摘要: 一、前言在MSDN上看到一篇关于SQL Server 表分区的文档:已分区索引的特殊指导原则,如果你对表分区没有实战经验的话是比较难理解文档里面描述的意思。这里我就里面的一些概念进行讲解,方便大家的交流。SQL Server 解读【已分区索引的特殊指导原则】(1)- 索引对齐SQL Server 解读【已分区索引的特殊指导原则】(2)- 唯一索引分区二、解读【对非聚集索引进行分区】“对唯一的非聚集索引进行分区时,索引键必须包含分区依据列。对非唯一的非聚集索引进行分区时 阅读全文
一、前言在MSDN上看到一篇关于SQL Server 表分区的文档:已分区索引的特殊指导原则,如果你对表分区没有实战经验的话是比较难理解文档里面描述的意思。这里我就里面的一些概念进行讲解,方便大家的交流。SQL Server 解读【已分区索引的特殊指导原则】(1)- 索引对齐SQL Server 解读【已分区索引的特殊指导原则】(2)- 唯一索引分区二、解读【对非聚集索引进行分区】“对唯一的非聚集索引进行分区时,索引键必须包含分区依据列。对非唯一的非聚集索引进行分区时 阅读全文
SQL Server 解读【已分区索引的特殊指导原则】(2)- 唯一索引分区
2013-07-26 14:52 by 听风吹雨, 2193 阅读, 0 推荐, 收藏, 编辑
摘要:
一、前言在MSDN上看到一篇关于SQL Server 表分区的文档:已分区索引的特殊指导原则,如果你对表分区没有实战经验的话是比较难理解文档里面描述的意思。这里我就里面的一些概念进行讲解,方便大家的交流。SQL Server 解读【已分区索引的特殊指导原则】(1)二、解读【对唯一索引进行分区】“对唯一索引(聚集或非聚集)进行分区时,必须从唯一索引键使用的分区依据列中选择分区依据列。此限制将使 SQL Server 只调查单个分区,以确保表中不存在重复的新键值。 阅读全文
SQL Server 解读【已分区索引的特殊指导原则】(1)- 索引对齐
2013-07-25 16:51 by 听风吹雨, 4821 阅读, 5 推荐, 收藏, 编辑
摘要: 一、前言在MSDN上看到一篇关于SQL Server 表分区的文档:已分区索引的特殊指导原则,如果你对表分区没有实战经验的话是比较难理解文档里面描述的意思。这里我就里面的一些概念进行讲解,方便大家的交流。(Figure0:索引与基表对齐)二、解读“索引要与其基表对齐,并不需要与基表参与相同的命名分区函数。但是,索引和基表的分区函数在实质上必须相同,即:1) 分区函数的参数具有相同的数据类型;2) 分区函数定义了相同数目的分区;3) 分区函数为分区定义了相同的边界值。 阅读全文
一、前言在MSDN上看到一篇关于SQL Server 表分区的文档:已分区索引的特殊指导原则,如果你对表分区没有实战经验的话是比较难理解文档里面描述的意思。这里我就里面的一些概念进行讲解,方便大家的交流。(Figure0:索引与基表对齐)二、解读“索引要与其基表对齐,并不需要与基表参与相同的命名分区函数。但是,索引和基表的分区函数在实质上必须相同,即:1) 分区函数的参数具有相同的数据类型;2) 分区函数定义了相同数目的分区;3) 分区函数为分区定义了相同的边界值。 阅读全文
一、前言在MSDN上看到一篇关于SQL Server 表分区的文档:已分区索引的特殊指导原则,如果你对表分区没有实战经验的话是比较难理解文档里面描述的意思。这里我就里面的一些概念进行讲解,方便大家的交流。(Figure0:索引与基表对齐)二、解读“索引要与其基表对齐,并不需要与基表参与相同的命名分区函数。但是,索引和基表的分区函数在实质上必须相同,即:1) 分区函数的参数具有相同的数据类型;2) 分区函数定义了相同数目的分区;3) 分区函数为分区定义了相同的边界值。 阅读全文
SQL Server 错误日志过滤(ERRORLOG)
2013-06-24 15:54 by 听风吹雨, 19366 阅读, 8 推荐, 收藏, 编辑
摘要:一、背景 有一天我发现SQL Server服务器的错误日志中包括非常多关于sa用户的登陆错误信息:“Login failed for user 'sa'. 原因: 评估密码时出错。[客户端: XX.XX.XX.XX]”。可是我很久之前就已经禁用了sa用户,怎么还会有那么多的sa用户登陆信息呢?我猜... 阅读全文
SQL Server 错误日志收缩(ERRORLOG)
2013-06-24 15:15 by 听风吹雨, 5133 阅读, 1 推荐, 收藏, 编辑
