
python爬虫B站每周热榜
一、选题的背景
为什么要选择此选题?要达到的数据分析的预期目标是什么?(10 分)
从社会、经济、技术、数据来源等方面进行描述(200 字以内)
在现今短视频洪流的影响下,拥有众多年轻人所钟爱的b站无疑是非常具有发展前景的,B站平均年龄21岁,新注册用户不到20岁,而且12个月80%以上会留下来,这个留存率是特别惊人的,这代表未来社会的中流砥柱以及现在社会上的主力的三十岁以下的年轻人都在B站或者说都在高速涌入B站并且来了就不走了。上一个这样的数据还是在QQ,腾讯帝国的根基正是始于此,而抓住了年轻人的b站在我看来是会有一个不错的未来的。在学习完网络爬虫等章节后,以及某天在b站看到爬取豆瓣top250的视频,我不由得想到爬取B站每周热榜。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称
2.主题式网络爬虫爬取的内容与数据特征分析
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
1. 基于B站每周必看从第1期到140期的数据爬取
网站链接:https://www.bilibili.com/v/popular/weekly?num=141
该网页链接只是第141期的每周必看的页面。然后开始检查网页的数据是存在于HTML里面是通过JSON的方式获取的。
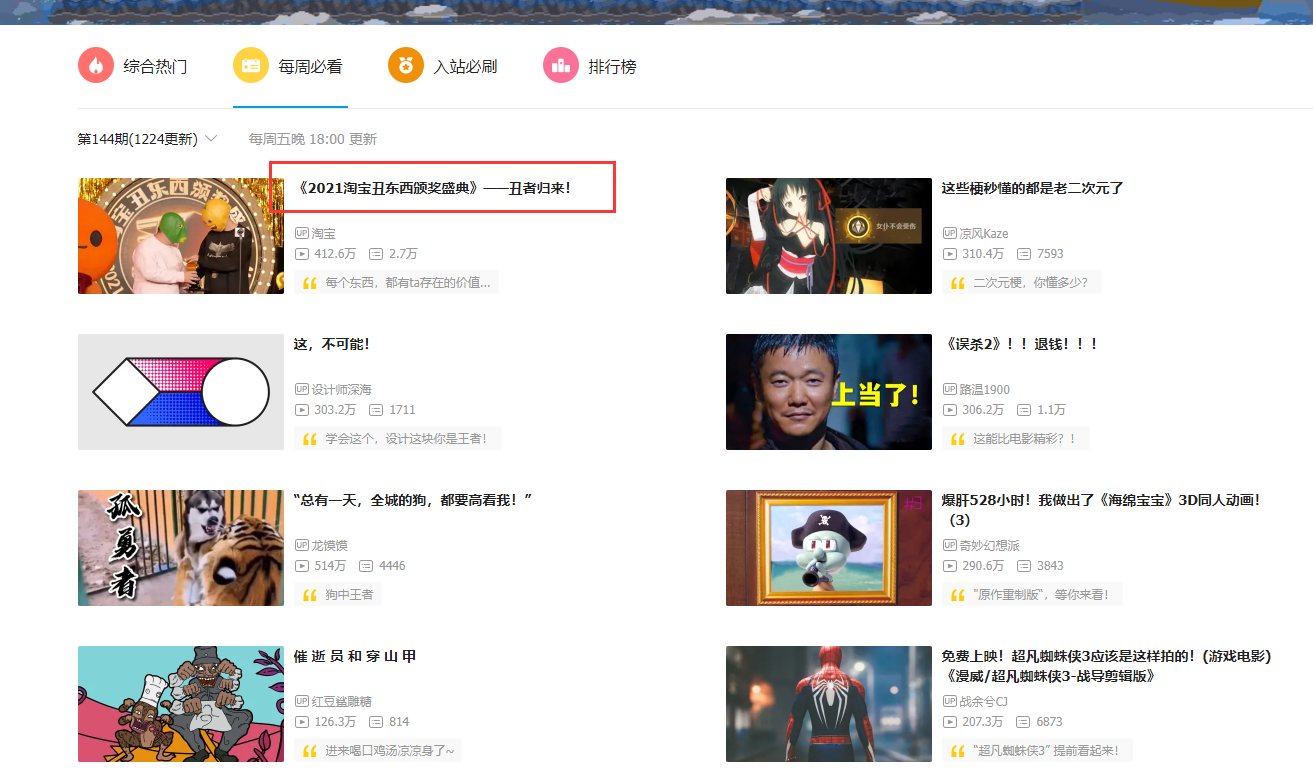
2. 爬取的主要是B站每周的必看排行榜,爬虫内容基于异步加载,数据以json的格式返回,比起将js放在head中,默认方式是同步加载,这样更为简洁和方便。
3. 数据不直接从网页获得,而是通过异步加载获得。
(1) 思路:模仿异步请求方式获取接口数据
(2) 难点:json数据结构,数据持久化,追加excel
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
2.Htmls 页面解析
3.节点(标签)查找方法与遍历方法(必要时画出节点树结构)
1. 页面的格式类似 ul 和li标签的格式 但是数据没在其中
2. 不进行html网页的解析,而是对接口数据进行json提取。
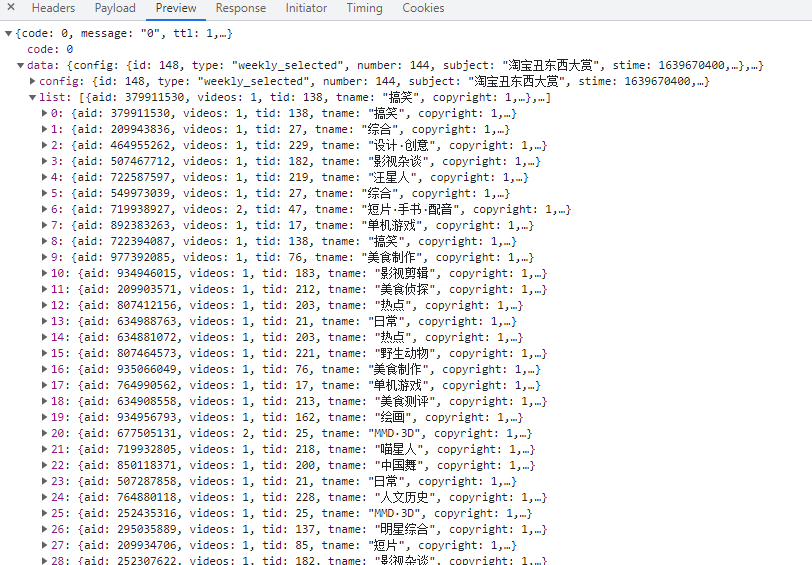
3. 获取到json中的list然后循环获取到指定的数据如:up主id,播放量等信息。
详细页面分析:
1.打开源码
2.复制数据

