
面向分布式数值计算场景中的传输数据压缩
看了博文:
https://juejin.cn/post/6969787751084654605
本文写下自己的学习、思考和设想。
=================================================
背景介绍:
传统的分布式数值计算一般要求极高的实时性,尤其是对于小数据量传输的低时延,比较典型的应用场景就是物理学、航天等领域中的流体力学计算问题、空气动力学问题、天气预测问题等等,这些都是比较传统的场景,这样的场景往往不需要较多的输入数据而是需要较为复杂的高耦合的计算,我们可以把这种场景简单的看做为对一个极为复杂的数学公式进行求解计算的过程,在这样的应用中我们所使用的计算范式一般是MPI这种消息传递的计算方法。但是近些年来由于互联网的高速发展产生了巨大的生成数据,由此再次兴起了以数据为驱动的机器学习范式,与传统的计算范式所不同,机器学习的计算可以以数据为区分点来划分计算,这类型的数据一般数据量较大,而且数据结构也较为复杂,同时由于计算的耦合性没有传统的计算那么高,数据的传输既可以使用同步的方式也可以使用异步的方式,甚至很多情境下对时延要求也不是很高,而又有的场景下对于并发性有要求,对于这样的需求传统的MPI计算范式就不是很适用了,这样也就再次兴起了RPC计算范式。总结的说下,传统的以计算结构为切分的分布式计算适合适用MPI通信方式,而以数据为驱动和划分的分布式计算则适合使用RPC这样的通信方式。
RPC现状:
现在设计的RPC通信方式虽然是数据驱动的分布式计算所常用的方式,但是由于数据类型和场景需求的不同还可以分为偏重计算业务和单纯偏重通信为主。本文所要讨论的就是面向分布式数值计算场景,这样场景中传递的数据类型比较单一,基本可以视为以float类型为主的数据,如果使用python语言的话我们可以把传递的数据全部看做是numpy的矩阵数据,由于本人平时面对的应用场景就是以这个为主,因此本文就是以此为示例前提来进行讨论的。
