
python | 爬取网易云音乐下载
一、选题背景
由于现在的音乐版权问题,很多音乐分布在各个平台的音乐播放器,而版权问题也使很多人非常的困扰,从而找不到音乐的资源。因此为帮助使用网易云的伙伴们,更好的找到各个平台的资源,听到更多自己喜欢的歌。
二、爬虫方案设计
1.实现功能
2.具体实现
1.搜索部分
3.下载歌曲
1.再次获取信息
2.下载
4.结语
三、实现功能
可以分别对歌名,歌手,歌单进行搜索,搜索歌曲和歌单会列出页面第一页所显示的所有歌曲或歌单及其id以供选择下载,搜索歌手会下载网易云音乐列表显示第一位歌手的所有热门歌曲。
四、具体实现
1.搜索部分
网易云音乐搜索界面为:https://music.163.com/#/search ,经过测试发现
对单曲搜索时链接为:https://music.163.com/#/search/m/?s={}&type=1 ,
对歌手搜索时链接为:https://music.163.com/#/search/m/?s={}&type=100 ,
对歌单搜索时链接为:https://music.163.com/#/search/m/?s={}&type=1000
其中大括号中内容为要搜索内容的名称,例如搜索年少有为,网址为:https://music.163.com/#/search/m/?s=年少有为&type=1 搜索后即出现此页面
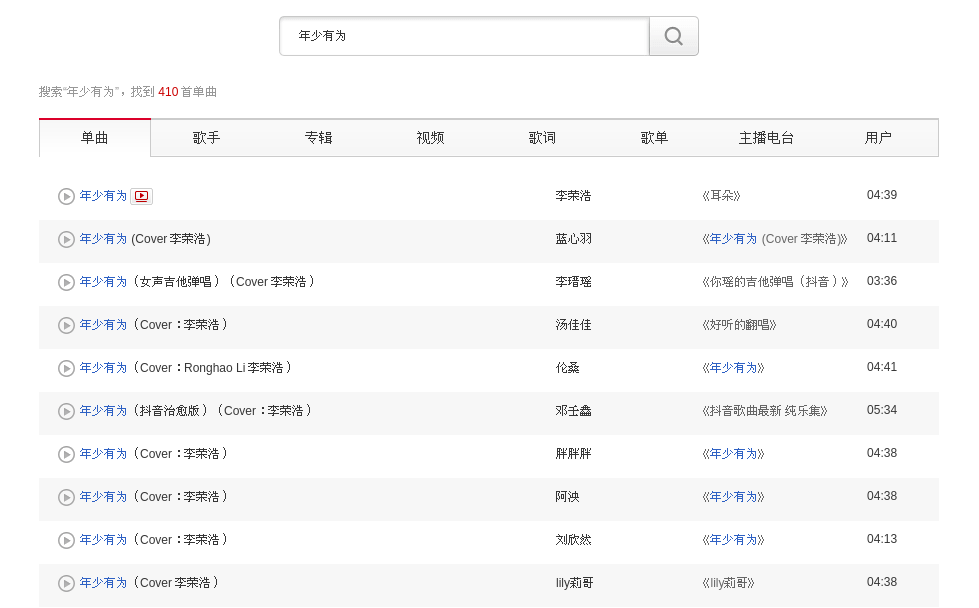
选择selenium + chrome 获取js渲染后的页面源码,并通过xpath提取想要的信息
python代码:
1 import requests
2 from urllib import request
3 from lxml import etree
4 from selenium import webdriver
5 import platform
6 import os
7 import time
8
9
10 headers = {
11 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36',
12 'Host': 'music.163.com',
13 'Referer': 'https://music.163.com/'
14 }
通过检查元素发现在网页的这一部分存在歌曲链接和名字
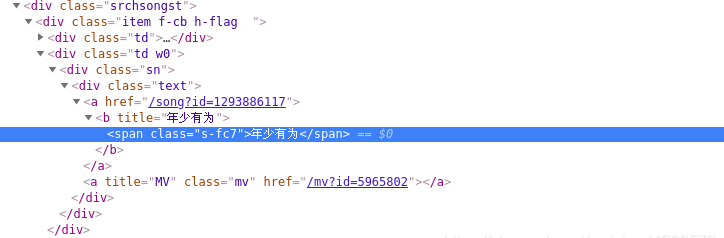
通过selenium获得页面源码
1 def selenium_get_html(url):
2 """通过selenium获得页面源码"""
3 # 无界面启动chrome
4 options = webdriver.ChromeOptions()
5 options.add_argument(
6 'User-Agent="Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"')
7 options.add_argument('--headless')
8 driver = webdriver.Chrome(chrome_options=options)
9 driver.get(url)
10 # 歌曲信息在frame框架内,进入frame框架得到源码
11 driver.switch_to.frame('contentFrame')
12 return driver.page_source
同理,在搜索歌单和歌手时检查元素也会发现类似的情况

得到具体信息
1 # 提取歌曲名称,演唱者姓名,和歌曲id以供选择
2 def search_input_song(url):
3 """获取歌曲名字和id"""
4 html = selenium_get_html(url)
5
6 root = etree.HTML(html)
7 id = root.xpath('//div[@class="srchsongst"]//div[@class="td w0"]//div[@class="text"]/a[1]/@href')
8 artist = root.xpath('//div[@class="srchsongst"]//div[@class="td w1"]//div[@class="text"]/a[1]/text()')
9 name = root.xpath('//div[@class="srchsongst"]//div[@class="td w0"]//div[@class="text"]//b/@title')
10
11 id = [i.strip('/song?id==') for i in id]
12 return zip(name, artist, id)
13
14 # 歌手默认选择第一位,所以仅得到第一位歌手的id
15 def search_input_artist(url):
16 """获取歌手id"""
17 html = selenium_get_html(url)
18
19 root = etree.HTML(html)
20 id = root.xpath('//div[@class="u-cover u-cover-5"]/a[1]/@href')
21
22 return id[0].strip('/artist?id==')
23
24 # 提取歌单名称,和歌单id以供选择
25 def search_input_playlist(url):
26 """获取歌单名字和id"""
27 html = selenium_get_html(url)
28
29 root = etree.HTML(html)
30 id = root.xpath('//div[@class="u-cover u-cover-3"]/a/@href')
31 name = root.xpath('//div[@class="u-cover u-cover-3"]//span/@title')
32
33 id = [i.strip('/playlist?id==') for i in id]
34 return zip(name, id)
五、下载歌曲
1.再次获取信息
得到id信息后,就可以在交互界面提示用户选择id下载。对于单曲来说获取用户选择的id后与对应地址拼接即可进行下载,而对于歌单和歌手因为每一个单位中都存在多首歌曲,第一次仅仅获取了歌手或歌单的id,需要二次分析。我们通过刚刚获取的链接可以发现
单曲的地址为:https://music.163.com/song?id={}
歌手的地址为:https://music.163.com/artist?id={}
歌单的地址为:https://music.163.com/playlist?id={} ({}内为id)
这回我们进入歌手的页面,检查元素查询歌曲信息,因为获取的页面中真正的歌曲信息并不在我们检查时看到所在的位置,通过查看框架源代码发现真正的信息在这,歌单页面也是一样。
![]()
python代码:
1 # url为歌单或歌手的地址
2 def get_url(url):
3 """从歌单中获取歌曲链接"""
