
【CVPR2022】NFormer: Robust Person Re-identification with Neighbor Transformer
【CVPR2022】NFormer: Robust Person Re-identification with Neighbor Transformer

1、研究动机
这是一个来自 Amsterdam 大学 和 小红书 团队的工作。要解决的问题是:当前大多数工作是分析单张图片内部特征之间的关联关系,没有考虑图片与图片之间的 potential ineractions。
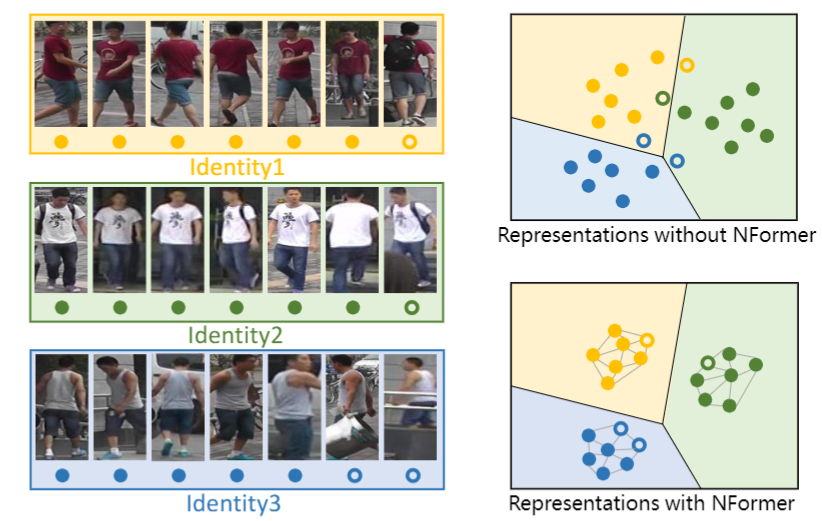
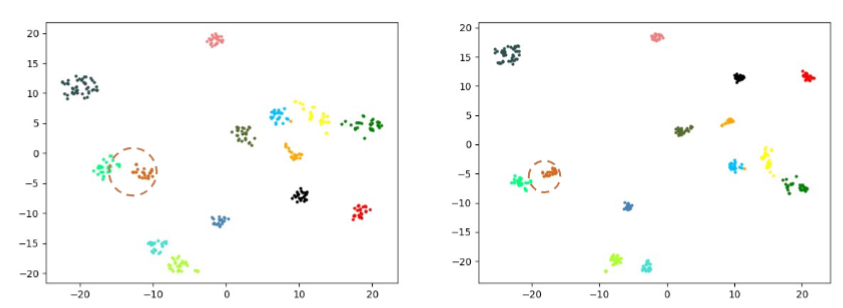
如下图所示,由于光照、遮挡、视角等因素,同一个类别的图片可能外观存在差异,导致outlier比较敏感(空心样本是因遮挡产生的ourlier,跑到别的类里了)。为此,作者提出了 Neighbor Transformer Network (NFormer),旨在建模所有输入图像之间的关系,可以看到所有类内部的联系更加紧密,outlier能够正确分类。
2、方法
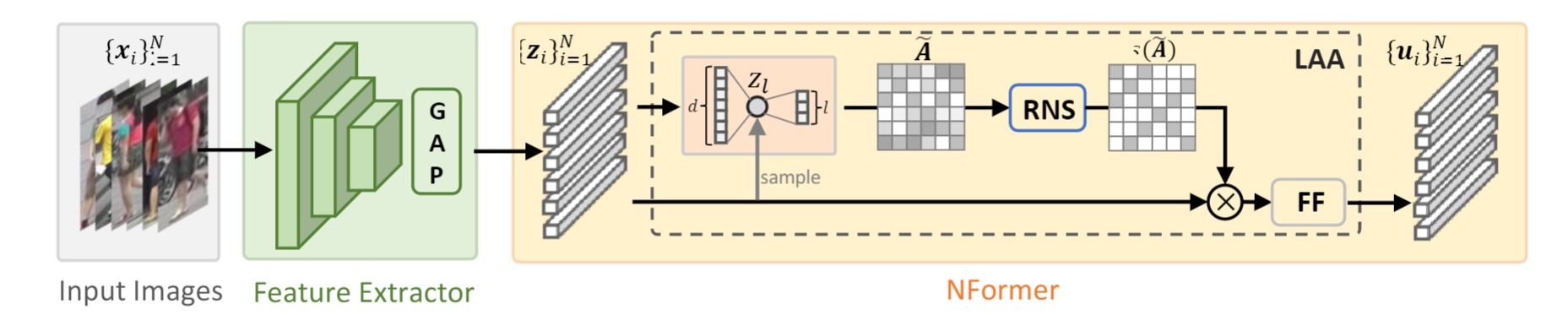
NFormer的框架如下图所示,比较关键的有两个部分:Landmark agent attention (LAA) 和 Reciprocal neighbor softmax (RNS)。
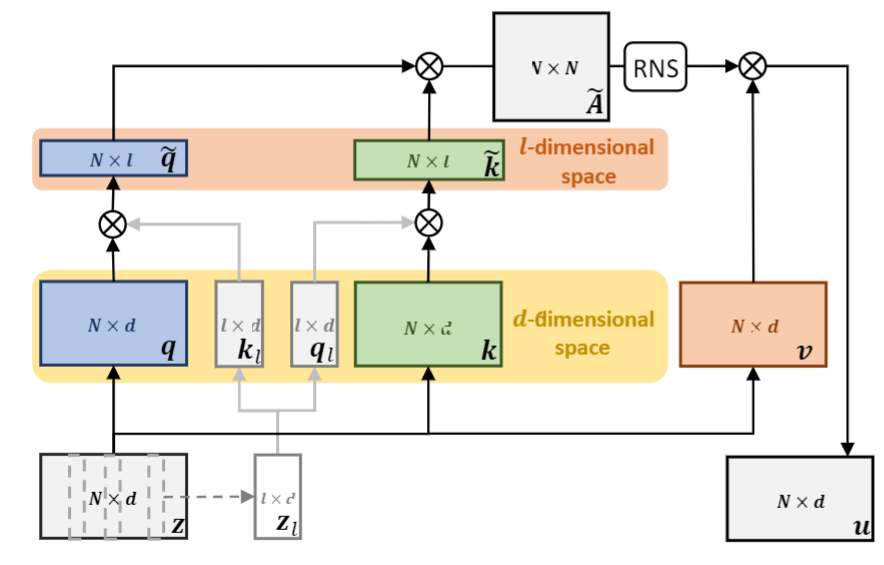