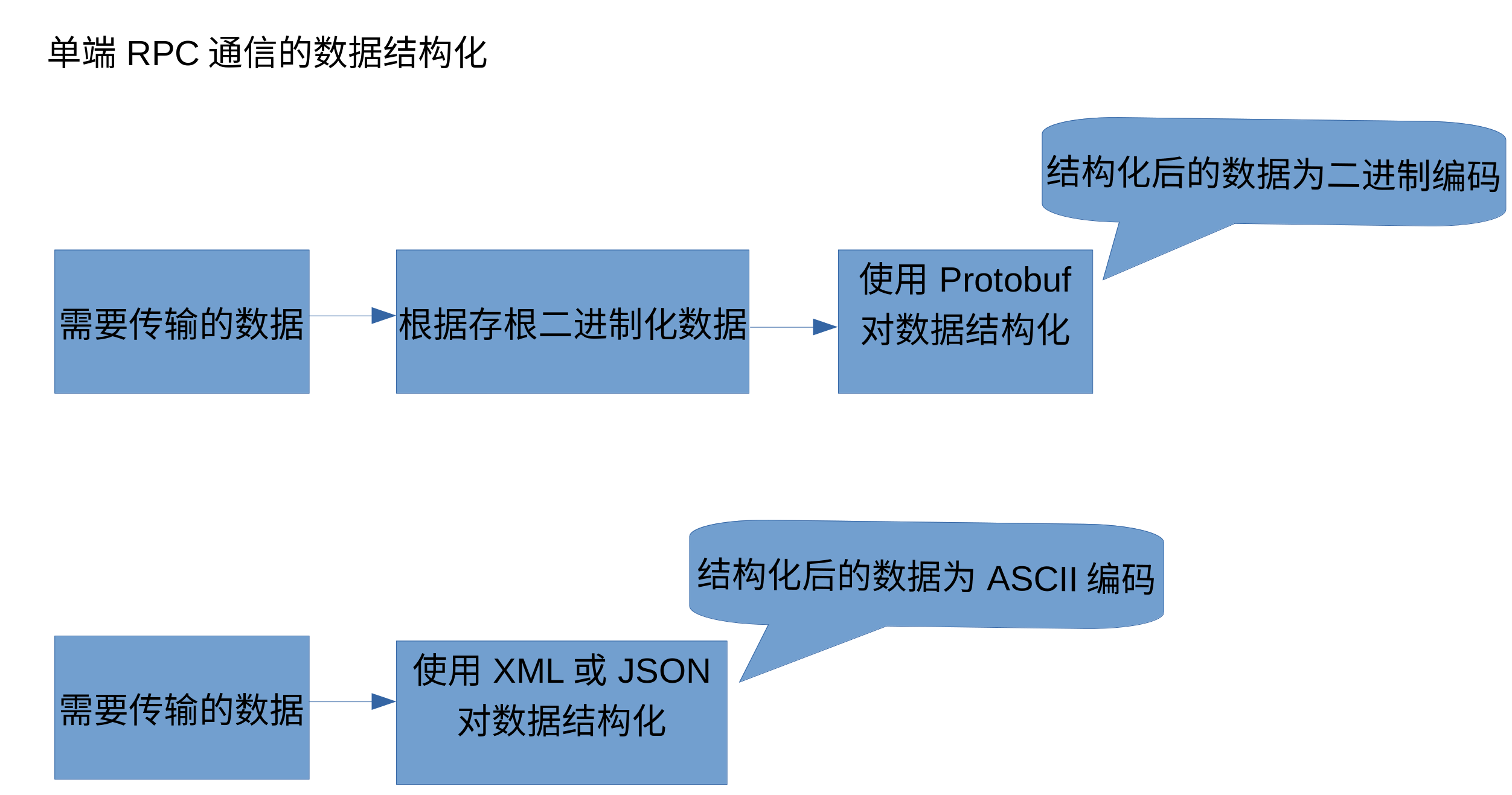
===========================================
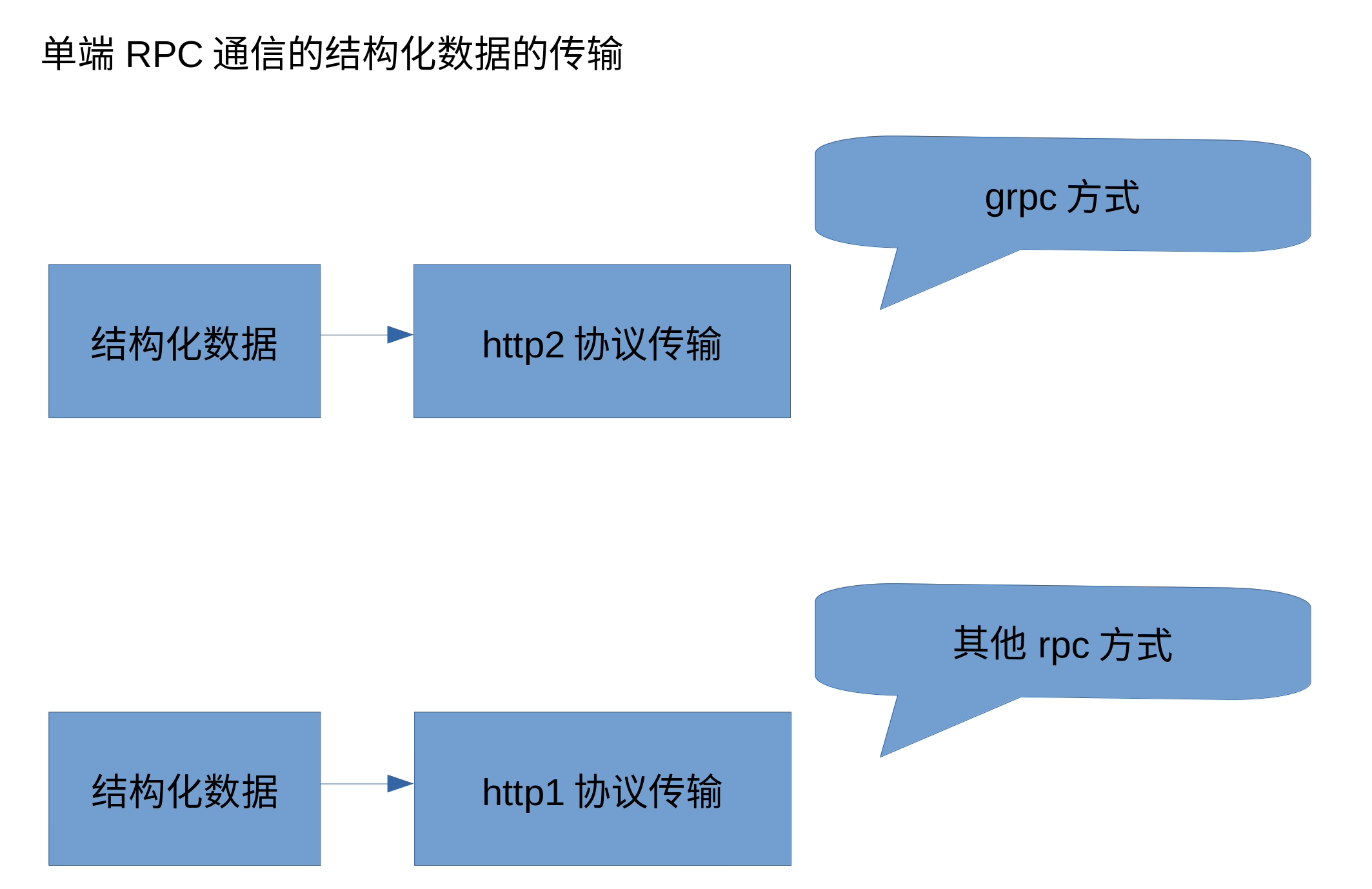
=============================================
上面两个图分别描述了grpc和其他rpc的一些通信示意图。上面的两个图但是发送方的结构,也就是可以理解为是编码,而收方的解码这里就不表述了。
可以看到发送方的操作可以分为两部分:1,发送数据的结构化;2,结构化后的数据的应用层协议控制。
首先说下第二部分的应用层协议,不论是http1还是http2都是每个发送的数据包可以分成包头及包内数据两部分,而其中的包内数据就是第一步操作中的结构化的数据,也就是我们要发送出去的数据。为什么要有这个http协议的包头呢,或者说为什么要有http协议在里面呢?其实写过tcp传输程序的人都知道我们如果在tcp协议层面上发送数据那么接收数据的一方能做的就是循环的从网络数据的缓存池中取出数据,而这些数据该如何解析是不知道的。
举个例子:
比如发送方要发送两个文本,第一个文本是40B大小,第二个文本是80B大小,接收方接收到120B大小的内容,到时接收方不知道后续还有没有数据发送过来,同时接收方也不知道这120B大小的内容是一个文本的内容还是两个文本的内容,也有可能是三个文本的内容,而HTTP协议做的就是告诉接收方接收的120B大小的内容是属于两个文本的,每个文本的大小是多少,后续还有没有数据要发送过来。这就是应用层协议要做的事情,不论是HTTP1还是HTTP2都是面向较为广泛的应用类型的,但是如果是只为数值计算场景所设计我想可以有一个更加简单的协议。

=====================================================

