1.11 flask
2019-1-11 16:14:34
还有一天flask剩下的就是爬虫了!
越努力,越幸运!永远不要高估自己!
别人玩,你在默默努力!上帝不会亏待你的!
Flask-SQLAlchemy参考连接
https://www.cnblogs.com/wupeiqi/articles/8259356.html
wtforms组件会用就好,没必要非得搞明白源码!
创建个对象过程
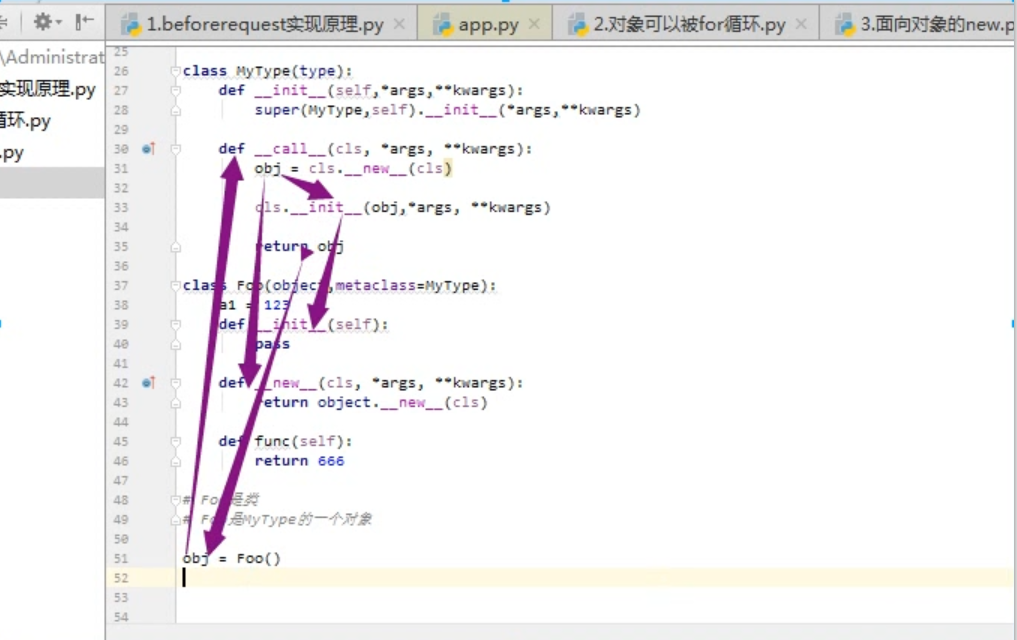
wtforms实现,py
from flask import Flask,request,render_template,session,current_app,g,redirect from wtforms import Form from wtforms.csrf.core import CSRF from wtforms.fields import simple from wtforms.fields import html5 from wtforms.fields import core from hashlib import md5 from wtforms import widgets from wtforms import validators app = Flask(__name__) class LoginForm(Form): name = simple.StringField( validators=[ validators.DataRequired(message='用户名不能为空.'), ], widget=widgets.TextInput(), render_kw={'placeholder':'请输入用户名'} ) pwd = simple.PasswordField( validators=[ validators.DataRequired(message='密码不能为空.'), ], render_kw={'placeholder':'请输入密码'} ) def validate_name(self, field): """ 自定义name字段规则 :param field: :return: """ # 最开始初始化时,self.data中已经有所有的值 print('钩子函数获取的值',field.data) if not field.data.startswith('old'): raise validators.ValidationError("用户名必须以old开头") # 继续后续验证 # raise validators.StopValidation("用户名必须以old开头") # 不再继续后续验证 @app.route('/login',methods=['GET','POST']) def login(): if request.method == "GET": form = LoginForm() return render_template('login.html',form=form) form = LoginForm(formdata=request.form) if form.validate(): print(form.data) return redirect('https://www.luffycity.com/home') else: return render_template('login.html', form=form) if __name__ == '__main__': app.run()
models.py
from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column from sqlalchemy import Integer,String,Text,Date,DateTime,ForeignKey,UniqueConstraint, Index from sqlalchemy import create_engine from sqlalchemy.orm import relationship Base = declarative_base() class Depart(Base): __tablename__ = 'depart' id = Column(Integer, primary_key=True) title = Column(String(32), index=True, nullable=False) class Users(Base): __tablename__ = 'users' id = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=False) depart_id = Column(Integer,ForeignKey("depart.id")) dp = relationship("Depart", backref='pers') class Student(Base): __tablename__ = 'student' id = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=False) course_list = relationship('Course', secondary='student2course', backref='student_list') class Course(Base): __tablename__ = 'course' id = Column(Integer, primary_key=True) title = Column(String(32), index=True, nullable=False) class Student2Course(Base): __tablename__ = 'student2course' id = Column(Integer, primary_key=True, autoincrement=True) student_id = Column(Integer, ForeignKey('student.id')) course_id = Column(Integer, ForeignKey('course.id')) __table_args__ = ( UniqueConstraint('student_id', 'course_id', name='uix_stu_cou'), # 联合唯一索引 # Index('ix_id_name', 'name', 'extra'), # 联合索引 ) def create_all(): engine = create_engine( "mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.create_all(engine) def drop_all(): engine = create_engine( "mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.drop_all(engine) if __name__ == '__main__': # drop_all() create_all()
用SQLalchemy查询
s1.py