1、Landmark agent attention. 该模块如下图所示,在以前的 attention 计算中,需要将输入 \(z\) 变成 \(q,k,v\),然后在计算 \(q\) 和\(k\) 之间相似性时复杂度较高为 \(O(N^2d)\)。 为此,作者如下改进:(1)在输入 \(z\) 中随机采样 \(l\) 个样本得到 \(z^l\) ,然后生成 \(k_l\) 和 \(q_l\),这样特征就从 \(N\times d\) 降为 \(l\times d\)。将原始的 \(q\) 和 \(k\) 通过与 \(k_l\) 和 \(q_l\) 分别相乘,得到 \(\hat{q}\in \R^{N\times l}\) $\hat{k}\in \R^{N\times l} \(。(3)\)\hat{q}$ 和 \(\hat{k}\) 计算得到 NxN 的相似性矩阵。这样,和原来相比,复杂度就从 \(O(N^2d)\) 降低为 \(O(N^2l)\) 。在这个论文中, \(l=5\) , \(d=256\),是显著降低了计算量的。
2、Reciprocal neighbor softmax. 原始的softmax计算是聚合所有的样本,但是不相关样本的显著存在会对最终计算产生负面影响。
假设如果两幅图像在特征空间中互为邻域,则它们很可能是相关的。为此,作者建议从矩阵 A 中进行如下计算:
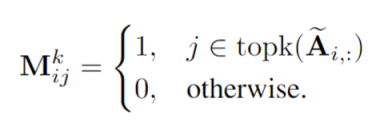
意思就是 A矩阵中每行 attention weights 前 k 个最大的置为1,其余的置为 0。然后使用下面计算生成一个 mask:
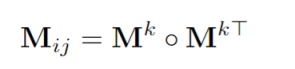
