='/usr/share/fonts/winfonts/simfang.ttf', background_color='White', max_words=1000, width=1000, height=500, #mask=graph, scale=1, ) wc.generate_from_frequencies(keywords)#按词出现的频率 wc.to_file("{}词云.jpg".format(platform)) finally: pass
结果如下:

4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
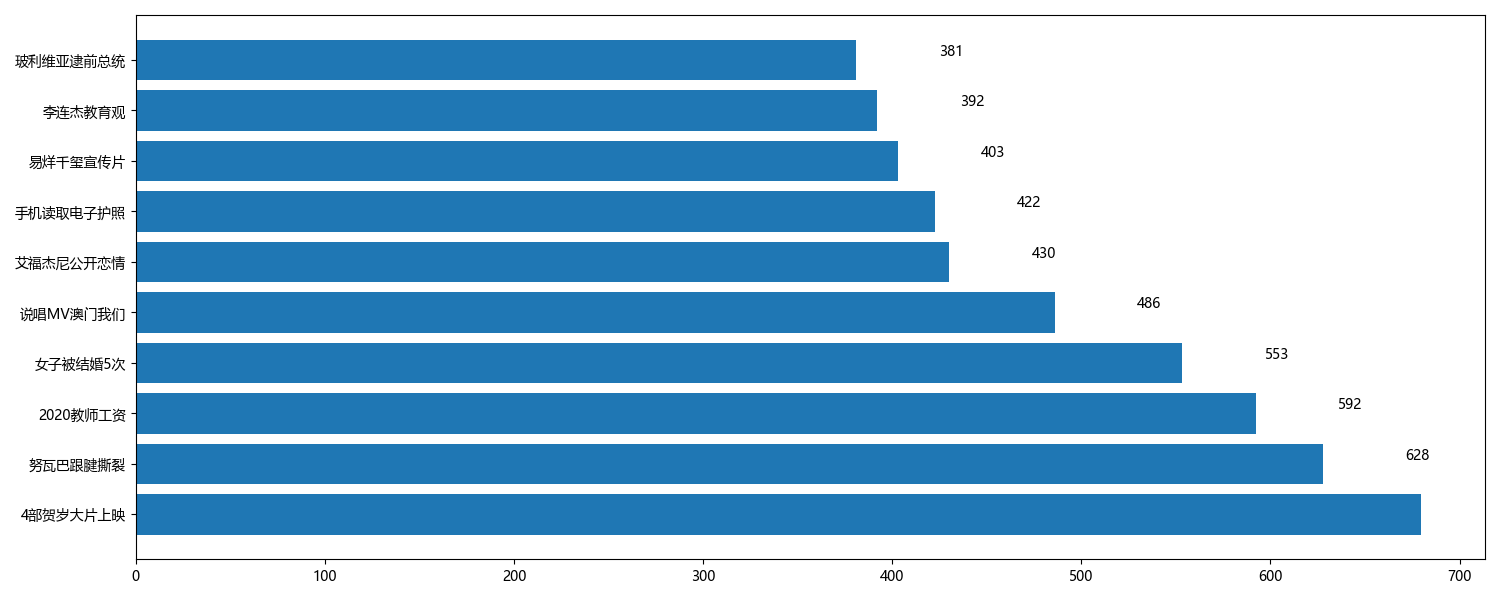
(1)各平台热度排行榜top10
根据个平台的热度进行排序,选取前10名画出横向柱形图。直观看出各平台当前最火的话题。
代码如下:
df = df.sort_values('handle_number', ascending=False) df= df.reset_index(drop=True) fig = plt.figure(figsize=(15, 6)) top10_df = df[:10] x = list(top10_df.index) y = list(top10_df['handle_number'].values) titles = list(top10_df['title'].values) plt.barh(titles, y) fig.tight_layout() for x_, y_, title in zip(x, y, titles): plt.text(y_+50 , title, '%.f' % y_, ha='center', va='bottom') plt.savefig('{}热度排行榜top10.png'.format(platform)) plt.close()
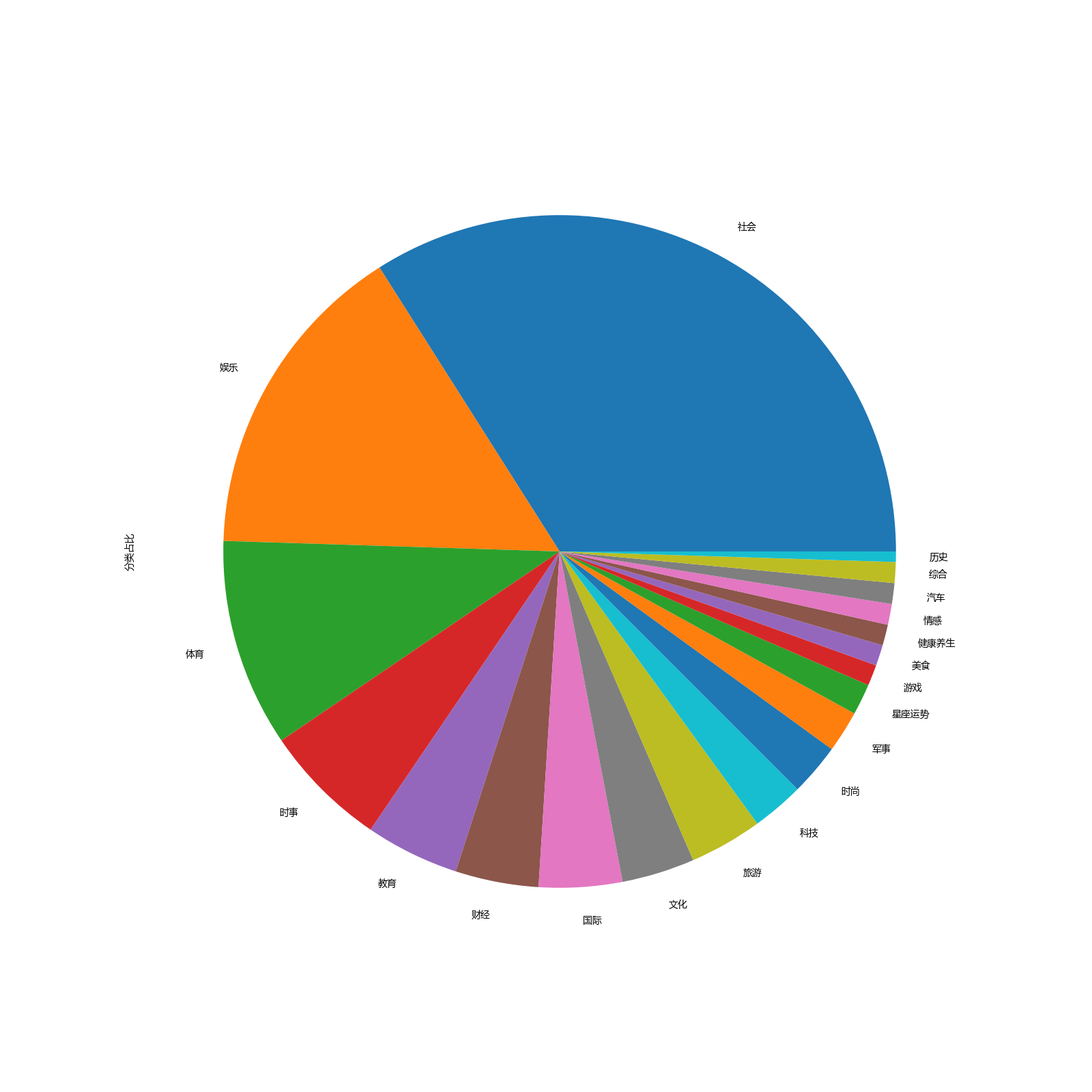
(2)各平台话题分类占比
统计各平台分类占比,对比每个平台对当今社会的侧重点在哪。
代码如下:
lv1_tag = df['lv1_tag'].value_counts(normalize=True) lv1_tag.plot.pie(subplots=True, figsize=(16, 16), label='分类占比') # autopct="%1.2f%%" plt.savefig('{}分类占比图.png'.format(platform)) plt.close()
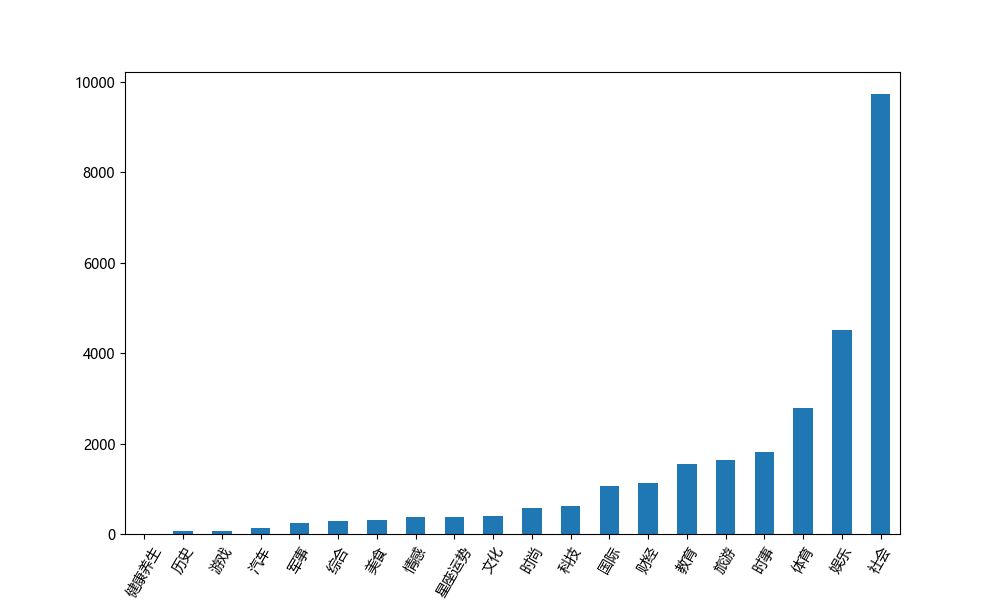
(3)各平台分类热度总值柱形图
使用pandas对各平台的话题分类进行分组计算热度总值,通过数据直观的看出各平台对当今社会的热点关注。
代码如下:
lv1_tag = df.groupby('lv1_tag')['handle_number'].sum() lv1_tag = lv1_tag.sort_values() lv1_tag.plot('bar', figsize=(10, 6)) plt.xticks(rotation=60) plt.savefig('{}分类热度图.png'.format(platform)) plt.close()
5.数据持久化
爬取数据和处理数据均使用csv保存
6.附完整程序代码
