
【转载】 《Human-level concept learning through probabilistic program induction》阅读笔记
原文地址:
https://blog.csdn.net/ln1996/article/details/78459060
---------------------
作者:lnn_csdn
来源:CSDN
--------------------------------------------------------------------------------
花了一周多的时间读了一篇论文《Human-level concept learning through probabilistic program induction》(《通过概率规划归纳进行类人概念学习》),这是15年12月science的一篇封面文章,主要解决了小样本情况下的计算机学习问题。第一次读论文,而且是英文论文还是有点吃力,参考了很多其他的博客和新闻评论,自己也总结出了一些阅读笔记。
背景:
我们知道,人类通过几个简单的例子就能够学会新的概念,但是对于传统的机器学习算法,却需要几十甚至是几百倍的数据训练才可以达到这样的程度。
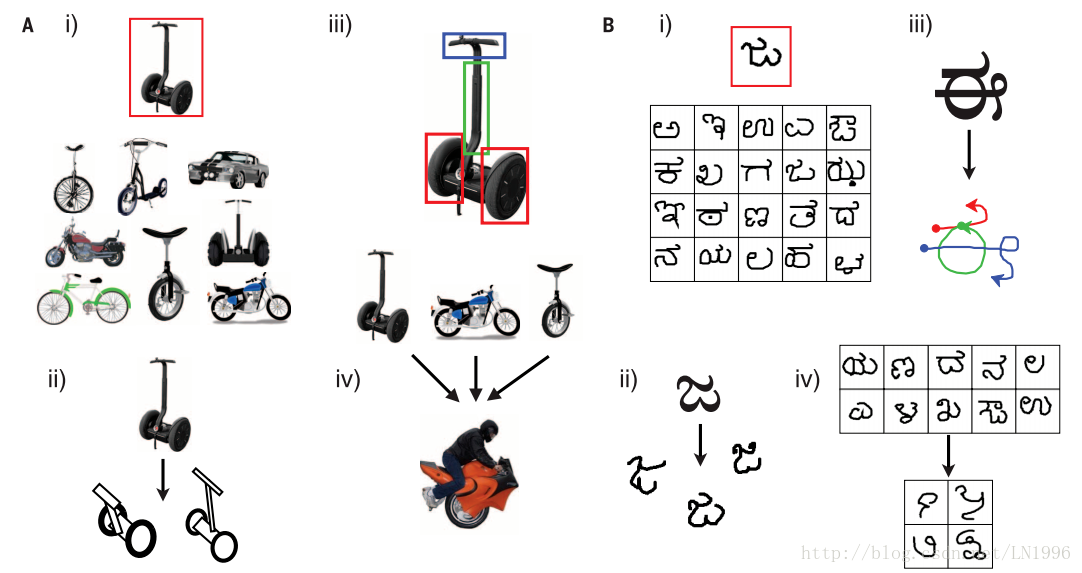
举个例子:
我们看到上图中左上角这个两轮车,我们一眼看到它的时候便知道它是代步工具;还可以根据它衍生出其他形状的两轮车;将这个二轮车解析为扶手、轮胎这一类更小的部件;还可以将它和其他的代步工具联合起来创造出其他的代步工具。
对右边的这个图也是一样,看到一个字符便知道它是那个字符系统里的;手写字符可以写出其他的变体(人每次写字的字迹都是不一样的);解析字符的笔画;根据一些字符,解析他们的特点创造出新的字符。
这说明,人类具有从极少量的数据中学习丰富概念的能力:归类、派生、解析、创造。
本文试图模仿人类的学习能力建立一个学习模型,从稀少的数据中形成丰富的概念。
BPL:
文章提出了BPL(贝叶斯规划学习)框架来进行类人概念学习。BPL框架具有三个重要的特性,分别是合成性、因果性、学习如何学习。合成性的意思是概念是由更简单的基本元素构成的,比如说一个字符是由更简单的笔画构成的;因果性指的物体是如何生成的这一抽象的关系。我们看到一个字符,就知道它是怎么写出来的,由哪些笔画构成、这些笔画间有什么关系;学习如何学习则指的是过去的概念知识能够帮助学习新概念,简单地说就是BPL可以从现有的字符中抽象出其部件,然后根据不同部件的因果关系创造新的字符。
BPL框架把上述三个特性结合在一起,具体思路是:每一个“概念”均由多个简单的“基本元素”组成,“基本元素”之间有位置、时间、因果等关系,“基本元素”根据这些关系选择性的“组合”,就得到一个相应的“概念”的实例。将上述关系在BPL模型中进行参数化,通过一定的概率计算,自动的学习这些参数。
