

Discuz!NT企业版之Sphinx全文搜索(下)
在前文中,介绍了Discuz!NT引入SPHINX的背景和相应的客户端的C#代码架构实现。今天这篇文章将会介绍如果在LINUX环境下安装配置SPHINX中文搜索工具,也就是服务器配置方案.
目前在网络上可以找到的SPHINX中文插件主要有两个:
1.coreseek: http://www.coreseek.cn/
2.sfc: http://code.google.com/p/sphinx-for-chinese/
其中的coreseek是目前对Discuz(PHP版)支持做的比较好的插件,它提供了相应的工具和源码包来尽可能简化sphinx的安装和配置。大家可从网上找到很多相关信息。
今天本文要说的是使用sfc来安装配置sphinx,呵呵:)
linux环境:centos 5.4 (需要安装gcc编译器来编译SPHINX源代码)
因为SPHINX要访问MYSQL数据库,所以如果机器上没有安装MYSQL,可以使用下面命令进行安装:
[root@localhost ~]# yum install -y automake autoconf
下面开始安装SPHINX(sfc 插件):


[root@localhost src]# wget http://sphinx-for-chinese.googlecode.com/files/sphinx-for-chinese-0.9.9-r2117.tar.gz
[root@localhost src]# tar zxvf sphinx-for-chinese-0.9.9-r2117.tar.gz
[root@localhost local]# cd sphinx-for-chinese-0.9.9-r2117
[root@localhost sphinx-for-chinese-0.9.9-r2117]# ./configure --prefix=/usr/local/sphinx --with-mysql #注意:这里sphinx已经默认支持了mysql,也可用--without-mysql来取消mysql
[root@localhost sphinx-for-chinese-0.9.9-r2117]# make && make install # 其中的“警告”可以忽略
到这里,基本就是完成了SPHINX的下载安装过程。
下面开始下载中文字典文档:
[root@localhost bin]# wget http://sphinx-for-chinese.googlecode.com/files/xdict_1.1.tar.gz
[root@localhost bin]# tar zxvf xdict_1.1.tar.gz
[root@localhost bin]#./mkdict xdict_1.1.txt xdict #注:mkdict是sfc自有的
这样就从xdict_1.1.txt文件生了xdict词典。
因为要在SPHINX中使用增量索引,因为参照官方文档中提供的思路,在指定的MYSQL数据库中创建增量统计表:
CREATE TABLE sphcounter(counterid INTEGER PRIMARY KEY NOT NULL,max_doc_id INTEGER NOT NULL);
接着就是创建Sphinx主索引文件、增量索引文件存放目录:
[root@localhost ~]#mkdir /usr/local/sphinx/var/data/dnt_posts1stemmed/
然后编辑usr/local/sphinx/etc/sphinx.conf文件:
[root@localhost etc] vi sphinx.conf
内容如下:
代码
{
# known types are mysql, pgsql, mssql, xmlpipe, xmlpipe2, odbc
type = mysql
sql_host = 10.0.4.66 #mysql数据库链接参数
sql_user = root
sql_pass = root
sql_db = test
sql_port = 3306 #optional, default is 3306
#下面是获取MYSQL数据表的查询语句
sql_query_pre = SET NAMES utf8 #加上这一行,以免因为编码不同造成中文乱码
sql_query_pre =replace into sphcounter select 1,MAX(pid) from dnt_posts1
sql_query = SELECT pid,fid,title,message,poster,postdatetime from dnt_posts1 where pid <= (select max_doc_id from sphcounter where counterid=1)
sql_ranged_throttle = 0
}
source src1throttled : src1
{
sql_query_pre=set names utf8
#增量表所使用的查询语句,以获取最新的帖子信息
sql_query=SELECT pid,fid,title,message,poster,postdatetime FROM dnt_posts1 where pid > (select max_doc_id from sphcounter where counterid=1)
}
index dnt_posts1
{
# 放索引的目录
path = /usr/local/sphinx/data/dnt_posts1
docinfo = extern
#编码