或者:

其中,动作ID是指数据发送是正常速度发送,暂停,结束等动作;时间戳是指发送数据时有效的时间,在机器学习中可以设置为梯度更新的次数;检验和根据可以取消。
因为本文考虑的应用层协议是面向分布式数值计算的,换句话说是面向分布式机器学习的,因此给出了上面的极简设计。不论是HTTP1还是2最初的设计都是给网页传输使用的,而对于分布式机器学习来说网络的应用层协议适当的简单些也是完全可以的,当然这也只是个人的观点。
之所以不设计包ID是因为我个人认为对于分布式计算环境不需要在应用层面上再切包然后乱序发送,这样对发送性能提高不大还导致复杂性,毕竟计算场景下传输的数据结构都比较单一,单TCP连接下也不会有太高并发要求。
不设计会话ID是个人认为在本文背景下单TCP连接下只远程调用单一的函数,在现有的分布式机器学习中远端调用的会话都是以一个为主而不是多个。
其实更为极简的设计是没有动作ID,不过这个可能性没有多考虑,甚至检验和也可以考虑去掉。
最终的极简设计:

=======================================================
而HTTP2的帧(包)设计:
https://blog.csdn.net/qq_40276626/article/details/120412462
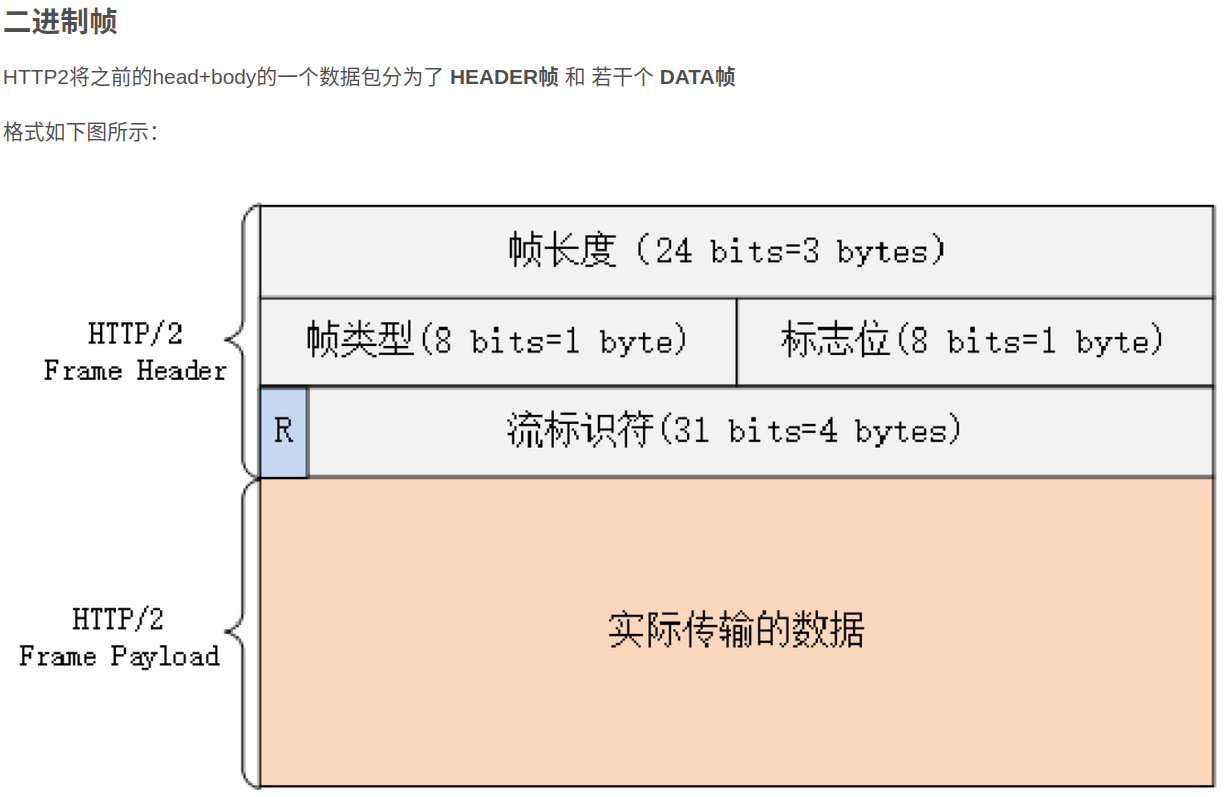
本文之所以给出分布式计算的极简网络应用层设计是因为现在一般用的HTTP1和2协议太复杂,而且对于至少是现在的分布式计算的网络通信需求本身也用不到这么复杂的协议。
===========================================================
而对于发送数据的结构化,XML,JSON都是比较容易懂的,而GRPC中使用的protobuf可能就相对的复杂和抽象些。
