
Java记录一
1、数据输入
int rd = System.in.read(); char c = (char)rd; char[] buffer = new char[n]; try { System.in.read(buffer); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); }
import java.io.BufferedReader;
import java.io.InputStreamReader;
char[] buffer = new char[n]; BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); br.read(buffer); br.readLine();
import java.util.Scanner;
Scanner scan = new Scanner(System.in); if(scan.hasNextLine()) { String str = scan.nextLine(); } Scanner sc = new Scanner(System.in); if (sc.hasNext()) { String str = sc.next(); } if (sc.hasNextInt()) { int value = sc.nextInt(); }
2、数据输出
StringBuilder sb = new StringBuilder(); sb.append("this array is: "); sb.append('['); sb.append(1); sb.append(','); sb.append(3.14); sb.append(']'); System.out.println(sb.toString());
3、命名
number_1 ✅ number_2 ✅ $1234 ✅ _number ✅ 1_number ❌
number.value ❌
4、java成员访问权限修饰词: public, protected, private,包访问权限
若不提供任何访问权限修饰词,则为包访问权限,表示当前包中所有其他类对那个成员都有访问权限,但包外的类无法访问;
类既不可以是private也不可能是protected;对于类的访问权限,仅有包访问权限和public;
public成员可以被所有其他类访问;
protected成员可以被子类访问,并提供包访问权限;若没有protected修饰,对于从另一个包继承的类,它唯一可以访问的是源包的public成员;
private成员只能被包含该成员的类访问。
5、内部类
闭包是一个记录了一些信息的可调用对象,这些信息来自于创建它的作用域。
内部类是面向对象的闭包,它不仅包含外围类对象的信息(它拥有其外围类的所有元素的访问权),还自动秘密捕获一个指向外围类对象的引用。
在拥有外部类对象之前,不可能创建内部类对象,因为没有外围类对象连接,但如果创建的是嵌套类,就不需要对外围类对象的引用。
内部类在访问外围类成员时,就是用那个引用来选择外围类的成员。
成员内部类可以由public, protected, private修饰,它和外部类的成员访问权限一致。
局部内部类放在代码块或方法中,不能有访问控制修饰符,不能用static修饰。
定义内部类的目的:
1)用内部类实现某类型的接口,然后在外围类中创建该内部类对象,就能用到该接口的实现。
2)想创建一个类来辅助解决一个复杂的问题,但不希望该类是公共可用的。
定义过程:
1、在方法中定义类(局部内部类) 2、在作用域中定义类(局部内部类) 3、定义一个实现了接口的匿名类 4、扩展了有非默认构造器的类 5、匿名类中执行字段初始化 6、匿名类通过实例初始化实现构造
内部类即使是在作用域中被定义,但它是和其它类一起被编译的,在作用域之外,该内部类就不可用了。
匿名内部类看起来似乎是你正要创建一个基类对象, 实际上指的是创建一个继承自基类的匿名类的对象,并且返回的引用被自动向上转型为对基类的引用。
匿名内部类没有构造器,它实际上调用了基类的构造器,即使在创建匿名内部类对象时传递了参数,该参数也被传递给了匿名类的基类的构造器,并不会在匿名类内部被直接使用。
匿名内部类在访问外部定义对象时,编译器希望该参数引用是final的。
匿名内部类既可以扩展类,也可以实现接口,但不能二者兼备;如果实现接口,也只能实现一个接口。
嵌套类:将内部类声明为static。
嵌套类对象不需要其外围类的对象;不能从嵌套类对象中访问非静态的外围类对象。
接口中的类:
在正常情况下,不能在接口内部放置任何代码,但不包括嵌套类。接口中的任何类自动时public和static。若想创建某些公共代码,它们可被某个接口的不同实现共用。
6、继承自基类方法和接口方法的visibility
不能降低继承方法的可视化程度
class Basis { void f() {} } class A extends Basis { @Override //private void f() {} ❌ //void f() {} ✅ //public void f() {} ✅ }
