
数据采集第三次大作业
作业一
内容
- 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网( http://www.weather.com.cn )。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
- 输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
代码&结果
分析中国气象网的html信息,发现图片的链接在img标签的‘src’属性值内,其他链接在a标签的‘href’属性里。

- 单线程:
使用requests+re匹配得到图片的链接,以及网页内的其他链接。对其他链接的遍历访问,爬取其中的图片。
其中要注意检查,得到的某些图片的链接不是像“https://……”一样的标准链接,跳过这类链接。
def spider(url, headers):
global count
global urls
if count > 132: # 如果已下载132张,则返回
return
if url not in urls: # 判断该链接是否爬取过,如果没有爬取过则加入到urls列表,并对它进行爬取
urls.append(url)
try:
data = getHTMLText(url, headers) # 获得页面信息
links = re.findall(r'a href="(.*?)"', data, re.S) # 正则匹配,得到页面中的网页链接
photos = re.findall(r'img src="(.*?)"', data, re.S) # 正则匹配, 得到图片的链接
for i in range(len(photos)):
if photos[i].startswith("http"): # 判断图片链接是否符合标准
download(photos[i], headers) # 将图片链接传入download函数进行图片下载
if count > 132: # 如果已下载132张图片,则停止爬取
break
if count <= 132: # 如果下载不满132张图片,则对新链接进行访问爬取图片
for link in links:
spider(link, headers)
except Exception as err:
print(err)
写一个download函数,下载相应链接的图片,按爬取顺序命名。
def download(url, count): # 下载图片
if count > 132: # 已下载132张则返回
return
try:
data = getPhoto(url, headers) # 获得图片信息
with open('./images/%d%s' % (count, url[-4:]), 'wb') as f: # 利用count和图片原本的扩展名对图片进行重命名
f.write(data) # 写入本地文件
print("{} {}".format(count, url)) # 在控制台打印出图片名与链接
except Exception as err:
print(err)
可以看到,图片按爬取的顺序下载完成。
- 多线程:
仍然使用requests+re,只是增加了线程的创建,对图片进行并发爬取下载,其他部分的代码与单线程相同。
try:
data = getHTMLText(url, headers) # 获得页面信息
links = re.findall(r'a href="(.*?)"', data, re.S) # 正则匹配,得到页面中的其他链接
photos = re.findall(r'img src="(.*?)"', data, re.S) # 正则匹配, 得到图片的链接
for i in range(len(photos)):
if photos[i].startswith("http"): # 判断图片链接是否符合标准
# 创建线程T,执行download函数,参数为图片链接和用以对图片命名的count值
T = threading.Thread(target=download, args=(photos[i], count))
T.setDaemon(False) # 非守护线程
T.start() # 启动线程
threads.append(T) # 将线程T装入threads列表
count += 1 # 爬取图片数量加1
if count > 132: # 如果已下载132张,则退出循环
break
if count <= 132: # 如果未下载132张图片,则爬取网页中的其他链接
for link in links:
spider(link, headers) # 对链接进行爬取
except Exception as err:
print(err)