4 req = requests.get(url, headers=headers)
5
6 root = etree.HTML(req.text)
7 items = root.xpath('//ul[@class="f-hide"]//a')
8 print(items)
9
10 return items
2.下载
通过之前的爬取,我们已经获得了歌曲的id及名称,可以进行下载了
网易云音乐有一个下载外链:https://music.163.com/song/media/outer/url?id={}.mp3
大括号中内容为所下载音乐在网易云的id,所以通过该外链和相应id即可下载网易云音乐。
将id和外链进行拼接后发送get请求,获取get请求所得到页面请求头中’Location’内容,这里面存储的是真正的音乐地址,使用request模块的urlretrieve方法下载。
python代码:
1 # song_id为歌曲id, song_name为歌曲名称
2 def download_song(song_id, song_name):
3 """通过外链下载歌曲"""
4
5 url = 'https://music.163.com/song/media/outer/url?id={}.mp3'.format(song_id)
6
7 # get请求设置禁止网页跳转,即allow_redirects=False
8 req = requests.get(url, headers=headers, allow_redirects=False)
9 song_url = req.headers['Location']
10 try:
11 # path在主函数中输入
12 request.urlretrieve(song_url, path + "/" + song_name + ".mp3")
13 print("{}--下载完成".format(song_name))
14 except:
15 print("{}--下载失败".format(song_name))
3.完整代码
1 import requests
2
3 from urllib import request
4 from lxml import etree
5 from selenium import webdriver
6
7
8 import platform
9 import os
10 import time
11
12
13 headers = {
14 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36',
15 'Host': 'music.163.com',
16 'Referer': 'https://music.163.com/'
17 }
18
19
20
21 def get_url(url):
22 """从歌单中获取歌曲链接"""
23 req = requests.get(url, headers=headers)
24 root = etree.HTML(req.text)
25 items = root.xpath('//ul[@class="f-hide"]//a')
26 print(items)
27 return items
28
29
30
31 def download_song(song_id, song_name):
32 """通过外链下载歌曲"""
33 url = 'https://music.163.com/song/media/outer/url?id={}.mp3'.format(song_id)
34
35 req = requests.get(url, headers=headers, allow_redirects=False)
36
37 song_url = req.headers['Location']
38 try:
39 request.urlretrieve(song_url, path + "/" + song_name + ".mp3")
40 print("{}--下载完成".format(song_name))
41 except:
42 print("{}--下载失败".format(song_name))
43
44
45
46 def download(items):
47 """全部歌曲下载"""
48 for item in items:
49 song_id = item.get('href').strip('/song?id=')
50 song_name = item.text
51 download_song(song_id, song_name)
52 print("-------下载完成-------")
53
54
55 def artist_id_down(id):
56 """根据歌手id下载全部歌曲"""
57 artist_url = 'https://music.163.com/artist?id={}'.format(id)
58 items = get_url(artist_url)
59 download(items)
60
61
62 def playlist_id_down(id):
63 """根据歌单id下载全部歌曲"""
64 playlist_url = 'https://music.163.com/playlist?id={}'.format(id)
65 items = get_url(playlist_url)
66 download(items)
67
68
69 def get_song_name(url):
70 """在歌曲页面获得名字"""
71 req = requests.get(url, headers=headers)
72 root = etree.HTML(req.text)
73 name = root.xpath('//em[@class="f-ff2"]/text()')
74 return name[0]
75
76
77 def song_id_down(id):
78 """根据歌曲id下载"""
79 url = 'https://music.163.com/song?id={}'.format(id)
80 name = get_song_name(url)
81 download_song(id, name)
82
83
84 def selenium_get_html(url):
85 """通过selenium获得页面源码"""
86 options = webdriver.ChromeOptions()
87
88
89 options.add_argument(
90 'User-Agent="Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"')
91 options.add_argument('--headless')
92 driver = webdriver.Chrome(chrome_options=options)
93 driver.get(url)