文章的主要内容:把BPL应用在手写字符的单样本概念学习中,实现了模拟手写字符,一次性分类手写字符,产生新的手写字符。 一些定义:
在学习这三个应用之前,先了解一些定义:

模拟手写字符:

将BPL应用在模拟手写字符这个过程分为两个部分:type level和token level。Type level主要是构建字符的解析结构,token level是根据解析结构产生手写字符的过程。
先来看type level:
(1)从背景集合的经验分布(就是前期的一些统计规律)中取样k个part,每个part中取样n个subpart;
(2)从背景集中学习得到离散笔画集,构造一个part的模版;
(3)通过采样每个subpart的一些控制点和尺度参数,将part表示成参数化的曲线(到这一步已经得到了笔画的轮廓,轨迹);
(4)根据relation(attached along,attached at start)得到笔画间粗略的位置关系(独立放置、开始、结束、还是沿着之前的subpart);
这时候就已经得到了字符的解析结构,然后进入到token level的过程:
(1)引入适当的噪声来生成笔画曲线S(m);
(2)笔画开始位置L的精确选定,从背景集中能够得到笔画的空间位置关系,结合上一笔,取样即可得到part的开始位置;
(3)进行放射变换A(m)以及加入适当的噪声;
(4)通过随机补偿函数即可得到二值图像,用灰色墨水画出轨迹。
一次性分类问题:
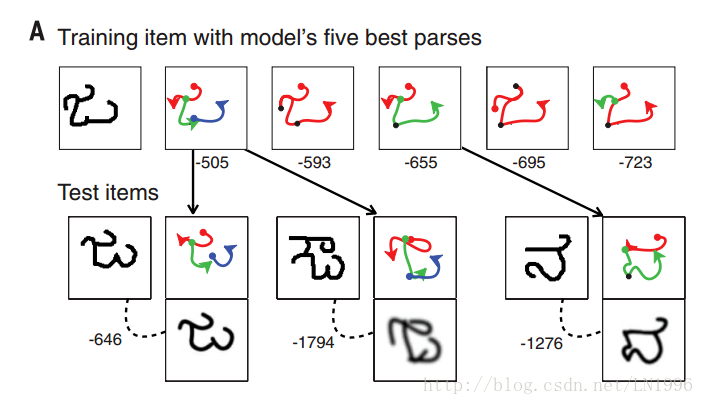
给出一个训练图像,5个训练图像的解析及得分,每个训练图像都能改造成测试图像。
选取fast bottom-up方法引入一系列的候选解析,使用连续优化、局部搜索形成离散后验概率分布的近似值,得分高的即为最佳解析。
这里的得分是log 后验概率
得分越高,重构的图像越清晰,说明他们更有可能属于同一类。
产生新字符:
问题定义:给定一个背景集中的几个例子,根据它们的特征创造出属于该背景集的新字符。
解决方案:对这些例子进行解析,重新生成“经验”,即这个背景集中最常出现的笔画数目、子笔画的样式、相互位置关系等等,然后再根据这一经验去创造新的字符。
实验结果分析:
研究者对这个AI系统进行了几项测试来检验BPL模型。
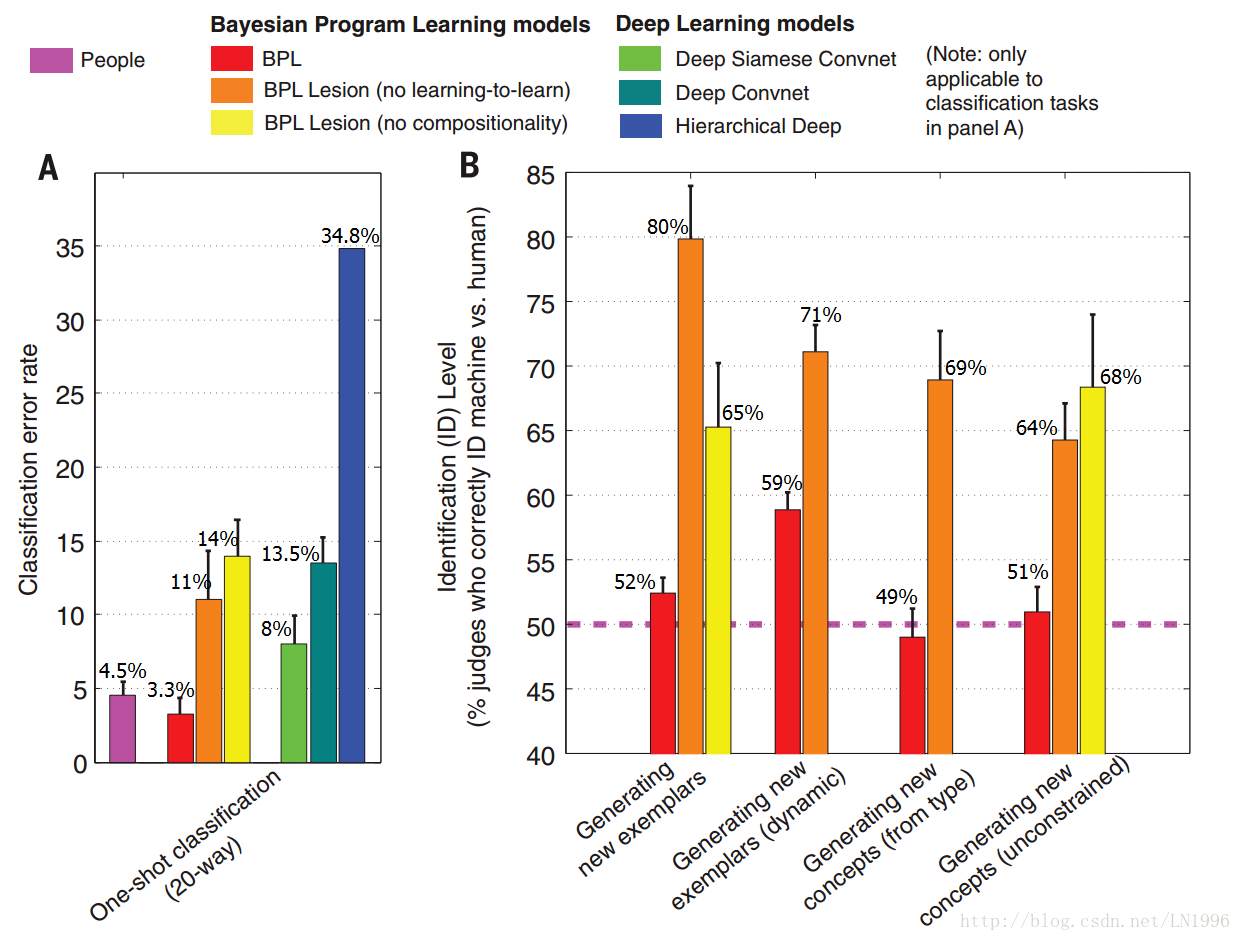
左边这个图是一次分类(one-shot classification)的测试结果,研究者给定一张字符图片,要求人类测试者和BPL机器从20张图片中选出和他同类的图片。人的错误率只有4.5%,BPL表现出了更低的错误率,只有3.3%,而深度卷积网络表现出了13.5%的错误率,HD模型的错误率最高34.8%,即使是优化后的深度卷积网络也有8%的错误率。因此BPL的优势是可以在概念的学习中对隐含的因果关系进行建模。
