GO语言: 双单链表、队列、进出栈打造一个简易的数据结构库 以及测试你的程序是否存在BUG!
GO语言进阶知识学习
通过双单链表、队列、进出栈打造一个简易的数据结构库
以及测试你的程序是否存在BUG
战斗环境:Ubuntu20.4TS
GO语言介绍:
比如通道传输。在1.8版本中开放插件(Plugin)的支持,这意味着现在能从Go中动态加载部分函数。
个人体验感受以及如何入坑:
前面介绍的肯·汤普逊(Ken Thompson) 是谁?如果不是计算机专业或行业内可能没听过,但是计算机教科书一定会出现一个名词“ 贝尔实验室”,
没错就是那个传奇计算机研究中心中最高的殿堂。像大名鼎鼎的C语言和UNIX操作系统,目前的计算机系统亦或是安卓苹果系统都是基于,
这个编程语言语言和操作系统。作为开发者之一的肯·汤普逊,也是GO语言开发之一。如果接触过GO语言的玩家可以看到整个结构很接近C语言,
但又有很大不同,如果感兴趣可以自行学习。
如何入坑的?
当时自己在学习c语言和python进度都非常慢,一直提高不了效率和开发不错的项目,大概限制在于C语言的开发难度,和python开发一些项目的速度不快的原因。
导致很难看到尽头,为了改变这种困境所以想做一些项目,为了应对现在时代变迁需求,选择往web方向。经过一顿百度操作,有了初略的开发学习思路,
一些PHP世界第一, javascript, java, css html 不断从我眼前闪烁。当时连什么前端后端都分不清楚,也不知道框架是什么,看了很久文章也不知道从哪里下手。
看到了PHP的口碑,就买了几本PHP书籍可以学习,从一开始就各种碰壁,不知道是我太笨还是这个作者教学太欠抽,根本看不懂,那只能跟着敲了吧?
一般都是php直接对接HTML那时候还没接触到前后端分离React.js Vue.js这些词汇。虽然跟着敲很快一个粗糙的西式网站主页就出来了,但是依旧不懂原理代码也很快忘记。
过程就为了找书中提到的加速插件,就让我发疯网上早已停止供应,崩溃。因为工作原因PHP学习就这样以失败告终。
后面如何接触GO?
由于自身空闲的时间比较多了,想着继续开发WEB,但是PHP感觉完全没学到。开始在网上找文章如何搭建WEB偶然 的机会在GO语言社区了解到GO语言,
看到社区搭建的风格都很活力而且速度很快。所以想着了解一下发现:如下图
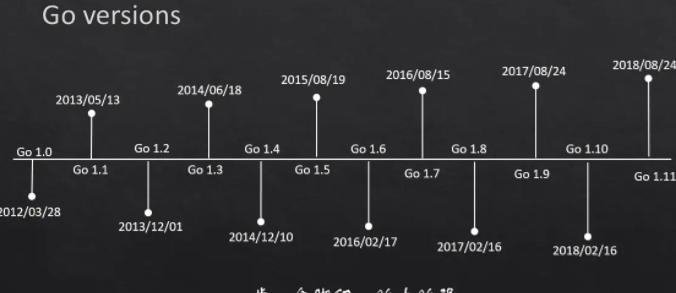
由于GO语言诞生比较新,所以社区比较活跃,加上有世界科技最前沿的公司Google在维护。
在网上买了几本GO语言的书籍,开始重新学习。与C语言的学习模式很像。
打嘴炮时间结束
第一种:通过git下载源码,根据自己习惯去放置位置:
git clone https://github.com/EternalNight996/go-tools.git cd go-tools go run index.go
第二种:用我们go语言自带的,跟上面获取的方式一样。但是这种不用产生新文件夹,会管理起来
go get github.com/EternalNight996/go-tools/container cd $GOPATH/src git clone https://github.com/EternalNight996/go-tools.git cd go-tools.git gvim index.go