3. 检查HTML源码是否存在数据:
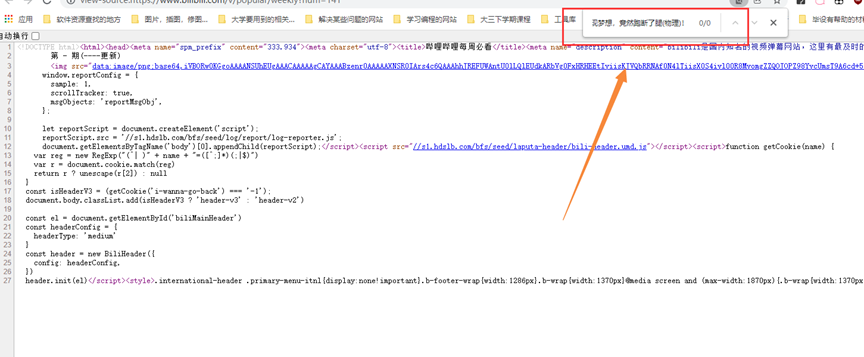
由此我们可以得出网页的数据来源并没有镶嵌在HTML中。所以应该存在JSON当中,接下来就是查看json数据来源
1. 打开开发者模式操作如图或则F12
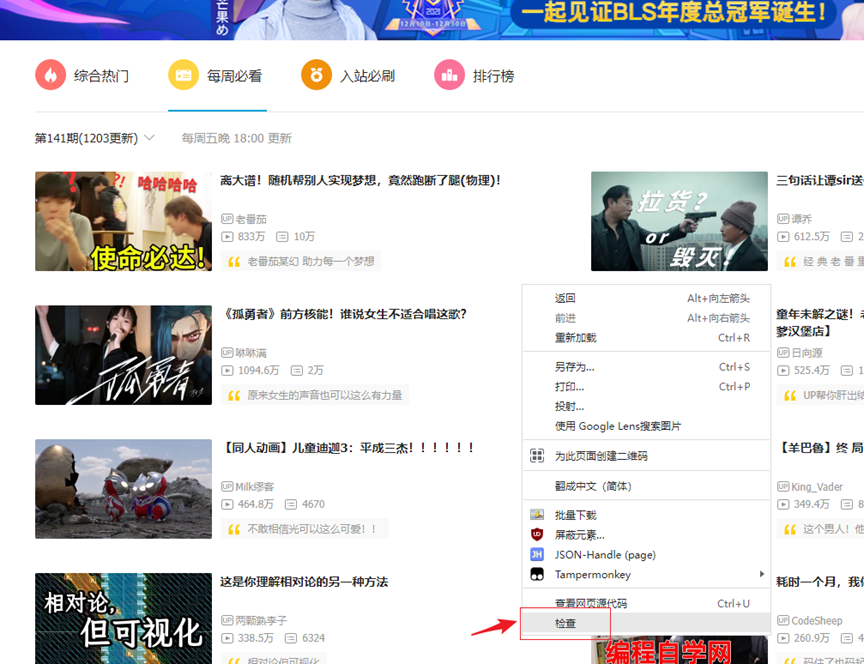
2.进入network

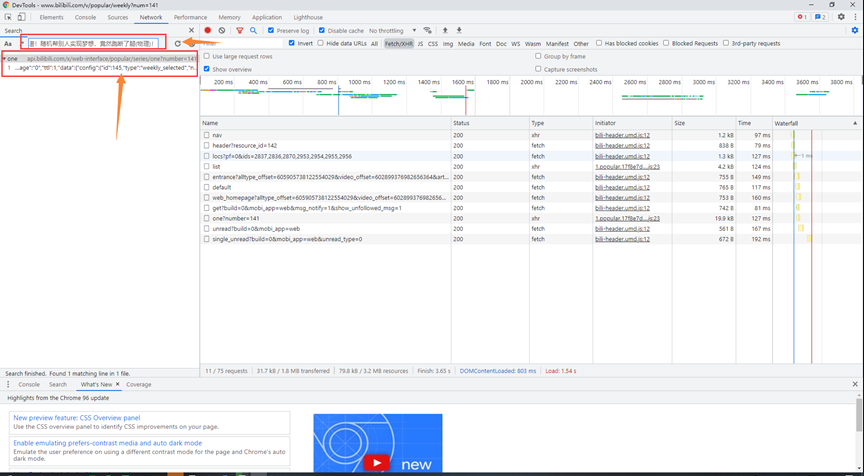
3.刷新页面获取到JSON数据的数据链接:(通过刚才复制的内容找到JSON所在的位置)
4. 获取链接并进行数据爬取:
(1)JSON数据预览。