import requests from lxml import etree import pandas as pd ''' 网址:https://tophub.today/ 微博:https://tophub.today/n/KqndgxeLl9 知乎:https://tophub.today/n/mproPpoq6O 百度:https://tophub.today/n/Jb0vmloB1G ''' urls = { '微博': 'https://tophub.today/n/KqndgxeLl9', '知乎': 'https://tophub.today/n/mproPpoq6O', '百度': 'https://tophub.today/n/Jb0vmloB1G', } headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'cookie': 'UM_distinctid=16ef50dda3e9c1-0fe2c80daba785-2393f61-1fa400-16ef50dda3fa9a; Hm_lvt_3b1e939f6e789219d8629de8a519eab9=1576069363,1576902795; CNZZDATA1276310587=1873865941-1576066676-%7C1576904182; Hm_lpvt_3b1e939f6e789219d8629de8a519eab9=1576906643', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36' } for platform, url in urls.items(): data = [] response = requests.get(url, headers=headers) selectore = etree.HTML(response.text) tables = selectore.xpath('.//table[@class="table"]') for table in tables: trs = table.xpath('.//tr') for tr in trs: title = tr.xpath('./td[2]/a/text()')[0] number = tr.xpath('./td[3]/text()')[0] data.append([title, number]) df = pd.DataFrame(data, columns=['title', 'number']) df.to_csv('data/{}.csv'.format(platform), index=False) import json import time import re import pandas as pd from aip import AipNlp # """ 你的 APPID AK SK """ APP_ID = '11703996' API_KEY = '5TetNdgFFeWQxNbI8H4fZ8kq' SECRET_KEY = 'RWmPGTBdcStIiDMtb7GOGGB0PVXMCyce' """ 你的 APPID AK SK """ APP_ID = '' API_KEY = '' SECRET_KEY = '' client = AipNlp(APP_ID, API_KEY, SECRET_KEY) for platform in ['百度', '微博', '知乎']: df = pd.read_csv('data/{}.csv'.format(platform)) # total = df['handle_number'].sum() # df['popularity'] = [round(popularity/total*1000, 3) for popularity in baidu_df['popularity']] df['handle_number'] = 0.0 df['lv1_tag'] = '' for index, row in df.iterrows(): print(index) try: title = row['title'] number = row['number'] find = re.findall('\d+.?\d?', number) if find: df.loc[index, 'handle_number'] = float(find[0]) else: pass content = title * 20 """ 调用api """ topic_result = client.topic(title, content) lv1_tag_list = topic_result.get('item').get('lv1_tag_list') if lv1_tag_list: lv1_tag = lv1_tag_list[0].get('tag') df.loc[index, 'lv1_tag'] = lv1_tag except: pass df = df.sort_values('handle_number', ascending=False) df= df.reset_index(drop=True) df.to_csv('./handle_data/{}.csv'.format(platform), index=None) import jieba.analyse import pandas as pd import matplotlib.pyplot as plt from wordcloud import WordCloud import random # 中文乱码和坐标轴负号的处理 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False # df = None for platform in ['百度', '微博', '知乎']: df = pd.read_csv('./handle_data/{}.csv'.format(platform)) # 热度排行榜top10 df = df.sort_values('handle_number', ascending=False) df= df.reset_index(drop=True) fig = plt.figure(figsize=(15, 6)) top10_df = df[:10] x = list(top10_df.index) y = list(top10_df['handle_number'].values) titles = list(top10_df['title'].values) plt.barh(titles, y) fig.tight_layout() for x_, y_, title in zip(x, y, titles): plt.text(y_+50 , title, '%.f' % y_, ha='center', va='bottom') plt.savefig('{}热度排行榜top10.png'.format(platform)) plt.close() # 分类占比 lv1_tag = df['lv1_tag'].value_counts(normalize=True) lv1_tag.plot.pie(subplots=True, figsize=(16, 16), label='分类占比') # autopct="%1.2f%%" plt.savefig('{}分类占比图.png'.format(platform)) plt.close() # 分类热度 lv1_tag = df.groupby('lv1_tag')['handle_number'].sum() lv1_tag = lv1_tag.sort_values() lv1_tag.plot('bar', figsize=(10, 6)) plt.xticks(rotation=60) plt.savefig('{}分类热度图.png'.format(platform)) plt.close() # jieba词云 df.loc[:, 'title'] = df['title'].astype('str') content = list(df['title'].values) content = '。'.join(content) try: jieba.analyse.set_stop_words('./data/stopwords.txt') tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True) keywords = dict() for i in tags: keywords[i[0]]=i[1] wc = WordCloud( font_path='/usr/share/fonts/winfonts/simfang.ttf', background_color='White', max_words=1000, width=1000, height=500, #mask=graph, scale=1, ) wc.generate_from_frequencies(keywords)#按词出现的频率 wc.to_file("{}词云.jpg".format(platform)) finally: pass
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过分析可知,各平台的话题分类中,社会分类均占比最高,随后微博平台的话题偏娱乐,知乎平台的话题偏教育,百度平台偏娱乐和体育。
通过关键词可以,当前最火的关键词为考研, 微博热点词还有圣诞,李云迪,澳门等,百度的热点词还有唐一菲,道歉,国足等,知乎使用最多
的关键词为评价,看待,是知乎平台常用的问题当时,其次有腾讯,综艺,余年。各平台关注最多的还是社会时事,然后每个平台都有自己关注的
侧重点。
2.对本次程序设计任务完成的情况做一个简单的小结。
本次程序设计,主要学习了伪造headers头请求数据,使用xpath提取数据,对于没有规则的数据,还是需要使用最基础的正则去处理。
pandas和matplotlib主要用于处理,保存数据和画图,画图时对于如何显示出完整的观赏性较高的图片较有难度,比如话题文本较长时,
无法显示出来,就需要新建画图的时间,使用tight_layout进行自适应。


