
哈夫曼编码实践
哈夫曼编码实践
1. 任务详情
设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树。
并完成对英文文件的编码和解码。
要求:
- 准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
- 构造哈夫曼树
- 对英文文件进行编码,输出一个编码后的文件
- 对编码文件进行解码,输出一个解码后的文件
- 撰写博客记录实验的设计和实现过程,并将源代码传到码云
- 把实验结果截图上传到云班课
2. 实验的设计和实现过程
1. 构造树的节点
先构造一个哈夫曼树的节点类HuffNode,节点类包含5个元素:左孩子left、右孩子right、节点字母ch、频率n和对应编码code。
2. 复写节点类的compareTo
根据字母出现的次数排序,次数多的排在前面,次数少的排在后面,此处实际上是在构造哈夫曼节点顺序。
3. 构造哈夫曼树的类
包含26个字母和空格的字符数组ch、读取文件得到的字符数组a、保存各个节点权值的整数数组sum、哈夫曼树的根节点root、保存各个节点编码值的字符串数组strings、哈夫曼树的列表形式treelist。
4. 读取未编码文件
用read从文件中读取字节流,并保存为字符数组。
用count统计各个字母出现的次数。
5. 构造一棵哈夫曼树
将所有节点都加入列表后调用Collections.sort()排序一次。当列表长度大于1时,每次选取两个列表中权值最小的节点,构成一个字符为空的父节点,列表中删除这两个节点。把父节点加入列表后,对列表再次排序,循环到列表中只剩下一个节点时,该节点为根节点,保存。
6. 根据哈夫曼树获取编码
编写getCode()方法,左子树编码为0,右子树编码为1;默认左右子树中出现次数较多的放右边。
根据编码转换文件内容的格式,并将转换后的结果存入文件(存入字符+次数,以逗号分割,例如“a2,b3”表示a出现了2次,b出现了3次),文件内容的编码之间以空格分割,便于解码。
写入一个search()方法,根据字符找到节点,从而找到该字符编码。
7. 构造哈夫曼树的类(解码)