那这些包都存储到哪里了? 要么$GOPATH/src/........ 要么$GOROOT/...
但是我下载到的是$GOPATH/pkg/mod, go get 的好处,是GO可以自动去$GOPATH/pkg 和 src里去调用包,不需要我们手动管理,推荐!!!但我们要下载示范码...
输出的结构分别对应的的是各个接口,这里用的是gvim编辑器,根据自己喜好。
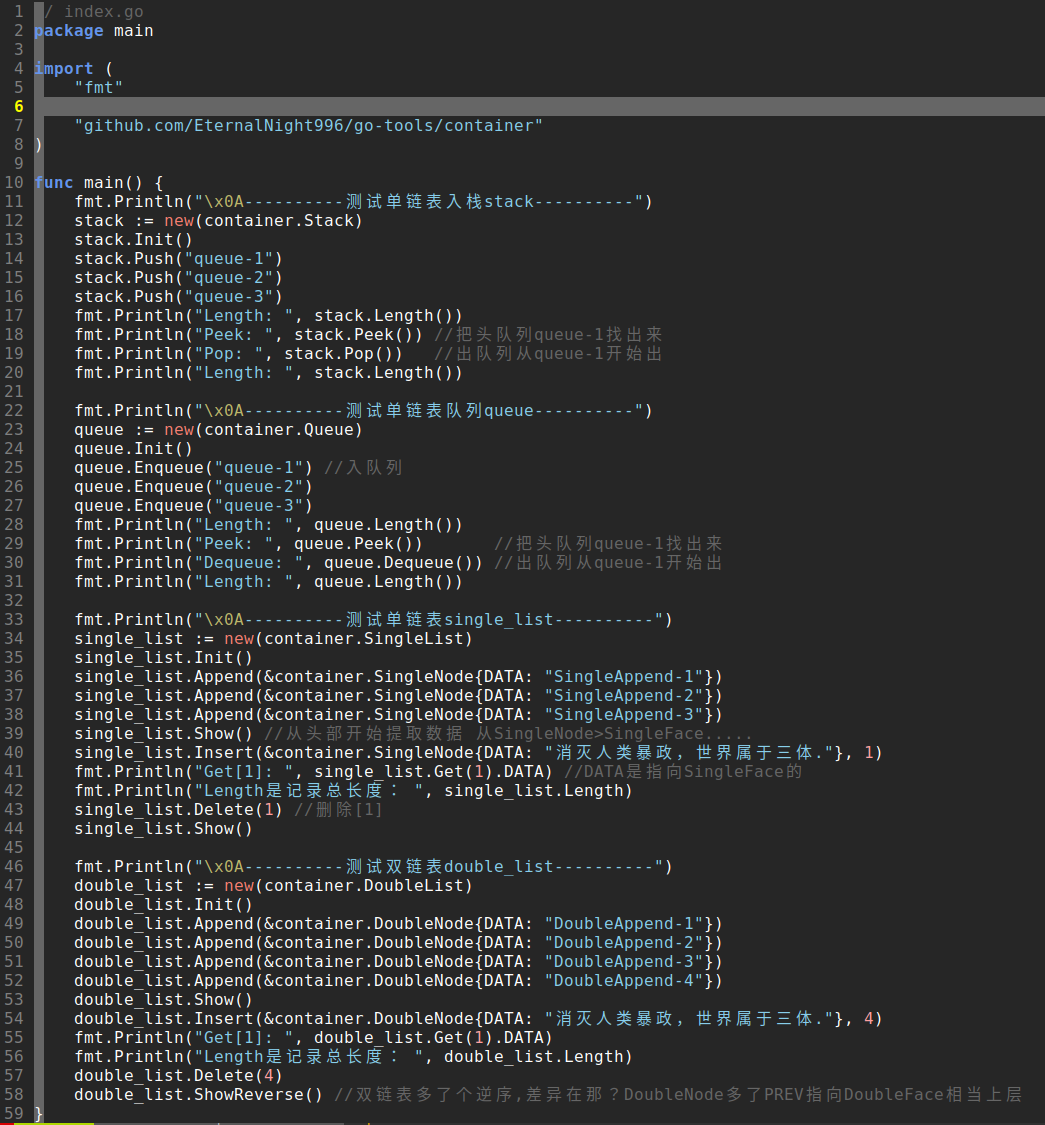
先有概要调用,以及我们可以看到调用的是github.com/EternalNight996/go-tools/container,这里大概关于golang不同package之间的互通原理及如何控制,
照顾下新人。因为我自己也被坑过!!!!我们玩过GO都知道开头 package main 是主要输出的包,类似c语言中的 main() {}把主要输出运行放在这个函数里面。
但事实上我们这个包的名字正确是叫什么?go-tools为什么呢?我打开github下载的go.mod 这个是什么?事实上是项目管理,还有另一个当我们建立了go.mod后
go get something? 以及运行自动go get的时候,go 就会自动给我们创建一个文件名为go.sum的,是主要放置go get 的所有版本记录和包。 go.mod也会记录,
但是只记录主要的包,和目前我们这个项目的包名和go version。