(2)获取请求链接以及请求时的headers模拟浏览器访问服务器。
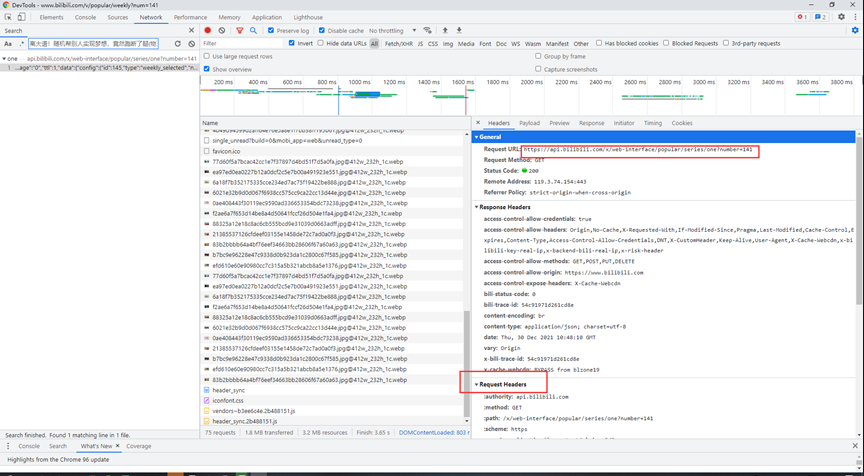
(3) 参数设置(从图中可以得到,我们只需要修改其中的number就可以改变我们想要每周的数据了)

|
URL JSON
https://api.bilibili.com/x/web-interface/popular/series/one?number=141 |
|
Headers
{ "accept": "application/json, text/plain, */*", "accept-encoding": "gzip, deflate, br", "accept-language": "zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7", "cache-control": "no-cache", "cookie": "buvid3=2689D680-DEA5-4931-F5A5-936A858E0A4818066infoc; blackside_state=1; fingerprint=307d2df668b86c9b801f9011702c0d18; buvid_fp=2689D680-DEA5-4931-F5A5-936A858E0A4818066infoc; buvid_fp_plain=2689D680-DEA5-4931-F5A5-936A858E0A4818066infoc; SESSDATA=a9a08d06%2C1647702446%2C6703b%2A91; bili_jct=af2e618bad59c5549d3244e6147d4a47; DedeUserID=149746646; DedeUserID__ckMd5=94ffcc3be97f858f; sid=7o9phjau; rpdid=|(u~)llJJmuk0J'uYJkul|R~m; LIVE_BUVID=AUTO7316362940569687; _uuid=DFE7584C-1FFE-4B31-DCCC-6D33292BAEFD15306infoc; video_page_version=v_old_home; bp_video_offset_149746646=602899376982656364; bp_t_offset_149746646=605905738122554029; CURRENT_QUALITY=0; i-wanna-go-back=-1; b_ut=5; CURRENT_BLACKGAP=0; CURRENT_FNVAL=2000; innersign=0", "origin": "https://www.bilibili.com", "pragma": "no-cache", "referer": "https://www.bilibili.com/", "sec-ch-ua": "\" Not A;Brand\";v=\"99\", \"Chromium\";v=\"96\", \"Google Chrome\";v=\"96\"", "sec-ch-ua-mobile": "?0", "sec-ch-ua-platform": "\"Windows\"", "sec-fetch-dest": "empty", "sec-fetch-mode": "cors", "sec-fetch-site": "same-site", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" } |
四、网络爬虫程序设计
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
1 import requests 2 import pandas as pd 3 from requests_html import HTMLSession 4 session = HTMLSession() # 自带了user-agent 5 def get_data(): 6 """ 7 get_data函数是用于爬取B站每周必看的视屏数据信息 8 """ 9 for i in range(1, 142): 10 res = session.get( 11 # 该数据 并不在网页上,而是通过异步加载的方式获取的数据 12 # 然后我们通过访问接口活得json数据 13 url="https://api.bilibili.com/x/web-interface/popular/series/one?number={}".format(i) 14 ) 15 all_data = [] 16 # 查看是否爬取成功 17 print(i, res.status_code, "数据获取成功!") 18 # 获取接口返回的数据 19 js = res.json() 20 # 读取json文件的每个视频信息并存放到一个列表里面,用于后期的持久化 21 week = i 22 videos = js["data"]["list"] 23 for rank, video in enumerate(videos): 24 all_data.append( 25 [ 26 week, 27 rank + 1, 28 video["aid"], 29 video["tname"], 30 video["title"], 31 video["pubdate"], 32 video["owner"]["mid"], 33 video["owner"]["name"], 34 video["owner"]["face"], 35 video["pic"], 36 video["stat"]["view"], 37 video["stat"]["danmaku"], 38 video["stat"]["reply"], 39 video["stat"]["favorite"], 40 video["stat"]["coin"], 41 video["stat"]["share"], 42 video["stat"]["like"], 43 video["short_link"], 44 video["bvid"], 45 video["rcmd_reason"], 46 ] 47 ) 48 # print(all_data) 49 50 src_data = pd.read_excel("hot_week.xlsx") 51 52 data = pd.DataFrame(all_data, 53 columns=["week", "rank", "aid", "tname", "title", "pubdate", "owner_mid", "owner_name", 54 "owner_face", "pic", "view", "danmaku", "reply", "favorite", "coin", 55 "share", "like", "link", "bvid", "rcmd_reason"]) 56 57 pd.DataFrame(src_data).append(data).to_excel("hot_week.xlsx", index=False)
开始数据爬取
# 初始化excel表格用于数据存放 # pd.DataFrame([], columns=["week", "rank","aid", "tname", "title", "pubdate", "owner_mid", "owner_name", # "owner_face", "pic", "view", "danmaku", "reply", "favorite", "coin", # "share", "like", "link", "bvid", "rcmd_reason"]).to_excel("hot_week.xlsx", index=False) # 调用爬虫方法 # get_data()


