用LSTM进行时间序列预测
LSTM(long short-term memory)长短期记忆网络是一种比较老的处理NLP的模型,但是其在时间序列预测方面的精度还是不错的,我这里以用“流量”数据为例进行时间序列预测。作者使用的是pytorch框架,在jupyter-lab环境下运行。
导入必要的包
import torch
import torch.nn as nn
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import sklearn.preprocessing as preprocessing
%matplotlib inline
加载数据集
dataset = pd.read_excel('./data3.xlsx')
dataset.columns = ['ds', 'y']
# 打印前5行数据
dataset.head()
输出的结果如下:
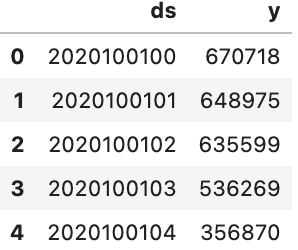
ds表示时间戳,y是每个时间段对应的流量值。为了看的更方便,将ds转换为标准格式
dataset['ds'] = pd.to_datetime(dataset['ds'], format='%Y%m%d%H')
dataset.head()
结果如下:

划分测试集和训练集
为了进行模型的评估,我们需要将数据划分成训练集和测试集,这里我以最后24个小时(即一天)作为测试集:
# 最后24个值作为测试集
test_size = 24
train_set = dataset[:-test_size].y.values
test_set = dataset[-test_size:].y.values
print(train_set.shape)
print(test_set.shape)