所以我们导入包的时候,前面要加github....,事实上项目只是go-tools/+子项目名如container。
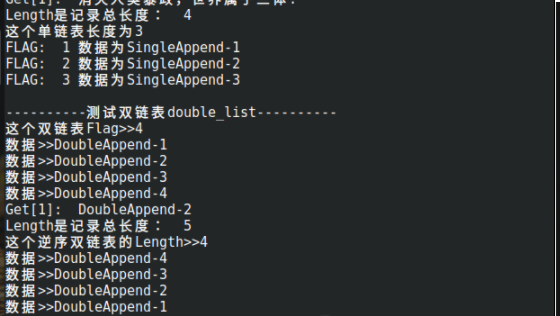
输入vim container/double_list.go或者vim container/double_list_test.go我们可以看到下图


这里又一个坑,我已经踩过一次了,这里的package不是随便取的,一定要对应文件夹名。通过文件夹统一内容共享。
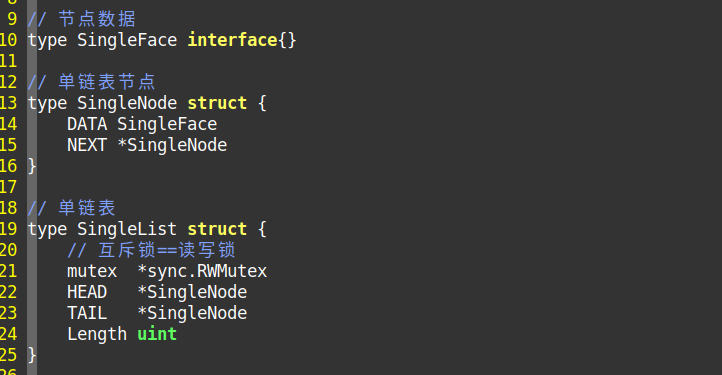
双链表与单链表
先进入container打开单链表
cd container
gvim single_list.go
下面即是所有内容的重点,如果这里的逻辑关系没搞清楚,双链表以及后面的队列 和出入栈。都会受到影响
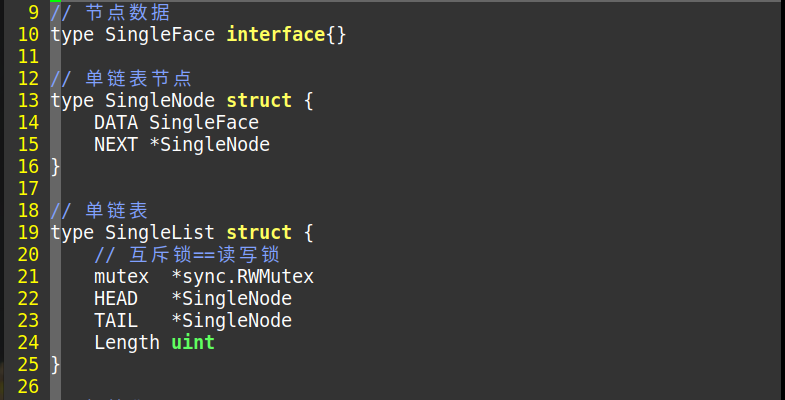

