DotNetty网络通信框架学习之源码分析
DotNetty网络通信框架学习之源码分析
有关DotNetty框架,网上的详细资料不是很多,有不多的几个博友做了简单的介绍,也没有做深入的探究,我也根据源码中提供的demo做一下记录,方便后期查阅。
github地址:https://github.com/Azure/DotNetty
源码的src文件夹中是框架的dll项目,包含以下的内容:

1、DotNetty.Buffers
缓冲区:传输数据时一般都会使用一个缓冲区包装数据,DotNetty衍生于Java的Netty,定义了自己的Buffer。Netty的提供的Buffer相当的强大,用来表示一个字节序列,帮助开发者定义自己的buffer类型。详细的介绍参考:https://blog.csdn.net/wangjinnan16/article/details/77972113.
buffers中还提供了很多类和接口,其中ByteBufferUtil.cs是一个Bytebuffer的帮助类,可将接收的缓冲区包转换成需要的数据格式,其中我用到的是:Hexdump,是将buffer转换成十六进制的字符串,方便在Modbus解析中使用。
2、DotNetty.Codecs
编解码器:编解码器的作用就将原始字节数据与目标程序数据格式之间进行相互转换。网络中的数据是字节的数据形式进行传输的,通过编码和解码来满足对数据的利用。Netty中根据不同数据传输类型,扩展了很多的解码规则抽象类。其中包括项目中的Http、Mqtt、Protobuf、Redis等。工作机制大概如下:

Decodes.Http
http协议实现的抽象类,类型如下:
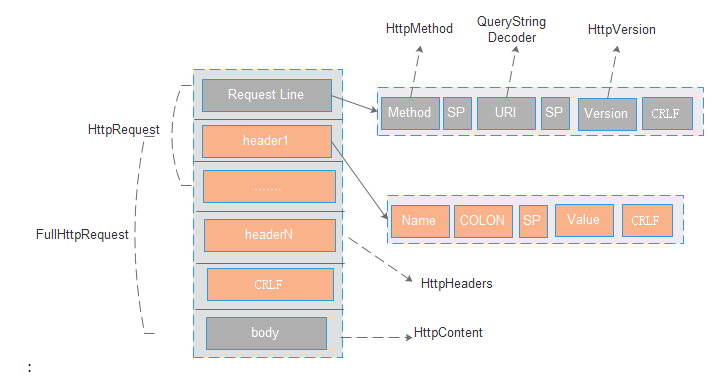
HttpMethod:对method的封装,包含method序列化的操作。get,put,post等。
HttpVersion:对Version的封装,包含版本1.0与1.1
HttpHeaders:包含对header的内容进行的封装及操作。
HttpContent:对httpnbody的封装,其本质是一个bytebuffer,
HttpRequest:包含对Request Line和Header的组合。
FullHttpRequest:包含对HttpRequest和httpContent 的组合封装。
request流程处理
基本的处理原理:
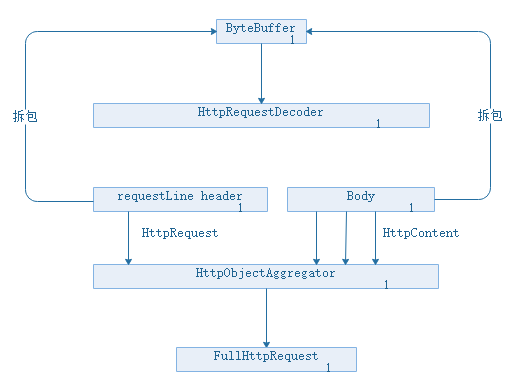
使用方法:只需要在通道ChannelLine中配置HttpRequestDecoder和HttpObjectAggregator.