将训练集标准化
为了消除值的量纲的差异,同时,由于神经网络对于数据较大的值比较敏感,运算会增加复杂度,因此我们将训练集进行标准化,这里我采用z-score标准化,即:
\[X = \frac{X-\mu}{\sigma},
\]
注意,这里只能将标准化运用到训练集上,如果运用在测试集上则会造成数据泄露,相当于已经看过了测试集,那么训练就没有意义了。
norm_scaler = preprocessing.StandardScaler()
train_set_normed = norm_scaler.fit_transform(train_set.reshape(-1,1)).reshape(-1, ).tolist()
train_set_normed[:5]
将数据转换为tensor
由于pytorch只能对tensor类型的数据进行训练,故需要转化:
train_set_normed = torch.FloatTensor(train_set_normed)
train_set_normed[:5]
制作用于训练的sequence
我们采用滑动窗口的形式进行sequence的制作,这里我以168小时(一周)的数据来预测后24小时(一天)的数据,所以我们标签窗口的大小为168,标签窗口的大小为24。相当于每168个数据预测完后24个数据后,窗口向右移动一位,用下一个168数据预测后24个数据,直到看完所有的训练集:
# 这里用168小时(即一周)的数据来预测24小时(一天)的数据
train_window_len = 168 # 训练窗口
pred_window_len = 24 #标签窗口
l = len(train_set_normed)
input_sequence = []
for i in range(l - train_window_len - pred_window_len + 1):
train_seq = train_set_normed[i:i+train_window_len]
label_seq = train_set_normed[i+train_window_len:i+train_window_len+pred_window_len]
input_sequence.append((train_seq, label_seq))
print(len(input_sequence))
input_sequence[0] # 展示第一个训练样本
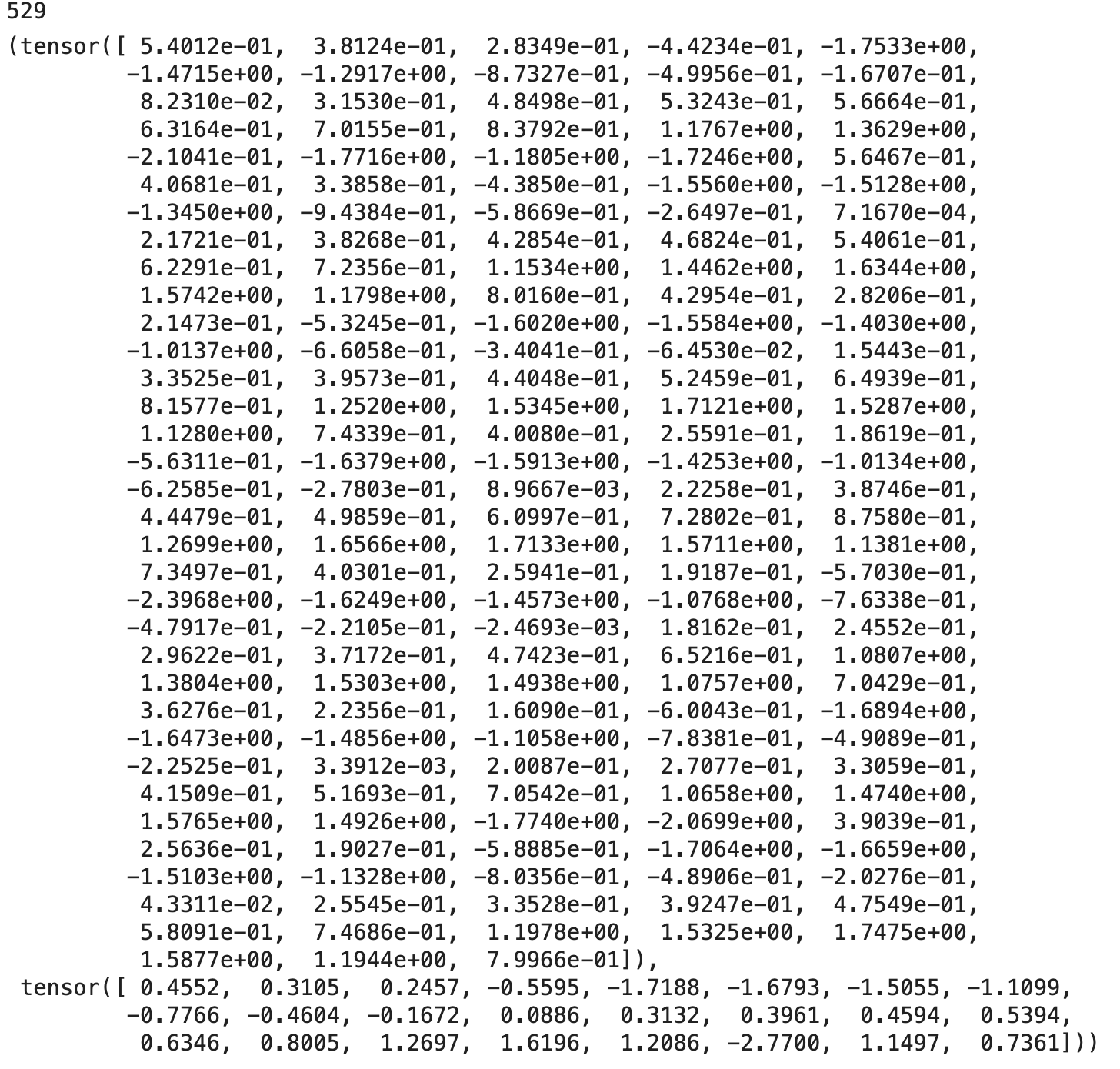
可以看到,每个训练样本由168个输入值和24个标签值组成
搭建LSTM模型
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
# input_size表示输入的特征维数
self.lstm = nn.LSTM(input_size, hidden_size)
# output_size表示输出的特征维数
self.linear = nn.Linear(hidden_size, output_size)
# memory_cell
self.hidden_cell = self.init_hidden_cell(output_size)
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)
# 由于最终的预测值只保存在最后一个单元格中, 所以只要输出最后一个
return self.linear(lstm_out.view(len(input_seq), -1))[-1]
def init_hidden_cell(self, output_size):
return (torch.zeros(1,1,self.hidden_size),
torch.zeros(1,1,self.hidden_size))
model = LSTMModel(1, 100, pred_window_len)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 迭代次数,这里为了省时间仅训练5次
n_epochs = 5
开始训练
for epoch in range(n_epochs):
train_loss = 0.
for seq, label in input_sequence:
optimizer.zero_grad()
# 重新初始化隐藏层数据,避免受之前运行代码的干扰,如果不重新初始化,会有报错。
model.hidden_cell = model.init_hidden_cell(pred_window_len)
pred_label = model(seq)
loss = criterion(pred_label, label)
train_loss += loss.item()
loss.backward()
optimizer.step()
print(f'epoch{epoch+1:2} loss: {train_loss/len(input_sequence):.4f}')
预测测试集的值进行模型的评估
# 最后168个值,可以用来预测后24个值,即测试集的值
test_inputs = train_set_normed[-train_window_len:].tolist()
model.eval()
pred_value = [] # 用于存放预测值
with torch.no_grad():
test_sequence = torch.FloatTensor(test_inputs)
model.hidden_cell = model.init_hidden_cell(test_size)
pred = model(test_sequence)
pred_value = pred
# 由于前面对训练集进行了标准化,故预测结果都是小数,这里需要将预测结果反标准化
pred_value = norm_scaler.inverse_transform(pred_value).tolist()
pred_value[:5]
前5个预测值
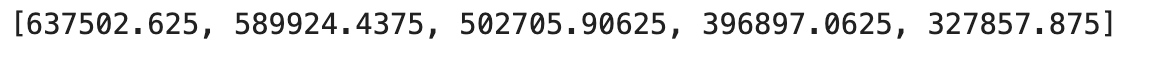
画出预测值和真实值的对比图
plt.figure(figsize=(15,5),dpi = 500)
plt.grid(linestyle='--')
plt.plot(list(range(24)), test_set, label='actual value')
plt.plot(list(range(24)), pred_value, label='predict value')
plt.legend()

由图可以看到预测的结果还是不错的
计算准确率来评估模型
模型的准确率计算公式为:
\[Accuarcy=\left(1-\sqrt{\frac{1}{n}\sum_{i=1}^n E_i^2}\right)\times 100\%
\]
其中n为预测总数,\(E_i\)为某一点的相对误差,计算公式为:
\[E_i=\frac{|actual-predict|}{actual}\times 100\%
\]
relative_error = 0.
for i in range(24):
relative_error += (abs(pred_value[i] - test_set[i]) / test_set[i]) ** 2
acc = 1- np.sqrt(relative_error / 24)
print(f'模型的测试准确率为:{acc*100:.2f}%')

模型的最终准确率为93.38%,可以看到效果还是不错的,如果继续调整学习率和迭代次数,搭配交叉验证和网格搜索,效果应该会更好一点。