解码方法可以和编码方法放在同一个哈夫曼树的类里。为了便于区分,这里将两个过程分开来写。
获取解码后的文件。
根据哈夫曼树获得编码:复用getCode()方法。
解码,同样写了一个search2()方法用来根据编码寻找节点,进而找到对应字符进行格式转换。
8. 运行结果截图
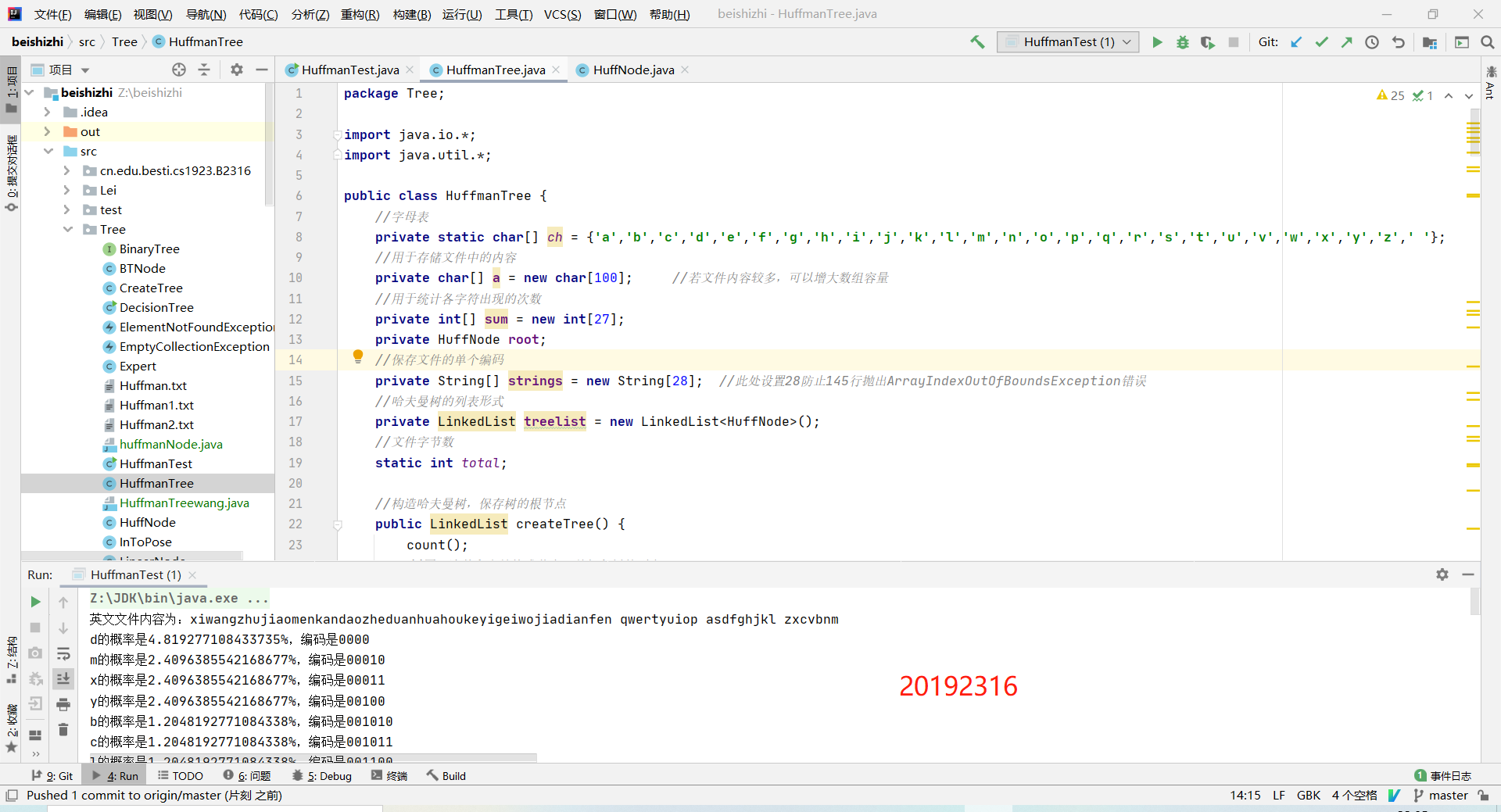

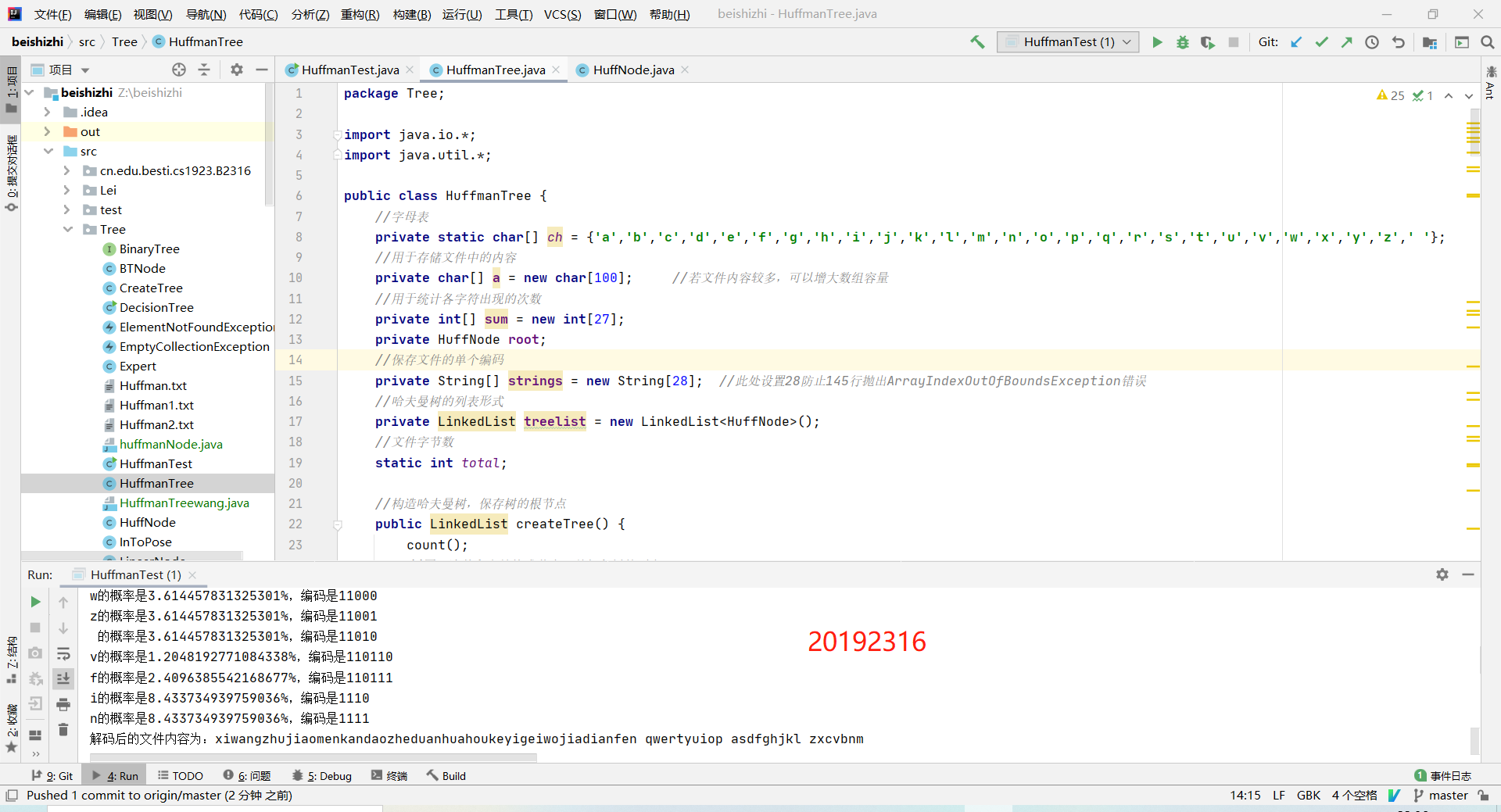
3. 实验过程中遇到的问题和解决过程
- 问题1:完全没有思路
- 问题1解决方案:通过老师给的两条哈夫曼树构建的代码,逐步单步调试摸索其思路和原理,从而构建出自己的思路。
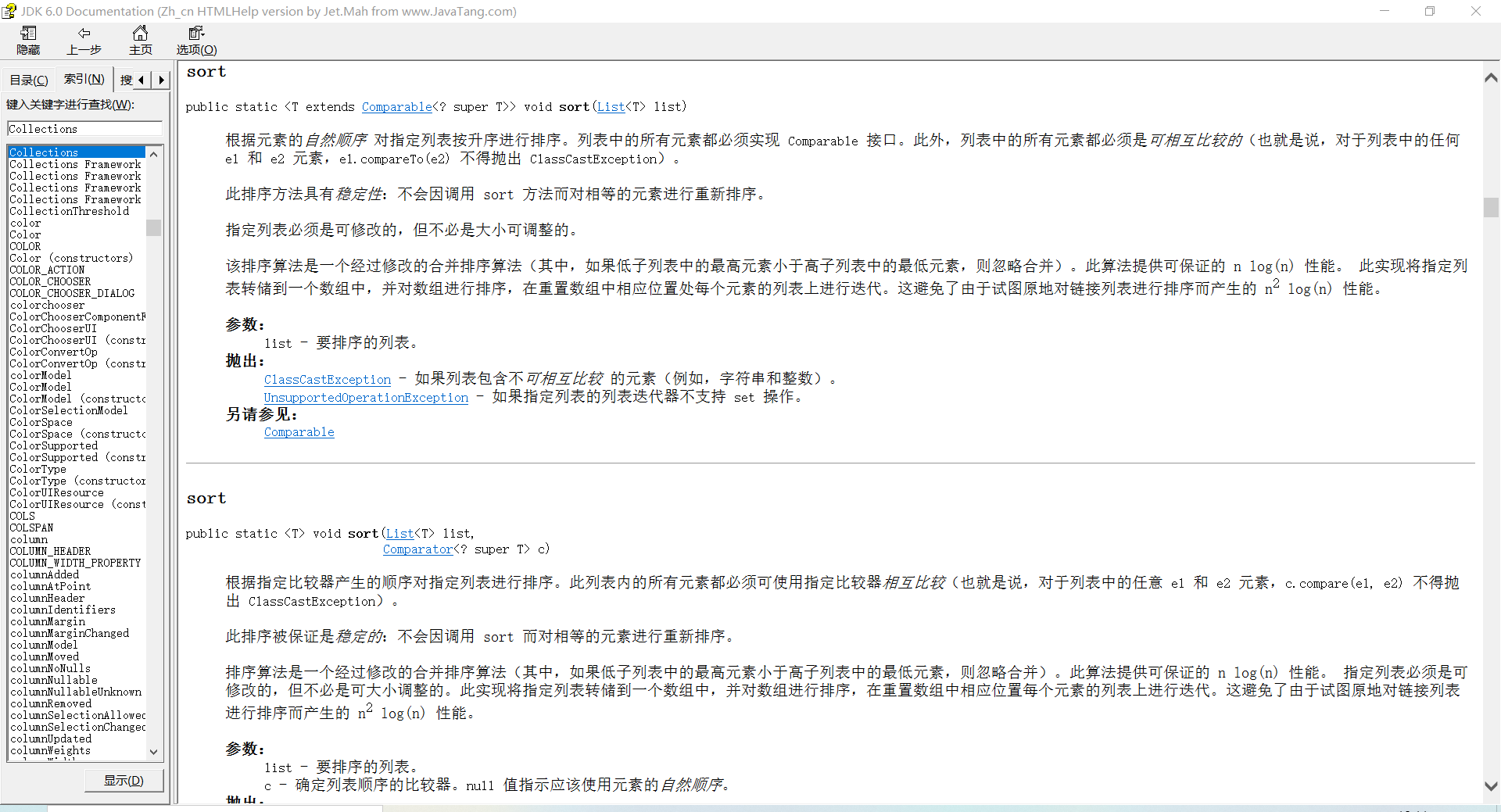
- 问题2:在网上学习到Collections.sort(),但不清楚其用法;
- 问题2解决方案:通过JDK_API_1_6_CN查询其用法,参考java基础——Collections.sort的两种用法。
其他(感悟、思考等)
树好难、、哈夫曼树好难。。