如果是分布式机器学习的话,传输的数据一般都是float32或int类型的,可能是单个数值,但是更大的可能性是一个数据矩阵,而如果是python数据的话更可能使用的是numpy数据矩阵。
https://juejin.cn/post/6969787751084654605对数据的结构化给出了一些解释:

而对于分布式的机器学习,数据的类型可以在建立tcp连接的时候就可以声明,但是数据的长度是固定还是不固定的却很难解决。比如传递两个numpy矩阵,A和B,类型都是float32,但是A是不定长的,B是定长的,比如B为16*16,那么我们一次性传递A和B矩阵就应该带有A的长度和维度。

如上图,A数据维度为3,即4*4*4,总长度为64。而B数据长度为64,由于是固定长度已经早就由双方约定。这样的结构化数据就比较好就行编解码了。
===========================================================
另外说一下,在http2中是要对结构化数据进行gzip压缩的从而减少数据体积,但是如果没有高效的压缩库比如使用python的压缩库可能造成的压缩耗时要高于不压缩的传输耗时,这样的情况下就没有必要使用gzip压缩了,当然如果你是用C语言写的协议自然可以高效的进行gzip压缩了,不过本文一直都是在python语言设想下讨论的,因此就不这样建议了。
===========================================================
相关资料:
https://zhuanlan.zhihu.com/p/127142107
https://blog.csdn.net/qq_40276626/article/details/120412462
https://juejin.cn/post/6969787751084654605
posted on 2022-05-20 10:45 Angry_Panda 阅读(108) 评论(0) 编辑 收藏 举报