摘要:一、基础知识默认情况下,错误日志位于 :C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\LOG\ERRORLOG和ERRORLOG.n 文件中。默认保留有7个 SQL Server 错误日志文件,分别是:ErrorLog,Errorlog.1~Errorlog.6 ,当前的错误日志(文件ErrorLog)没有扩展名。每当启动 SQL Server 实例时,将创建新的错误日志ErrorLog,并将之前的ErrorLog更名为ErrorLog.1,之前的ErrorLog.1更名为ErrorLog.2,依次类推,原先的ErroLog.6被删除。 阅读全文
SQL Server 限制IP登陆(登陆触发器运用)
2013-05-23 16:51 by 听风吹雨, 30414 阅读, 11 推荐, 收藏, 编辑
摘要: 一、背景在MySQL的mysql.User表保存了登陆用户的权限信息,Host和User字段则是关于登陆IP的限制。但是在SQL Server没有这样一个表,那SQL Server有什么办法可以实现类似的安全控制的功能呢?SQL Server 包括三种常规类型的触发器:DML触发器、DDL触发器和登录触发器。DML触发器是比较常使用的,它通常在表或视图中修改数据(INSERT、UPDATE和DELETE 等)为了保证业务数据的完整性和一致性,可以对事务进行回滚等操作;如果你对DDL触发器感兴趣,可以参考:SQL Server DDL触发器运用 阅读全文
一、背景在MySQL的mysql.User表保存了登陆用户的权限信息,Host和User字段则是关于登陆IP的限制。但是在SQL Server没有这样一个表,那SQL Server有什么办法可以实现类似的安全控制的功能呢?SQL Server 包括三种常规类型的触发器:DML触发器、DDL触发器和登录触发器。DML触发器是比较常使用的,它通常在表或视图中修改数据(INSERT、UPDATE和DELETE 等)为了保证业务数据的完整性和一致性,可以对事务进行回滚等操作;如果你对DDL触发器感兴趣,可以参考:SQL Server DDL触发器运用 阅读全文
SQL Server 游标运用:查看所有数据库所有表大小信息(Sizes of All Tables in All Database)
2013-05-08 15:32 by 听风吹雨, 7156 阅读, 6 推荐, 收藏, 编辑
摘要:
之前写了篇关于:SQL Server 游标运用:查看一个数据库所有表大小信息(Sizes of All Tables in a Database)的文章,它罗列出某个数据所有表的信息,这些信息包括:表的记录数、数据记录占用空间、索引占用空间、没使用的空间等(如Figure1所示),现在我来讲述如何获取整个数据库实例中所有数据库所有表的信息(如Figure2所示)。
下面内容讲述了在实现Figure2过程中遇到的一些问题,如果你对这些问题不感兴趣可以直接看最后实现的SQL脚本。下面讲述了4种实现方法: 阅读全文
SQL Server 游标运用:查看一个数据库所有表大小信息(Sizes of All Tables in a Database)
2013-05-07 12:09 by 听风吹雨, 4175 阅读, 3 推荐, 收藏, 编辑
摘要:
一、背景在性能调优或者需要了解某数据库表信息的时候,最直观的方式就是罗列出这个数据所有表的信息,这些信息包括:表的记录数、数据记录占用空间、索引占用空间、未使用的空间等(如Figure1所示),有了这些信息你可以简单的判断这个数据库来自数据上的压力可能是某个表造成的。因为表数据越大,对数据库性能的影响越大。要实现某个数据库所有表的信息,可以通过游标的形式获取相应的数据,下图Figure1返回某数据库中所有表的信息:(Figure1:某数据库所有表信息)也许你并不满足于Figure1的信息,你希望获取整个数据库实例中所有数据库所有表的信息(如Figure2所示) 阅读全文
SQL Server 重置Identity标识列的值(INT爆了)
2013-04-23 17:45 by 听风吹雨, 27646 阅读, 9 推荐, 收藏, 编辑