2.对数据进行清洗和处理
读取数据
1 data = pd.read_excel("./hot_week.xlsx") 2 data

查看数据的columns
有以下步骤:
1.获取columns
2.得到需要处理和分析的column name
3.获得新的DataFrame
1 data.columns

1 need_columns = ['week','tname', 'title', 'owner_name','view', 'danmaku', 'reply','favorite', 'coin', 'share', 'like'] 2 need_data = pd.DataFrame(data, columns=need_columns) 3 need_data
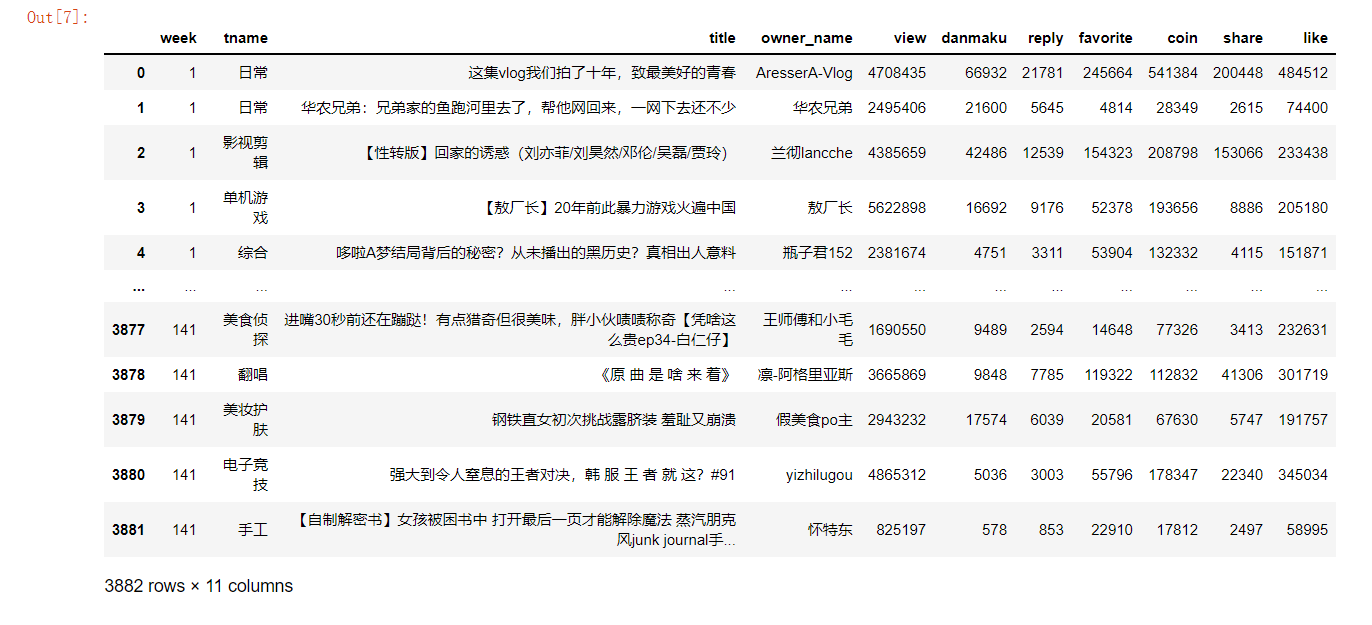
need_data.clip()
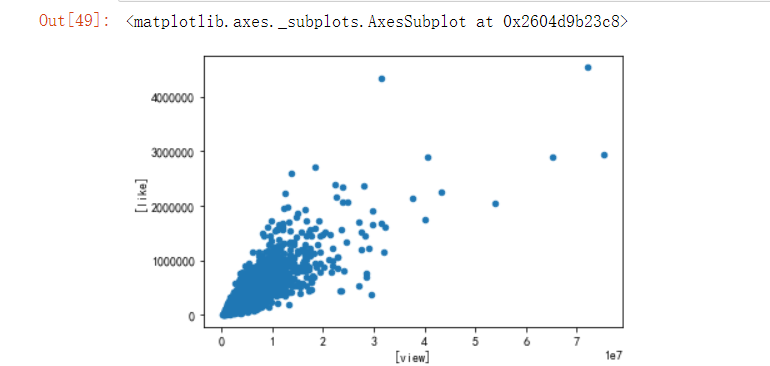
1 # need_data.plot.scatter() 2 pd.DataFrame(need_data, columns=["view", "like"]).plot.scatter(x=["view"], y=["like"])
3.文本分析(可选):jieba 分词、wordcloud 的分词可视化
以下是思路
(1)将所有的标题进行分词统计查看140周中标题中最热的词是那些,并使用pyecharts制作词云。
(2)统计tname也即是视频类型的分布情况,使用柱状图进行分析。
(3)用折线图来分析从第一周到140周热门每周必看视频的增加情况。
用到收集工具collections和绘图工具pyecharts
1 from collections import Counter # 用作词频统计 2 import jieba 3 from pyecharts import options as opts 4 from pyecharts.charts import WordCloud 5 titles = need_data.loc[:, "title"] 6 titles
1 def my_counter(words): 2 counter = {} 3 for word in words: 4 if counter.get(word) is None: 5 counter[word] = 1 6 else: 7 counter[word] += 1 8 return counter
1 titles = need_data.loc[:, "title"]
2 titles