在这个一次分类(one-shot classification)实验中,研究者还对缺少“学习如何学习”或“合成性”特性的BPL模型做了测试,分别表现出了11%和14%的错误率,说明这两个特性对BPL起着重要作用(缺少“学习如何学习”(no learning to learn)的意思是破坏之前设计好的type level和token level生成模型的超参数,比如以token level为例,原来设计好的参数可能是让along这种位置关系的两个笔画在一定范围内进行连接,破坏后则是完全随机的一种连接方式。缺少“合成性”(no compositionality)的意思是说把字符看成一个整体,通过一条样条曲线进行拟合,而不是像之前一样做笔画和子笔画的拆分。)
右边这个图是做了一个视觉图灵测试,研究者向BPL系统展示它从未见过的书写系统中的一个字符例子,并让它写出同样的字符。并不是让它复制出完全相同的字符,而是让它写出9个不同的变体,就像人每次手写的笔迹都不相同一样。与此同时,人类测试者也被要求做同样的事情。最后,通过视觉图灵测试来比较人和机器产生的例子——研究者要求一组人类裁判分辨出哪些字符是机器写的,哪些是人类写的。 这个测试的评价参数为Identification level,理想情况下ID level的值为50% ,即裁判不能区分哪些是机器产生的,哪些是人产生的,最差的表现情况下ID level的值是100%,就是说人类裁判完全能够正确区分人类和机器。从图中可以看出BPL的ID level是52%,非常接近理想值。而缺少“学着如何学习”或“合成性”特性的BPL模型的ID level分别为80%和65%,说明这两个特性对BPL模型的拟人化非常重要。
为了更直白地评价分解情况,研究者通过另外一个动态视觉测试来完成此项任务,并且换了一批裁判,每个裁判会被展示人类和机器写同一个字符的笔画过程,这时BPL在这一视觉图灵测试上的表现为59% ID level,不是那么理想了。如果再把学习到的笔画的书写顺序等先验知识去掉,结果仅为71% ID,因此捕捉正确的动态的因果关系对于BPL来说非常重要。
后面的两组实验就不做具体讲解了,总之研究者通过这些实验告诉我们,BPL通过了视觉图灵测试,大多数人类裁判已经无法对BPL模型生成的字符和人类手写字符进行有效的区分了。
总结:
作者在本文中基于贝叶斯准则提出了一种计算模型,用来模拟人类的学习能力,将其用于手写字符的单样本概念学习中,实现模拟手写字符、一次性分类手写字符、产生新的手写字符。在具有挑战性的一次性分类任务上,该模型实现了人类层面的性能且胜过最近的深度学习方法。该论文也通过“视觉图灵测试”探索了模型创造性泛化能力,表明该模型在很多方面和人类的行为是极为相似的。
BPL的意义在于:模仿了人类对新事物的认知,通过少量的样本学习出一类事物。不同于目前主流的运用大量数据训练复杂模型的深度神经网络,BPL提供了学习模型的一种新思路。
posted on 2019-07-02 14:48 Angry_Panda 阅读(770) 评论(0) 编辑 收藏 举报