摘要:一、背景 SQL Server数据库中表A中Id字段的定义是:[Id] [int] IDENTITY(1,1),随着数据的不断增长,Id值已经接近2147483647(int的取值范围为:-2 147 483 648 到 2 147 483 647)了,虽然已经对旧数据进行归档,但是这个表需要保留最近的1亿数据,有什么方法解决Id值就快爆的问题呢? 解决上面的问题有两个办法:一个是修改表结构,把Id的int数据类型修改为bigint;第二个是重置Id(Identity标识列)的值,使它重新增长。 当前标识值:current identity value,用于记录和保存最后一次系统分配的I... 阅读全文
MySQL表数据迁移自动化
2013-03-15 17:36 by 听风吹雨, 17782 阅读, 6 推荐, 收藏, 编辑
摘要: 一、背景之前我写过关于SQL Server的数据迁移自动化的文章:SQL Server 数据库迁移偏方,在上篇文章中设计了一张临时表,这个临时表记录搬迁的配置信息,用一个存储过程读取这张表进行数据的迁移,再由一个Job进行迭代调用这个存储过程。在这次MySQL的实战中,我的数据库已经做了4个分片,分布在不同的4台机器上,每台机器上的数据量有1.7亿(1.7*4=6.8亿),占用空间260G(260*4=1040G),这次迁移的目的就是删除掉一些历史记录,减轻数据库压力,有人说这为什么不使用表分区呢? 阅读全文
一、背景之前我写过关于SQL Server的数据迁移自动化的文章:SQL Server 数据库迁移偏方,在上篇文章中设计了一张临时表,这个临时表记录搬迁的配置信息,用一个存储过程读取这张表进行数据的迁移,再由一个Job进行迭代调用这个存储过程。在这次MySQL的实战中,我的数据库已经做了4个分片,分布在不同的4台机器上,每台机器上的数据量有1.7亿(1.7*4=6.8亿),占用空间260G(260*4=1040G),这次迁移的目的就是删除掉一些历史记录,减轻数据库压力,有人说这为什么不使用表分区呢? 阅读全文
Ubuntu12下挂载硬盘(9TB)(文章索引)
2013-02-16 17:41 by 听风吹雨, 1439 阅读, 0 推荐, 收藏, 编辑
摘要: 前言在linux下挂载硬盘,很多人说使用mount,但是这个是挂载一个硬盘,如果想让服务器可以把硬盘都挂载到同一个目录下,mount是无法实现的,但是很多应用都有某个目录的空间足够大。下面的文章就是一步步教你怎么挂载的。实战说明经过实战,已经成功挂载了9TB的空间。(Figure:磁盘信息)
系列文章索引Step1:Ubuntu12下挂载硬盘(9TB)Step2:Ubuntu12下未知驱动器处理 Step3:Ubuntu12下重新挂载硬盘 阅读全文
前言在linux下挂载硬盘,很多人说使用mount,但是这个是挂载一个硬盘,如果想让服务器可以把硬盘都挂载到同一个目录下,mount是无法实现的,但是很多应用都有某个目录的空间足够大。下面的文章就是一步步教你怎么挂载的。实战说明经过实战,已经成功挂载了9TB的空间。(Figure:磁盘信息)
系列文章索引Step1:Ubuntu12下挂载硬盘(9TB)Step2:Ubuntu12下未知驱动器处理 Step3:Ubuntu12下重新挂载硬盘 阅读全文
Ubuntu12下未知驱动器处理
2013-02-16 14:32 by 听风吹雨, 534 阅读, 0 推荐, 收藏, 编辑
摘要:
一、背景在挂载大硬盘(Ubuntu12下挂载硬盘(9TB))的过程出现了错误导致下图的错误:Ubuntu下使用pvdisplay命令发现有未知驱动器的信息:Couldn’t find device with uuid ‘xxxxxxxxxxxxx’,如下图所示:(图1:unknown device)如果出现上面的错误,是没有办法按照Ubuntu12下挂载硬盘(9TB)的步骤进行挂载的,如果想要挂载成功,首先要解决这个问题,把不认识的驱动盘remove掉。二、解决过程使用命令:vgreduce --removemissing barfoo18,执行的结果如下图所示:(图2:remove)三、参考 阅读全文
Ubuntu12下挂载存储柜硬盘
2013-02-16 13:48 by 听风吹雨, 4804 阅读, 0 推荐, 收藏, 编辑