在计算 Softmax 时候,把 M 乘在前面,如下:
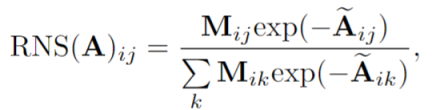
需要注意的是,可以从作者的代码看到,在测试阶段使用的是torch的稀疏矩阵,这样在计算softmax以及矩阵乘时不需要考虑非0的位置,可以降低复杂度,但是在训练阶段则是dense的矩阵乘法,貌似并没有降低复杂度。
if self.training:
w = w * mask + -1e9 * (1 - mask)
w = F.softmax(w,dim=3)
a_v = torch.matmul(w, v)
else:
w = (w * mask).reshape(bs*hn,dl,dl).to_sparse()
w = torch.sparse.softmax(w,2)
v = v.reshape(bs*hn,dl,-1)
a_v = torch.bmm(w,v).reshape(bs,hn,dl,-1)
3、实验分析
作者使用ResNet50提取特征,将特征降为256。在LAA中,landmark agent数量设置为5。同时,RNS 中 neighbor 的数量设置为 20。
下图是特征可视化的结果,(a)、(b)分别为with / without NFormer,结论是:We observe better feature discriminability for the NFormer, while the outliers of each identity are significantly constrained because the relevant and common information