观察在控制台输出的下载完的图片信息,起先仍然顺序完成下载,排错发现创建线程时没有用args进行传参(语句如下),导致多线程不能并发执行。
T = threading.Thread(target=download(photos[i], count))
经过代码调整,多线程并发下载图片,下载完成顺序与爬取到的顺序不同。
心得
- 通过练习,我巩固了网站的遍历、链接的寻找,也体会到多线程并发下载图片,大大加快了下载速度。
完整代码链接
https://gitee.com/cxqi/crawl_project/tree/master/实验3/作业1
作业二
内容
- 要求:使用scrapy框架复现作业一。
- 输出信息:同作业一。
代码&结果
对网页html信息分析同作业一,直接进行代码编写。
- items.py
编写数据项目类PhotoItem,保存图片信息
class PhotoItem(scrapy.Item):
data = scrapy.Field() # 图片二进制信息
name = scrapy.Field() # 图片名
link = scrapy.Field() # 图片链接
- pipelines.py
编写数据处理类PhotoPipeline,对数据进行下载。
class PhotoPipeline(object):
count = 0
imdir = "E:/example/exe3/images/" # 图片保存文件
print("下载:")
def process_item(self, item, spider):
try:
impath = self.imdir + item["name"] # 图片保存路径,通过item的name对图片进行命名
with open(impath, 'wb') as f:
f.write(item["data"]) # 下载图片至本地文件
print("{} {}".format(item["name"], item["link"])) # 在控制台打印图片名和相应链接
except Exception as err:
print(err)
return item
- settings.py
编写配置文件,设置不遵守爬虫协议
ROBOTSTXT_OBEY = False # 不遵守爬虫协议,防止被反爬
把数据推送到PhotoPipeline类中
ITEM_PIPELINES = { # 打开管道
'exe3.pipelines.PhotoPipeline': 300,
}
- myspider.py
网页爬取入口函数:
def start_requests(self): # 爬虫入口函数,爬取完网页执行回调函数parse
yield scrapy.Request(url=self.url, callback=self.parse, headers=self.headers)
具体图片链接、其他网页链接的提取,并生成两种网页请求,一种是对图片链接,执行回调函数imParse;一种是其他网页链接,执行回调函数parse,继续进行图片与其他网页链接的爬取。
def parse(self, response):
try:
data = response.body.decode()
selector = scrapy.Selector(text=data)
photos = selector.xpath("//img/@src").extract() # 提取图片链接
links = selector.xpath("//a/@href").extract() # 提取网页中的其他链接,用以翻页
for photo in photos: # 对图片进行处理
if photo.startswith("http") and self.count <= 132:
# 判断图片链接是否标准,如果图片链接可以访问,则执行回调函数imParse进行图片数据;同时判断下载图片数量,不满132张继续进行图片下载
yield scrapy.Request(url=photo, callback=self.imParse, headers=self.headers)
if self.count <= 132: # 如果下载图片数量不满132张,再进行网页内的链接的访问爬取
for link in links:
if link not in self.urls: # 判断该链接是否已经爬取
# 如果未爬取,则将其加入已访问列表urls,再进行该网页访问爬取
self.urls.append(link)
yield scrapy.Request(url=link, callback=self.parse, headers=self.headers)
except Exception as err:
print(err)
再写一个函数,完成对图片链接的访问下载,生成数据项目类PhotoItem,推送给PhotoPipeline。
def imParse(self, response):