摘要:一、背景在Ubuntu12下挂载硬盘(9TB)和Ubuntu12下重新挂载硬盘文章中我已经描述过挂载硬盘的操作方法,那么这次的又有什么不同呢?上两篇文章中的物理硬盘都是直接挂载服务器的,但是这次的是连接存储柜上的硬盘,按照之前的方法出错了,本文就是告诉你如何解决这个问题。二、挂载过程别看标题写着的是存储柜就觉得要解决这个问题会很复杂,其实一开始我上网找了下,也没有类似的文章,但是后来发现,其实挂载存储柜的硬盘跟挂载虚拟机上的硬盘点类似。所以问题变得简单了。一开始的时候,我使用了mkfs.ext4进行格式化的时候出现了Figure 2的错误信息(Figure 1:sd信息)(Figure 2:出 阅读全文
Ubuntu12下挂载硬盘(9TB)Shell版
2013-02-04 17:35 by 听风吹雨, 1424 阅读, 1 推荐, 收藏, 编辑
摘要:一、背景我们的服务器上安装了Ubuntu Server 12.04版本,由于开发环境的问题,所以没有上CenteOS或者Red Hat,我们有几块大的硬盘,需要通通挂载到root目录下,这个挂载的方式跟Windows是不太一样的。单台机器的挂载方法可以参考:Ubuntu12下挂载硬盘(9TB),如果我们需要安装N台机器的话,我们有什么好的办法呢?难道要一台一台的安装不成?不,这个时候Shell可以帮助你。二、挂载详细命令1. 先查看一下磁盘信息ls /dev/sd*/dev/sda /dev/sda2 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf/d 阅读全文
MySQL当批量插入遇上唯一索引
2013-01-04 11:48 by 听风吹雨, 17179 阅读, 4 推荐, 收藏, 编辑
摘要:
一、背景以前使用SQL Server进行表分区的时候就碰到很多关于唯一索引的问题:Step8:SQL Server 当表分区遇上唯一约束,没想到在MySQL的分区中一样会遇到这样的问题:MySQL表分区实战。今天我们来了解MySQL唯一索引的一些知识:包括如何创建,如何批量插入,还有一些技巧上SQL;这些问题的根源在什么地方?有什么共同点?MySQL中也有分区对齐的概念?唯一索引是在很多系统中都会出现的要求,有什么办法可以避免?它对性能的影响有多大? 阅读全文
MySQL定时器Events
2012-12-24 17:11 by 听风吹雨, 37126 阅读, 4 推荐, 收藏, 编辑
摘要:
一、背景我们MySQL的表A的数据量已经达到1.6亿,由于一些历史原因,需要把表A的数据转移到一个新表B,但是因为这是线上产品,所以宕机时间需要尽量的短,在不影响数据持续入库的情况下,我希望能通过作业(定时器Events)的形式慢慢搬迁这些数据。在MySQL作业的执行过程中有一个问题是让人比较郁闷的,就是如果频率很快,快到作业还没有执行完成的话,作业就会被重复执行,这点跟SQL Server的不一样的,如果想达到类似SQL Server作业的串行效果,只有当作业执行完毕 阅读全文
Ubuntu10下MySQL搭建Amoeba_读写分离+分片
2012-12-03 10:35 by 听风吹雨, 2779 阅读, 3 推荐, 收藏, 编辑
摘要:一、背景知识之前已经写了一篇关于Amoeba读写分离:Ubuntu10下MySQL搭建Amoeba_读写分离,上篇文章只是简单的测试下搭建读写分离,这里再加上一点的内容,在读写分离的基础上再加入分片。阅读本篇文章之前建议你先阅读:Ubuntu10下MySQL搭建Master/SlaveUbuntu10下搭建MySQL Proxy读写分离测试内容:把数据分片到Master1与Master2,再由Master1同步到Slave1,Master2同步到Slave2,把对数据的读取分布到Slave1和Slave2。二、搭建过程(一)测试环境Amoeba for MySQL:192.168.1.147M 阅读全文
SQL Server 磁盘空间告急(磁盘扩容)
2012-11-27 10:00 by 听风吹雨, 16704 阅读, 10 推荐, 收藏, 编辑
摘要: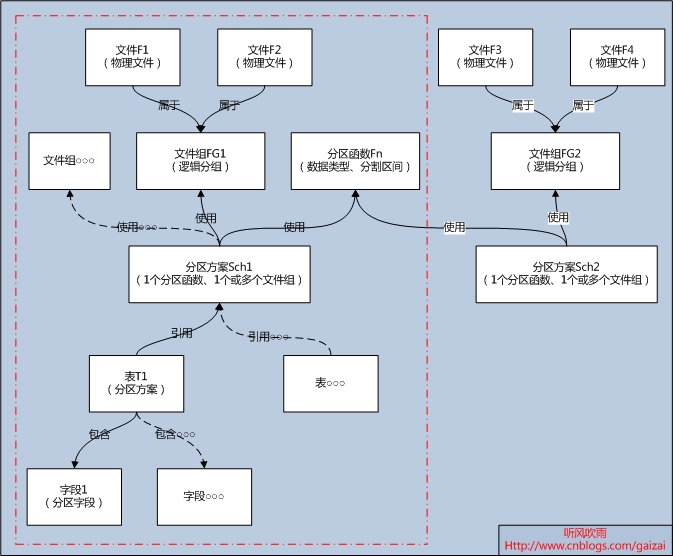 一、背景在线上系统中,如果我们发现存放数据库文件的磁盘空间不够,我们应该怎么办呢?新买一个硬盘挂载上去可以嘛?(linux下可以直接挂载硬盘进行扩容),但是我们的SQL Server是运行在Windows下的,有什么办法可以解决这燃眉之急呢?有两种方法可以解决上面的问题:第一种就是把数据库磁盘转换为【动态磁盘】,新增新的磁盘就可以解决了;第二种就是我今天要讲述的,使用SQL Server在其它磁盘(或者逻辑分区)中添加新的文件,添加完成后,SQL Server马上就能进新的数据了 阅读全文