上面是我们单链表代码,下面是我们一开始示范接口的开始段。我们先建立了一个new()去连接container.SingleList,
从上面可以看到类型是 type SingleList struct,是类型结构。SingleList结构非常简单。
如果你是刚学GO或者学了GO还没深入了解* 这个字符的意思,这里我小小科普。接触*是我主要在学
C语言时接触到的,即指针。不同场合不同作用如 a *= 1那可能是a = a * 1, 但是放在赋值的下面举例:
var source int = 10 var i int = source var j *int = &source i = i + 4 *j = *j - 4 fmt.Println("source==", source) //source== 6发现source我们没去操作值被剪掉了4! fmt.Println("i==", i) //i== 14 既然没被减? fmt.Println("j==", j) //j== 0xc00008c010 这是什么?是分配source所在的地址,&source。 fmt.Println("*j==", *j) //*j== 6 同理我们操作source -= 1或 *j -= 1两个值都守捆绑,实现同步
j就是那个被赋予指针指向&source的那个指针变量,这样可能看的懂一点了,但是还在神游这就是指针的恐怖之处,
这只是指针的冰山一角,尤其是C语言的指针复杂程度超乎其他编程语言哈哈。。逃离C语言的指针支配是正确的选择。我们只需要知道我们需要的知识即可。
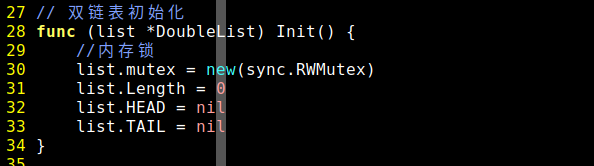
mutex *sync.RWMutex(Read Write Mutex)读写互斥锁用途就是防止goroutine抢资源读写出错,后面有细讲。
HEAD *SingleNode 我们根据上面我们可以知道*可以让我们HEAD与 SingleNode结构实现同步,试想一下。
如果我们HEAD一直与一个数组[0]同步,那么每次我们获取HEAD的时候相当是获取[0]无论值是什么样。
TAIL *SingleNode 如果一个数组[0, 1, 2, 3, 4, 5, 6.........N]一直扩张,而我们又不能在不同的函数或不同的位置去修改变量,
除了工作量大了代码多了,还容易出错。指针就很重要,因为他是同步的。他不接收实质的值,
他只接收内存地址去取。只要每次插入或者更新列表时候,将列表的最后一个值与TAIL相连接就可以实现尾部同步了。
Length uint 唯一的一个常量,uint为32位长度到底是什么这里不细讲,你就当他是一个没有负整数的整数。
这个可以方便我们去快速锁定位置,和知道目前SingleFace最大的长度。
type SingleFace interface {} 节点数据 这个是什么?这就是GO语言的强大之处,他相当于一个高级的指针接口,
什么是高级指针?就是不需要我们去管理指针,我们也知道在C语言中指针多了,就会出现野指针等,特别容易系统崩溃。

这是什么情况,&container这格式是不是有点眼熟?如果我们把&con....打印出来,
大概的格式如*container.DoubleNode 那么我们用指针呢?0xc00000c1e没错事实上interface{}
要干的事情就是将这些0x00000c1e十六进制地址存储并标记起来,是数据结构还是整数字符串,
抑或是函数也能存储。所以说强大对吧? ype SingleNode struct { DATA SingleFace; NEXT *SingleNode },
如果我们用过归递和代送,都知道它们能循环去做某项任务直到任务完成或者错误。有点老鸟就说了“不就是,
底层0 | 1原理吗?”基础很好,很多虽然知道,但就是不能很好的解释和弄懂。
有点新鸟可能连归递与代送区别都没弄懂,这里还是照顾新人。下面代码以代送与归递实现相同功能。
//代送打印100内的偶数 for i := 1; i < 101; i++ { if i%2 == 0 { fmt.Println(i) } } //归递打印100内的偶数 func funcTest(one int) { if one < 101 { if one%2 == 0 { fmt.Println(one) } funcTest(one + 1) } } funcTest(1)
虽然同样能实现一样的结果,但由于底层机制不相同,归递除了效率没代送高而且容易走火。
链表节点也是一样的,如果我们加判断语句那么就会容易在内存的海洋迷失!
心细的玩家就会发现,DATA DoubleFace怎么没赋予指针?假设我们赋予指针那么会发生什么?

我们不断添加数据,而不是一次性。那么上面例子的DoubleFace可提取的内容是什么?
"SingleAppend-3"只要我们去掉了指针,就可以实际的存储值,每次赋值的时候,内存就会分配一个新内存空间!
最后解释SingleNode, 如果我们需要加入新的存储内容就需要通过SingleNode,通过SingleNode指向SingleFace。
有的说为什么不把SingleList放到SingleNode?如果我们将SingleList的TAIL和HEAD..放到SingleNode里行不行?
当然是可以,但是我们分层就可以方便管理了。当这里核心的内容就讲完了。面我们就看下如何构建一个完整的存储系统?
初始化Init()
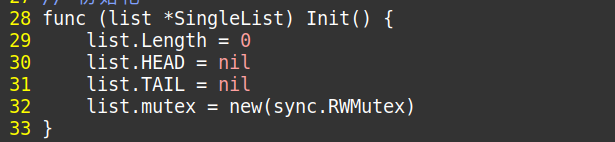