//接口中的域都是隐式地为public,static和final,方法都是隐式地为public,,故在实现接口的类中方法必须被定义为public interface Interface { void f(); } class B implements Interface{ @Override //private void f() {} ❌ //void f() {} ❌ //public void f() {} ✅ }
7、Random
Random rand = new Random(); rand.nextInt(N); //int的数据范围控制在[0,N)之间
8、成员初始化
对于局部变量,java以编译时错误来保证使用前得到初始化;
类的基本数据类型成员被自动赋予了0初始值(后面会讲理由);类的非基本数据类型成员(即对象)在没有初始化前,获得特殊值null,若未初始化就尝试使用它,会出现运行时错误(即异常);
初始化可以在定义类成员变量的地方,也可以在构造器内初始化;其中,变量定义会在任何方法调用之前(包括构造器)得到初始化,且变量定义的先后顺序决定了初始化的顺序;
变量定义的初始化包括静态实例的初始化和非静态实例的初始化。其中,初始化的顺序是先静态对象,而后是非静态对象;
静态初始化只有在必要时刻才会进行,即当首次生成一个类的对象(构造器实际上也是静态方法),或者首次访问属于该类的静态数据成员或静态方法时,静态初始化的代码才执行,且只执行一次;
非静态实例的初始化在静态初始化之后,构造器执行之前;
创建对象过程的初始化顺序:
1)当首次创建该类的对象,或者类的静态方法/静态数据首次被访问时,java加载器查找用户类路径,并定位该类的.class文件。
2)载入.class文件,给静态域分配空间,执行静态初始化操作。
3)当用new创建对象时,先在堆上为该对象分配充足的存储空间。
4)将存储空间清零(故对象中所有基本类型数据都被设置成默认值,而引用被设置为null);
5)执行所有非静态字段定义处的初始化。
6)执行构造器。
9、构造器的调用顺序和构造器内部的多态行为
当创建一个类时,总是在继承,它会自动得到基类中所有的域和方法;但导出类只能访问自己的成员,不能访问基类的private成员,只有基类的构造器才有权限对自己的元素进行初始化。因此,必须令所有的构造器都得到调用,否则不能正确构造完整对象。若不能调用基类构造器(例如基类构造器为private访问权限),编译器会报错。当创建了导出类对象,该对象即包含了基类的子对象。
总的来说,导出类的构建过程从基类向外扩散,基类在导出类构造器可以访问它之前,就已经完成了初始化。
调用导出类构造器的顺序是:
1)将分配给对象的存储空间初始化为0;
2)先调用基类构造器(若没有默认的基类构造器,可在导出类构造器中显式地调用带参数基类构造器,调用基类构造器必须是导出类构造器总要做的第一件事);
3)按声明顺序调用导出类成员的初始化块;
4)再调用导出类构造器(2,3步遵循类成员初始化的原理(该文章第八点));
构造器内部的多态:
class A{ void draw() {print("A.draw()");} A() { draw();} } class B extends A{ void draw() {print("B.draw()");} B() {} } class Test{ public static void main(String[] s){ new B(); } } /*Output: B.draw(); *///
其中,基类的draw()方法被覆盖,这种覆盖是在导出类中发生的,但是基类构造器本来是想调用它的这个方法,结果变成了对导出类draw()方法的调用。
因此,在构造器中调用方法是非常不合适的行为,它使对象产生不稳定因素。在构造器中唯一能够安全调用的方法是final方法,因为这些方法不能被覆盖。
总结:使用类(new 一个新的对象)之前有三个步骤要做:
1)加载:由类加载器通过一个类的全限定名来获取定义此类的二进制字节流(即 查找字节码),(可能是.class文件,也可能是其它),载入并创建一个class对象,若该类有超类,先加载超类的.class文件;类的加载方式分为隐式加载和显式加载,用new创建对象时会隐式加载,用class.forName()是显式加载;
2)链接:1、检查:待加载的字节码的正确性,比如是否包含不良java代码;2、准备:为静态域分配存储空间3、解析:符号引用转换成直接引用;
3)初始化:为该类的超类初始化(先执行超类的静态初始化器),之后执行该类的静态初始化构造器(由静态域的赋值和静态代码块合并产生)。
三个必要步骤做完了,现在开始new一个对象:
4)先创建超类的对象,为非静态域分配存储空间;
5)超类执行非static的初始化块;
6)超类调用构造器;
7)再创建子类对象,为非静态域分配存储空间;
8)子类执行非static的初始化块;
9)子类调用构造器;
class A { public A(){ System.out.println("construct class A"); } { System.out.println("initialize class A"); } static{ System.out.println("static class A"); } } public B extends A { public B(){ System.out.println("construct class B"); } { System.out.println("initialize class B"); } static{ System.out.println("static class B"); } } /*Output: static class A static class B initialize class A construct class A initialize class B construct class B *///
