
AtomicLong与LongAdder的区别
// unsafe对象
private static final Unsafe U = Unsafe.getUnsafe();
// 预期原值(用作cas)
private static final long VALUE
= U.objectFieldOffset(AtomicLong.class, "value");
// 初始值
private volatile long value;
- 用了Unsafe对象,主要用来调用unsafe方法
- 有一个预期原值VALUE,U.objectFieldOffset(AtomicLong.class, "value")来获取。用作CAS比较
看一下计算方法(unsafe类):
@IntrinsicCandidate public final long getAndAddLong(Object o, long offset, long delta) { long v; do { // 获取当前值 v = getLongVolatile(o, offset); // offset:预期原值 // v:当前值(实际的值) // v+delta:计算后的结果 // CAS,如果 offset == v,则表示 没有其他线程修改过,则把 计算后的值 赋值给 v,退出循环 // 如果 offset != v,表示其他线程改过,继续循环比较 } while (!weakCompareAndSetLong(o, offset, v, v + delta)); return v; }
所以AtomicLong的核心是:
1、volatile保证value的可见性、顺序性
2、cas来保证原子性
AtomicLong的问题:
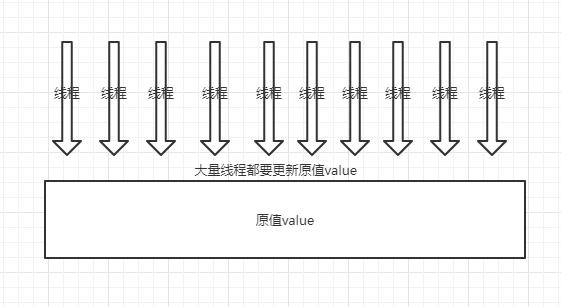
当存在大量线程同时修改 这个AtomicLong对象时,那么CAS方法会返回false,那么大量线程都会循环。
(线程数特别多,同时修改值时)这样会导致:循环次数大大提升,计算成功的效率就降低了,计算时间也变长了。
所以基于这个问题,java有了一个新的线程安全的计算类:LongAdder
2、LongAdder
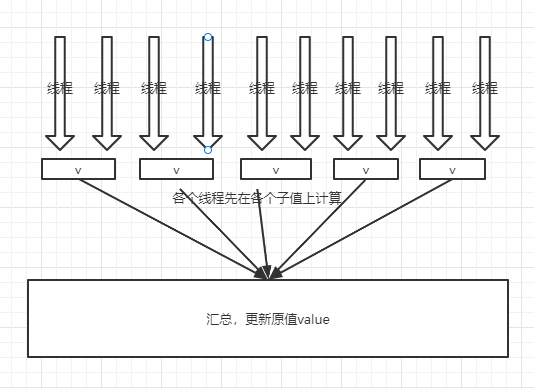
LongAdder的思路是:
- 如果一个值有很多线程同时计算
- 那我让各个线程,各自计算各自的值。
- 所有线程计算完成之后,再把所有计算结果再合并起来
- 这样就完成了最终的计算结果
1、当大量线程要更新原值时
2、各个线程先在各自的区间计算,在合并结果
首先看下主要的类成员:
/** * 单元格表。当非空时,大小是 2 的幂。 */ transient volatile Cell[] cells; /** * 基值,主要在没有争用时使用,但也可作为表初始化竞赛期间的后备。通过 CAS 更新。 */ transient volatile long base; /** * 调整大小和/或创建单元格时使用自旋锁(通过 CAS 锁定)。 */ transient volatile int cellsBusy;
这几个都是 父类:Striped64的成员变量
核心add方法:
public void add(long x) { Cell[] cs; long b, v; int m; Cell c; // 先判断cells是否非空 // 为空,则走casBase,在base上累加,cas操作,类似atomicLong if ((cs = cells) != null || !casBase(b = base, b + x)) { // 非空(cas失败、开始竞争),则通过cells来求和。if内容 // 当前线程应该操作哪一个cell的index int index = getProbe(); boolean uncontended = true; if (cs == null || (m = cs.length - 1) < 0 || (c = cs[index & m]) == null || // cas更新cell的值 !(uncontended = c.cas(v = c.value, v + x))) longAccumulate(x, null, uncontended, index); } }
这里可以看到:
- 先判断是否需要分区计算,不需要的话,直接用casBase,通过cas更新原值
- 否则就要 分区计算了
- 先计算此线程要计算哪一个分区值(cells是一个数组),获取此线程的index(hash),这样保证此线程每一次计算时,都更新 同一个cell
- 然后就是核心的longAccumulate方法(真正计算的业务逻辑:cells数组初始化和扩容都在这里,此方法有很多逻辑判断,这里忽略实现细节)
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended, int index) { if (index == 0) { ThreadLocalRandom.current(); // force initialization index = getProbe(); wasUncontended = true; } for (boolean collide = false;;) { // True if last slot nonempty Cell[] cs; Cell c; int n; long v; if ((cs = cells) != null && (n = cs.length) > 0) { if ((c = cs[(n - 1) & index]) == null) { if (cellsBusy == 0) { // Try to attach new Cell Cell r = new Cell(x); // Optimistically create if (cellsBusy == 0 && casCellsBusy()) { try { // Recheck under lock Cell[] rs; int m, j; if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & index] == null) { rs[j] = r; break; } } finally { cellsBusy = 0; } continue; // Slot is now non-empty } } collide = false; } else if (!wasUncontended) // CAS already known to fail wasUncontended = true; // Continue after rehash else if (c.cas(v = c.value, (fn == null) ? v + x : fn.applyAsLong(v, x))) break; else if (n >= NCPU || cells != cs) collide = false; // At max size or stale else if (!collide) collide = true; else if (cellsBusy == 0 && casCellsBusy()) { try { if (cells == cs) // Expand table unless stale cells = Arrays.copyOf(cs, n << 1); } finally { cellsBusy = 0; } collide = false; continue; // Retry with expanded table } index = advanceProbe(index); } else if (cellsBusy == 0 && cells == cs && casCellsBusy()) { try { // Initialize table if (cells == cs) { Cell[] rs = new Cell[2]; rs[index & 1] = new Cell(x); cells = rs; break; } } finally { cellsBusy = 0; } } // Fall back on using base else if (casBase(v = base, (fn == null) ? v + x : fn.applyAsLong(v, x))) break; } }
总结:
- longAddr通过分区的方式,将多线程分成多个区间,各自区间都计算自己的,这样大大减少了线程竞争。
- 当所有线程计算完了,再合并所有区间的结果,就得到真正的结果。
所以这样表明,longAdder在计算过程中,value值不是强一致的。他只保证了最终一致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号