charset_type = utf-8
#指定utf-8的编码表。注意:如使用这种方式,则sphinx会对中文进行单字切分,即进行字索引,若要使用中文分词,必须使用其他分词插件如 coreseek,sfc
charset_table = U+FF10..U+FF19->0..9, 0..9, U+FF41..U+FF5A->a..z, U+FF21..U+FF3A->a..z,\
A..Z->a..z, a..z, U+0149, U+017F, U+0138, U+00DF, U+00FF, U+00C0..U+00D6->U+00E0..U+00F6,\
U+00E0..U+00F6, U+00D8..U+00DE->U+00F8..U+00FE, U+00F8..U+00FE, U+0100->U+0101, U+0101,\
U+0102->U+0103, U+0103, U+0104->U+0105, U+0105, U+0106->U+0107, U+0107, U+0108->U+0109,\
U+0109, U+010A->U+010B, U+010B, U+010C->U+010D, U+010D, U+010E->U+010F, U+010F,\
U+0110->U+0111, U+0111, U+0112->U+0113, U+0113, U+0114->U+0115, U+0115, U+0116->U+0117,\
U+0117, U+0118->U+0119, U+0119, U+011A->U+011B, U+011B, U+011C->U+011D, U+011D,\
U+011E->U+011F, U+011F, U+0130->U+0131, U+0131, U+0132->U+0133, U+0133, U+0134->U+0135,\
U+0135, U+0136->U+0137, U+0137, U+0139->U+013A, U+013A, U+013B->U+013C, U+013C,\
U+013D->U+013E, U+013E, U+013F->U+0140, U+0140, U+0141->U+0142, U+0142, U+0143->U+0144,\
U+0144, U+0145->U+0146, U+0146, U+0147->U+0148, U+0148, U+014A->U+014B, U+014B,\
U+014C->U+014D, U+014D, U+014E->U+014F, U+014F, U+0150->U+0151, U+0151, U+0152->U+0153,\
U+0153, U+0154->U+0155, U+0155, U+0156->U+0157, U+0157, U+0158->U+0159, U+0159,\
U+015A->U+015B, U+015B, U+015C->U+015D, U+015D, U+015E->U+015F, U+015F, U+0160->U+0161,\
U+0161, U+0162->U+0163, U+0163, U+0164->U+0165, U+0165, U+0166->U+0167, U+0167,\
U+0168->U+0169, U+0169, U+016A->U+016B, U+016B, U+016C->U+016D, U+016D, U+016E->U+016F,\
U+016F, U+0170->U+0171, U+0171, U+0172->U+0173, U+0173, U+0174->U+0175, U+0175,\
U+0176->U+0177, U+0177, U+0178->U+00FF, U+00FF, U+0179->U+017A, U+017A, U+017B->U+017C,\
U+017C, U+017D->U+017E, U+017E, U+0410..U+042F->U+0430..U+044F, U+0430..U+044F,\
U+05D0..U+05EA, U+0531..U+0556->U+0561..U+0586, U+0561..U+0587, U+0621..U+063A, U+01B9,\
U+01BF, U+0640..U+064A, U+0660..U+0669, U+066E, U+066F, U+0671..U+06D3, U+06F0..U+06FF,\
U+0904..U+0939, U+0958..U+095F, U+0960..U+0963, U+0966..U+096F, U+097B..U+097F,\
U+0985..U+09B9, U+09CE, U+09DC..U+09E3, U+09E6..U+09EF, U+0A05..U+0A39, U+0A59..U+0A5E,\
U+0A66..U+0A6F, U+0A85..U+0AB9, U+0AE0..U+0AE3, U+0AE6..U+0AEF, U+0B05..U+0B39,\
U+0B5C..U+0B61, U+0B66..U+0B6F, U+0B71, U+0B85..U+0BB9, U+0BE6..U+0BF2, U+0C05..U+0C39,\
U+0C66..U+0C6F, U+0C85..U+0CB9, U+0CDE..U+0CE3, U+0CE6..U+0CEF, U+0D05..U+0D39, U+0D60,\
U+0D61, U+0D66..U+0D6F, U+0D85..U+0DC6, U+1900..U+1938, U+1946..U+194F, U+A800..U+A805,\