if self.count > 132: # 已下载132张则返回
return
try:
item = PhotoItem() # 创建一个PhotoItem对象
item["data"] = response.body # 图片数据为图片链接对应的页面信息
item["name"] = str(self.count) + response.url[-4:] # 对图片重命名,包括用计数count和该图片本身的后缀名进行命名
item["link"] = response.url # 图片链接
yield item
self.count += 1
except Exception as err:
print(err)
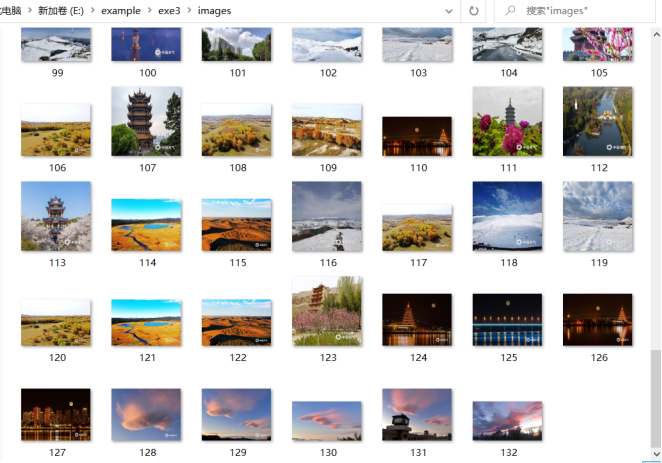
运行程序,控制台输出如下:
下载得到图片:
心得
通过练习,我巩固了scrapy框架爬取网页信息的做法,同时学习到了对于不同需求的信息处理,可以编写多个回调函数来实现。
完整代码链接
https://gitee.com/cxqi/crawl_project/tree/master/实验3/作业2
作业三
内容
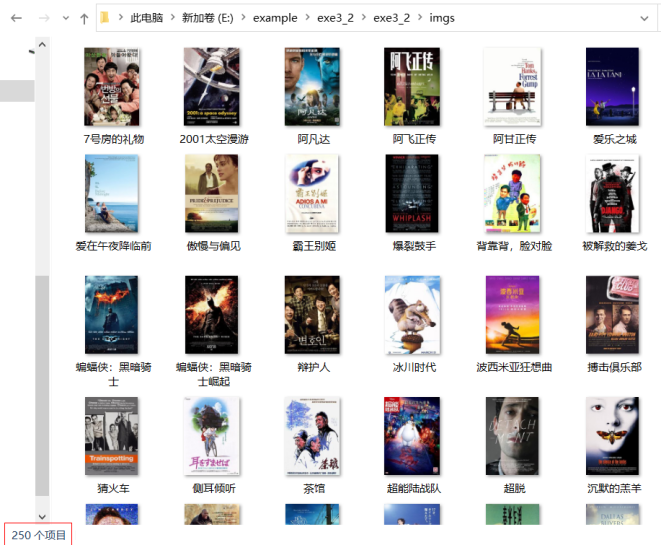
- 要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
- 候选网站: https://movie.douban.com/top250
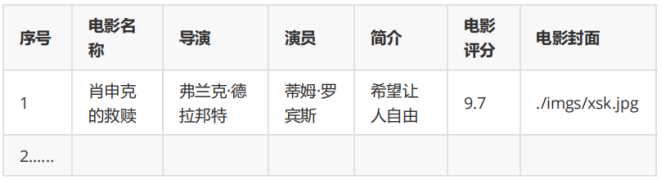
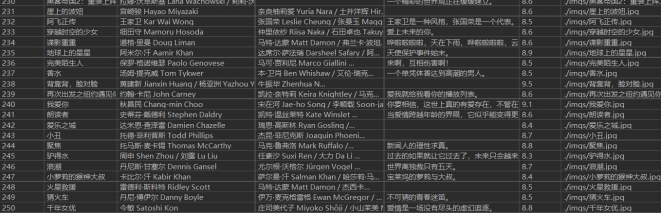
- 输出信息:
代码&结果
- items.py
由输出信息得到我们要提取的一部电影的信息有:
class MovieItem(scrapy.Item):
rank = scrapy.Field() # 电影排名
name = scrapy.Field() # 电影名称
director = scrapy.Field() # 导演
actor = scrapy.Field() # 演员
summary = scrapy.Field() # 简述
score = scrapy.Field() # 电影评分
photo = scrapy.Field() # 电影封面
link = scrapy.Field() # 电影封面图片链接
- myspider.py
在网页的html信息中找到所需信息的所在位置,进行信息提取。
这里要注意,在得到的电影列表内,对每个电影进行xpath定位,需要写成“.//”形式,不能忽略“.”,否则extract_first后只能爬取到每页的第一个电影。
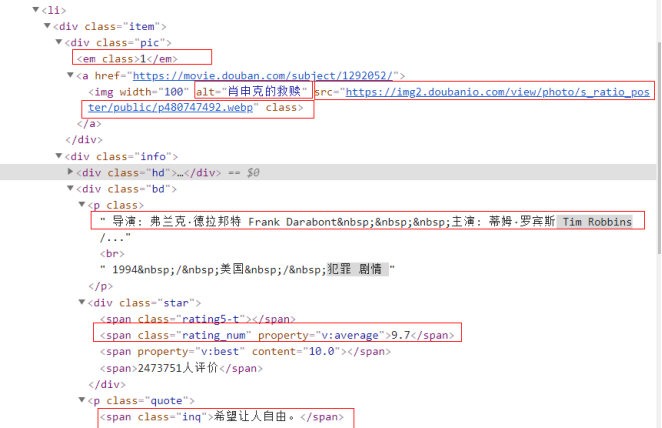
movies = selector.xpath("//li/div[@class='item']") # 一个网页内的所有电影
for movie in movies:
rank = movie.xpath(".//div[@class='pic']/em/text()").extract_first() # 电影排名
name = movie.xpath(".//div[@class='pic']//img/@alt").extract_first() # 电影名称
p = movie.xpath(".//div[@class='bd']/p/text()").extract_first() # 电影导演及主演信息
summary = movie.xpath(".//p[@class='quote']/span/text()").extract_first() # 电影简介
score = movie.xpath(".//span[@class='rating_num']/text()").extract_first() # 电影评分
link = movie.xpath(".//div[@class='pic']//img/@src").extract_first() # 电影封面图片链接
发现有些信息不能直接得到,电影导演和演员信息在一个标签内,对提取到的字符串再进行re匹配。

director = re.findall(r'导演: (.*?)\xa0', p) # re匹配得到电影的导演
actor = re.findall(r'主演: (.*)', p) # re匹配得到电影的主演
生成数据项目类MovieItem,要注意对爬取不到的某些信息进行处理,如设置成""。
item = MovieItem() # 创建一个MovieItem对象
# 对数据进行处理,如果提取的信息不存在,就把None转换为""
item["rank"] = rank if rank else ""
item["name"] = name if name else ""