1 words = jieba.lcut("".join(titles))
2 words[:10]

1 word_counter = Counter(words)
2 word_counter

从上面可以得出我们的分词效果有很多不好的,所以这样分词是不好的,所以我们选择下面的方式进行
1 # 导入jieba中的的tag抽取包 2 from jieba import analyse 3 word_data = [] 4 for title in titles: 5 word_list = analyse.extract_tags(title) 6 word_data += word_list 7 new_word_counter = Counter(word_data)
可以看出得出来比较好的效果,不用人为的去定义要少了那些停用词
接下来就是词云可视化
1 from wordcloud import WordCloud 2 font = r'C:\Windows\Fonts\STCAIYUN.TTF'#字体路径 3 4 # 关键一步 5 my_wordcloud = WordCloud(scale=4,font_path=font,background_color='white', 6 max_words = 100,max_font_size = 60,random_state=40).generate(" ".join(word_data)) 7 8 9 #显示生成的词云 10 plt.figure(figsize=[15, 10]) 11 plt.imshow(my_wordcloud) 12 plt.axis("off") 13 plt.show()

4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
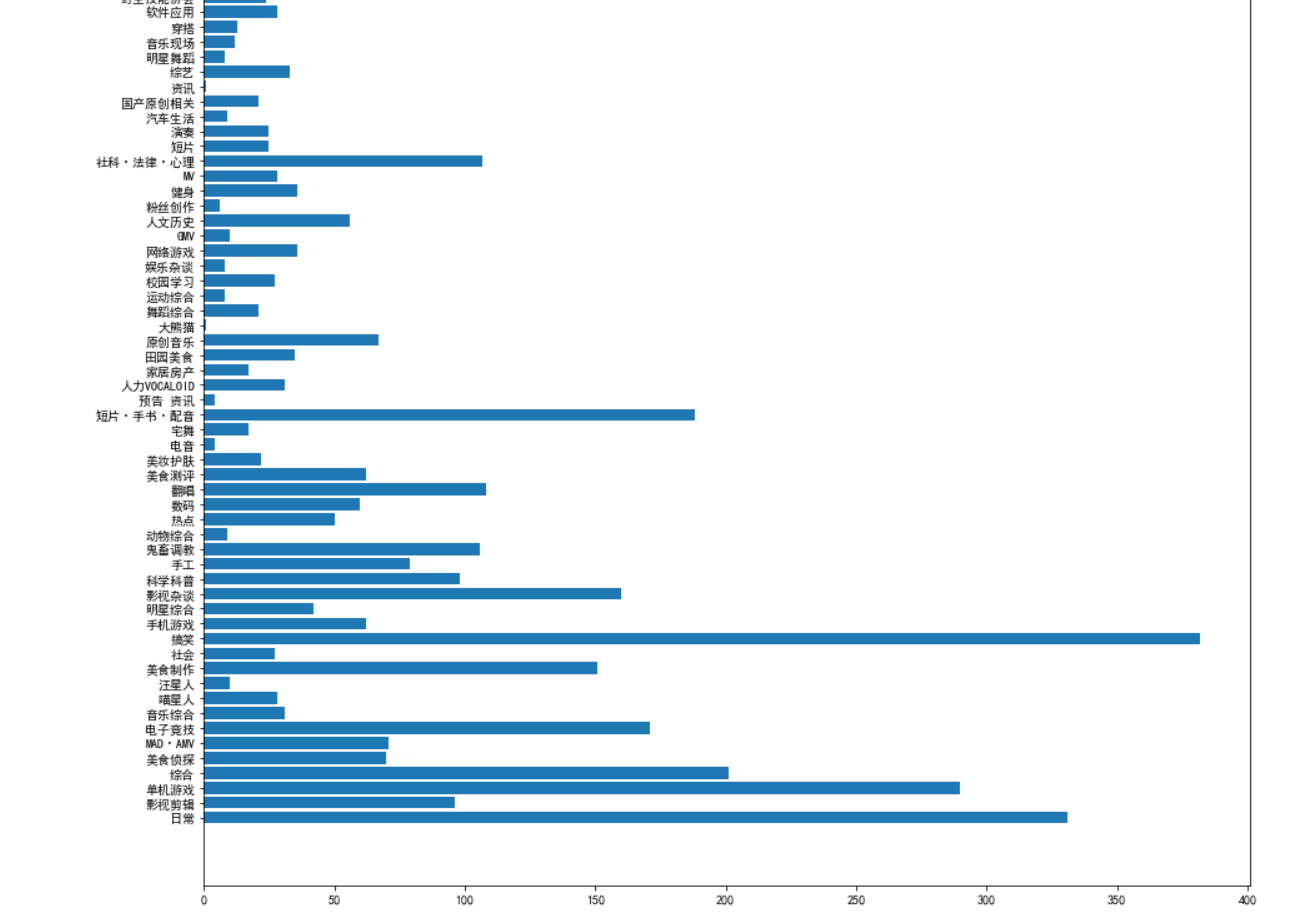
柱状图分析视频类型分布
1 types = need_data.loc[:, "tname"]
2 types[:10]

1 types_counter = Counter(types)
2 types_counter

1 from pyecharts.charts import Bar # 导入柱状图 2 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 3 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 4 5 plt.figure(figsize=[15, 20]) 6 plt.barh(y=[k for k, v in types_counter.items()], width=[v for k, v in types_counter.items()]) 7 plt.show()
统计视频的数量变化情况
1 from pyecharts.charts import Line 2 weeks = need_data.loc[:, "week"] 3 weeks[:10]