10、数组
int[] a; //✅ int a[]; //✅
编译器不允许指定数组的大小。现在拥有的只是对数组的一个引用,且没有给数组对象本身分配任何空间;在java中可以将一个数组直接赋值给另一个数组,因为它只是复制了一个引用。
int[] a = {1,2,3}; //✅
int[] b ;
b = {1,2,3}; //❌
int[] c;
c = new int[]{1,2,3}; //✅
用特殊初始化表达式对数组初始化,数组的存储空间的分配由编译器负责,且必须在定义数组的地方才能使用该方法;还可以用new创建数组。数组元素的基本数据类型会自动初始化为0,非基本数据类型会获得null),这是由于分配存储空间后有将存储空间清零的步骤。
Arrays.toString()方法属于java.util库,将产生一维数组的可打印版本。
11、方法重载
每个重载方法都必须有一个独一无二的参数类型列表;
若方法参数列表声明了相同的参数,但顺序不同,也为不同;
方法接受实际较小的基本类型作为参数,若传入的实参较大,得将实参执行窄化转换,否则编译器报错。
若写的类没有构造器,编译器会自动创建一个和其类具有相同访问权限的默认构造器;若自定义了一个构造器,编译器将不再创建默认构造器。
若类中有多了构造器,且想在某个构造器中调用另一个构造器,用this,但this不能调用两个构造器,且必须将构造器的调用置于起始位置,否则编译器报错。
除构造器外,编译器禁止在其它任何方法中调用构造器。
class A{ int a; A(String msg){} A(int T){} A(){ //✅ this.A("test"); a = 10; } A(){ //❌ a = 10; this.A("test"); } A(){ //❌ this.A("test"); this.A(10); } void f(){ //❌ this.A(); } }
12、Thread类
实现多线程有三种方式:
1)继承Thread类,重写run()方法。Thread类实现了Runnable接口,且继承了Thread类就不能继承其它类了;
2)实现Runable接口,实现run()方法;
3)实现Callable接口,线程结束后有返回值;
13、持有对象(对象集合)
集合框架图(不包含Queue) 简化版(去除抽象类和弃用类)

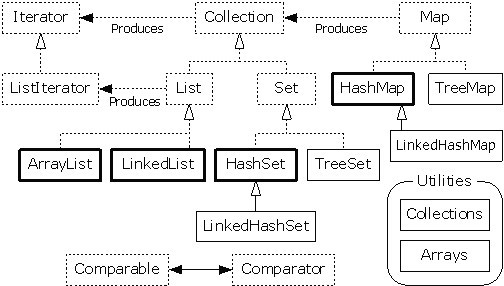
接口:
Collection:独立元素的序列;
List:按照插入顺序保存元素,不关心重复;
Set:不能有重复元素;
Queue:按照排序规则产生顺序;
Map:键值对;Map允许将null作为键,也允许将null作为值,对于每一个键,Map只接受一次存储;
Collection.addAll()只接受另一个Collection对象作为参数,而Collections.addAll()和Arrays.asList()接受可变参数列表作为参数;Collections.fill()只能替换已有的元素,不能添加新的元素;
Arrays.asList()的输出为List,但其底层表示的是数组,不能调整尺寸;若试图add()或delete(),将得到运行时异常;Collections.unmodifiableList()产生不可修改的List列表;
List<int[]> list1 = Arrays.asList(new int[] {2,3,4}); List<Integer> list2 = Arrays.asList(2,3,4);
Collection:有add, addAll, remove, removeAll, contains,containsAll, retainAll(两个List的交集), clear, toArray, isEmpty, size (不包括随机访问get)
将Collection转化为对应Array数组:
// 以List为例 List<Integer> list = new ArrayList<Integer>(); Integer[] arr = (Integer[])list.toArray(new Integer[]{});
对Array数组进行内置排序:
int[] arr = new int[]{1,3,2}; Arrays.parallelSort(arr);
ArrayList:底层由数组支持,有get, set, indexOf, subList方法;
LinkedList:底层由双向链表实现;除了List,还实现了Deque接口(继承自Queue),添加了用作栈、队列、双端队列的方法;有getFirst, element, peek; removeFirst, remove, poll; addFirst, add; addLast, offer, removeLast;
Set:具有与Collection完全一样的接口;
Set和List之间的转换:
Set<Integer> set = new HashSet<Integer>(); List<Integer> list = new ArrayList<Integer>(); set.addAll(list); //✅ Collections.addAll(set, list); //❌ list.addAll(set); //✅ Collections.addAll(list, set); //❌
Map:有containsKey, containsValue, keySet, values, entrySet, get, putAll;Map的键是Set, 值是Collection;
HashMap:使用了特殊的值,即hashcode来取代了对键的缓慢搜索。hashcode是相对唯一的,它通过将对象的部分信息转换生成的。所有java对象都能产生hashcode,若使用object的hashcode(),它默认使用对象的地址计算hashcode。任何键都具有equals()方法,若用于HashMap,则键还具有hashcode()方法;
HashMap的结构:一个hashcode查询数组(通常称为bucket)和多个LinkedList列表构成,其中Linkedlist的结点是Map.Entry ;通过键对象生成一个hashcode值,将其作为数组的下标,找到散列数组对应的槽位,每个槽位对应一个LinkedList列表,遍历该列表,对每一个结点使用equals()方法完全确定对象的身份。
因为散列表是一个数组,当HashMap和HashSet的负载情况达到负载因子时,容量将自动增加其槽位,实现方式是重新申请一个更大的数组,将现有对象分布到新的bucket中(再散列)。
BitSet:高效率地存储大量“开/关”信息,最小容量是long64位,若存储内容较小,则比较浪费空间,速度比本地数组稍慢。
14、对List<List<T>>进行排序
//即使元素类型为基本数据类型的包装类,但list.sort(null)和Collections.sort(list,null) //只能对List<T>排序,不能对List<List<T>>排序 //若想对其排序,只能实现Comparator接口,自定义比较规则 List<List<Integer>> result = new ArrayList<List<Integer>>(); result.sort(new Comparator<List<T>>() { @Override public int compare(List<T> l1, List<T> l2) { return l1.get(0).compareTo(l2.get(0)); //✅ // if(l1.get(0)<=l2.get(0)) return 0; //❌ // else return 1; // if(l1.get(0)<l2.get(0))return -1; //✅ // else if(l1.get(0)==l2.get(0))return 0; // else return 1; } });
15、反射
查询类型信息:instanceof和isInstance()的结果一样,指的是“你是这个类或这个类的派生类吗?”考虑了继承;而==和equals()的结果一样,指的是确切的某个实际对象类型,没有考虑继承。
对于RTTI来说,编译器在编译时就要打开和检查.class文件,而对于反射来说,.class文件在编译时不可取,在运行时才打开和检查.class文件。
java.lang.reflect类库包含field\method\constructor类,这些类型对象由jvm在运行时创建;
16、代理
代理是基本的设计模式,代理模式在访问实际对象时引入了一定程度的间接性,在这个间接性中,可以织入多种用途;其特征是代理类和委托类有同样的接口。代理类的对象本身不真正实现服务,而是通过调用委托类对象的方法来提供服务。
静态代理:代理类和委托类实现了同样的接口,代理类中包含接口对象,且通过构造器实现了委托类对象的依赖注入;
interface Interface{ void doSomething(); } class realObject implements Interface{ public void doSomething(){} } class OneProxy implements Interface{ private Interface proxied; public OneProxy(Interface proxied){ this.proxied = proxied; } public void doSomething(){ proxied.doSomething(); } }
动态代理:在动态代理上的所有调用都会被重定向到单一的调用处理器InvocationHandler上,该接口有一个invoke方法,该方法会传递进一个代理对象,,在该invoke方法内部,该方法内部会实现对代理的调用。
