web scraper 抓取数据并做简单数据分析
其实 web scraper 说到底就是那点儿东西,所有的网站都是大同小异,但是都还不同。这也是好多同学总是遇到问题的原因。因为没有统一的模板可用,需要理解了 web scraper 的原理并且对目标网站加以分析才可以。
今天再介绍一篇关于 web scraper 抓取数据的文章,除了 web scraper 的使用方式外,还包括一些简单的数据处理和分析。都是基础的不能再基础了。
选择这个网站一来是因为作为一个开发者在上面买了不少课,还有个原因就是它的专栏也比较有特点,需要先滚动加载,然后再点击按钮加载。
开始正式的数据抓取工作之前,先来看一下我的成果,我把抓取到的90多个专栏的订阅数和销售总价做了一个排序,然后把 TOP 10 拿出来做了一个柱状图出来。

抓取数据
今天要抓的这个网站是一个 IT 知识付费社区,极客时间,应该互联网圈的大多数同学都听说过,我还在上面买了 9 门课,虽然没怎么看过。
极客时间的首页会列出所有网课,和简书首页的加载方式一样,都是先滚动下拉加载,之后变为点击加载更多按钮加载更多。这是一种典型网站加载方式,有好多的网站都是两种方式结合的。这就给我们用 web scraper 抓数据制造了一定的麻烦,不过也很好解决。
1、创建 sitemap,设置 start url 为 https://time.geekbang.org/。
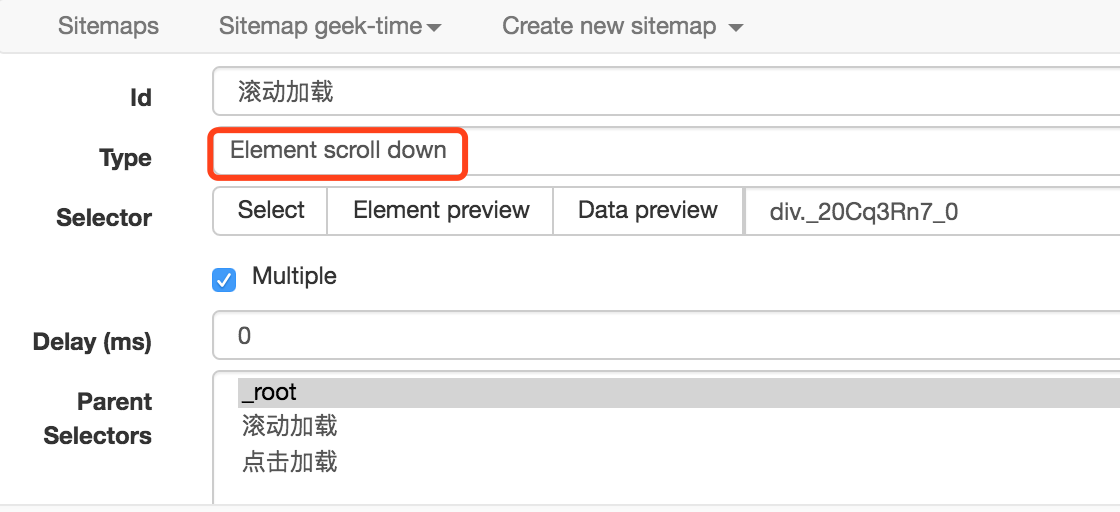
2、创建滚动加载的 Selector,这只是个辅助,帮助我们把页面加载到出现点击加载更多按钮出现,设置如下,注意类型选择 Element scroll down,选择整个课程列表区域作为 Element。
3、创建点击加载更多按钮的 Selector,这个才是真正要抓取内容的 Selector。之后会在它下面创建子选择器。创建之前,需要下拉记载页面,直到出现加载更多按钮。