1 week_counter = Counter(weeks)
2 week_counter
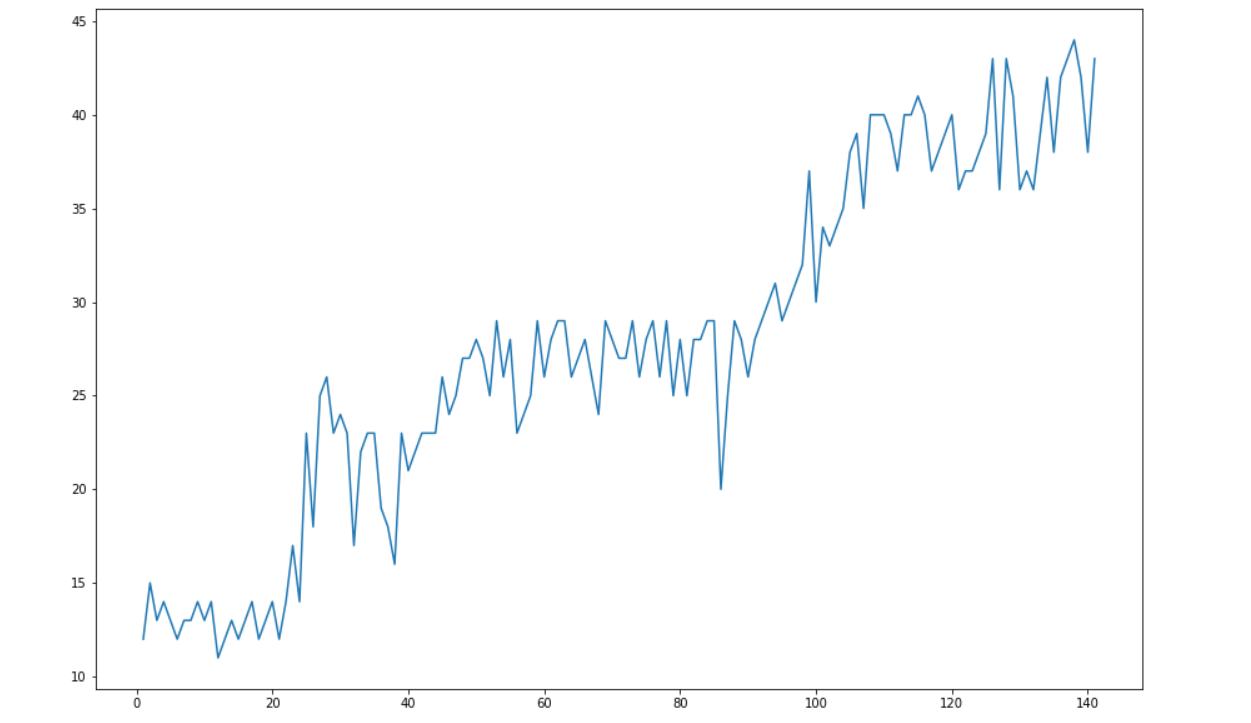
1 # 每日必看视频随时间的变化 2 x = [k for k, v in week_counter.items()] 3 y = [v for k, v in week_counter.items()] 4 plt.figure(figsize=[15, 10]) 5 plt.plot(x, y) 6 plt.show()
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)。
先分析数据
need_data
分析点赞量和播放量之间的关系
1 import matplotlib.pyplot as plt 2 import pandas as pd 3 from sklearn.linear_model import LinearRegression 4 dia = need_data.loc[:,'view'].values 5 price = need_data.loc[:,'like'].values 6 print(dia) 7 print(price)

1 model = LinearRegression() # 创建模型 2 X = dia.reshape((-1,1)) 3 y = price 4 model.fit(X, y) # 拟合 5 dia_x = [] 6 for d in dia: 7 dia_x.append([d]) 8 X2 = dia_x # 取两个预测值 9 y2 = model.predict(X2) # 进行预测 10 print(y2) # 查看预测值
1 plt.figure(figsize=[15, 10]) 2 plt.plot(dia, price, 'k.') 3 plt.plot(X2, y2, 'g-') # 画出拟合曲线 4 plt.savefig("view_like.jpg") # 保存图片 5 plt.show()

1 dia = need_data.loc[:,'like'].values 2 price = need_data.loc[:,'coin'].values 3 4 model = LinearRegression() # 创建模型 5 X = dia.reshape((-1,1)) 6 y = price 7 model.fit(X, y) # 拟合 8 dia_x = [] 9 for d in dia: 10 dia_x.append([d]) 11 12 X2 = dia_x # 取两个预测值 13 y2 = model.predict(X2) # 进行预测 14 15 16 plt.figure(figsize=[15, 10]) 17 plt.plot(dia, price, 'k.') 18 plt.plot(X2, y2, 'g-') # 画出拟合曲线 19 plt.savefig("like_coin.jpg") # 保存图片 20 plt.show()

