

InnoDB索引结构浅析
InnoDB索引浅析
在mysql中,索引作为一种数据结构,它提供对表的 行 进行快速查找的能力 ,通常通过形成表示特定列或一组列 的所有值的 树结构(B+树) 。索引用于快速查找具有特定列值的行。如果没有索引,MySQL 必须从第一行开始,然后读取整个表以查找相关行。表越大,成本就越高。如果表中有相关列的索引,MySQL 可以快速确定在数据文件中寻找的位置,而不必查看所有数据。这比按顺序读取每一行要快得多。
InnoDB表始终具有 表示主键的聚集索引。它们还可以在一个或多个列上定义一个或多个二级索引。
Everything is an index in InnoDB.
在InnoDB中一切都是索引,基于这几点可以得到这个结论:
- 所有表都有主键,没有唯一值字段的表会产生一个 GEN_CLUST_INDEX来作为主键保存。
- 完整的行数据都存储在聚簇索引结构里,与其中的主键链接(或者说主键就是数据的一部分
- 次级索引保存在一个单独的索引结构中,其中只保存主键和次级索引键的数据
由此可见,索引和数据是不分家的,在分析索引结构也是直接在分析数据存储结构
InnoDB中的数据存储结构
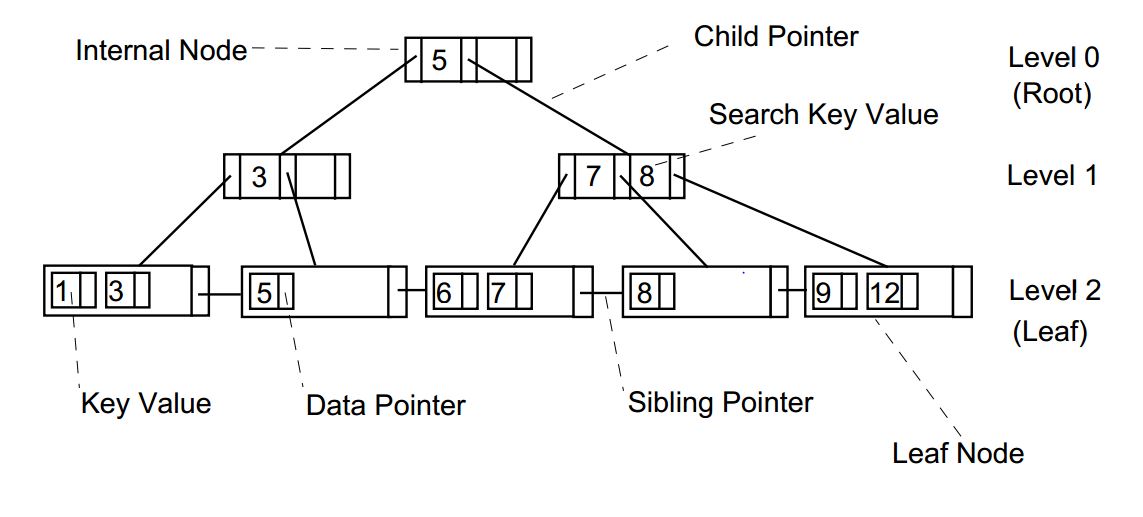
B+ 树中,记录(数据)只能存储在叶节点上,而内部节点只能存储键值。B+树的叶节点以单链表的形式链接在一起,以提高搜索查询的效率。
B+ 树结构
innodb存储页的类B+树结构
从b+树图和基于b+树的简略索引图可以看出,InnoDB的索引几乎是一个B+树结构,不过它的每一层都有一个首位没有链接的双向链表(页的链接),而b+树只在叶子节点有一个单链表。
在索引结构中,页对应b+树的节点,通过页中记录的数据来分配子节点。非叶子节点只存储主键值和子节点的页值,叶子节点存储主键对应的其他数据。每个页的内部将记录按主键顺序排序存放。
例如查询数据 D,如果知道主键3,可以通过index_key=3,可以通过b+树走二分法直达页7,再遍历7中的数据,拿出数据。但没有索引的话, 查询no_index_key=D,就需要从页6开始完整的遍历一次叶子节点,取出所有值等于D的数据,性能差距非常大。
B+树的层级和深度
在InnoDB中,按以下表规定有索引的大小和深度限制
在超出层数大小或叶子数大小后,会将页进行分层
| 高度 | 非叶子页 | 叶子页 | 大小 |
|---|---|---|---|
| 1 | 0 | 1 | 16.0 KB |
| 2 | 1 | 1203 | 18.8MB |
| 3 | 1024 | 1447209 | 22.1 GB |
| 4 | 1448413 | 1740992427 | 25.9 TB |
InnoDB规定每个子页的大小最大为16k,在这个条件下,根据叶子节点数和大小来调整B+树高度。由于主键存储在树中的每一个节点下,过大的主键会导致叶子页树没有达到最大值就不得不提高高度,复杂化树结构。
创建一个student表,表结构及数据:
CREATE TABLE `student` (
`s_id` int(10) NOT NULL AUTO_INCREMENT,
`name` varchar(10) COLLATE utf8mb4_bin NOT NULL DEFAULT '',
`age` tinyint(3) NOT NULL DEFAULT '0',
`info` varchar(200) COLLATE utf8mb4_bin NOT NULL DEFAULT '',
PRIMARY KEY (`s_id`),
KEY `idx_name_age_info` (`name`,`age`,`info`),
KEY `idx_info` (`info`)
)
+------+---------+-----+----------+
| s_id | name | age | info |
+------+---------+-----+----------+
| 1 | aaa | 12 | cat |