现在知道为什么要分SingleList和SingleNode吧?是为了实现频繁对象访问,降低资源消耗!
如果没怎么接触过高级语言的小伙伴,如纯玩C语言的可能对对象有些陌生。也体验不到对象的强大。
如果我们用平时写函数的方式写这个Init()会如何?
func Init(list *SingleList) { .... .... } //如何调用呢? single_list := new(container.SingleList) container.Init(single_list) //发现了吧?哈哈乖乖的用高级语言吧
为什么要进行初始化?我们要知道前面写的结构只是struct声明,是没有赋值表明的状态的。
Append添加数据
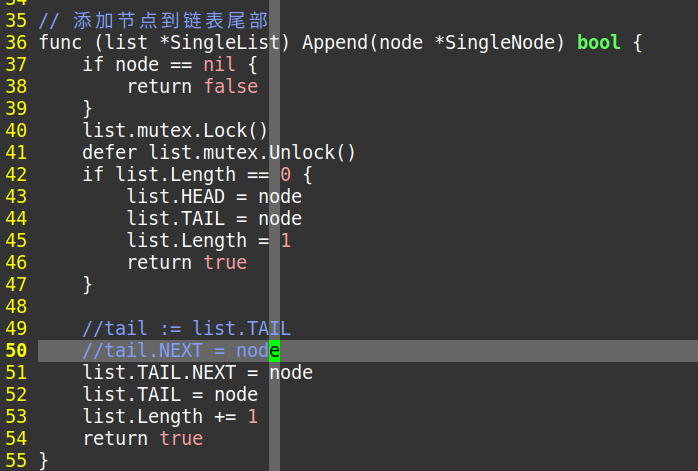

func (list *SingleList) Append(node *SingleNode) bool {}
相信来看我文章的基础都不错,但是也有部分基础比较差,或者不熟悉GO语言,还是花些时间好好解释下。
上面已经解释过(list *SingleList)Append 是这个对象建立,我们能在函数内通过list指针变量去访问 SingleList,
这个list是指针变量,也就是说这个使用list发生变化时,那么SingleList也会变化。
还有点就是我们也可以通过SingleList去访问Append,single_list.Append()这是对象建立的双向性。
Append(node *SingleNode) bool {} ()内表明需要我们导入值进去,类型也限制了为*SingleNode,
也就需要我们给予一个SingleNode结构指针,就是我们只需要导入&SingleNode即可,
在我们平时调用的时候建立一个函数即可,因为每次输&con....就有些重复了,如果我们建立变量,
那么如果我们要插入100多个数据呢?也不行对吧?我们可以外部建立个接口就可以解决这些问题。
bool则是数据类型中的布尔值 0 | 1 或 true | false, 就是会返回bool类型的值,以便我们去判断这个函数是否添加数据成功!
if node == nil {return false} //如果我们导入的值为空,则返回一个1 | false list.mutex.Lock() //加锁,说明我们正在写入 defer list.mutex.Unlock() //解锁,前面加个 defer事实上就是把解锁,放在函数解锁时。 if list.Length == 0 { //当我们处于没存储任何值的状态 list.HEAD = node //那么头就指向 node数据 list.TAIL = node //那么尾就指向 node数据, 因为只有一个数据。 list.Length = 1 //长度+1 return true //返回true | 0 } //前面已经排除空值,未存储值。也就是说后面都是大于1长度的方法 list.TAIL.NEXT = node //每次都通过尾部的空间的下一层去获取这个值这样就实现扩展了。 list.TAIL = node //如果不更新TAIL 那么就不会再扩张,因为停留在原处。
Insert插入值


区别Append在尾部等多输入一个 uint整型的标识,
if node == nil || index > list.Length {return false} //不为空,插入位置小于总长度 //因为append是添加的时候NEXT一定为空的,所以我们只要在TAIL.NEXT存储即可。但是这个插入0的时候可能后面会有值。 if index == 0 { //未插入时【HEAD NEXT1 NEXT2 NEXT3 TAIL】 //插入0时node添加HEAD后【node HEAD..】因为HEAD.NEXT是NEXT1.NEXT是NEXT2。。。。。以此类推 node.NEXT = list.HEAD list.HEAD = node //最后只要调整HEAD的指针即可 list.Length += 1 //这时候总量发生变化+1 } //当非插入0的时候 ptr := list.HEAD //先获取HEAD部位置 for i = 1; i < index; i++ { ptr = ptr.NEXT //我们先将指针指向要插入的位置 } // 是不是很熟悉 相当 假设我们让a与b交换,但是a = b还是b = a 都部行,那么聪明的你就想到。 // c = a; a = b; b = c; 那么a 与 b 就成功对换了,这些基础只要学过任何语言都知道。 next := ptr.NEXT //next等同c ptr.NEXT = node node.NEXT = next
Get获取
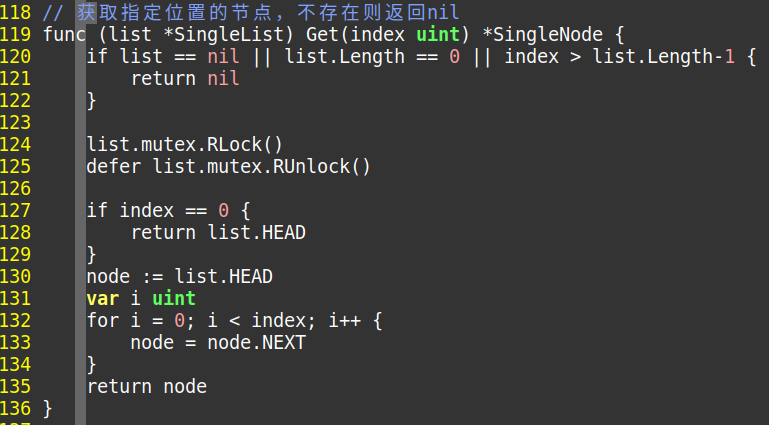