class DynamicProxyHandler implements InvocationHandler{ private Object proxied; //委托类对象 public DynamicProxyHandler(Object proxied){ this.proxied = proxied; } public Object invoke(Object proxy, Method method, Object[] args){ return method.invoke(proxy,args); //完成proxy类对象的请求转发 } } class OneDynamicProxy{ public void doConfiguration(){ RealObject real = new RealObject(); //Proxy.newProxyInstance()创建动态代理,它需要一个接口类的类加载器,一个希望实现的接口列表,一个InvocationHandler接口的实现 Interface proxy = (Interface)Proxy.newProxyInstance(Interface.class.getClassLoader(),new Class[]{Interface.class}, new DynamicProxyHandler(real)); } }
17、Java内存结构和内存溢出异常
Java运行时数据区域:程序计数器、虚拟机栈、本地方法栈、堆、方法区、运行时常量池;
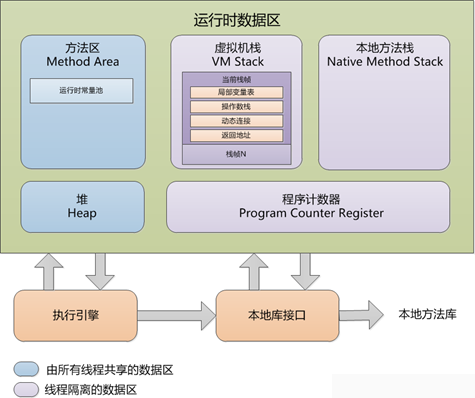
1)程序计数器:记录当前执行的字节码指令的地址,字节码解释器可通过控制该值选取下一条指令;每条线程独占一个程序计数器,各线程计数互不干扰;若正执行native方法,则程序计数器值为空;
2)虚拟机栈:每个方法创建一个栈帧,存储局部变量表、操作数栈、动态链接(栈帧包含一个指向运行时常量池中方法的符号引用,转化为直接引用即为动态链接)、方法出口(返回地址)等;局部变量表编译时可知,栈帧分配的局部变量空间完全确定,运行时不变化;规定了两种异常:
(1) 若线程请求的栈深度大于允许深度,抛出StackOverFlowError;(栈内存溢出)一般是由于程序中存在死循环或者深度递归调用造成的,
(2)若虚拟机栈动态扩展时无法申请足够内存,抛出OutOfMemoryError; 即栈大小设置太小。
3)本地方法栈:和虚拟机栈差不多,但只为native方法服务;
4)堆:存储对象实例、数组和多个划分的线程私有的分配缓冲区TLAB;有异常:
(1) java.lang.OutOfMemoryError: Java heap space ------>java堆内存溢出,一般由于内存泄露或者堆的大小设置不当引起。内存泄漏:查看泄露对象到GCRoots对象的引用链,该引用链导致GC无法回收泄露对象。
5)方法区:存储类加载信息,常量、静态变量、即时编译器编译后的代码,主要用于对class类型的装卸,回收常量池;
(1) java.lang.OutOfMemoryError: PermGen space ------>java永久代溢出,即方法区溢出了,一般出现于大量Class或者jsp页面,或者采用cglib等反射机制的情况,有大量的Class信息存储于方法区,另外,过多的常量尤其是字符串也会导致方法区溢出。
6)运行时常量池:方法区的一部分,存储编译期生成的字面值常量和符号引用(放在常量池中),解析出来的直接引用,运行时新的常量;
7)直接内存:不受Java堆大小的限制;
使用过程:当jvm遇到一个new指令,先检查该指令参数能否定位常量池中的一个类的符号引用,并检查该类是否被加载、解析、初始化,若无,则执行这些步骤。然后为类实例分配存储空间,并将该新分配的空间清零。
对象的访问:程序通过栈上的引用信息找到堆上具体对象地址,访问包括句柄访问和直接指针访问;
1)句柄访问:堆中划分一块内存作为句柄池,栈上引用存储句柄池中的句柄地址,句柄包含实例数据地址(指向堆中的实例)和类型数据地址(指向方法区中类信息),共三次指针定位开销;
2)直接指针访问:栈上引用存储堆中对象地址,该地址存放了类型数据的地址和实例数据本身,共两次指针定位开销。
18、Java垃圾收集器与内存分配策略
强引用、软引用、弱引用、虚引用;
可达性分析:以GCRoots对象(栈中的引用、类静态对象、常量对象)为起始点,确认其引用链不可达的对象是不可用的;
两次标记:第一次发生在GC发现引用链不可达的对象,做好标记,并将对象放入f_queue;第二次发生在GC遍历f_queue中的对象,做好标记;
回收方法区:废弃常量和无用类(无用类包括该类的所有实例均被回收,该类的类加载器被回收,该类的class对象没被引用)可以回收。
垃圾收集算法:
1)标记-清除算法:标记完成后统一回收对象,该处理将产生大量不连续内存碎片;
2)标记-整理算法:标记完成后,将存活对象移动至一侧的边界,清理掉其它内存;
3)复制算法:将内存划分为大小相等两块,一次只使用一个内存块,当块中内存分配完后,将存活对象复制到另一块,然后对整个内存半块进行清理回收;或者内存划分为新生代区和老年代区,其中新生代区分为一个eden区和二个survivor区,比例为8:1:1,每次只使用eden和一个survivor(另一个survivor作为轮换备份),回收时,将存活对象一次性复制到survivor区,当该survivor区空间不足时,老年代区分配担保;
4)分代收集:新生代用复制算法,老年代用标记-整理\清除算法;
MinorGC和FullGC的触发条件:https://blog.csdn.net/qq_28165595/article/details/82633308