| 4 | abc | 11 | catgort |
| 5 | abf | 12 | wolf |
| 7 | akg | 22 | earphone |
| 2 | bbb | 25 | man |
| 6 | bbc | 23 | radio |
| 8 | ccc | 11 | mooncell |
| 3 | ccc | 19 | dog |
| 9 | ccc | 22 | how |
+------+---------+-----+----------+
student表索引结构:
id name root fseg fseg_id used allocated fill_factor
58 PRIMARY 3 internal 1 1 1 100.00%
58 PRIMARY 3 leaf 2 0 0 0.00%
根节点为第三页,由于数据量较少,没有子节点
第三页的结构,作为叶子节点展示了所有的数据
Record 127: (s_id=1) → (name="aaa", age=12, info="cat")
Record 158: (s_id=2) → (name="bbb", age=25, info="man")
Record 189: (s_id=3) → (name="ccc", age=19, info="dog")
Record 417: (s_id=4) → (name="abc", age=11, info="catgort")
Record 249: (s_id=5) → (name="abf", age=12, info="wolf")
Record 281: (s_id=6) → (name="bbc", age=23, info="radio")
Record 345: (s_id=7) → (name="akg", age=22, info="earphone")
Record 381: (s_id=8) → (name="ccc", age=11, info="mooncell")
Record 488: (s_id=9) → (name="ccc", age=22, info="how")
另一个结构简单(甚至没有设主键)的表user,数据量大很多:
CREATE TABLE `user` (
`name` varchar(10) COLLATE utf8mb4_bin NOT NULL DEFAULT '',
`age` tinyint(3) NOT NULL DEFAULT '0',
`info` varchar(200) COLLATE utf8mb4_bin NOT NULL DEFAULT ''
)
mysql> SELECT COUNT(1) FROM user;
+----------+
| COUNT(1) |
+----------+
| 2523 |
+----------+
1 row in set (0.00 sec)
它的根节点不是最底层,对应的子节点才是有数据的叶子节点
根节点:
Record 125: () → #5
Record 140: () → #15
Record 155: () → #15
Record 170: () → #15
Record 185: () → #15
Record 200: () → #15
叶子节点:
Record 127: () → (name="\x00\x00\x01", age=-37, info="\x01\x10a")
Record 160: () → (name="\x00\x00\x01", age=-37, info="\x01\x1Eb")
Record 193: () → (name="\x00\x00\x01", age=-37, info="\x01,c")
Record 226: () → (name="\x00\x00\x01", age=-13, info="")
Record 256: () → (name="\x00\x00\x01", age=-13, info="")
...