// 在我们获取HEAD,从HEAD开始出发,直到到达index,则将node指针返回 node := list.HEAD var i uint for i = 0; i < index; i++ { node = node.NEXT } return node
Show()打印
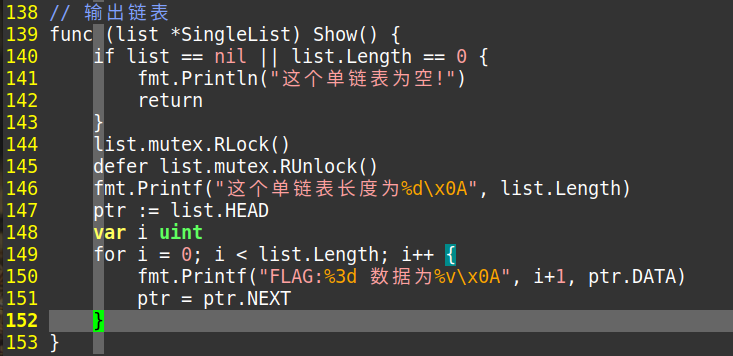
//跟查询一样,但是我们需要走完全程,每走一步就打印当时的数据。 ptr := list.HEAD var i uint for i = 0; i < list.Length; i++ { fmt.Printf("FLAG:%3d 数据为%v\x0A", i+1, ptr.DATA) ptr = ptr.NEXT }
DoubleList双链表
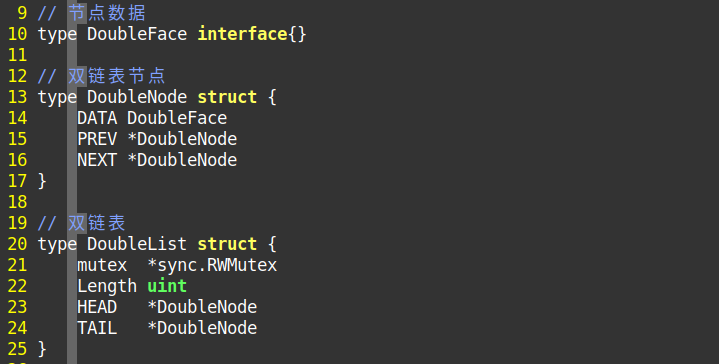
核心都在单链表讲过了,双链表就概要讲下,如果想了解细节则自己看源码。
// 双链表节点 type DoubleNode struct { //多了一个PREV 即上层的意思,单表中我们只能够向下走,每次通过HEAD寻找回家路 //如果有了PREV就可以向上走,大大的提高效率。 //但是这也意味着,你需要在每个数据中要存储上层指针 PREV *DoubleNode } //如下面Append添加 else { node.PREV = list.TAIL //因为要返回到上层,而Append上层永远是list.TAIL }
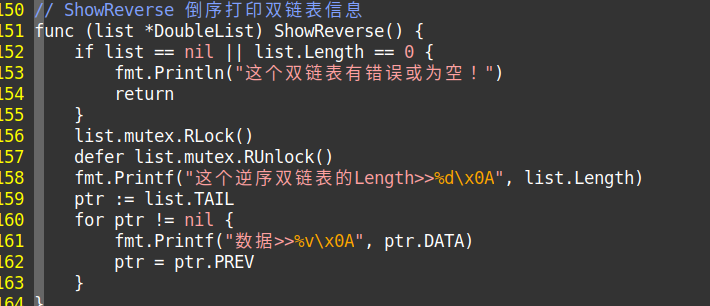
//多了一个函数ShowReverse() 就是逆向打印12345变成 54321 //因为我们单链表没有上层,所以无法通过TAIL用PREV返回上层,所以每次只能通过NEXT ptr := list.TAIL for ptr != nil { ptr = ptr.PREV //跟ptr = ptr.NEXT是一样的 }
如果你认真跟我学到这里,我相信你已经吸收了这门知识,并深入了解到了GO语言。结束了吗?还没
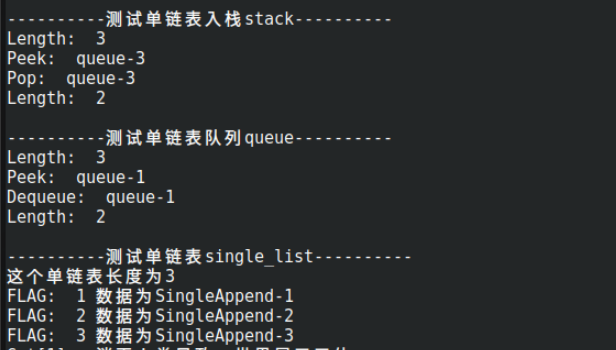
queue队列与stack栈
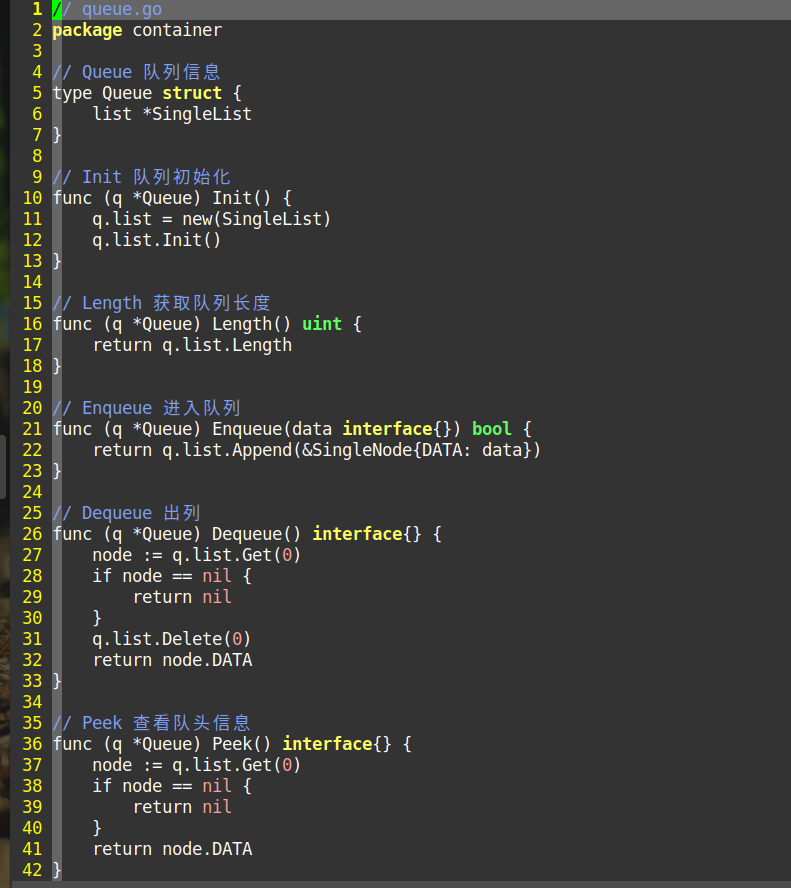
相信很多人都听说过队列和消息队列,但是却不知道用来干嘛的,什么原理。如果我告诉你们原理却不告诉你们用途,这不是让你们白学了吗?消息队列有什么用途?
场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种 1.串行的方式;2.并行方式
串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端
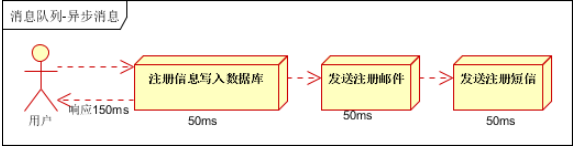
并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间
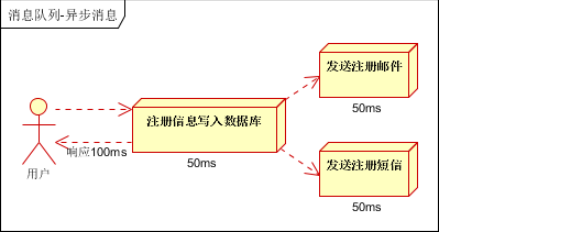
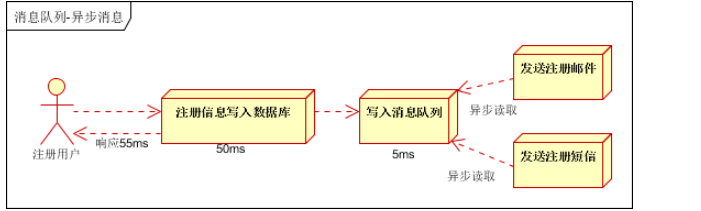
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,
直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50毫秒。因此架构改变后,
系统的吞吐量提高到每秒20 QPS。比串行提高了3倍,比并行提高了两倍。看实例吧!!!