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from models import Users engine = create_engine( "mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) # 根据Users类对users表进行增删改查 session = SessionFactory() # ############################## 基本增删改查 ############################### # 1. 增加 # obj = Users(name='alex') # session.add(obj) # session.commit() # session.add_all([ # Users(name='小东北'), # Users(name='龙泰') # ]) # session.commit() # 2. 查 # result = session.query(Users).all() # for row in result: # print(row.id,row.name) # result = session.query(Users).filter(Users.id >= 2) # for row in result: # print(row.id,row.name) # result = session.query(Users).filter(Users.id >= 2).first() # print(result) # 3.删 # session.query(Users).filter(Users.id >= 2).delete() # session.commit() # 4.改 # session.query(Users).filter(Users.id == 4).update({Users.name:'东北'}) # session.query(Users).filter(Users.id == 4).update({'name':'小东北'}) # session.query(Users).filter(Users.id == 4).update({'name':Users.name+"DSB"},synchronize_session=False) # session.commit() # ############################## 其他常用 ############################### # 1. 指定列 # select id,name as cname from users; # result = session.query(Users.id,Users.name.label('cname')).all() # for item in result: # print(item[0],item.id,item.cname) # 2. 默认条件and # session.query(Users).filter(Users.id > 1, Users.name == 'eric').all() # 3. between # session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all() # 4. in # session.query(Users).filter(Users.id.in_([1,3,4])).all() # session.query(Users).filter(~Users.id.in_([1,3,4])).all() # 5. 子查询 # session.query(Users).filter(Users.id.in_(session.query(Users.id).filter(Users.name=='eric'))).all() # 6. and 和 or # from sqlalchemy import and_, or_ # session.query(Users).filter(Users.id > 3, Users.name == 'eric').all() # session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all() # session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all() # session.query(Users).filter( # or_( # Users.id < 2, # and_(Users.name == 'eric', Users.id > 3), # Users.extra != "" # )).all() # 7. filter_by # session.query(Users).filter_by(name='alex').all() # 8. 通配符 # ret = session.query(Users).filter(Users.name.like('e%')).all() # ret = session.query(Users).filter(~Users.name.like('e%')).all() # 9. 切片 # result = session.query(Users)[1:2] # 10.排序 # ret = session.query(Users).order_by(Users.name.desc()).all() # ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() # 11. group by from sqlalchemy.sql import func # ret = session.query( # Users.depart_id, # func.count(Users.id), # ).group_by(Users.depart_id).all() # for item in ret: # print(item) # # from sqlalchemy.sql import func # # ret = session.query( # Users.depart_id, # func.count(Users.id), # ).group_by(Users.depart_id).having(func.count(Users.id) >= 2).all() # for item in ret: # print(item) # 12.union 和 union all """ select id,name from users UNION select id,name from users; """ # q1 = session.query(Users.name).filter(Users.id > 2) # q2 = session.query(Favor.caption).filter(Favor.nid < 2) # ret = q1.union(q2).all() # # q1 = session.query(Users.name).filter(Users.id > 2) # q2 = session.query(Favor.caption).filter(Favor.nid < 2) # ret = q1.union_all(q2).all() session.close()
s2.py
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from models import Users,Depart engine = create_engine( "mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) # 根据Users类对users表进行增删改查 session = SessionFactory() # 1. 查询所有用户 # ret = session.query(Users).all() # for row in ret: # print(row.id,row.name,row.depart_id) # 2. 查询所有用户+所属部门名称 # ret = session.query(Users.id,Users.name,Depart.title).join(Depart,Users.depart_id == Depart.id).all() # for row in ret: # print(row.id,row.name,row.title) # query = session.query(Users.id,Users.name,Depart.title).join(Depart,Users.depart_id == Depart.id,isouter=True) # print(query) # 3. relation字段:查询所有用户+所属部门名称 # ret = session.query(Users).all() # for row in ret: # print(row.id,row.name,row.depart_id,row.dp.title) # 4. relation字段:查询销售部所有的人员 # obj = session.query(Depart).filter(Depart.title == '销售').first() # for row in obj.pers: # print(row.id,row.name,obj.title) # 5. 