HttpRequest解码器现将强求通道中的内筒解析成HttpRequest对象,在传到聚合其中,当聚合器解析完http协议后,再封装成FullHttpRequest。
response流程处理
原理:
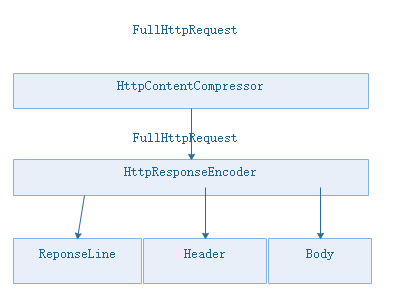
使用方法在编码之前加上HttpContent压缩机,response先被压缩后再进行编码序列化。压缩只是对Body的压缩。
有关Http编解码器的详细内容可参考:https://www.cnblogs.com/chris-oil/p/6098258.html
Codecs.Mqtt协议编解码
首先了解一下MQTT协议:根据百度百科的解释,它的的定义如下:
Mqtt(Message Queuing Telemetry Transport) 消息队列遥测传输,是IBM开发的一个即时通讯协议。该协议支持所有的平台,被广泛用于人工智能,区块链和物联网等。
MQTT提供了订阅和发布两种消息模式,更为简约、轻量、易于使用,特别适用于受限环境中的消息发布,属于物联网的一个标准传输协议。
更过的关于MQTT的内容学习可参考:http://www.360doc.com/content/18/0116/05/163747_722273693.shtml
Netty中提供了MQTT协议的解码和编码方法,具体的实践探索将在后期进行。
Codecs.Protobuf 协议编解码器
同样先得知道Protobuf协议是个什么东西:
Protobuf(Google Protocol Buffer):是谷歌开发的一套用于数据存储,网络通信时用于协议编解码的工具库,和XML和JSON类似,把数据用某种形式保存起来,唯一不同的是它是一种二进制的数据格式,具有更好的传输,打包和解包的效率。
DotNetty只是提供了编辑码协议用的抽象类,并没有做进一步的处理,有关协议的详细使用后期将不断的探索。更多内容可参考大神博客:https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/index.html ,http://baijiahao.baidu.com/s?id=1583577904006702816&wfr=spider&for=pc。
有关ProtocolBuf协议的解析过程探索可参考:https://www.cnblogs.com/Binhua-Liu/p/5577622.html
https://blog.csdn.net/kokjuis/article/details/72845163
https://blog.csdn.net/z69183787/article/details/52980720
Codecs.Redis 协议协议编解码器
下面是一段对Redis中协议的介绍:
Redis的客户端与服务端采用一种叫做 RESP(REdis Serialization Protocol)的网络通信协议交换数据。RESP的设计权衡了实现简单、解析快速、人类可读这三个因素。Redis客户端通过RESP序列化整数、字符串、数据等数据类型,发送字符串数组表示参数的命令到服务端。服务端根据不同的请求命令响应不同的数据类型。除了管道和订阅外,Redis客户端和服务端都是以这种简单的请求-响应模型通信的。 --------------------- 本文来自 cdai 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/dc_726/article/details/46565257?utm_source=copy
以”*”消息头标识总长度,消息内部还可能有”$”标识字符串长度,每行以\r\n结束
- 简单字符串(Simple String):以”+”开头,表示正确的状态信息,”+”后就是具体信息。许多Redis命令使用简单字符串作为成功的响应,例如”+OK\r\n”。但简单字符串因为不像Bulk String那样有长度信息,而只能靠\r\n确定是否结束,所以 Simple String不是二进制安全的,即字符串里不能包含\r\n。
- 错误(Error):以”-“开头,表示错误的状态信息,”-“后就是具体信息。
- 整数(Integer):以”:”开头,像SETNX, DEL, EXISTS, INCR, INCRBY, DECR, DECRBY, DBSIZE, LASTSAVE, RENAMENX, MOVE, LLEN, SADD, SREM, SISMEMBER, SCARD都返回整数。
- 批量字符串(Bulk String):以”$”开头,表示下一行的字符串长度,具体字符串在下一行中,字符串最大能达到512MB。”$-1\r\n”叫做Null Bulk String,表示没有数据存在。
- 数组(Array):以”*”开头,表示消息体总共有多少行(不包括当前行),”*”是具体行数。客户端用RESP数组表示命令发送到服务端,反过来服务端也可以用RESP数组返回数据的集合给客户端。数组可以是混合数据类型,例如一个整数加一个字符串”*2\r\n:1\r\n$6\r\nfoobar\r\n”。另外,嵌套数组也是可以的。
Netty中提供的几个与Redis有关的Handler为:
- RedisCommandDecoder:解析Redis协议,将字节数组转为Command对象。
- RedisReplyEncoder:将响应写入到输出流中,返回给客户端。
- RedisCommandHandler:执行Command中的命令。
详细的有关redis协议的处理将在后期更新,相关内容参考至:https://blog.csdn.net/dc_726/article/details/46565257
Handler、Transport、TransportLibuv
这是Netty中核心的东西,包含所有的数据转换和处理的内容,将在后期的学习中不断的完善。
以上内容是参考了很多网上的资源,感谢那些原创作者的贡献,仅作为个人学习使用。

