
Python高级应用程序设计任务
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
名称:爬取虾米音乐排行
2.主题式网络爬虫爬取的内容与数据特征分析本次爬虫主要爬取虾米音乐排行榜和评论数
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)本次设计方案主要使用request库和beautifulSoup库对网站访问,records数据持久化。
技术难点主要包括对虾米音乐网站页面的结构分析。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
打开虾米音乐的官网,点击鼠标右键按“查看元素”或按“F12”打开网页源代码,查找自己所要爬取的内容
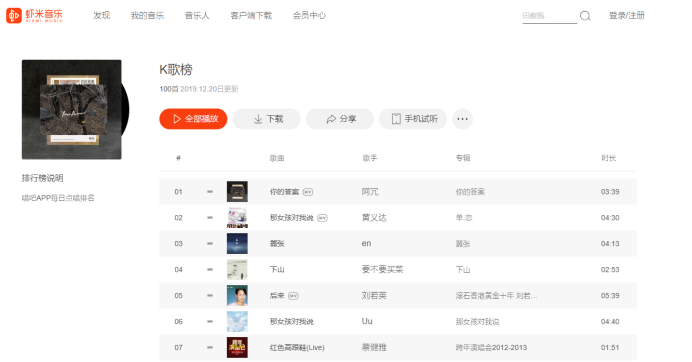



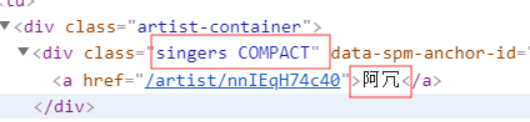

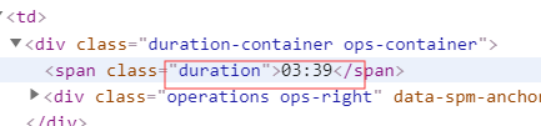
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
(必要时画出节点树结构)
查找方法:find
遍历方法:for循环嵌套
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import records
def getHtml(url):
'''
获取目标网页数据
'''
try:
# 伪装UA
ua = {'user-agent': 'Mozilla/5.0 Chrome/79.0.3945.88 Safari/537.36'}
# 读取网页
r = requests.get(url, headers=ua)
# 获取状态
r.raise_for_status()
# 打印数据 print(r.text)
# 返回数据
return r.text
except:
return "Fail"
def parseHtml(html):
# 数据数组
datas = []
# 结构解析
soup = BeautifulSoup(html, "html.parser")
# 获取排名
ids = soup.select('.em.index')
# 组号
i = 0
# 循环排名号
for id in ids:
# 字典
data = {}
# 获取编号
idd = id.get_text()
# 打印数据
print(idd)
# 获取歌曲名
titles = soup.select('.song-name.em')[i].get_text()
# 打印数据
print(titles)
# 获取歌手
songer = soup.select('.singers.COMPACT')[i].get_text()
# 打印数据
print(songer)
# 获取专辑
album = soup.select('.album')[i].get_text()
# 打印数据
print(album)
# 获取时长
duration = soup.select('.duration')[i].get_text()
# 打印数据
print(duration)
# 数组
i = i + 1
# 加入字典
data['#'] = idd
data['歌曲'] = titles
data['歌手'] = songer
data['专辑'] = album
data['时长'] = duration
# 加入数组
datas.append(data)
# 返回数组
return datas
def main():
# url
url = "https://www.xiami.com/billboard/306"
# 获取网页数据
html = getHtml(url)
# 解析网页结构
list = parseHtml(html)
# 初始化组件
results = records.RecordCollection(iter(list))
# 文件流
with open('list.xlsx', 'wb') as f:
# 写入
f.write(results.export('xlsx'))
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
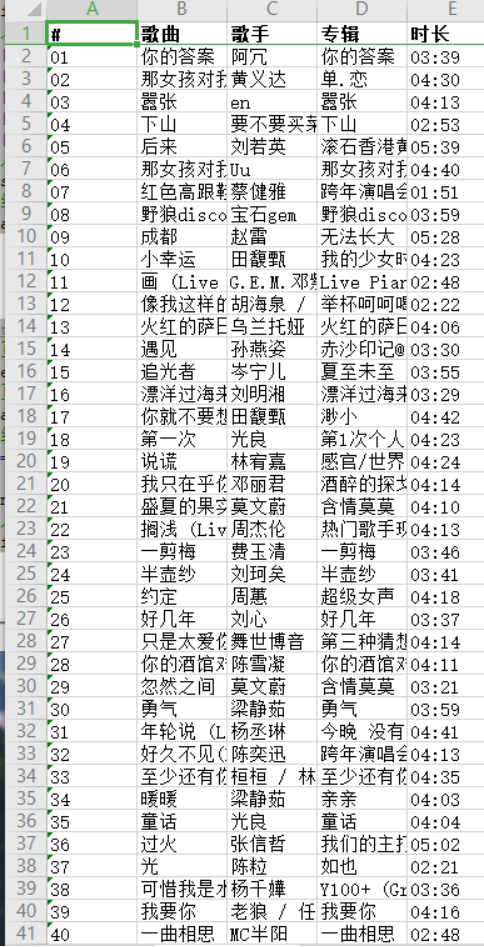

5.数据持久化
6.附完整程序代码
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup import records def getHtml(url): ''' 获取目标网页数据 ''' try: # 伪装UA ua = {'user-agent': 'Mozilla/5.0 Chrome/79.0.3945.88 Safari/537.36'} # 读取网页 r = requests.get(url, headers=ua) # 获取状态 r.raise_for_status() # 打印数据 print(r.text) # 返回数据 return r.text except: return "Fail" def parseHtml(html): # 数据数组 datas = [] # 结构解析 soup = BeautifulSoup(html, "html.parser") # 获取排名 ids = soup.select('.em.index') # 组号 i = 0 # 循环排名号 for id in ids: # 字典 data = {} # 获取编号 idd = id.get_text() # 打印数据 print(idd) # 获取歌曲名 titles = soup.select('.song-name.em')[i].get_text() # 打印数据 print(titles) # 获取歌手 songer = soup.select('.singers.COMPACT')[i].get_text() # 打印数据 print(songer) # 获取专辑 album = soup.select('.album')[i].get_text() # 打印数据 print(album) # 获取时长 duration = soup.select('.duration')[i].get_text() # 打印数据 print(duration) # 数组 i = i + 1 # 加入字典 data['#'] = idd data['歌曲'] = titles data['歌手'] = songer data['专辑'] = album data['时长'] = duration # 加入数组 datas.append(data) # 返回数组 return datas def main(): # url url = "https://www.xiami.com/billboard/306" # 获取网页数据 html = getHtml(url) # 解析网页结构 list = parseHtml(html) # 初始化组件 results = records.RecordCollection(iter(list)) # 文件流 with open('list.xlsx', 'wb') as f: # 写入 f.write(results.export('xlsx'))
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过对虾米音乐榜单爬虫,可以获取虾米音乐的榜单歌曲相关信息,例如歌名、歌手、专辑、时长、链接,得出了榜单前三的歌曲是:你的答案、那女孩对我说、嚣张。歌手分别是:阿冗、黄义达、en。时长分别是:03:39、04:30、04:13.
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过本次的爬虫课程设计作业,我学习到 了利用Python语言爬虫的技巧。通过利用中国慕课MOOC、CSDN论坛等资源自学,提高了自学能力,不懂的疑问请教同学,学习了很多新知识,提高了沟通能力。虽然不是所有的细节都已经掌握,但正在不断进步中。很幸运学习了一门新技巧。