一、背景在线上系统中,如果我们发现存放数据库文件的磁盘空间不够,我们应该怎么办呢?新买一个硬盘挂载上去可以嘛?(linux下可以直接挂载硬盘进行扩容),但是我们的SQL Server是运行在Windows下的,有什么办法可以解决这燃眉之急呢?有两种方法可以解决上面的问题:第一种就是把数据库磁盘转换为【动态磁盘】,新增新的磁盘就可以解决了;第二种就是我今天要讲述的,使用SQL Server在其它磁盘(或者逻辑分区)中添加新的文件,添加完成后,SQL Server马上就能进新的数据了 阅读全文
一、背景在线上系统中,如果我们发现存放数据库文件的磁盘空间不够,我们应该怎么办呢?新买一个硬盘挂载上去可以嘛?(linux下可以直接挂载硬盘进行扩容),但是我们的SQL Server是运行在Windows下的,有什么办法可以解决这燃眉之急呢?有两种方法可以解决上面的问题:第一种就是把数据库磁盘转换为【动态磁盘】,新增新的磁盘就可以解决了;第二种就是我今天要讲述的,使用SQL Server在其它磁盘(或者逻辑分区)中添加新的文件,添加完成后,SQL Server马上就能进新的数据了 阅读全文
Ubuntu10下搭建MySQL Proxy读写分离
2012-11-21 15:42 by 听风吹雨, 6733 阅读, 5 推荐, 收藏, 编辑
摘要: MySQL Proxy是一个处于你的Client端和MySQL server端之间的简单程序,它可以监测、分析或改变它们的通信。它使用灵活,没有限制,常见的用途包括:负载平衡,故障、查询分析,查询过滤和修改等等。
(Figure1:MySQL Proxy)
MySQL-Proxy, announced in June, is a binary application that sits between your MySQL client and server, and supports the embedded scripting language Lua. The proxy can be used to analy 阅读全文
MySQL Proxy是一个处于你的Client端和MySQL server端之间的简单程序,它可以监测、分析或改变它们的通信。它使用灵活,没有限制,常见的用途包括:负载平衡,故障、查询分析,查询过滤和修改等等。
(Figure1:MySQL Proxy)
MySQL-Proxy, announced in June, is a binary application that sits between your MySQL client and server, and supports the embedded scripting language Lua. The proxy can be used to analy 阅读全文
MySQL Proxy是一个处于你的Client端和MySQL server端之间的简单程序,它可以监测、分析或改变它们的通信。它使用灵活,没有限制,常见的用途包括:负载平衡,故障、查询分析,查询过滤和修改等等。
(Figure1:MySQL Proxy)
MySQL-Proxy, announced in June, is a binary application that sits between your MySQL client and server, and supports the embedded scripting language Lua. The proxy can be used to analy 阅读全文
Ubuntu10下MySQL搭建Amoeba_读写分离
2012-11-16 18:23 by 听风吹雨, 2584 阅读, 2 推荐, 收藏, 编辑
摘要:一、背景知识Amoeba(变形虫)项目,专注 分布式数据库 proxy 开发。座落与Client、DB Server(s)之间。对客户端透明。具有负载均衡、高可用性、sql过滤、读写分离、可路由相关的query到目标数据库、可并发请求多台数据库合并结果。要想搭建Amoeba读写分离,首先需要知道MySQL的主从配置,可参考:Ubuntu10下MySQL搭建Master/Slave,更好的情况下是你还需要了解MySQL-Proxy,可参考:Ubuntu10下搭建MySQL Proxy读写分离二、搭建过程(一)测试环境Amoeba for MySQL:192.168.1.147Master:192 阅读全文