U+A807..U+A822, U+0386->U+03B1, U+03AC->U+03B1, U+0388->U+03B5, U+03AD->U+03B5,\
U+0389->U+03B7, U+03AE->U+03B7, U+038A->U+03B9, U+0390->U+03B9, U+03AA->U+03B9,\
U+03AF->U+03B9, U+03CA->U+03B9, U+038C->U+03BF, U+03CC->U+03BF, U+038E->U+03C5,\
U+03AB->U+03C5, U+03B0->U+03C5, U+03CB->U+03C5, U+03CD->U+03C5, U+038F->U+03C9,\
U+03CE->U+03C9, U+03C2->U+03C3, U+0391..U+03A1->U+03B1..U+03C1,\
U+03A3..U+03A9->U+03C3..U+03C9, U+03B1..U+03C1, U+03C3..U+03C9, U+0E01..U+0E2E,\
U+0E30..U+0E3A, U+0E40..U+0E45, U+0E47, U+0E50..U+0E59, U+A000..U+A48F, U+4E00..U+9FBF,\
U+3400..U+4DBF, U+20000..U+2A6DF, U+F900..U+FAFF, U+2F800..U+2FA1F, U+2E80..U+2EFF,\
U+2F00..U+2FDF, U+3100..U+312F, U+31A0..U+31BF, U+3040..U+309F, U+30A0..U+30FF,\
U+31F0..U+31FF, U+AC00..U+D7AF, U+1100..U+11FF, U+3130..U+318F, U+A000..U+A48F,\
U+A490..U+A4CF
#简单分词,只支持0和1,如果要搜索中文,请指定为1
ngram_len = 1
#需要分词的字符,如果要搜索中文,去掉前面的注释
ngram_chars = U+4E00..U+9FBF, U+3400..U+4DBF, U+20000..U+2A6DF, U+F900..U+FAFF,\
U+2F800..U+2FA1F, U+2E80..U+2EFF, U+2F00..U+2FDF, U+3100..U+312F, U+31A0..U+31BF,\
U+3040..U+309F, U+30A0..U+30FF, U+31F0..U+31FF, U+AC00..U+D7AF, U+1100..U+11FF,\
U+3130..U+318F, U+A000..U+A48F, U+A490..U+A4CF
source = src1
min_infix_len = 1
min_word_len = 1
#加上这个选项,则会对每个中文,英文字词进行分割,速度会慢
#ngram_chars = U+4E00..U+9FBF, U+3400..U+4DBF, U+20000..U+2A6DF, U+F900..U+FAFF,\
#U+2F800..U+2FA1F, U+2E80..U+2EFF, U+2F00..U+2FDF, U+3100..U+312F, U+31A0..U+31BF,\
#U+3040..U+309F, U+30A0..U+30FF, U+31F0..U+31FF, U+AC00..U+D7AF, U+1100..U+11FF,\
#U+3130..U+318F, U+A000..U+A48F, U+A490..U+A4CF
chinese_dictionary = /usr/local/sphinx/bin/xdict
}
index dnt_posts1stemmed : dnt_posts1
{
source =src1throttled
path = /usr/local/sphinx/data/dnt_posts1stemmed
}
indexer
{}
searchd
{
listen = 10.0.4.66:3312
pid_file = /usr/local/sphinx/log/searchd.pid
read_timeout = 30 #请求超时
client_timeout = 300
max_children = 30 #同时可执行的最大searchd 进程数
preopen_indexes = 1
max_packet_size = 128M
max_matches = 1000 #查询结果的最大返回数
max_filters = 256
max_filter_values = 4096
read_buffer = 4096K
}
其中的searchd节点下listen对应的是就服务器SPHINX守护进程的地址和端口信息及其它进程配置参数(详见sphinx官方示例文档)
对应上面的配置文件,下面是sfc官方的说明:
charset_type = utf-8 #其中charst_type选择utf-8即可
chinese_dictionary = /path/to/xdict #chinese_dictionary是指定分词词典的选项,包括路径和文件名,这样中文支持就可以了
同时当chinese_dictionary和utf-8的ngram选项同时出现时,会优先使用sphinx-for-chinese的中文支持方法。如果要使用ngram方法,将chinese_dictionary选项去掉即可。
如果配置正确,就可以使用下面命令行来创建索引了:
信息显示:
Copyright (c) 2001-2009, Andrew Aksyonoff
using config file 'etc/sphinx.conf'...