创建一个名称叫:IT部门,再在该部门中添加一个员工:田硕 # 方式一: # d1 = Depart(title='IT') # session.add(d1) # session.commit() # # u1 = Users(name='田硕',depart_id=d1.id) # session.add(u1) # session.commit() # 方式二: # u1 = Users(name='田硕',dp=Depart(title='IT')) # session.add(u1) # session.commit() # 6. 创建一个名称叫:王者荣耀,再在该部门中添加一个员工:龚林峰/长好梦/王爷们 # d1 = Depart(title='王者荣耀') # d1.pers = [Users(name='龚林峰'),Users(name='长好梦'),Users(name='王爷们'),] # session.add(d1) # session.commit() session.close()
s3.py
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from models import Student,Course,Student2Course engine = create_engine( "mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) # 根据Users类对users表进行增删改查 session = SessionFactory() # 1. 录入数据 # session.add_all([ # Student(name='先用'), # Student(name='佳俊'), # Course(title='生物'), # Course(title='体育'), # ]) # session.commit() # session.add_all([ # Student2Course(student_id=2,course_id=1) # ]) # session.commit() # 2. 三张表关联 # ret = session.query(Student2Course.id,Student.name,Course.title).join(Student,Student2Course.student_id==Student.id,isouter=True).join(Course,Student2Course.course_id==Course.id,isouter=True).order_by(Student2Course.id.asc()) # for row in ret: # print(row) # 3. “先用”选的所有课 # ret = session.query(Student2Course.id,Student.name,Course.title).join(Student,Student2Course.student_id==Student.id,isouter=True).join(Course,Student2Course.course_id==Course.id,isouter=True).filter(Student.name=='先用').order_by(Student2Course.id.asc()).all() # print(ret) # obj = session.query(Student).filter(Student.name=='先用').first() # for item in obj.course_list: # print(item.title) # 4. 选了“生物”的所有人 # obj = session.query(Course).filter(Course.title=='生物').first() # for item in obj.student_list: # print(item.name) # 5. 创建一个课程,创建2学生,两个学生选新创建的课程。 # obj = Course(title='英语') # obj.student_list = [Student(name='为名'),Student(name='广宗')] # # session.add(obj) # session.commit() session.close()
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from models import Student,Course,Student2Course engine = create_engine( "mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) def task(): # 去连接池中获取一个连接 session = SessionFactory() ret = session.query(Student).all() # 将连接交还给连接池 session.close() from threading import Thread for i in range(20): t = Thread(target=task) t.start()
s5.py
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session from models import Student,Course,Student2Course engine = create_engine( "mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) session = scoped_session(SessionFactory) def task(): ret = session.query(Student).all() # 将连接交还给连接池 session.remove() from threading import Thread for i in range(20): t = Thread(target=task) t.start()
s6.py
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session from models import Student,Course,Student2Course engine = create_engine( "mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) session = scoped_session(SessionFactory) def task(): """""" # 方式一: """ # 查询 # cursor = session.execute('select * from users') # result = cursor.fetchall() # 添加 cursor = session.execute('INSERT INTO users(name) VALUES(:value)', params={"value": 'wupeiqi'}) session.commit() print(cursor.lastrowid) """ # 方式二: """ # conn = engine.raw_connection() # cursor = conn.cursor() # cursor.execute( # "select * from t1" # ) # result = cursor.fetchall() # cursor.close() # conn.close() """ # 将连接交还给连接池 session.remove() from threading import Thread for i in range(20): t = Thread(target=task) t.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号