索引的种类
在B+树结构的索引中,主要分为聚簇索引与二级索引两类
聚簇索引 Cluster_index
每个InnoDB表都有一个称为聚集索引的特殊索引,用于存储行数据。通常,聚集索引与主键同义。
- PRIMARY KEY在表上 定义时,InnoDB将其用作聚簇索引。应为每个表定义一个主键。如果没有逻辑上唯一且非空的列或列集来使用主键,请添加一个自动增量列。自动增量列的值是唯一的,并在插入新行时自动添加
- 如果没有PRIMARY KEY为表定义,则使用将所有键列定义为的InnoDB第一个 索引作为聚集索引。 UNIQUENOT NULL
- 如果表没有索引PRIMARY KEY或没有合适的 UNIQUE索引,InnoDB 则生成一个隐藏的聚集索引 GEN_CLUST_INDEX,该索引以包含行 ID 值的合成列命名。行按分配的行 ID 排序InnoDB。行 ID 是一个 6 字节字段,随着新行的插入而单调增加。因此,按行 ID 排序的行在物理上按插入顺序排列。
上面对聚簇索引的描述摘自Mysql5.7的官方文档,总来来说就是:1.主键即聚簇索引 2.每个表必需由一个唯一且非空的列做聚簇索引,如果没有则自动生成一个
例如上文中的user表,它是一个没有主键且没有唯一值的表,查看表的索引列表,可以看到InnoDB自动生成了一个聚簇索引:
id name root fseg fseg_id used allocated fill_factor
59 GEN_CLUST_INDEX 3 internal 1 1 1 100.00%
59 GEN_CLUST_INDEX 3 leaf 2 6 6 100.00%
二级索引 Secondary_indexes
除聚集索引之外的索引称为二级索引。在 中InnoDB,二级索引中的每个记录都包含行的主键列以及为二级索引指定的列。 InnoDB使用此主键值在聚集索引中搜索行。如果主键很长,则二级索引将使用更多空间,因此使用较短的主键是有利的。
官方对于二级索引的描述很少,从上面分析表的索引结构可以看出,二级索引的非叶子节点和聚簇索引相似,但叶子节点只保存了二级索引的列的值和主键值。如果需要查询这俩之外的值,则会进行一个回表操作,先查询二级索引,将主键值保存在内存中,再用主键值回聚簇索引表查询其他数据。
上图student表的二级索引:
id name root fseg fseg_id used allocated fill_factor
69 idx_info 5 internal 5 1 1 100.00%
69 idx_info 5 leaf 6 0 0 0.00%
查看二级索引叶子节点的结构,仅由索引键和主键字段构成:
Record 139: (info="cat") → (s_id=1)
Record 260: (info="catgort") → (s_id=4)
Record 152: (info="dog") → (s_id=3)
Record 165: (info="earphone") → (s_id=7)
Record 277: (info="how") → (s_id=9)
Record 183: (info="man") → (s_id=2)
Record 196: (info="mooncell") → (s_id=8)
Record 214: (info="radio") → (s_id=6)
Record 229: (info="wolf") → (s_id=5)
一些提高效率的使用方式
以上面的student表为例
字符串的场合
精准匹配,正确使用索引
mysql> EXPLAIN SELECT * FROM student WHERE `info` LIKE 'cat';
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | student | NULL | range | idx_info | idx_info | 802 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
右侧模糊匹配,可以使用索引
mysql> EXPLAIN SELECT * FROM student WHERE `info` LIKE 'c%';
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | student | NULL | range | idx_info | idx_info | 802 | NULL | 2 | 100.00 | Using index condition |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
左侧模糊匹配与全模糊匹配,无法走索引
mysql> EXPLAIN SELECT * FROM student WHERE `info` LIKE '%c';
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 11.11 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
回到student表中的索引结构,按照索引行的编码结构进行了从左到右的排序
Record 139: (info="cat") → (s_id=1)
Record 260: (info="catgort") → (s_id=4)
Record 152: (info="dog") → (s_id=3)
Record 165: (info="earphone") → (s_id=7)
Record 277: (info="how") → (s_id=9)
Record 183: (info="man") → (s_id=2)
Record 196: (info="mooncell") → (s_id=8)
Record 214: (info="radio") → (s_id=6)
Record 229: (info="wolf") → (s_id=5)
在查询字符串时,通过右侧模糊匹配可以配合索引查询,左侧一旦有模糊项则无法使用索引。这是B+树的存储特性决定的
如果有前段相似后段不同的字符串需要索引,可以使用逆序存储,如cat->tac, catgory->yrogtca 通过这种方式来有效使用索引
联合索引的场合
student表中创建 name_age 的联合索引
mysql> SHOW INDEX FROM student;
+---------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | s_id | A | 10 | NULL | NULL | | BTREE | | |
| student | 1 | idx_info | 1 | info | A | 10 | NULL | NULL | | BTREE | | |
| student | 1 | idx_name_age | 1 | name | A | 7 | NULL | NULL | | BTREE | | |
| student | 1 | idx_name_age | 2 | age | A | 9 | NULL | NULL | | BTREE | | |
+---------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
二级索引树的构成
Record 126: (name="aaa", age=12) → (s_id=1)
Record 140: (name="abc", age=11) → (s_id=4)
Record 154: (name="abf", age=12) → (s_id=5)
Record 168: (name="akg", age=22) → (s_id=7)
Record 182: (name="bbb", age=25) → (s_id=2)
Record 196: (name="bbc", age=23) → (s_id=6)
Record 210: (name="ccc", age=11) → (s_id=8)
Record 224: (name="ccc", age=19) → (s_id=3)
Record 238: (name="ccc", age=22) → (s_id=9)
可以看到,先将name排序,在相同的name中,再将age排序。
精准匹配name和age的结果是不同的,后者无法走索引
mysql> EXPLAIN SELECT * FROM student WHERE `name`='abc';
+----+-------------+---------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | student | NULL | ref | idx_name_age | idx_name_age | 42 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
mysql> EXPLAIN SELECT * FROM student WHERE `age` = 12;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
在搭配name后,age也能走上索引了
mysql> EXPLAIN SELECT `name`, `age` FROM student WHERE `name`='ccc' AND `age`=11;