//队列与出入栈都是用SingleList做示例 //与SingleList建立连接 // Queue 队列信息 type Queue struct { list *SingleList } // Enqueue 进入队列 func (q *Queue) Enqueue(data interface{}) bool { return q.list.Append(&SingleNode{DATA: data}) } // Dequeue 出列 func (q *Queue) Dequeue() interface{} { node := q.list.Get(0) if node == nil { return nil } q.list.Delete(0) return node.DATA }
事实上就是调用SingleNode,连添加都一样就是改个名字哈哈, 我们下面简单用SingleList写一个.
single_list := new(container.SingleList) single_list.Init() single_list.Append(&container.SingleNode{DATA: "data1"}) //把数据1进队列 single_list.Append(&container.SingleNode{DATA: "data2"}) //把数据2进队列 single_list.Append(&container.SingleNode{DATA: "data3"}) //把数据3进队列 //我们现在完成出队列了 fmt.Println(single_list.Get(0).DATA) single_list.Delete(0) //这两部就是出队列的核心,因为每次只提取头部数据,发现了吧? //出栈是提取尾部,出队列是提取头部。 single_list.Get(single_list.Length) single_list.Delete(single_list.Length) //这部分就是出栈,其他都差不多,只是函数名定义不同
其他我就不多讲了,也不需要了。因为最核心的东西你们已经掌握,相信其他挑战就会变得容易。
代码测试
到了最后一步,这里完了就真结束了。有点说为什么需要代码测试?我们能跑起来不就好了吗?下面看几段测试的代码!!!
func TestDoubleList_Init(t *testing.T) { list := new(DoubleList) list.Init() if list.Length == 0 { t.Log("double list init success") } else { t.Error("double list init success") } }

那么测试错误呢?我们讲值改成1


现在我们知道,简单的测试使用和结果。有的人说不就是测试逻辑判断吗?我们加到主代码就可以了,不需要这些额外的,
显得麻烦。这样你就错了,如果我们没有这些外部的测试程序,我们在日常测试任务就会复杂且庞大许多,
如我们的项目有几百万行代码分好些个文件夹,各种多。别说几百万行,几千行你可能都需要反复修改代码运行测试。
这样反而是损耗你的时间,打磨你的精力,还耗损你的设备。我们可以看到container文件夹下有一些_test.go结尾的。

这些可不是随便命名,这种命名方式GO识别后不会将其导入到我们操作中。它可以测试时嵌入到container,平时不会被调用。
如何写测试程序且如何测试?我们需要导入一个testing库,testing下有很多功能下面只演示testing.T
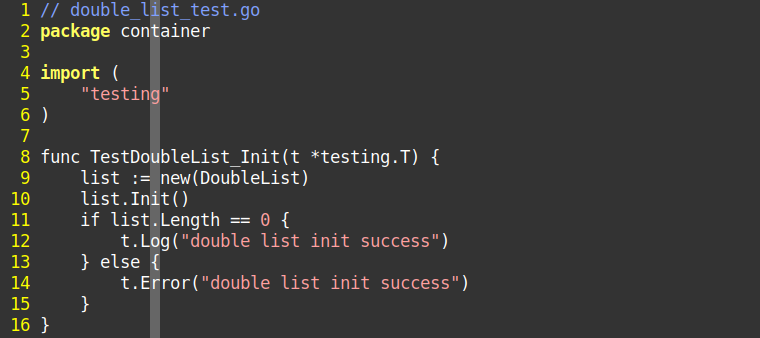
就是正需要测试的部位添加判断返回t.Log() 或 t.Error()就是这么简单,写好测试程序。就可以在外部调用,单条测试.
go test -run=TestDoubleList_Init

加-v则有打印内容
go test -v -run=TestDoubleList_Init

测试整个项目所有代码,这里不加-v因为内容比较多
go test

从入坑到入坟,选择权在你.
我是玫瑰与屠夫,一个逆风前行的玩家。
2021/5/27

 浙公网安备 33010602011771号
浙公网安备 33010602011771号