Major GC 是清理永久代,Full GC 是清理整个堆空间—包括年轻代和永久代,但许多 Major GC 是由 Minor GC 触发的;
19、jvm类加载机制
jvm加载类的过程:
当我们执行一个java程序时,
1)java.exe帮助找到jre,接着找到jre内部的jvm.dll,这是一个jvm,然后加载动态库,激活jvm;
2)jvm激活后,进行初始化;初始化完成后,产生第一个类加载器-Bootstrap Loader启动类加载器;
3)Bootstrap Loader加载Launcher.java中的ExtClassLoader扩展类加载器,并将其parent设为null;
4)Bootstrap Loader加载Launcher.java中的AppClassLoader应用程序类加载器,并将其parent设为ExtClassLoader;
加载对应类:
1)Bootstrap Loader加载存放于%JAVA_HOME%lib中的类库;Bootstrap Loader无法被java程序直接引用;
2)ExtClassLoader加载存放于%JAVA_HOME%libext中的类库;java程序可使用;
3)(默认)AppClassLoader加载用户类路径classpath上指定的类库;java程序可使用;
类加载器:将类加载阶段获取二进制字节流的动作放到虚拟机外部去实现,实现该动作的代码称为“类加载器”;
对于任意一个类,由该类和加载它的类加载器共同确立其在jvm中的唯一性;比较两个类是否相等,只有在这两个类是同一类加载器加载才有意义;否则,即使这两个类来源于同一个Class文件,被同一个虚拟机加载,只要类加载器不同,这两个类必定是不相等的。这里的“相等”,包括使用instanceof关键字做对象所属关系判定等情况。
双亲委派模型(父子类加载器关系使用的是组合而非继承):启动类加载器<-扩展类加载器<-应用程序类加载器(默认)<-自定义类加载器
若一个类加载器收到加载请求,先把该请求委派给父类加载器,递归到顶层,只有当父加载器反馈无法加载请求,再将请求向下传递,子类加载器尝试加载;实现双亲委派的代码都在java.lang.ClassLoader的loadClass()方法,先检查是否已经被加载过,若没有加载则调用父类加载器的loadClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。如果父加载失败,则抛出ClassNotFoundException异常后,再调用自己的findClass()方法进行加载。
使用双亲委派模型的好处在于Java类随着它的类加载器一起具备了一种带有优先级的层次关系,例如java.lang.Object类在程序的各种类加载器环境中都是同一个类。相反,如果没有双亲委派模型,那系统中将会出现多个不同的Object类,程序将混乱。如果开发者尝试编写一个与核心类库中重名的Java类,可以正常编译,但是永远无法被加载运行。
破坏双亲委派模型:当用户使用代码热替换、模块热部署的技术,每个程序模块bundle都有一个自己的类加载器(应用程序类加载器(用户指定classpath上的类库)),当需要更换bundle时,把bundle连同类加载器一起换掉。
20、jvm执行引擎、热点代码、热点检测
hotspot虚拟机使用解释器和jit编译器并存的架构,当程序需要迅速启动和执行时,解释器首先发挥作用,立即执行;在程序运行后,随着时间的推移,jit编译器逐渐发挥作用,把热点代码编译成本地代码(本地代码 即 特定的处理器硬件平台对应的指令代码,又叫原生型指令码),以获取更高的执行效率。解释器执行可节约内存空间,jit编译器执行可提升运行时的执行效率;
jit编译器:花费少许的编译时间来节省稍后相当长的执行时间;
参考文章:JVM即时编译(JIT)
21、Cookies和Session的区别
Session和Cookies同样都是针对单独用户的变量(或者说是对象好像更合适点),不同的用户在访问网站的时候都会拥有各自的Session或者Cookies,不同用户之间互不干扰。
Session 是一个抽象概念,将 User Agent 和 Server 之间一对一的交互,抽象为“会话”; Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookies是一个实际存在的东西,Http 协议中定义在 Header 中的字段,它是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式(Session 因为 Session id 的存在,通常要借助 Cookies 实现);
22、状态码301和302的区别
共同点:用户都可以看到原url被重定向到一个一个新的url,然后发出请求;
差异:301是永久重定向,而302是临时重定向;
301 Moved Permanently 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一;除非额外指定,否则这个响应也是可缓存的。
302 Found 请求的资源现在临时从不同的URI响应请求,客户端应当继续向原有地址发送以后的请求;只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。