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | student | NULL | range | idx_name_age | idx_name_age | 42 | NULL | 1 | 100.00 | Using where; Using index |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
范围匹配中,name的范围可以走到索引,但其后的所有键都没办法,因为在name的范围内后续的键都是局部有序整体无序的。只有前面的键为精准匹配,后续的范围匹配才能使用索引
第一个字段范围匹配,扫了7行
mysql> EXPLAIN SELECT `name`, `age` FROM student WHERE `name` > 'abc';
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | student | NULL | range | idx_name_age | idx_name_age | 42 | NULL | 7 | 100.00 | Using where; Using index |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
第一个字段+第二个字段一起匹配,依旧是扫7行,通过覆盖率也可以看出,是在第一个字段范围内,一个一个判断是否满足第二个字段的条件,并非索引模式
mysql> EXPLAIN SELECT `name`, `age` FROM student WHERE `name` > 'abc' AND `age` > 12;
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | student | NULL | range | idx_name_age | idx_name_age | 42 | NULL | 7 | 33.33 | Using where; Using index |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
当第一个字段使用精准匹配后,第二个字段再使用范围匹配也能走上索引了
mysql> EXPLAIN SELECT `name`, `age` FROM student WHERE `name` = 'ccc' AND `age` > 12;
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | student | NULL | range | idx_name_age | idx_name_age | 43 | NULL | 2 | 100.00 | Using where; Using index |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
ORDER BY与GROUP BY,结合索引B+树的特性,也可以看出,满足左边键精准的前提下,后续键才能走到索引
虽然设计的表不太好体现,但从结构分析,下面这种写法显然能对age使用索引快速排序
mysql> EXPLAIN SELECT `name`, `age` FROM student WHERE `name` = 'ccc' ORDER BY age ASC;
+----+-------------+---------+------------+------+---------------+--------------+---------+-------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+--------------+---------+-------+------+----------+--------------------------+
| 1 | SIMPLE | student | NULL | ref | idx_name_age | idx_name_age | 42 | const | 3 | 100.00 | Using where; Using index |
+----+-------------+---------+------------+------+---------------+--------------+---------+-------+------+----------+--------------------------+
但这种写法就无法使用索引对age排序,因为name是一个范围
mysql> EXPLAIN SELECT `name`, `age` FROM student WHERE `name` > 'aaa' ORDER BY age ASC;
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+------------------------------------------+
| 1 | SIMPLE | student | NULL | range | idx_name_age | idx_name_age | 42 | NULL | 8 | 100.00 | Using where; Using index; Using filesort |
+----+-------------+---------+------------+-------+---------------+--------------+---------+------+------+----------+------------------------------------------+
回表问题
当查询的数据在索引表中都存在时,只需按索引键查出结果即可,但二级索引只保存的主键和索引键数据,所以需要进行回表操作
只需idx_info就能完成查询
mysql> EXPLAIN SELECT `s_id`, `info` FROM student WHERE `info` LIKE 'c%';
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | student | NULL | range | idx_info | idx_info | 802 | NULL | 2 | 100.00 | Using where; Using index |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
explain分析的结果的是一样的,但当数据量特别大导致大量回表情况时,优化器会采用扫全表而非 二级索引+回表的方式。
mysql> EXPLAIN SELECT `s_id`, `info`, 'age' FROM student WHERE `info` LIKE 'c%';
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | student | NULL | range | idx_info | idx_info | 802 | NULL | 2 | 100.00 | Using where; Using index |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
索引列在比较表达式中单独显现
比较表达式中对索引列进行了比较以外的操作(数学运算,函数等),会导致索引失效
mysql> EXPLAIN SELECT * FROM student WHERE s_id*2 > 4;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 100.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
操作非索引字段能使索引生效
mysql> EXPLAIN SELECT * FROM student WHERE s_id > 4/2;
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | student | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 7 | 100.00 | Using where |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
总结
索引结构的核心就是B+树,一切逻辑都围绕该结构展开,在使用中应该注意的点
- 主键值设计尽可能小,降低索引表的空间占用并提高查询效率
- 由于二级索引会有回表的操作,且联合索引的限制很多,所以在设计时要结合业务实际,争取达到不回表的效果
- 无论是联合索引还是模糊匹配,都存在最左优先原则,先全值匹配左侧才有可能使右边的使用索引
- 避免在比较表达式中对索引列进行比较之外的操作
参考
掘金小册子,从根儿上理解MySQL: https://juejin.cn/book/6844733769996304392?enter_from=course_center&utm_source=course_center
innodb树结构解析与分析工具: https://blog.jcole.us/innodb/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号