1 dia = need_data.loc[:,'favorite'].values 2 price = need_data.loc[:,'share'].values 3 4 model = LinearRegression() # 创建模型 5 X = dia.reshape((-1,1)) 6 y = price 7 model.fit(X, y) # 拟合 8 dia_x = [] 9 for d in dia: 10 dia_x.append([d]) 11 12 X2 = dia_x # 取两个预测值 13 y2 = model.predict(X2) # 进行预测 14 15 16 plt.figure(figsize=[15, 10]) 17 plt.plot(dia, price, 'k.') 18 plt.plot(X2, y2, 'g-') # 画出拟合曲线 19 plt.savefig("favorite_share.jpg") # 保存图片 20 plt.show()
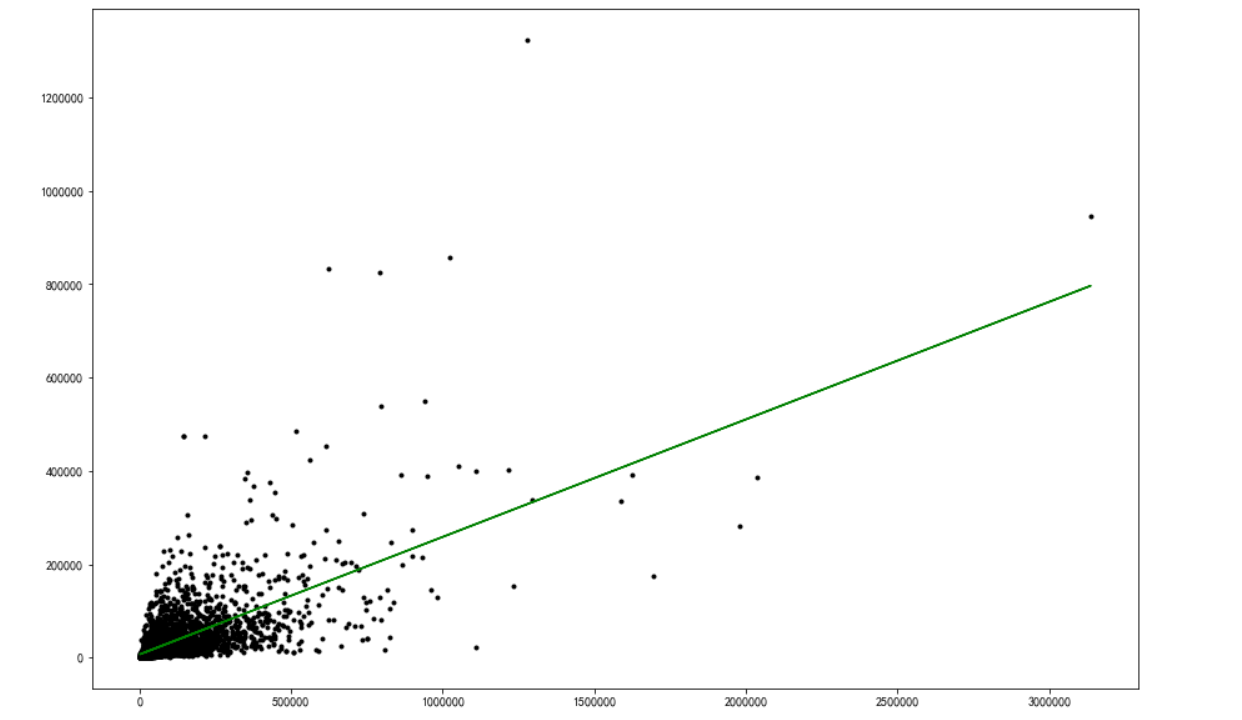
从以上可以看出以上 view和like、like和coin、faverate和share中like和coin的相关性比较强,而且离散不强
6.数据持久化
pd.DataFrame(need_data).to_excel("need_data.xlsx")