item["director"] = director[0] if director else ""
item["actor"] = actor[0] if actor else ""
item["summary"] = summary if summary else ""
item["score"] = score if score else ""
# 将item的photo设置为电影封面图片保存的本地文件目录
item["photo"] = "./imgs/" + name + ".jpg" if name else ""
item["link"] = link if link else ""
yield item # 将item推送给pipelines.py下的数据管道
对于多页爬取,还要进行翻页规律探索,可以看出规律比较简单。



self.page += 25
if self.page <= 225: # 翻页处理,共爬取10页
url = self.start_url + "?start=" + str(self.page) + "&filter="
yield scrapy.Request(url=url, callback=self.parse, headers=self.headers)
- pipelines.py
MoviePipeline进行数据库表的创建与信息插入。
def process_item(self, item, spider):
try:
if self.opened:
# 把爬取到的电影信息存入数据库
self.cursor.execute("insert into movies (序号, 电影名称, 导演, 演员, 简介, 电影评分, 电影封面)"
"values (?,?,?,?,?,?,?)", (item["rank"], item["name"], item["director"],
item["actor"], item["summary"], item["score"], item["photo"]))
self.count += 1
except Exception as err:
print(err)
return item
PhotoPipeline继承ImagesPipeline,对图片进行下载。
class PhotoPipeline(ImagesPipeline): # 引入ImagePipeline通道
def get_media_requests(self, item, info): # 重写get_media_requests函数,将图片的url生成request请求
yield scrapy.Request(url=item['link'], meta={'item': item}) # 利用meta参数将item项进行传输,以便重命名时读取item中的电影名称
def file_path(self, request, response=None, info=None):
item = request.meta['item'] # 上面的meta传递过来item
# 图片重命名,request.url.split('/')[-1].split('.')[-1]得到图片后缀jpg,png
image_name = item['name'] + '.' + request.url.split('/')[-1].split('.')[-1]
# 图片下载目录
filename = u'imgs/{0}'.format(image_name)
return filename
def item_completed(self, results, item, info):
# 判断如果存在path,就将图片保存到这个path
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths: # 如果其中没有图片,则采用drop
raise DropItem("Item contains no images")
return item
- settings.py
IMAGES_STORE = r'.' # 设置图片保存地址
ROBOTSTXT_OBEY = False # 不遵守爬虫协议,防止被反爬
ITEM_PIPELINES = { # 打开管道,分配给每个管道的整型值,确定了他们运行的顺序,数值越低优先值越高
'exe3_2.pipelines.MoviePipeline': 100,
'exe3_2.pipelines.PhotoPipeline': 200,
}
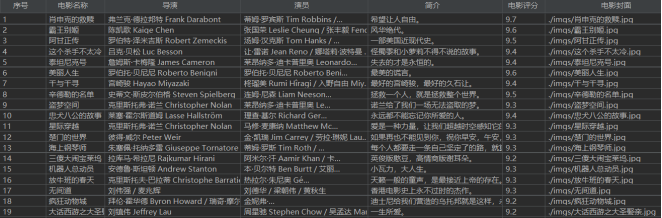
- 结果
心得
通过练习,我掌握了除了作业二方法外,scarpy框架下另一种图片的下载方式。同时我也掌握了meta传参的方法,因为其中比较特别的要求是对图片重命名,需要利用meta在scrapy.Request里进行传参,以便重命名时获得图片对应的电影名称。