首先选择元素类型为 Element click 。
Selector 选择整个课程列表,并设置为 Multiple。
Click 选择加载更多按钮,这里需要注意一点,之前的文章里也提到过,这个按钮没办法直接点击选中,因为点击后会触发页面加载动作,所以要勾选 Enable key events,然后按 S 键,来选中这个按钮。
Click type 设置为 Click more 类型。
Click element uniqueness 设置 unique CSS Selector。
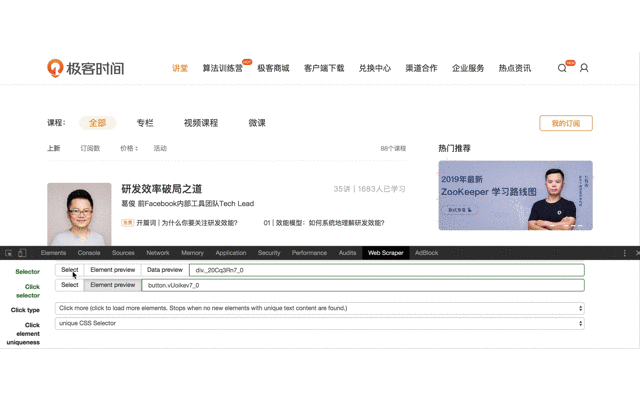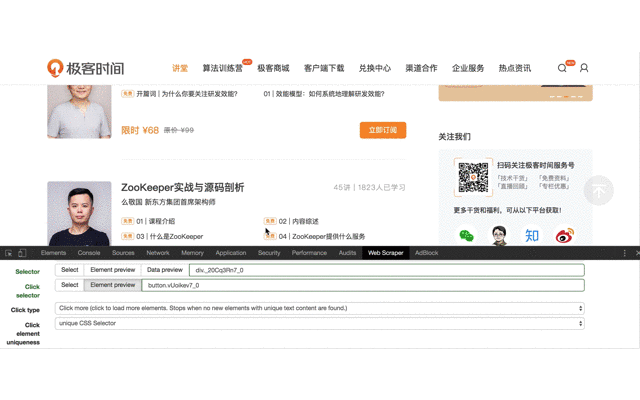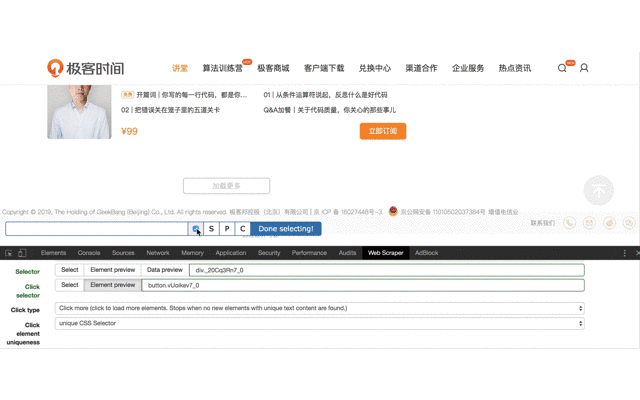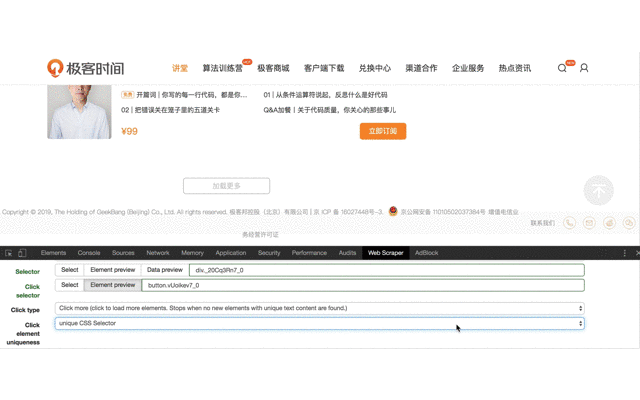
4、进入上一步创建的 Selector ,创建子选择器,用来抓取最终需要的内容。

5、最后运行抓取就可以啦。
数据清洗
这里只是很简单的演示,真正的大数据量的数据清洗工作要费力耗时的多。而且也远不止一个 Excel 能完成的,还需要程序代码的配合,大多数时候还会用到数据库,当然对于比较简单的数据或者没有开发经验的同学来说,用 Excel 也就是最简单省事的选择了。
打开 csv 文件后,第一列信息是 web scraper 自动生成的,直接删掉即可。不知道什么原因,有几条重复数据,第一步,先把重复项去掉,进入 Excel 「数据」选项卡,点击删除重复项即可。
第二步,由于抓下来的课时和报名人数在同一个元素下,没办法在 web scraper 直接放到两个列,所以只能到 Excel 中处理。我的操作思路是这样的,先复制一列出来,然后利用内容替换的方式,将其中一列的报名人数替换成空字符,替换的表达式为 讲 | *人已学习,这样此列就变成了课时列。将另外一列的课时替换为空字符串,先替换 x讲,替换内容为*讲 | ,然后再替换人已学习, 那么这列就变成了报名人数列。价格就只保留当前价格,删掉无用列,并且处理掉限时、拼团、¥这些无用字符。
数据分析
因为这里抓取的数据比较简单,也没指望能分析出什么结果。 一共90几门课,也就是分析分析哪门课最受欢迎、价格最高。直接在 Excel 里排个序就好了。然后计算一下几门课程的总价格。
当然真正的商业数据分析不仅仅是一个 Excel 画个图就搞定的事儿。也不是弄两个柱状图就可以的了,一般都需要多个维度、数据关联分析、深度挖掘等。
在 Excel 中做了两个柱状图,分别统计订阅人数前十名和总销售金额的前十名。下面是最后的呈现效果。