7.将以上各部分的代码汇总,附上完整程序代码
1 import requests 2 import pandas as pd 3 from requests_html import HTMLSession 4 session = HTMLSession() # 自带了user-agent 5 def get_data(): 6 """ 7 get_data函数是用于爬取B站每周必看的视屏数据信息 8 """ 9 for i in range(1, 142): 10 res = session.get( 11 # 该数据 并不在网页上,而是通过异步加载的方式获取的数据 12 # 然后我们通过访问接口活得json数据 13 url="https://api.bilibili.com/x/web-interface/popular/series/one?number={}".format(i) 14 ) 15 all_data = [] 16 # 查看是否爬取成功 17 print(i, res.status_code, "数据获取成功!") 18 # 获取接口返回的数据 19 js = res.json() 20 # 读取json文件的每个视频信息并存放到一个列表里面,用于后期的持久化 21 week = i 22 videos = js["data"]["list"] 23 for rank, video in enumerate(videos): 24 all_data.append( 25 [ 26 week, 27 rank + 1, 28 video["aid"], 29 video["tname"], 30 video["title"], 31 video["pubdate"], 32 video["owner"]["mid"], 33 video["owner"]["name"], 34 video["owner"]["face"], 35 video["pic"], 36 video["stat"]["view"], 37 video["stat"]["danmaku"], 38 video["stat"]["reply"], 39 video["stat"]["favorite"], 40 video["stat"]["coin"], 41 video["stat"]["share"], 42 video["stat"]["like"], 43 video["short_link"], 44 video["bvid"], 45 video["rcmd_reason"], 46 ] 47 ) 48 # print(all_data) 49 50 src_data = pd.read_excel("hot_week.xlsx") 51 52 53 data = pd.DataFrame(all_data, 54 columns=["week", "rank", "aid", "tname", "title", "pubdate", "owner_mid", "owner_name", 55 "owner_face", "pic", "view", "danmaku", "reply", "favorite", "coin", 56 "share", "like", "link", "bvid", "rcmd_reason"]) 57 58 pd.DataFrame(src_data).append(data).to_excel("hot_week.xlsx", index=False) 59 60 61 # 初始化excel表格用于数据存放 62 # pd.DataFrame([], columns=["week", "rank","aid", "tname", "title", "pubdate", "owner_mid", "owner_name", 63 # "owner_face", "pic", "view", "danmaku", "reply", "favorite", "coin", 64 # "share", "like", "link", "bvid", "rcmd_reason"]).to_excel("hot_week.xlsx", index=False) 65 # 调用爬虫方法 66 67 # get_data() 68 data = pd.read_excel("./hot_week.xlsx") 69 data 70 data.columns 71 72 73 need_columns = ['week','tname', 'title', 'owner_name','view', 'danmaku', 'reply','favorite', 'coin', 'share', 'like'] 74 need_data = pd.DataFrame(data, columns=need_columns) 75 need_data 76 77 need_data.clip() 78 79 # need_data.plot.scatter() 80 2 pd.DataFrame(need_data, columns=["view", "like"]).plot.scatter(x=["view"], y=["like"]) 81 82 83 from collections import Counter # 用作词频统计 84 import jieba 85 from pyecharts import options as opts 86 from pyecharts.charts import WordCloud 87 titles = need_data.loc[:, "title"] 88 titles 89 90 def my_counter(words): 91 counter = {} 92 for word in words: 93 if counter.get(word) is None: 94 counter[word] = 1 95 else: 96 counter[word] += 1 97 return counter 98 99 100 titles = need_data.loc[:, "title"] 101 102 titles 103 104 words = jieba.lcut("".join(titles)) 105 106 words[:10] 107 108 word_counter = Counter(words) 109 110 word_counter 111 112 # 导入jieba中的的tag抽取包 113 from jieba import analyse 114 word_data = [] 115 for title in titles: 116 word_list = analyse.extract_tags(title) 117 word_data += word_list 118 new_word_counter = Counter(word_data) 119 120 from wordcloud import WordCloud 121 font = r'C:\Windows\Fonts\STCAIYUN.TTF'#字体路径 122 123 # 关键一步 124 my_wordcloud = WordCloud(scale=4,font_path=font,background_color='white', 125 max_words = 100,max_font_size = 60,random_state=40).generate(" ".join(word_data)) 126 127 128 #显示生成的词云 129 plt.figure(figsize=[15, 10]) 130 plt.imshow(my_wordcloud) 131 plt.axis("off") 132 plt.show() 133 134 types = need_data.loc[:, "tname"] 135 136 types[:10] 137 138 types_counter = Counter(types) 139 140 types_counter 141 142 from pyecharts.charts import Bar # 导入柱状图 143 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 144 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 145 146 plt.figure(figsize=[15, 20]) 147 plt.barh(y=[k for k, v in types_counter.items()], width=[v for k, v in types_counter.items()]) 148 plt.show() 149 150 from pyecharts.charts import Line 151 weeks = need_data.loc[:, "week"] 152 weeks[:10] 153 154 week_counter = Counter(weeks) 155 156 week_counter 157 158 # 每日必看视频随时间的变化 159 x = [k for k, v in week_counter.items()] 160 y = [v for k, v in week_counter.items()] 161 plt.figure(figsize=[15, 10]) 162 plt.plot(x, y) 163 plt.show() 164 165 need_data 166 167 import matplotlib.pyplot as plt 168 import pandas as pd 169 from sklearn.linear_model import LinearRegression 170 dia = need_data.loc[:,'view'].values 171 price = need_data.loc[:,'like'].values 172 print(dia) 173 print(price) 174 175 model = LinearRegression() # 创建模型 176 X = dia.reshape((-1,1)) 177 y = price 178 model.fit(X, y) # 拟合 179 dia_x = [] 180 for d in dia: 181 dia_x.append([d]) 182 X2 = dia_x # 取两个预测值 183 y2 = model.predict(X2) # 进行预测 184 print(y2) # 查看预测值 185 186 plt.figure(figsize=[15, 10]) 187 plt.plot(dia, price, 'k.') 188 plt.plot(X2, y2, 'g-') # 画出拟合曲线 189 plt.savefig("view_like.jpg") # 保存图片 190 plt.show() 191 192 dia = need_data.loc[:,'like'].values 193 price = need_data.loc[:,'coin'].values 194 195 model = LinearRegression() # 创建模型 196 X = dia.reshape((-1,1)) 197 y = price 198 model.fit(X, y) # 拟合 199 dia_x = [] 200 for d in dia: 201 dia_x.append([d]) 202 203 X2 = dia_x # 取两个预测值 204 y2 = model.predict(X2) # 进行预测 205 206 207 plt.figure(figsize=[15, 10]) 208 plt.plot(dia, price, 'k.') 209 plt.plot(X2, y2, 'g-') # 画出拟合曲线 210 plt.savefig("like_coin.jpg") # 保存图片 211 plt.show() 212 213 dia = need_data.loc[:,'favorite'].values 214 price = need_data.loc[:,'share'].values 215 216 model = LinearRegression() # 创建模型 217 X = dia.reshape((-1,1)) 218 y = price 219 model.fit(X, y) # 拟合 220 dia_x = [] 221 for d in dia: 222 dia_x.append([d]) 223 224 X2 = dia_x # 取两个预测值 225 y2 = model.predict(X2) # 进行预测 226 227 228 plt.figure(figsize=[15, 10]) 229 plt.plot(dia, price, 'k.') 230 plt.plot(X2, y2, 'g-') # 画出拟合曲线 231 plt.savefig("favorite_share.jpg") # 保存图片 232 plt.show() 233 234 pd.DataFrame(need_data).to_excel("need_data.xlsx")
五、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
2.在完成此设计过程中,得到哪些收获?以及要改进的建议
1.通过对数据的分析和可视化,可以得到词云,方便分析文本。可以得到视频视频类型以搞笑和日常为主要输出分布。可以看到从第一周到现在每周必看视频大体上呈上升趋势。可以看到 观看和点赞、点赞和硬币、收藏和分享中点赞和硬币的相关性比较强,而且离散性不强。
2.在此次设计中,我学到了不少新的工具和函数,比如collections和pyecharts,虽然还是很多不太能熟练使用,比如pyecharts用到一半还是使用了matplotlib但也熟悉了不少新知识,再比如异步加载这种以前从未接触过的知识。整体的完成有参考网络资源例如csdn和b站,也有问比较擅长的同学,一定程度上提高了我的学习能力。

