
Hadoop框架:MapReduce基本原理和入门案例
一、MapReduce概述
1、基本概念
Hadoop核心组件之一:分布式计算的方案MapReduce,是一种编程模型,用于大规模数据集的并行运算,其中Map(映射)和Reduce(归约)。
MapReduce既是一个编程模型,也是一个计算组件,处理的过程分为两个阶段,Map阶段:负责把任务分解为多个小任务,Reduce负责把多个小任务的处理结果进行汇总。其中Map阶段主要输入是一对Key-Value,经过map计算后输出一对Key-Value值;然后将相同Key合并,形成Key-Value集合;再将这个Key-Value集合转入Reduce阶段,经过计算输出最终Key-Value结果集。
2、特点描述
MapReduce可以实现基于上千台服务器并发工作,提供很强大的数据处理能力,如果其中单台服务挂掉,计算任务会自动转义到另外节点执行,保证高容错性;但是MapReduce不适应于实时计算与流式计算,计算的数据是静态的。
二、操作案例
1、流程描述

数据文件一般以CSV格式居多,数据行通常以空格分隔,这里需要考虑数据内容特点;
文件经过切片分配在不同的MapTask任务中并发执行;
MapTask任务执行完毕之后,执行ReduceTask任务,依赖Map阶段的数据;
ReduceTask任务执行完毕后,输出文件结果。
2、基础配置
hadoop:
# 读取的文件源
inputPath: hdfs://hop01:9000/hopdir/javaNew.txt
# 该路径必须是程序运行前不存在的
outputPath: /wordOut
3、Mapper程序
public class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text mapKey = new Text();
IntWritable mapValue = new IntWritable(1);
@Override
protected void map (LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 1、读取行
String line = value.toString();
// 2、行内容切割,根据文件中分隔符
String[] words = line.split(" ");
// 3、存储
for (String word : words) {
mapKey.set(word);
context.write(mapKey, mapValue);
}
}
}
4、Reducer程序
public class WordReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
int sum ;
IntWritable value = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
// 1、累加求和统计
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2、输出结果
value.set(sum);
context.write(key,value);
}
}
5、执行程序
@RestController
public class WordWeb {
@Resource
private MapReduceConfig mapReduceConfig ;
@GetMapping("/getWord")
public String getWord () throws IOException, ClassNotFoundException, InterruptedException {
// 声明配置
Configuration hadoopConfig = new Configuration();
hadoopConfig.set("fs.hdfs.impl",
org.apache.hadoop.hdfs.DistributedFileSystem.class.getName()
);
hadoopConfig.set("fs.file.impl",
org.apache.hadoop.fs.LocalFileSystem.class.getName()
);
Job job = Job.getInstance(hadoopConfig);
// Job执行作业 输入路径
FileInputFormat.addInputPath(job, new Path(mapReduceConfig.getInputPath()));
// Job执行作业 输出路径
FileOutputFormat.setOutputPath(job, new Path(mapReduceConfig.getOutputPath()));
// 自定义 Mapper和Reducer 两个阶段的任务处理类
job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReducer.class);
// 设置输出结果的Key和Value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//执行Job直到完成
job.waitForCompletion(true);
return "success" ;
}
}
6、执行结果查看
将应用程序打包放到hop01服务上执行;
java -jar map-reduce-case01.jar

三、案例分析
1、数据类型
Java数据类型与对应的Hadoop数据序列化类型;
| Java类型 | Writable类型 | Java类型 | Writable类型 |
|---|---|---|---|
| String | Text | float | FloatWritable |
| int | IntWritable | long | LongWritable |
| boolean | BooleanWritable | double | DoubleWritable |
| byte | ByteWritable | array | DoubleWritable |
| map | MapWritable |
2、核心模块
Mapper模块:处理输入的数据,业务逻辑在map()方法中完成,输出的数据也是KV格式;
Reducer模块:处理Map程序输出的KV数据,业务逻辑在reduce()方法中;
Driver模块:将程序提交到yarn进行调度,提交封装了运行参数的job对象;
四、序列化操作
1、序列化简介
序列化:将内存中对象转换为二进制的字节序列,可以通过输出流持久化存储或者网络传输;
反序列化:接收输入字节流或者读取磁盘持久化的数据,加载到内存的对象过程;
Hadoop序列化相关接口:Writable实现的序列化机制、Comparable管理Key的排序问题;
2、案例实现
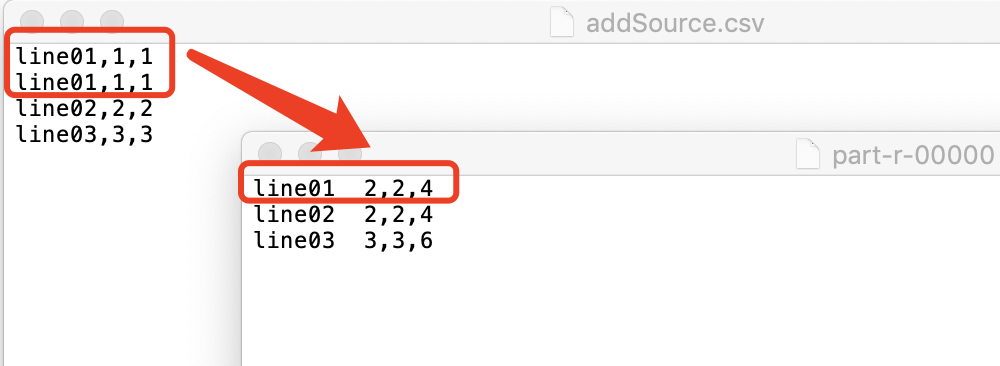
案例描述:读取文件,并对文件相同的行做数据累加计算,输出计算结果;该案例演示在本地执行,不把Jar包上传的hadoop服务器,驱动配置一致。
实体对象属性
public class AddEntity implements Writable {
private long addNum01;
private long addNum02;
private long resNum;
// 构造方法
public AddEntity() {
super();
}
public AddEntity(long addNum01, long addNum02) {
super();
this.addNum01 = addNum01;
this.addNum02 = addNum02;
this.resNum = addNum01 + addNum02;
}
// 序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(addNum01);
dataOutput.writeLong(addNum02);
dataOutput.writeLong(resNum);
}
// 反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
// 注意:反序列化顺序和写序列化顺序一致
this.addNum01 = dataInput.readLong();
this.addNum02 = dataInput.readLong();
this.resNum = dataInput.readLong();
}
// 省略Get和Set方法
}
Mapper机制
public class AddMapper extends Mapper<LongWritable, Text, Text, AddEntity> {
Text myKey = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 读取行
String line = value.toString();
// 行内容切割
String[] lineArr = line.split(",");
// 内容格式处理
String lineNum = lineArr[0];
long addNum01 = Long.parseLong(lineArr[1]);
long addNum02 = Long.parseLong(lineArr[2]);
myKey.set(lineNum);
AddEntity myValue = new AddEntity(addNum01,addNum02);
// 输出
context.write(myKey, myValue);
}
}
Reducer机制
public class AddReducer extends Reducer<Text, AddEntity, Text, AddEntity> {
@Override
protected void reduce(Text key, Iterable<AddEntity> values, Context context)
throws IOException, InterruptedException {
long addNum01Sum = 0;
long addNum02Sum = 0;
// 处理Key相同
for (AddEntity addEntity : values) {
addNum01Sum += addEntity.getAddNum01();
addNum02Sum += addEntity.getAddNum02();
}
// 最终输出
AddEntity addRes = new AddEntity(addNum01Sum, addNum02Sum);
context.write(key, addRes);
}
}
案例最终结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号