如果不想用 Excel, 有一些在线的图表制作网站也可以将 Excel 上传做一些基本的图表,但是灵活性稍微差一点。我用了「图表秀(https://www.tubiaoxiu.com/)」,可以将 Excel 上传,而且还能对 Excel 进行编辑,可以删除列、删除行等操作,这也是相对其他在线图表平台的优势,比如百度的「图说」。下面是我做的一个简单的柱状图,除了柱状图外还支持好多种图表。
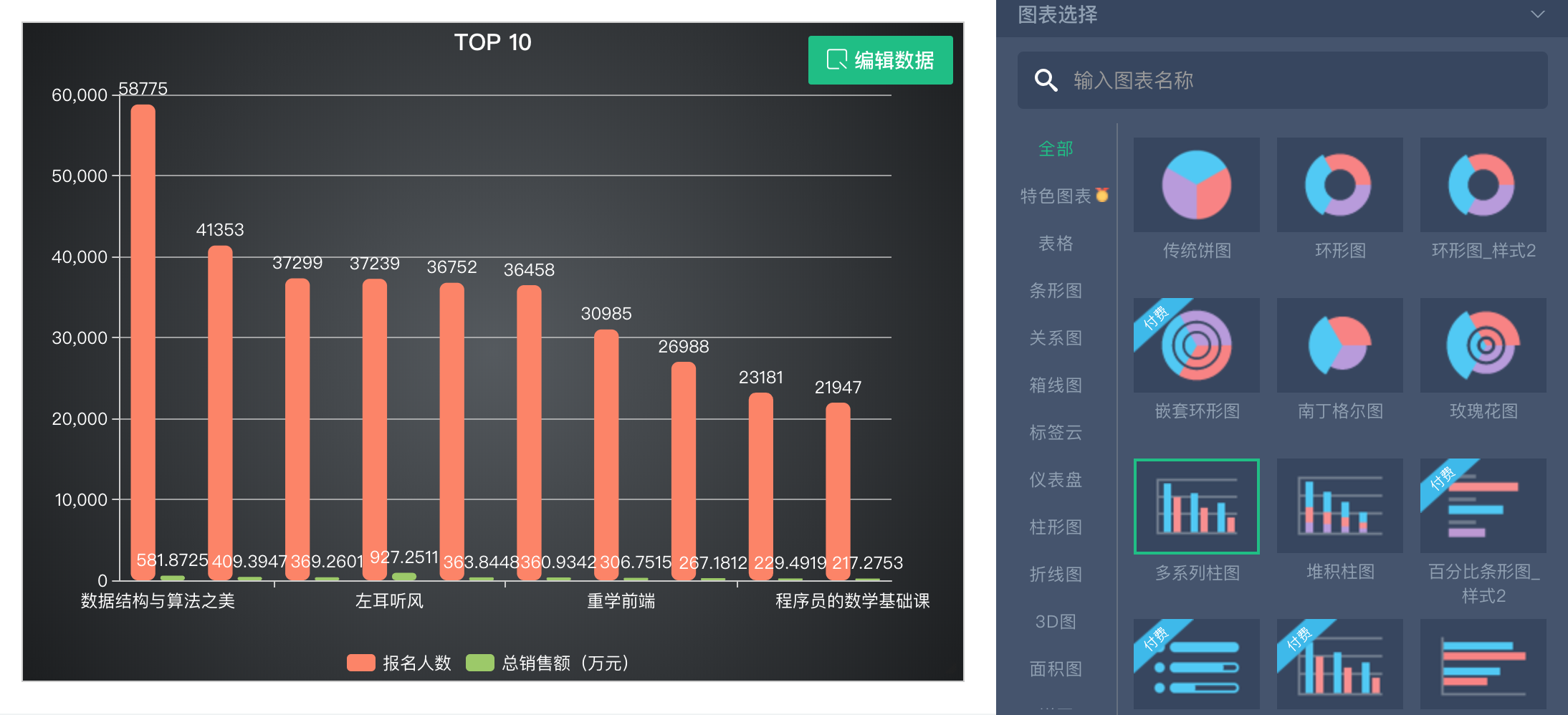
以上仅仅是一个业余选手做数据抓取和分析的过程,请酌情参考。
扫描下方二维码,关注公众号:
回复「Excel」获取本例中的 Excel 数据文件。
回复「jike」获取本例中的 sitemap。
不要吝惜你的「推荐」呦
欢迎关注,不定期更新本系列和其他文章
公众号:古时的风筝

相关阅读:

