

Subject Matter Experts:
T.K. Anand
Sasha (Alexander) Berger
Marius Dumitru
Eric Jacobsen
Edward Melomed
Akshai Mirchandani
Mosha Pasumansky
Cristian Petculescu
Carl Rabeler
Wayne Robertson
Richard Tkachuk
Dave Wickert
Len Wyatt
Published: February 2007
Applies To: SQL Server 2005, Service Pack 2
概要:此白皮书详述应用程序开发人员如何应用性能调校手段来优化Microsoft SQL Server 2005联机分析处理(OLAP)方案。
发表于:博客园
版权
文档中的信息仅代表发表之日止微软公司的观点。因为微软公司需要响应不断变化的市场环境,所以微软公司不能保证发表之日后,文档中信息的正确性。
此白皮书仅用于报告目的。微软不为此文档作任何担保。
用户有责任遵从版权法。如果没有微软公司的授权,用户不得超出权限以任何形式(包括电子或机械复制、拍照、记录、及其他形式)复制此文档。
此文档可能包含了微软的专利、专利应用、商标、版权或其他非物质财富。除了微软提供专门的书面授权,否则你不能使用文档中的这些专利、商标……
除非特别说明,此文档的例子中出现的公司、企业、产品、域名、电子邮箱地址、图标、人名、地点和事件都是虚构的,如有雷同,纯属巧合。
2007 Microsoft Corporation. All rights reserved.
Microsoft, Windows, and Windows Server are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
All other trademarks are property of their respective owners.
介绍
联机分析处理系统都需要快速的查询响应和及时的数据更新,以提供高效的数据分析。传统的OLAP系统使用层次组织和汇总数据,层次为有效地分析提供合理的数据结构。但严格的层次结构又限制了用户自由的组织和分析数据。
为了提供更自由和更弹性的数据分析,Microsoft® SQL Server™ Analysis Services (SSAS) 2005既包含了传统层次分析的优点,又有新一代的更弹性的属性层次。属性层次允许用户在查询时自由的组织数据,而不限于设计好的导航路径。要支持这样的弹性化分析,Analysis Services OLAP构架经过了特殊的设计,以应用属性和层次分析,同时还保持传统OLAP数据库的快速查询性能。
你需要理解OLAP构架是如何支持属性和层次构架,理解如何有效使用这种构架满足分析需求,以及如何让构架充分利用系统资源。
注意 要使用此白皮书中讨论的性能调校技术,你必须安装了SQL Server 2005 Service Pack 2。
为了满足各种OLAP设计方案的性能需要,此文档提供了广泛的指导,指导你使用更多手段优化Analysis Services性能。因为Analysis Services性能调校是非常宽泛的话题,此白皮书的内容按如下的四个章节组织。
增强查询性能 – 查询性能直接影响终端用户的体验,也是衡量OLAP是否成功的主要标准。Analysis Services提供了多种机制加速查询性能,包括聚合、缓存、数据索引,而且你可以通过优化维度属性、cube、MDX查询语句来提升性能。
调校处理性能 – 处理是更新Analysis Services数据库的操作。处理速度越快,用户能更及时地获取更新后的数据。Analysis Services提供了多种机制让你影响处理性能,包括有效的维度设计、合适的聚合、分区、节制的处理策略(例如用增量更新代替完全更新,主动缓存技术等)。
为特殊应用优化设计 – 复杂的设计场景要求特殊的性能调校技术,以确保OLAP能够成功的应用,特别是复杂的设计再加上大数据量。例如,在OLAP中包含了特殊聚合函数、父子层次、复杂的维度关系、近实时地更新数据。
调校服务器资源 – Analysis Services的操作受服务器资源的限制,理解Analysis Services如何使用内存、CPU和磁盘资源可以帮助你更有效的管理服务器,优化查询和处理性能。
文档的三个附录提供了更多相关信息。
增强查询性能
查询是指Analysis Services依据多维表达式(MDX)将数据提供给客户端应用程序。因为查询的性能直接影响到客户的体验,这部分将详述改进查询性能的几种手段。下面就是这部分的主要内容:
理解查询构架 - Analysis Services查询构架支持三种主要操作:会话管理、MDX查询执行和返回数据。若要优化查询性能就需理解这三种操作如何协调工作实现查询。
优化维度设计 - 经过良好调校的维度设计可能会是提高Analysis Services性能最重要的因素。创建属性关系和在层次中使用属性会影响到聚合设计、MDX计算、维度数据存储效率和磁盘读取数据的性能。
最大化聚合数据 - 通过预汇总计算,聚合数据能够提高查询性能。为了最大化聚合数据,确保你有一种合适聚合设计以满足你特定的需求。
使用分区增强查询性能 - 分区是一种将度量值组存储到独立物理单元的机制,这种机制能提高查询、处理性能,使管理更简便。而且分区能实现并发查询,可以通过聚合设计选项和服务端属性设置优化分区性能。
编写高效的MDX语句 – 这部分详述如何编写高效的MDX语句,例如:1)在MDX语句中使用更精确和更窄的计算空间。2)设计多用户可重用的计算成员。3)用最简洁的方式编写计算成员表达式,使查询执行引擎能最有效的选择执行路径。
理解查询构架
为了使终端用户能有尽可能快速的查询体验,Analysis Services使用了若干组件协同工作实现高效计算和返回数据。图1标明了在查询发生时三个主要操作:会话管理、MDX查询执行、返回数据,以及参与每部分操作的服务组件。

图 1 Analysis Services查询构架
会话管理
客户端应用程序通过TCP IP或HTTP,使用XML for Analysis (XMLA)与Analysis Services通讯。Analysis Services使用XMLA监听组件管理所有的XMLA通讯。会话管理决定客户端连接到Analysis Services实例的方式。通过Windows认证,且拥有相关权限的用户才能连接到Analysis Services。在用户连接到Analysis Services后,安全管理依据用户在Analysis Services中的角色决定用户的权限。基于客户端应用程序构架和连接安全权限,当客户端应用程序连接到Analysis Services时,为客户应用程序创建一个会话,用户的所有查询请求都会重用这个会话,直到客户端应用程序关闭会话或在服务端终止会话。在查询执行引擎执行用户的请求时,会话提供了上下文。关于会话的生命周期,参考文档中“监控超时的空闲会话”章节。
MDX查询执行
查询执行引擎的主要工作是执行MDX查询,这部分概述查询执行引擎如何执行查询。关于优化MDX的细节,参考文档中“编写高效的MDX语句”章节。
实际的查询执行过程分多步执行,从性能方面考虑,查询执行引擎必须考虑两种基本需求:找到数据和产生结果集。
1. 找到数据—为了找到查询请求的数据,查询执行引擎将MDX查询分解成多个数据请求。又在与存储引擎通讯时,将这些数据请求翻译成存储引擎能够理解的子立方体请求,子立方体的数量依赖于查询的粒度和复杂度。子立方体代表了查询、缓存、查找数据的逻辑单元。注意,这里的子立方体是泛指,不要与MDX语句CREATE SUBCUBE所指的子立方体搞混淆。