indexing index 'dnt_posts1'...
collected 99820 docs, 17.6 MB
sorted 29.8 Mhits, 97.4% done
total 99820 docs, 17553938 bytes
total 35.498 sec, 494498 bytes/sec, 2811.95 docs/sec
WARNING: no such index '-rotate', skipping.
total 294 reads, 0.220 sec, 432.5 kb/call avg, 0.7 msec/call avg
total 312 writes, 1.372 sec, 956.0 kb/call avg, 4.3 msec/call avg
查询:
信息显示:
Sphinx 0.9.9-release (r2117)
Copyright (c) 2001-2009, Andrew Aksyonoff
using config file 'etc/sphinx.conf'...
index 'dnt_posts20': query 'hello ': returned 12 matches of 12 total in 0.001 sec
displaying matches:
1. document=5206761, weight=1, tid=312375, fid=4, posterid=97258, postdatetime=Mon Jan 2 17:30:00 2006
2. document=5213543, weight=1, tid=312709, fid=4, posterid=30374, postdatetime=Tue Jan 3 01:43:00 2006
3. document=5237575, weight=1, tid=314170, fid=79, posterid=54334, postdatetime=Sat Jan 7 19:55:00 2006
4. document=5253361, weight=1, tid=314961, fid=12, posterid=2587, postdatetime=Mon Jan 9 13:22:00 2006
5. document=5258138, weight=1, tid=315239, fid=78, posterid=52580, postdatetime=Wed Jan 11 17:03:00 2006
6. document=5258160, weight=1, tid=315239, fid=78, posterid=39959, postdatetime=Thu Jan 12 19:49:00 2006
7. document=5259929, weight=1, tid=315343, fid=12, posterid=55028, postdatetime=Wed Jan 25 17:48:00 2006
8. document=5262286, weight=1, tid=315516, fid=81, posterid=57720, postdatetime=Wed Jan 11 01:00:00 2006
9. document=5264041, weight=1, tid=315612, fid=18, posterid=96303, postdatetime=Thu Jan 12 13:00:00 2006
10. document=5268527, weight=1, tid=315837, fid=78, posterid=26965, postdatetime=Thu Jan 12 12:47:00 2006
11. document=5268541, weight=1, tid=315837, fid=78, posterid=48761, postdatetime=Thu Jan 12 18:54:00 2006
12. document=5274196, weight=1, tid=316220, fid=12, posterid=50496, postdatetime=Fri Jan 13 22:22:00 2006
words:
1. 'hello': 12 documents, 16 hits
index 'dnt_posts20_stem': query 'hello ': returned 5 matches of 5 total in 0.000 sec
displaying matches:
1. document=5300417, weight=1, tid=317247, fid=4, posterid=97227, postdatetime=Thu Jan 1 08:33:26 1970
2. document=5300424, weight=1, tid=317247, fid=4, posterid=31887, postdatetime=Thu Jan 1 08:33:26 1970
3. document=5307959, weight=1, tid=317654, fid=120, posterid=18760, postdatetime=Thu Jan 1 08:33:26 1970
4. document=5308076, weight=1, tid=317662, fid=120, posterid=18760, postdatetime=Thu Jan 1 08:33:26 1970
5. document=5308079, weight=1, tid=317662, fid=120, posterid=18760, postdatetime=Thu Jan 1 08:33:26 1970
words:
1. 'hello': 5 documents, 10 hits
开启守护进程:
信息显示:
Copyright (c) 2001-2009, Andrew Aksyonoff
using config file 'etc/sphinx.conf'...