of neighbors is integrated into each data point. We conclude that NFormer learns relations between input persons not only effectively but also efficiently.
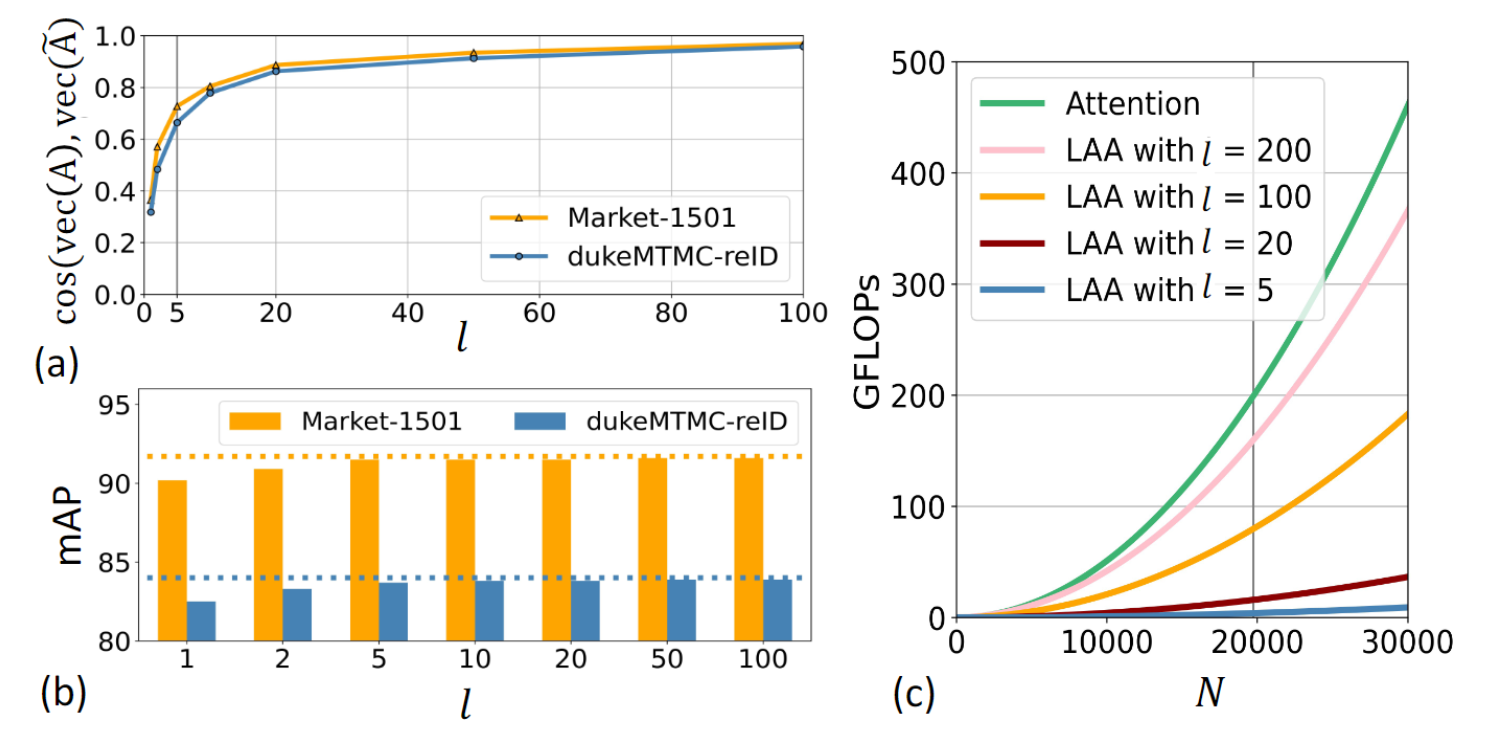
下图展示了landmark agent数量的实验。图(a)中展示,即使只使用较小的 agent,矩阵A和\hat{A} 仍然非常接近。图(b)表示,使用5个agent时,准确率就比较高了。图(c)表示,使用更多agent时,计算量会显著增加。
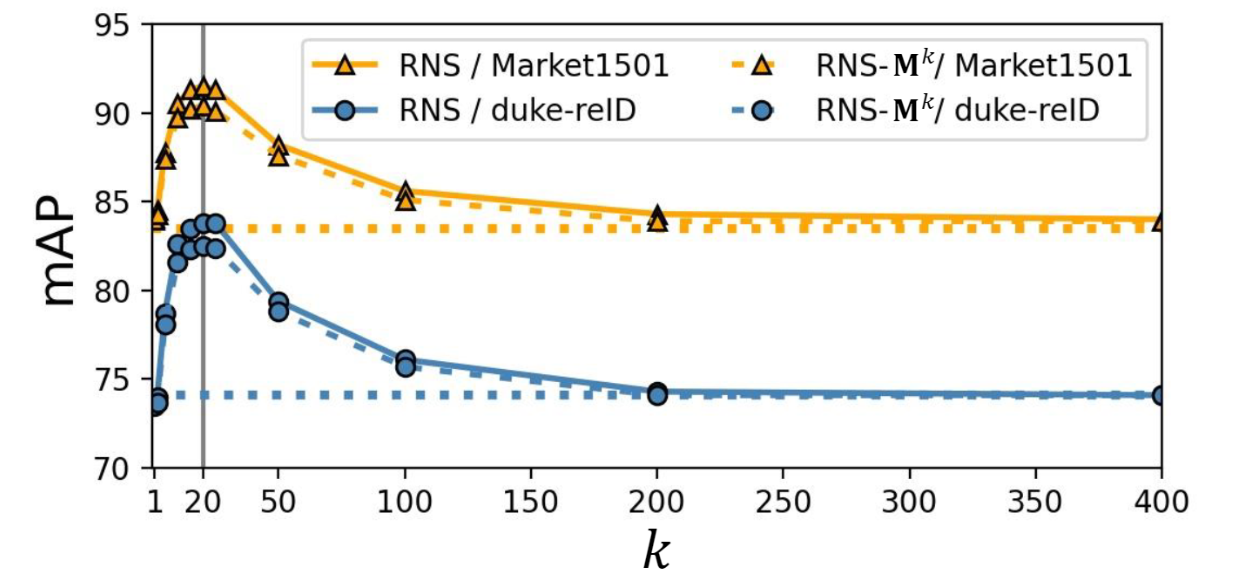
下图展示了 RNS 中使用 neighbor 数量的分析。可以看到在20左右取得最高值,后面 AP 会下降。作者解释是:more neighbors information benefits the aggregation of the individual representations in the early stage. Then as k continues to increase, the performance gradually decreases because of the introduction of irrelevant interactions.
其它实验可以参考作者论文,这里不再过多介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号