94 driver.switch_to.frame('contentFrame')
95 driver.close()
96 return driver.page_source
97
98
99 def search_input_song(url):
100 """获取歌曲名字和id"""
101 html = selenium_get_html(url)
102 root = etree.HTML(html)
103
104 id = root.xpath('//div[@class="srchsongst"]//div[@class="td w0"]//div[@class="text"]/a[1]/@href')
105 artist = root.xpath('//div[@class="srchsongst"]//div[@class="td w1"]//div[@class="text"]/a[1]/text()')
106 name = root.xpath('//div[@class="srchsongst"]//div[@class="td w0"]//div[@class="text"]//b/@title')
107
108
109 id = [i.strip('/song?id==') for i in id]
110 return zip(name, artist, id)
111
112
113 def search_input_artist(url):
114 """获取歌手id"""
115 html = selenium_get_html(url)
116 root = etree.HTML(html)
117 id = root.xpath('//div[@class="u-cover u-cover-5"]/a[1]/@href')
118 return id[0].strip('/artist?id==')
119
120
121 def search_input_playlist(url):
122 """获取歌单名字和id"""
123 html = selenium_get_html(url)
124 root = etree.HTML(html)
125 id = root.xpath('//div[@class="u-cover u-cover-3"]/a/@href')
126 name = root.xpath('//div[@class="u-cover u-cover-3"]//span/@title')
127 id = [i.strip('/playlist?id==') for i in id]
128 return zip(name, id)
129
130
131 def main(name, choose_id):
132 if choose_id == 1:
133 url = 'https://music.163.com/#/search/m/?s={}&type=1'.format(name)
134 com = search_input_song(url)
135 ids = []
136 for i, j, k in com:
137 ids.append(k)
138 print("歌曲名称:{0}-------演唱者:{1}-------id:{2}".format(i, j, k))
139 while True:
140 id = input("请输入需要下载的id(输入q退出):")
141 if id == 'q':
142 return
143 if id in ids:
144 song_id_down(id)
145 return
146 print("请输入正确的id!!!")
147
148
149 elif choose_id == 2:
150 url = 'https://music.163.com/#/search/m/?s={}&type=100'.format(name)
151 id = search_input_artist(url)
152 artist_id_down(id)
153 elif choose_id == 3:
154 url = 'https://music.163.com/#/search/m/?s={}&type=1000'.format(name)
155 com = search_input_playlist(url)
156 ids = []
157 for i, j in com:
158 ids.append(j)
159 print("歌单名称:{0}-------id:{1}".format(i, j))
160 while True:
161 id = input("请输入需要下载的id(输入q退出):")
162 if id == 'q':
163 return
164 if id in ids:
165 playlist_id_down(id)
166 return
167 print("请输入正确的id(输入q退出):")
168
169
170 def recognition():
171 """判断系统,执行清屏命令"""
172 sysstr = platform.system()
173 if (sysstr == "Windows"):
174 os.system('cls')
175 elif (sysstr == "Linux"):
176 os.system('clear')
177 if __name__ == '__main__':
178 path = input("请输入完整路径地址:")
179 if not os.path.exists(path):
180 os.makedirs(path)
181 while True:
182 print("=========================")
183 print("请按提示选择搜索类型:")
184 print("1.歌曲")
185 print("2.歌手")
186 print("3.歌单")
187 print("4.退出")
188 print("=========================")
189 choose_id = int(input("搜索类型:"))
190
191
192 if choose_id == 4:
193 break
194 elif choose_id != 1 and choose_id != 2 and choose_id != 3:
195 print("请按要求输入!!!")
196 continue
197 else:
198 recognition()
199 name = input("请输入搜索内容:")
200 main(name, choose_id)
201 print("3秒后返回主页面")
202 time.sleep(3)
6、结语
这篇文章和代码是网易云音乐的下载,里面的数据比较全面,大块可分为:评论用户信息、评论信息、用户权限信息、评论回复信息等。本文爬取的数据有,评论人昵称、评论时间、评论内容、用户ID。这篇文章就到这里了,如果有不足的地方欢迎各位大佬指定一下,谢谢!