2. 产生结果集—为了处理从存储引擎查找到的数据,查询执行引擎使用两种执行计划来计算结果:可以批量计算整个子立方,或者计算单独的单元。通常,子立方体赋值路径更高效,但查询执行引擎依靠查询的复杂程度选择合适的执行计划。注意,同一查询的会分解成多个查询部分,因而产生多个子执行计划,而且这些子执行计划可以独立的选择两种执行计划中的一种,所以没有单一的全局计划方式。例如,要查询年际利润大于10%的分销商,查询执行引擎使用一个执行计划来计算每个分销商的年际利润,另一个执行计划用来筛选利润大于10%的分销商。
当你执行一个MDX计算,查询执行引擎需要计算的单元数量可能远超出你的想象。比如,你使用MDX查询年初至今销售最大的五个区域。看起来你只需要五个单元值,但要决定哪五个区域销售最大,及计算年初至今销售值,Analysis Services必须计算更多单元。一个常用的优化手段是在MDX语句中将查询执行引擎所需计算的数据量最小化。要了解更多MDX优化手段,参考此文档中“指明计算空间”章节。
当查询执行引擎计算单元,它会使用查询执行引擎缓存和储存引擎缓存保存计算结果。缓存的好处就是优化计算和支持计算结果重用。为了优化缓存重用,查询执行引擎可管理三种范围的缓存:全局范围、会话范围、查询范围。关于缓存共享和重用的信息,参考“利用查询执行引擎缓存”章节。
数据查找:维度
在数据查找期间,存储引擎必须选择最佳的查找机制以满足维度和度量数据请求。
为了满足维度数据请求,存储引擎从属性和层次存储中抽取数据。当查找所需的数据时,存储引擎使用动态即需缓存,仅将所需的成员存入内存,而不是将所有维度成员静态保存在内存中。维度数据结构可以寄存于磁盘上、Analysis Services的内存中、或者Windows操作系统的文件缓存中,这由系统内存装载方式决定。
顾名思义,维度属性存储包含维度属性的所有信息。维度属性存储的各部分如图 2所示。

图 2 维度属性存储
如图中那样,维度属性存储中每个维度属性包含下面部分:
· 键存储—键存储包含属性键成员值和一个称为DataID的内部唯一标识。Analysis Services为每一个属性成员分配DataID。
· 参数存储—参数存储用来记录属性的各种附带参数,包括成员名称和翻译。DataID是从零开始连续分配的,参数存储对应到DataID。为了能不使用额外的索引或哈希表实现快速的随机访问,参数存储和关系存储一样按照DataID的顺序物理排列。
※注:为了不跟维度中的Attribute搞混,Property我只好翻译成“参数”。
· 哈希表—为了在查询和处理过程中,便捷的找到属性,会为每一个属性在磁盘上保存两个哈希表。键哈希表通过唯一键索引成员;名称哈希表通过名称索引成员。
· 关系存储—关系存储包含了属性与其他属性的关系。确切地说,关系存储保存了带有DataID的原记录与其他属性的对应关系。考虑下面的产品维的例子:在一个维度中产品是键属性,它与颜色属性和尺寸属性有直接关系。“运动头盔”是产品属性的成员之一,它的DataID是1001;“黑色”是颜色属性的成员之一,它的DataID是25;“大号”是尺寸属性的成员之一,它的DataID是5。这些属性成员组成了一个维度实例集——“运动头盔,黑色,大号尺寸”,这在关系存储中保存为1001, 25, 5。注意如果一个属性与其他属性没有属性关系,则不会为特殊的属性创建关系存储。关于属性关系更多信息,参考“识别属性关系”章节。
· 位图索引—为了在查询时快速在关系存储中找到属性数据,存储引擎在处理时创建位图索引。对属性的每一个DataID(成员),位图索引描述数据页中是否包含带有此DataID的纪录。如果属性有非常多的DataID,既此属性有很多成员,那么在处理时将花费大量时间。在大部分场合,位图索引能显著的改进查询性能。但在设计时,第一次创建位图索引的代价超出了查询时的益处。可以通过将AttributeHierarchyOptimizedState设置为Not Optimized,删除指定属性的位图索引。关于这种设计方案,参考“减少属性负担”章节。
除了属性存储,层次存储为终端用户将属性排列成导航路径,如图 3所示。
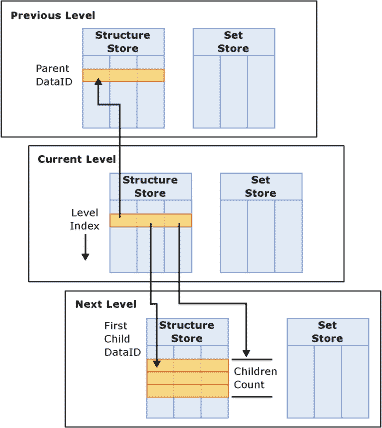
图 3 层次存储
层次存储由下面几个主要部分组成:
· 集合存储—集合存储将DataID从第一级排列到当前级别,来为每一个成员构建路径。例如,“山地自行车500系列”的DataID是6,它的父成员是“山地自行车”;“山地自行车”的DataID是5,它的父成员是“自行车”;“自行车”的DataID是2,它的父成员是“所有产品”;“所有产品”的DataID是1。那么“山地自行车500系列”的结构存储就是1,2,5,6。
· 结构存储—对级别中每个成员,结构存储包含父成员的DataID,第一个子成员的DataID和子成员的数量。结构存储中的每个成员都按照其级别索引排序,级别索引是由维度排序设置决定的成员在级别中的位置。为了更好的理解结构存储,考虑下面的例子:如果成员自行车有3个子成员,那么它的结构存储为1,5,3;1是自行车父成员的DataID,5是自行车第一个子成员的DataID,3是子成员的数量。
注意,只有自然层次才在层次结构中物化存储。关于设计层次最佳实践,参考“有效使用层次”章节。
数据查找:度量值组
对数据请求,存储引擎在分区中查找度量数据。分区包含两类度量数据:事实和聚合数据。为了适应不同的数据存储结构,每个分区可使用不同的存储模式。MOLAP存储模式提供了最快的查询性能,MOLAP分区会以压缩的多维格式存储事实和聚合数据。大部分情况下,都应该使用MOLAP存储模式。如果你想了解更多分区模式的信息,参看“附录 B”。如果你考虑“近实时”部署,参考“近实时数据更新”章节。
在MOLAP分区中,事实和聚合数据结构是一样的。关系型数据库中事实表的数据被高度压缩后,存储到MOLAP分区中。记录(通俗的讲,就是二维表的行)是最小存储单位,每个记录存储度量值组的所有度量值和一组内部的DataID用于关联维度的粒度属性。256个记录组成一个页,256个页组成一个段。
为了有效地满足数据请求,存储引擎应用三种机制优化查询请求:缓存、聚合、事实数据。如图 4。
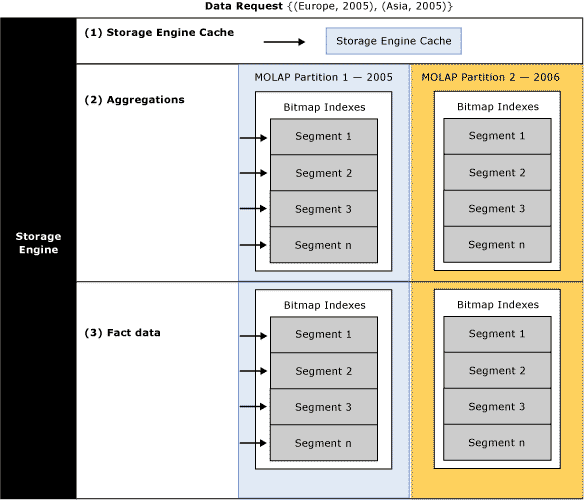
图 4 满足数据请求
图 4标示了对{(Europe, 2005), (Asia, 2005)}的数据请求,存储引擎选择了下面的途径实现请求:
1. 储存引擎缓存—存储引擎首先试图使用存储引擎缓存满足数据请求。存储引擎缓存永远是居于内存中的,使用存储引擎缓存提供了最好的性能。关于管理存储引擎缓存的信息,参考“查询时内存需求”章节。
2. 聚合—如果缓存中没有相关数据,存储引擎查询预计算的聚合数据。在某些场合,聚合恰好能满足数据请求。例如,当按产品类别和年来查询销售数据时,就可以使用聚合。存储引擎也可以使用低级别的聚合数据,例如按月或季度查询数据。关于如何设计聚合来提供性能,参考“最大化聚合”章节。
3. 事实数据—如果没有合适的聚合数据能满足查询,存储引擎必须从分区中查找事实数据。存储引擎使用多种内部优化手段从磁盘查找数据,包括增强索引和聚类相关记录。聚合和事实数据都可以将数据的不同部分存储到磁盘或Windows操作系统文件缓存,这依赖于系统的内存转载方式。
一种优化数据查找的关键手段是使用多分区将度量值划分成不同的数据片断,从而减少存储引擎需要扫描的数据量。多分区不仅能增强查询速度,而且更便于数据管理和处理。
从查询的角度考虑,存储引擎预计每个MOLAP分区存储的数据,并优化它的MOLAP分区并行查找计划。例如图 4,2005的分区数据显示蓝色,2006的分区显示黄色,数据请求{(Europe, 2005), (Asia, 2005)}只要求2005的数据,因此存储引擎只需要查找2005分区。为了优化查询性能,存储引擎尽可能的使用并行查询。为了在分区中定位数据,存储引擎并行查找段,并使用位图索引有效的扫描页以找到想要的数据。
分区是高性能立方体的主要条件。关于分区的好处,参考下面的章节:
· 要了解如何创建位图索引,在分区中使用位图索引,参考“分区处理作业”章节。
· 要了解分区优点的细节,参考“使用分区增强查询性能”章节。
· 要了解分区对处理所带来的好处,参考“使用分区增强处理性能”章节。