listening on 10.0.4.66:3312
You have new mail in /var/spool/mail/root
之前提到,客户端会对主索引和增量索引同时进行查询,而主索引和增量索引会被做了定时任务方式进行执行。那么接下来就是做这一部分的工作:
创建两个shell脚本,分别用来创建主索引和创建增量索引。
1.创建主索引更新脚本,build_main_index.sh:
输入以下内容(双击打开):
/usr/local/shpinx/bin/indexr --rotate dnt_posts1
sleep 1
#清空搜索日志
:/>/usr/local/sphinx/var/log/query.log
:/>/usr/local/sphinx/var/log/searchd.log
2.赋予主索引更新脚本可执行权限:
3.每天凌晨定时重建主索引:
增加以下内容:
19 4 * * * /bin/sh /usr/local/sphinx/bin/build_main_index.sh
4.创建脚本build_delta_index.sh:
输入以下内容(双击打开):
/usr/local/sphinx/bin/indexer --rotate dnt_posts1stemmed
5.赋予增量索引更新脚本可执行权限:
6.每3分钟自动重建一次搜索引擎的增量索引:
增加以下内容:
0-57/3 * * * * /bin/sh /usr/local/sphinx/bin/build_delta_index.sh
7.配置服务器开机启动时需要自动执行的命令
内容:
/usr/bin/nohup /bin/sh /usr/local/sphinx/bin/build_main_index.sh 2>&1 > /dev/null &
/bin/sh /usr/local/sphinx/bin/build_delta_index.sh 2>&1 > /dev/null
/usr/local/sphinx/bin/searchd
这样在服务端的配置工作就告一段落了。
当然,对于以前使用过Discuz!NT的用户,我们提供了一个同步工具来将已有的帖子分表同步的指定的MYSQL数据库里以便让SPHINX来访问。如下:
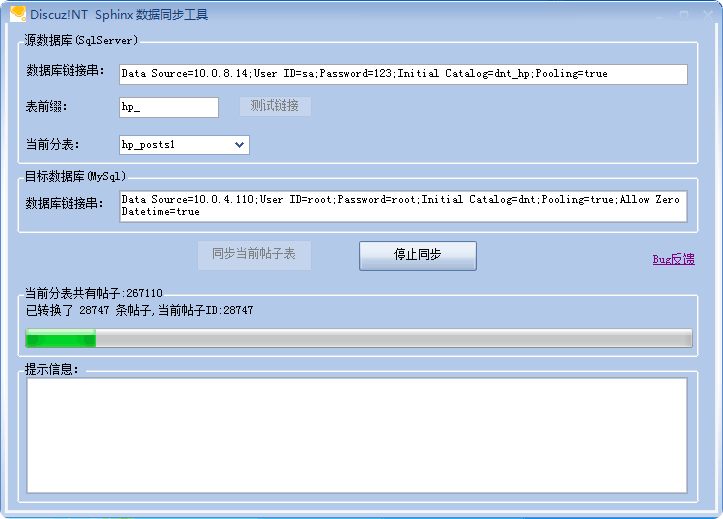
这样就解决了已有数据该如何被索引的问题,剩下的就是要不断的修改sphinx.conf文件以添加新的索引和增量索引了(因为我们使用了帖子分表功能,会在帖子表记录达到一定数量时创建新的分表,这样就可以保持当前所使用的帖子分表记录不会过于庞大,从而影响数据库查询效率)和在相应的sh文件中添加对新索引的定时创建命令了。
当然,SPHINX还支持分布式检索服务,不过因为眼下的架构未用到,所以就不多做说明了,大家可以去网上搜索相关信息即可。
原文链接:http://www.cnblogs.com/daizhj/archive/2010/06/30/discuznt_entlib_sphinx_two.html
BLOG: http://daizhj.cnblogs.com/
作者:daizhj,代震军
参考链接:
Sphinx中文指南 http://www.sphinxsearch.org/
sphinx_doc_zhcn_0.9-中文手册 http://www.coreseek.cn/uploads/pdf/sphinx_doc_zhcn_0.9.pdf
亿级数据的高并发通用搜索引擎架构设计 http://blog.s135.com/post/385/
sphinx-for-chinese : http://code.google.com/p/sphinx-for-chinese/
coreseek: http://www.coreseek.cn/

